
关键字:
数据同步,目标端入库,性能、人大金仓
概述
程序的性能是指计算机程序在执行任务时所表现出的速度、效率和稳定性等方面的度量。性能的好坏直接影响到程序的用户体验和开发成本。优化程序性能通常包括提高代码质量、减少资源消耗、采用更高效的算法和技术等方面。本文将简要介绍KFS实时同步目标端的性能定位方案。
实时同步流程概述

KFS源端的工作流分为两个阶段:binlog-to-q, q-to-kufl.
binlog-to-q阶段,KFS从源端的数据库日志中抽取增量数据,经过extractor模块解析封装后,以DBMSEvent的形式在内存队列queue中暂存,此阶段的主要工作是将数据库的元组信息抽取转化为DBMSEvent,我们称此阶段为“解析”阶段。
q-to-kufl阶段,将队列中的DBMSEvent取出,封装为KUFLEvent,经过序列化成为KUFL持久化在外存文件中,此阶段主要是将内存中的数据转化为外存文件持久化,我们称此阶段为“存储”阶段。
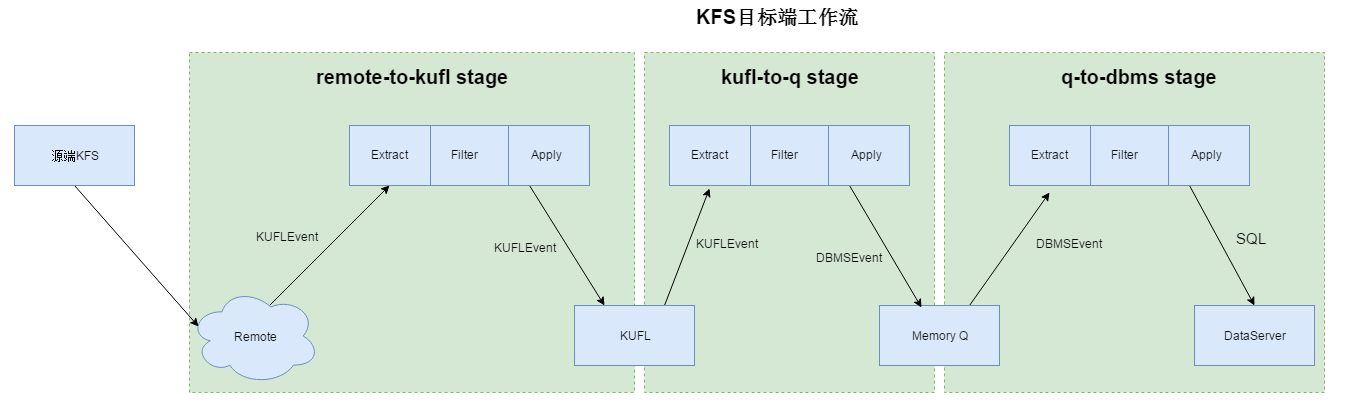
KFS目标端工作流分为三个阶段:remote-to-kufl, kufl-to-q, q-to-dbms.
remote-to-kufl阶段,KFS目标端通过主动访问源端的监听,建立TCP连接,从源端的KUFL文件中反序列化按顺序将KUFLEvent获取,获取完成后序列化成为KUFL存储在本地,此阶段的主要任务是将源端的文件发送到目标端,我们将此阶段称为“传输”阶段。
kufl-to-q阶段,KFS将本地的KUFL中反序列化成为KUFLEvent,同时解析为DBMSEvent存储在内存队列queue中。
q-to-dbms阶段,applier将内存中的DBMSEvent取出,同时将其翻译成为SQL语句,应用到目标端数据库中,此阶段的主要目的是将数据入库,因此我们将此阶段称为“入库”阶段。
简要来说,各个阶段所进行的活动如下:
源端
binlog-to-q:1.从事务日志获取增量数据 2.将增量数据放入内存队列
q-to-kufl:1.从内存队列中获取增量数据 2.将增量数据写入KUFL文件持久化 3.更新数据库中间表中的断点位置。
目标端
remote-to-kufl:1.通过网络从源端获取增量数据 2.将增量数据写入KUFL文件持久化
kufl-to-q:1.从本地KUFL文件获取增量数据 2.将增量数据放入内存队列
q-to-dbms:1.从内存队列中获取增量数据2.将增量数据加载到目标数据库
目标端入库优化指南
网络问题优化
对于KFS来说,网络问题的优化方式通常有2种:
- 改善网络质量,增大带宽
- 将存在网络问题的组件集中部署,例如,源端数据库和源端KFS集中部署,目标端数据库和目标端KFS集中部署。
KFS所在机器CPU问题
此问题一般是当前的硬件环境下,KFS的解析效率已经达到极限,那么解决这个方法,可以从两个方面入手:
- 增强相关的硬件性能,如增加cpu主频。
- 减少解析的量,通过配置底层过滤在日志中将无需解析的表过滤。
property=replicator.extractor.dbms.lowLevelFilter=true
property=replicator.extractor.dbms.tablePatterns=public.,mytest.
JVM内存不足
配置方法
通过调整flysync.ini中的repl_java_mem_size参数完成。
参数单位为m,配置时无需加单位。
所需内存大小计算方式
源端:该服务设置的大事务分片数平均每条数据大小(该源端关联的目标端数量+1)
目标端:该服务对应的源端设置的大事务分片数*平均每条数据大小
频繁更新中间表断点问题
在源端flysync.ini中配置:
property=replicator.pipeline.master.syncKUFLWithExtractor=false
该参数配置后,KFS将不在向源端数据库中更新断点,断点信息全部存储在KUFL当中,需要注意的是,若KUFL也被清除,那么KFS再次启动时将无法获取断点,从当前最新位置启动。
磁盘写入效率低
此问题暂时没有较好的解决手段,只能通过增强相关硬件的方式处理。
如使用SSD盘。
网络带宽问题
同网络问题优化思路。
数据库加载慢
批量入库
property=replicator.applier.dbms.optimizeRowEvents=true
property=replicator.applier.dbms.maxRowBatchSize=20
大小通常设置为500~2000即可,可根据实际内存调整。
Jdbc插入优化(仅限KESV8数据源)
property=replicator.datasource.global.connectionSpec.urlOptions=socketTimeout=60&preferQueryMode=extendedForPrepared&
reWriteBatchedInserts=true
内存队列缓冲池大小
property= replicator.global.buffer.size=100
大小通常设置为10~200,可根据实际内存调整。
除了上述通用参数之外,还有以下和业务强相关的场景。
小事务较多,无法进行批量
数据集中在某些表上,分布不均匀,导致入库效率低
update、delete较多,并且执行慢
存在跑批类型的数据
对于问题1,2,我们考虑采用多通道并行入库的方式进行。
配置方法如下:
1)在flysync.ini文件中增加以下内容:
svc_parallelization_type=memory
channels=4
property=replicator.store.parallel-queue.partitionerClass=com.kingbase.flysync.replicator.storage.parallel.ShardListPartitioner
同时,在目标端原有的过滤器后面追加新的过滤器:
shardbytable
2)找到static文件同级目录下的shard.list文件。在最下面添加:
public_a1=0
public_a2=1
public_a3=2
public_a4=3
(*)=0
public_a1=0 含义为:public.a1表走通道0
public_a2=1 含义为:public.a2表走通道1
public_a3=2 含义为:public.a3表走通道2
public_a4=3 含义为:public.a4表走通道3
(*)=0 含义为:其他未配置的表默认走通过0
对于问题3,确定是否存在索引,若没有则需要增加索引。
对于问题4,考虑从方案层面不同步此类数据。
版权归原作者 KFS补给站 所有, 如有侵权,请联系我们删除。