
生产环境常见问题分析
消息零丢失方案
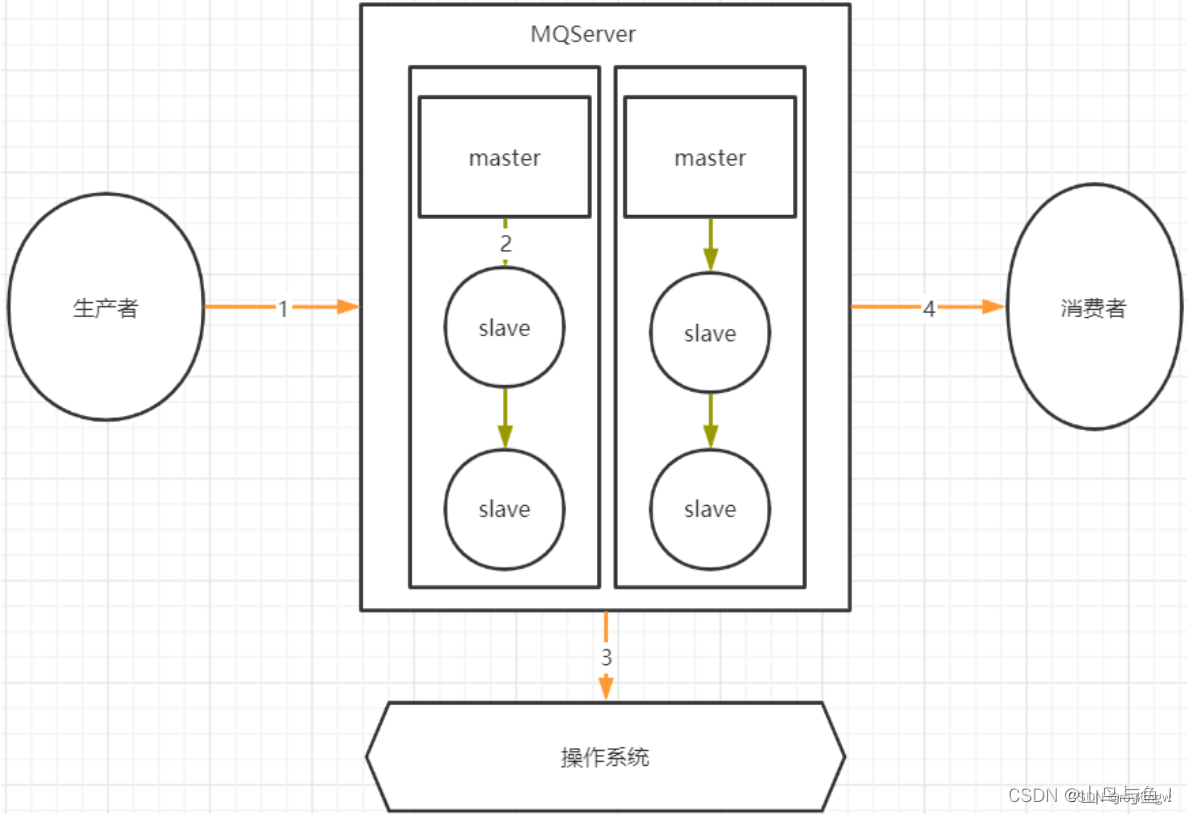
1、生产者发消息到Broker不丢失
Kafka的消息生产者Producer,支持定制一个参数,ProducerConfig.ACKS_CONFIG。
acks配置为0 : 生产者只负责往Broker端发消息,而不关注Broker的响应。也就是说不关心Broker端有没有收到消息。性能高,但是数据会有丢消息的可能。
acks配置为1:当Broker端的Leader Partition接收到消息后,只完成本地日志文件的写入,然后就给生产者答复。其他Partiton异步拉取Leader Partiton的消息文件。这种方式如果其他Partiton拉取消息失败,也有可能丢消息。
acks配置为-1或者all:Broker端会完整所有Partition的本地日志写入后,才会给生产者答复。数据安全性最高,但是性能显然是最低的。
对于KafkaProducer,只要将acks设置成1或-1,那么Producer发送消息后都可以拿到Broker的反馈RecordMetadata,里面包含了消息在Broker端的partition,offset等信息。通过这这些信息可以判断消息是否发送成功。如果没有发送成功,Producer就可以根据情况选择重新进行发送。
2、Broker端保存消息不丢失
首先,合理优化刷盘频率,防止服务异常崩溃造成消息未刷盘。Kafka的消息都是先写入操作系统的PageCache缓存,然后再刷盘写入到硬盘。PageCache缓存中的消息是断电即丢失的。如果消息只在PageCache中,而没有写入硬盘,此时如果服务异常崩溃,这些未写入硬盘的消息就会丢失。Kafka并不支持写一条消息就刷一次盘的同步刷盘机制,只能通过调整刷盘的执行频率,提升消息安全。主要涉及几个参数:
flush.ms : 多长时间进行一次强制刷盘。
log.flush.interval.messages:表示当同一个Partiton的消息条数积累到这个数量时,就会申请一次刷盘操作。默认是Long.MAX。
log.flush.interval.ms:当一个消息在内存中保留的时间,达到这个数量时,就会申请一次刷盘操作。他的默认值是空。
然后,配置多备份因子,防止单点消息丢失。在Kafka中,可以给Topic配置更大的备份因子replication-factors。配置了备份因子后,Kafka会给每个Partition分配多个备份Partition。这些Partiton会尽量平均的分配到多个Broker上。并且,在这些Partiton中,会选举产生Leader Partition和Follower Partition。这样,当Leader Partition发生故障时,其他Follower Partition上还有消息的备份。就可以重新选举产生Leader Partition,继续提供服务。
3、消费者端防止异步处理丢失消息
消费者端由于有消息重试机制,正常情况下是不会丢消息的。每次消费者处理一批消息,需要在处理完后给Broker应答,提交当前消息的Offset。Broker接到应答后,会推进本地日志的Offset记录。如果Broker没有接到应答,那么Broker会重新向同一个消费者组的消费者实例推送消息,最终保证消息不丢失。这时,消费者端采用手动提交Offset的方式,相比自动提交会更容易控制提交Offset的时机。
消费者端唯一需要注意的是,不要异步处理业务逻辑。因为如果业务逻辑异步进行,而消费者已经同步提交了Offset,那么如果业务逻辑执行过程中出现了异常,失败了,那么Broker端已经接收到了消费者的应答,后续就不会再重新推送消息,这样就造成了业务层面的消息丢失。
消息积压如何处理
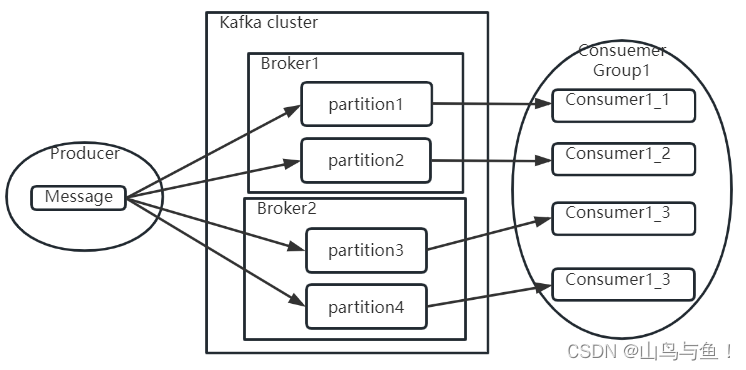
通常情况下,Kafka本身是能够存储海量消息的,他的消息积压能力是很强的。但是,如果发现消息积压问题已经影响了业务处理进度,这时就需要进行一定的优化。
1、如果业务运行正常,只是因为消费者处理消息过慢,造成消息加压。那么可以增加Topic的Partition分区数,将消息拆分到更到的Partition。然后增加消费者个数,最多让消费者个数=Partition分区数,让一个Consumer负责一个分区,将消费进度提升到最大。
另外,在发送消息时,还是要尽量保证消息在各个Partition中的分布比较均匀。比如,在原有Topic下,可以调整Producer的分区策略,让Producer将后续的消息更多的发送到新增的Partition里,这样可以让各个Partition上的消息能够趋于平衡。如果你觉得这样太麻烦,那就新增一个Topic,配置更多的Partition以及对应的消费者实例。然后启动一批Consumer,将消息从旧的Topic搬运到新的Topic。这些Consumer不处理业务逻辑,只是做消息搬运,所以他们的性能是很高的。这样就能让新的Topic下的各个Partition数量趋于平衡。
2、如果是消费者的业务问题导致消息阻塞了,从而积压大量消息,并影响了系统正常运行。比如消费者序列化失败,或者业务处理全部异常。这时可以采用一种降级的方案,先启动一个Consumer将Topic下的消息先转发到其他队列中,然后再慢慢分析新队列里的消息处理问题。类似于死信队列的处理方式。
如何保证消息顺序
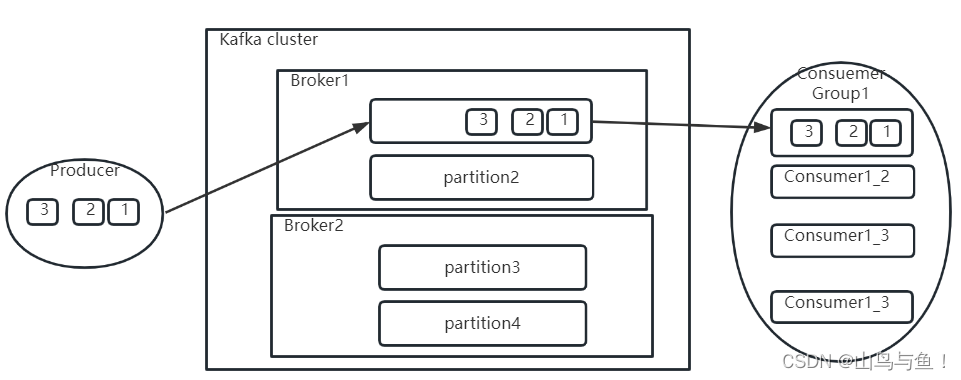
问题要分两个方面来考虑:
1、因为kafka中各个Partition的消息是并发处理的,所以要保证消息顺序,对于Producer,要保证将一组有序的消息发到同一个Partition里。因为Partition的数据是顺序写的,所以自然就能保证消息是按顺序保存的。
2、对于消费者,需要能够按照1,2,3的顺序处理消息。
问题一、如何保证Producer发到Partition上的消息是有序的
首先,要保证Producer将消息都发送到一个Partition上,其实有两种方法。一种简答粗暴的想法就是给Topic只配一个Partition,没有其他Partition可选了,自然所有消息都到同一个Partition上了。表示从创建Topic时就放弃了多Partition带来的吞吐量便利,是不现实的。另一种是Topic依然配置多个Partition,但是通过定制Producer的Partition分区器,将消息分配到同一个Partition上。这样对于某一些要求局部有序的场景是至少是可行的。例如在电商场景,我可能只是需要保证同一个订单相关的多条消息有序,但是并不要求所有消息有序。这样就可以通过自定义分区路由器,将订单相同的多条消息发送到同一个Partition。
但是Producer都将消息往同一个Partition,也不能保证消息顺序。因为消息可能发送失败。比如Producer依次发送1,2,3,三条消息。如果消息1因为网络原因发送失败了,2 和3 发送成功了,这样消息顺序就乱了。如果把producer的acks参数设置成1或-1,这样每次发送消息后,可以根据Broker的反馈判断消息是否成功。思路是可行的,但是重试的次数,发送消息的数量等都是需要考虑的问题。
回顾一下之前对于生产者消息幂等性的设计:
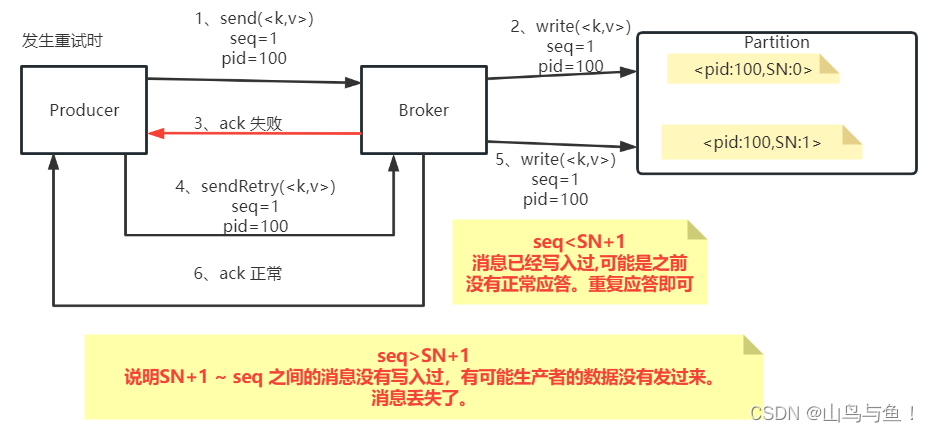
Kafka的这个sequenceNumber是单调递增的。如果只是为了消息幂等性考虑,那么只要保证sequenceNumber唯一就行了,为什么要设计成单调递增呢?其实Kafka这样设计的原因就是可以通过sequenceNumber来判断消息的顺序。也就是说,在Producer发送消息之前就可以通过sequenceNumber定制好消息的顺序,然后Broker端就可以按照顺序来保存消息。与此同时, SequenceNumber单调递增的特性不光保证了消息是有顺序的,同时还保证了每一条消息不会丢失。一旦Kafka发现Producer传过来的SequenceNumber出现了跨越,那么就意味着中间有可能消息出现了丢失,就会往Producer抛出一个OutOfOrderSequenceException异常。
在生产者的配置类ProducerConfig中很快能找到很多和消息顺序ordering的描述:
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking."
+ " Note that if this configuration is set to be greater than 1 and <code>enable.idempotence</code> is set to false, there is a risk of"
+ " message reordering after a failed send due to retries (i.e., if retries are enabled); "
+ " if retries are disabled or if <code>enable.idempotence</code> is set to true, ordering will be preserved."
+ " Additionally, enabling idempotence requires the value of this configuration to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE + "."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled. ";
问题二:Partition中的消息有序后,如何保证Consumer的消费顺序是有序的
public static final String FETCH_MAX_BYTES_CONFIG = "fetch.max.bytes";
private static final String FETCH_MAX_BYTES_DOC = "The maximum amount of data the server should return for a fetch request. " +
"Records are fetched in batches by the consumer, and if the first record batch in the first non-empty partition of the fetch is larger than " +
"this value, the record batch will still be returned to ensure that the consumer can make progress. As such, this is not a absolute maximum. " +
"The maximum record batch size accepted by the broker is defined via <code>message.max.bytes</code> (broker config) or " +
"<code>max.message.bytes</code> (topic config). Note that the consumer performs multiple fetches in parallel.";
public static final int DEFAULT_FETCH_MAX_BYTES = 50 * 1024 * 1024;
这里明确提到Consumer其实是每次并行的拉取多个Batch批次的消息进行处理的。也就是说Consumer拉取过来的多批消息并不是串行消费的。所以在Kafka提供的客户端Consumer中,是没有办法直接保证消费的消息顺序。其实这也比较好理解,因为Kafka设计的重点是高吞吐量,所以他的设计是让Consumer尽最大的能力去消费消息。而只要对消费的顺序做处理,就必然会影响Consumer拉取消息的性能。
所以这时候,我们能做的就是在Consumer的处理逻辑中,将消息进行排序。比如将消息按照业务独立性收集到一个集合中,然后在集合中对消息进行排序。
版权归原作者 山鸟与鱼! 所有, 如有侵权,请联系我们删除。