
进程地址空间
文章目录

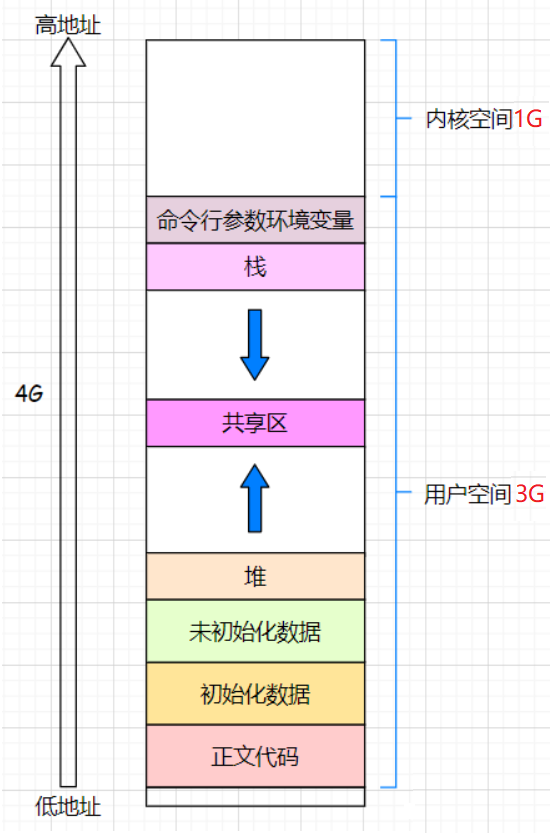
一、程序地址空间的空间排布
相信我们在学习C的过程中,下面这幅图都见过:
1、验证程序地址空间的排布:
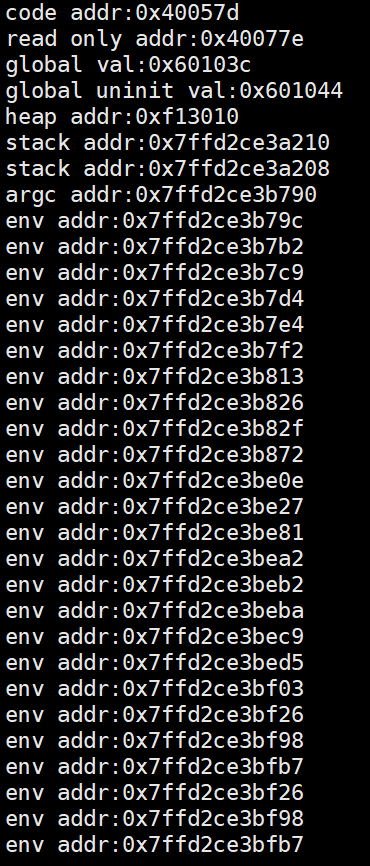
- 程序地址空间不是内存。我们在linux操作系统中通过代码对该布局进行如下的验证:
#include<stdio.h>#include<stdlib.h>int g_unval;//未初始化int g_val =100;//初始化intmain(int argc,char*argv[],char*envp[]){printf("code addr:%p\n",main);//代码区起始地址constchar* p ="hello world";//p是指针变量(栈区),p指向字符常量h(字符常量区)printf("read only addr:%p\n",p);//初始化数据printf("global val:%p\n",&g_val);//未初始化数据printf("global uninit val:%p\n",&g_unval);char*q =(char*)malloc(10);printf("heap addr:%p\n",q);//堆区printf("stack addr:%p\n",&p);//栈区 p先定义,先入栈printf("stack addr:%p\n",&q);//栈区int i =0;for(int i =0; i < argc; i++){printf("argc addr:%p\n", argv[i]);//命令行参数} i =0;while(envp[i]){printf("env addr:%p\n", envp[i]);//环境变量 i++;}return0;}
总结:
- 堆区向地址增大方向增长(箭头向上)
- 栈区向地址减少方向增长(箭头向下)
- 堆,栈相对而生
- 我们一般在C函数中定义的变量,通常在栈上保存,那么先定义的一定是地址比较高(先定义先入栈,后定义后入栈)的。
3、如何理解static变量:
- 先前我们知道如果一个变量被static修饰,它的作用域不变,依旧在该函数内有效,但是其声明周期会随着程序一直存在,可为什么呢?
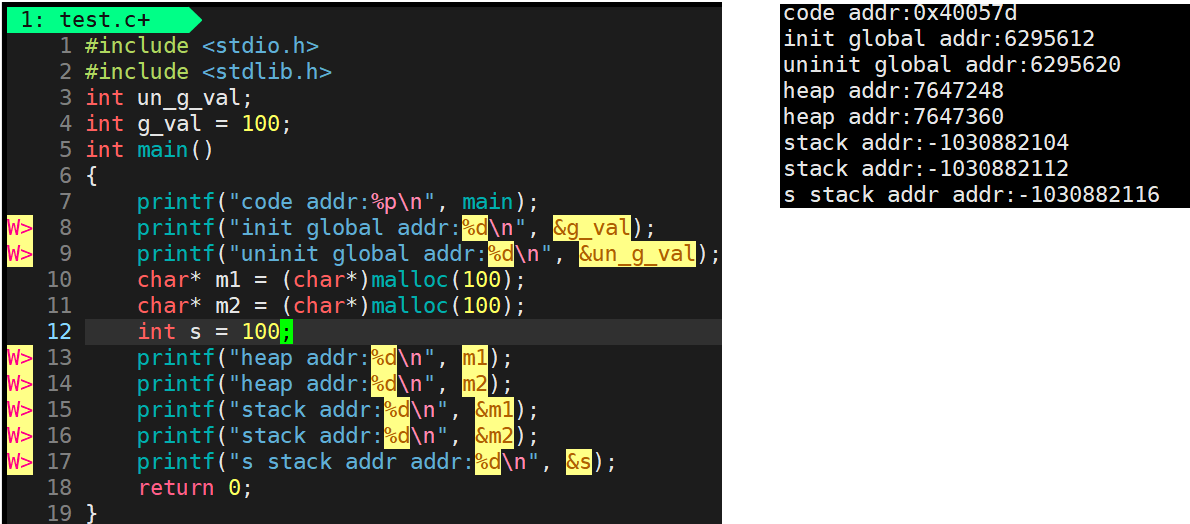
先来看下正常定义的变量:
#include<stdio.h>#include<stdlib.h>int un_g_val;int g_val =100;intmain(){printf("code addr:%p\n", main);printf("init global addr:%d\n",&g_val);printf("uninit global addr:%d\n",&un_g_val);char* m1 =(char*)malloc(100);char* m2 =(char*)malloc(100);int s =100;printf("heap addr:%d\n", m1);printf("heap addr:%d\n", m2);printf("stack addr:%d\n",&m1);printf("stack addr:%d\n",&m2);printf("s stack addr addr:%d\n",&s);return0;}
此时正常定义的变量s就符合先前栈的地址分布规则:后定义的变量在地址较低处,下面来看下static定义的变量:
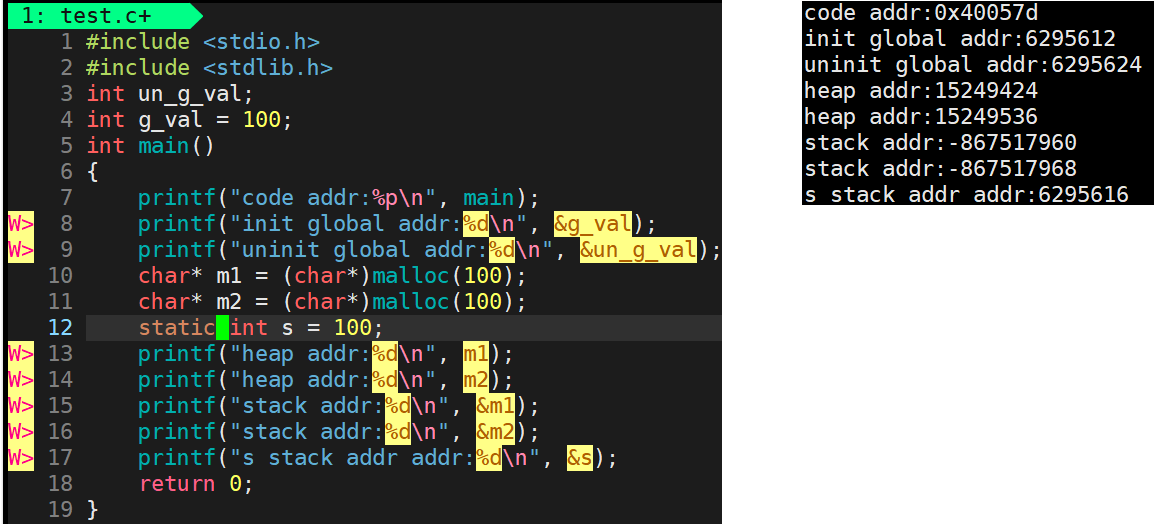
根据图示:变量s一旦被static修饰,尽管s是在代码函数里面被定义,可是此变量已经不在栈上面了,此时变成了全局变量,这也就
是为什么生命周期会一直存在。
总结:函数内定义的变量static修饰,本质是编译器会把该变量编译进全局数据区内。
二、进程地址空间是什么?
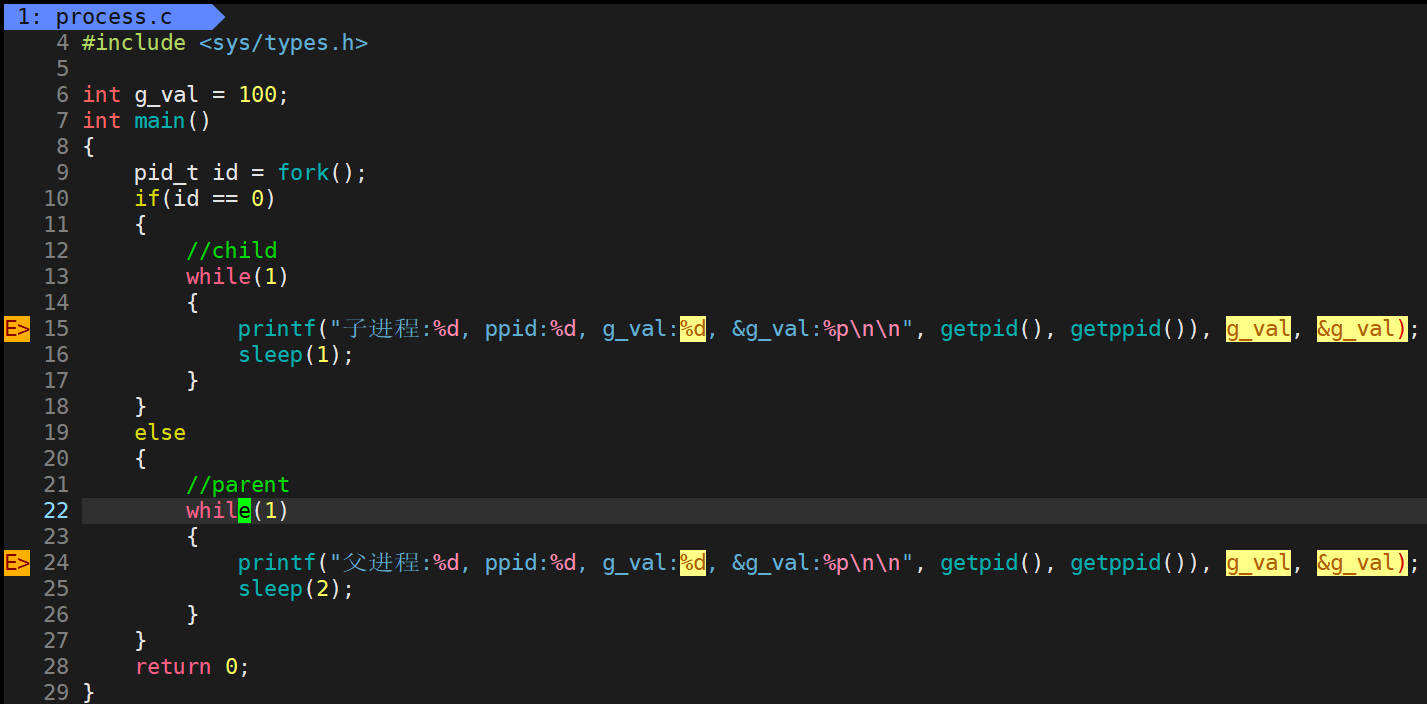
用下面代码为示例:
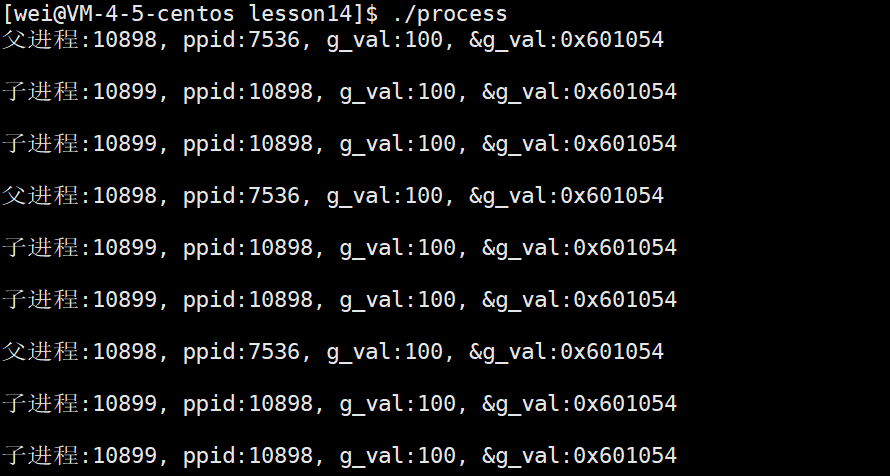
当父子进程没有人修改全局数据的时候,父子是共享该数据的!可以通过下面的运行结果看出:
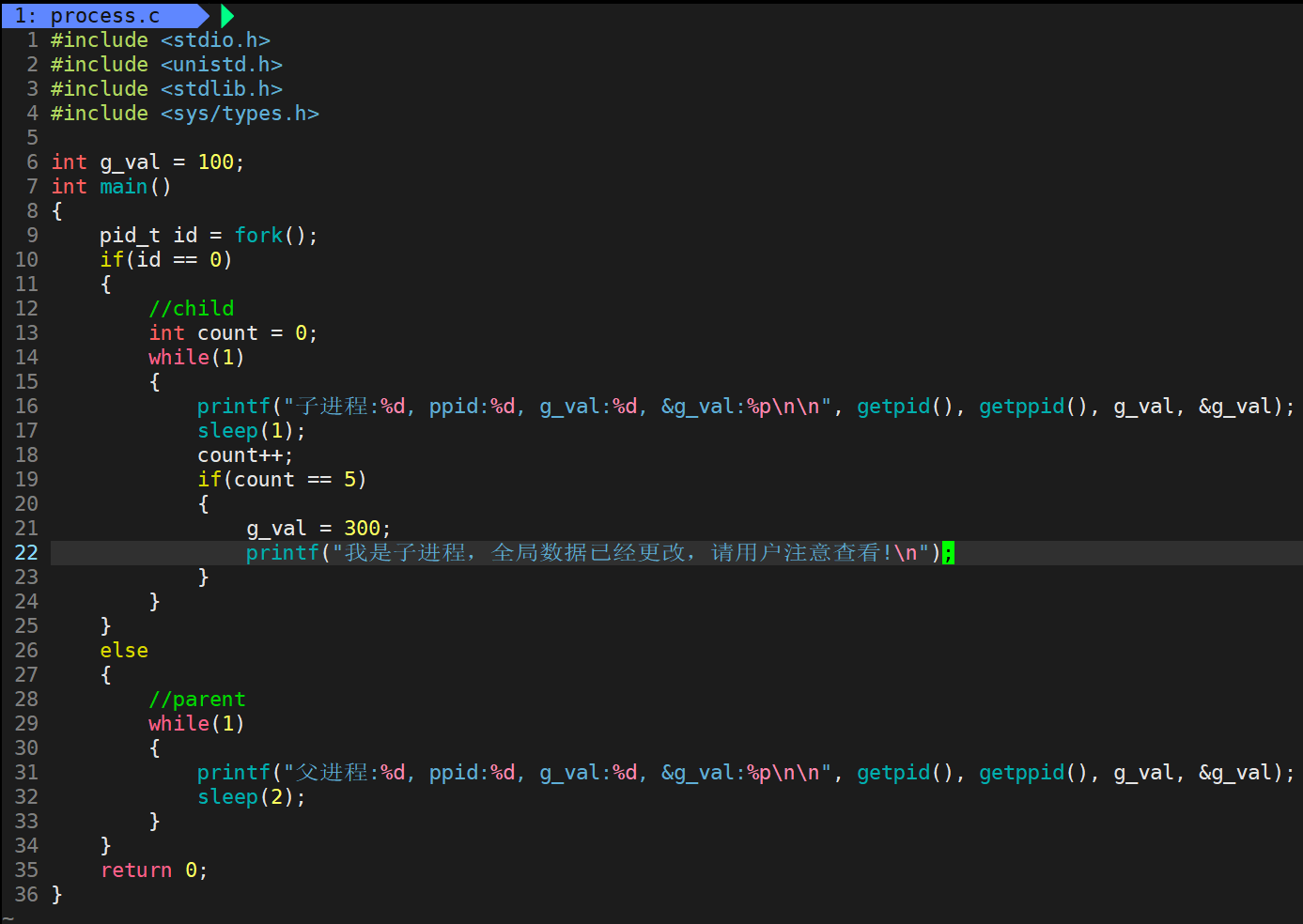
如果尝试写入呢?
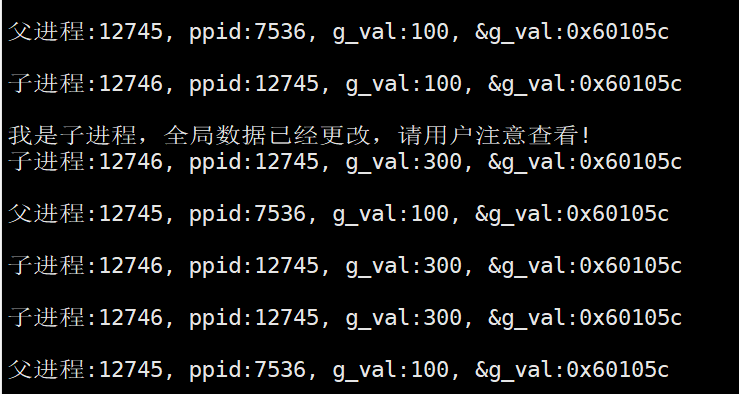
代码共享,所以看到前五次打印的g_val的地址都是一样的,这我们不意外,等到了第六次时,我们发现父进程g_val依然是100,子进程的g_val变成了300,因为我们将它改了,这也不意外,因为前面说了,父子进程之间代码共享,而数据是各自私有一份的(写时拷贝),但是令人奇怪的是地址竟然是一样的!
如果我们看到的地址,是物理地址,这种情况可不可能呢?
这是绝对不可能的,如果可能,那么父子进程在同一个地址处读取数据怎么会是不同的值呢?所以,我们曾经所学到的所有的地址,绝对不是物理地址。
这种地址我们称之为虚拟地址、线性地址、逻辑地址!!!
任何我们学过的语言,里面的地址都绝对不会是物理地址,虚拟地址这种地址是由操作系统给我们提供的,操作系统如何给我们提供呢?既然这种地址是虚拟地址,那么一定有某种途径将虚拟地址转化为物理地址,因为数据和代码一定在物理内存上,因为冯诺依曼规定任何数据在启动时必须加载到物理内存,所以肯定需要将虚拟地址转化成物理地址,这里的转化工作由操作系统完成,所有的程序都必须运行起来,运行起来之后,该程序立即变成了进程,那么刚刚打印的虚拟地址大概率和进程有某种关系
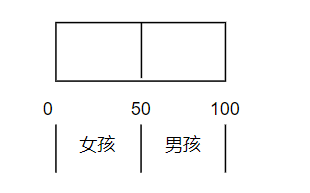
我们在上学期间,经常可能会和同桌画三八线,比如一张课桌是100cm,我们用一把尺子来划分区域,女孩的区域是0,50,男孩的区域是51,100,那么我们再计算机当中怎么描述这个事情呢?我们可以这样定义:
structarea{unsignedlong start;unsignedlong end;};structarea girl ={0,50};structarea boy ={50,100};此时我们就划分好了区域,这时,不管是男孩还是女孩,大脑里都有了这样的一个区域:
当女孩觉得自己活动范围不够,想扩大自己的区域时,就可以调整自己认为的[start,end],划分三八线的过程,就是划分区域的过程,调整区域的过程,本质就是调整自己认为的[start,end]
其中我们将桌子认为是物理内存,男孩和女孩认为是每一个进程,而男孩和女孩本质上都认为自己有一把尺子(脑海里的尺子),这把尺子就是进程地址空间,男孩想放自己的书包、铅笔等物品时,男孩就在自己的进程地址空间再划分区域放自己的物品。
那么如何划分进程地址空间的区域呢?在Linux当中,进程地址空间本质上是一种数据结构,是多个区域的集合。
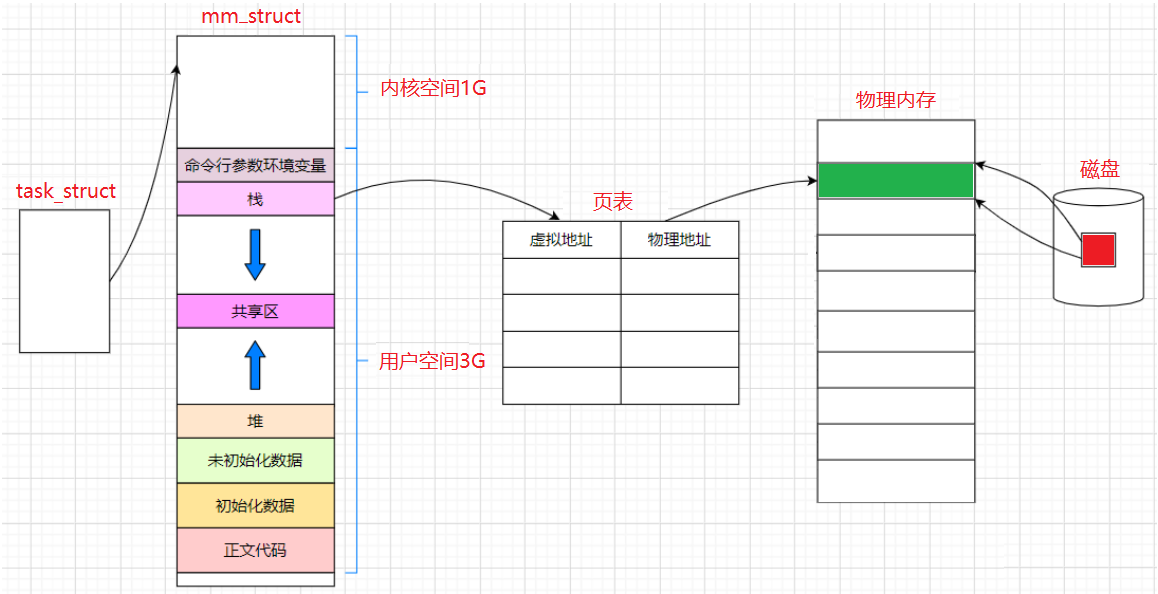
在Linux内核中,有这样一个结构体:struct mm_struct,在这个结构体去表示我们开始说的一个一个的区域呢?这样去表示:
structmm_struct{unsignedlong code_start;//代码区unsignedlong code_end;unsignedlong init_start;//初始化区unsignedlong init_end;unsignedlong uninit_start;//未初始化区unsignedlong uninit_end;unsignedlong heap_start;//堆区unsignedlong heap_end;unsignedlong stack_start;//栈区unsignedlong stack_end;//...等等}在上面的例子中,男孩脑海里有一把尺子,想着自己拥有桌子的一半,女孩脑海里也有一把尺子,想着自己也拥有桌子的一半,而此时我们改变了:男孩和女孩关系比较好,不进行什么划分三八线,男孩脑海里有一把尺子,想着自己拥有0-100cm的桌子,女孩脑海里有一把尺子,想着自己也拥有0-100cm的桌子,他们在放东西时,只要记住了尺子的刻度就可以了。
为了更深一步的理解进程地址空间,我们再来举一个例子:
比如有一个富豪,他拥有10个亿的身家,这个富豪有3个私生子,这3个私生子互相并不知道自己的存在,富豪对自己的每一个私生子都说孩子你好好工作、好好学习,好好干,老爸现在有10个亿的家产,以后就全是你的,这大饼画的666,请问在这3个私生子的视觉来看,他们认为他们有多少的家产?当然是10亿,当每个私生子向这个富豪要钱时,只要能接受,富豪肯定都会给,不能接受,富豪可以直接拒绝,在这个例子中富豪给每个私生子脑海里建立了虚拟的10个亿,此时每个私生子都认为自己有10个亿,每个人要的钱都是不一样的。
在这个例子中:富豪称之为操作系统,私生子称之为进程,富豪给私生子画的10亿家产,当前私生子的地址空间,对比言之:操作系统默认会给每个进程构成一个地址空间的概念(32位下,地址空间是从000000…0000到FFFFFF…FFF)4GB的空间,每个进程都认为自己有4GB的空间,每个进程都可以向内存申请空间,只要能接受都会给你,不能接受操作系统会直接拒绝,但是对进程来说并没有什么影响,进程依旧认为自己有4GB的空间。
再回到男孩和女孩的例子,我们的进程地址空间就相当于是那把尺子,而尺子是有刻度的,进程地址空间也是从00000000的地址到FFFFFFFF的地址,可以在这上面进行区域划分:比如代码区:[code_start,code_end],比如代码区的地址区间是这个:[0x10000,0x20000],那么区间的每一个地址单位就称为虚拟地址。
我们之前将那张布局图称为程序地址空间实际上是不准确的,那张布局图实际上应该叫做进程地址空间,进程地址空间本质上是内存中的一种内核数据结构,在Linux当中进程地址空间具体由结构体mm_struct实现。之前说"程序的地址空间"其实是不准确的,准确的应该说成"进程地址空间",概念如下:
- 每一个进程在启动的时候,都会让操作系统给它创建一个地址空间,该地址空间就是进程地址空间。每一个进程都会由一个自己的进程地址空间。操作系统需要管理这些进程地址空间,依旧是先描述,再组织。所谓的进程地址空间,其实是内核的一个数据结构(struct mm_struct )
总结:
进程地址空间本质是进程看待内存的方式,抽象出来的一个概念,内核:struct mm_struct,这样的每个进程,都认为自己独占系统内存资源(每个私生子都认为自己独占10亿家产),地址空间区域划分本质:将线性地址空间划分成为一个一个的area,[start,end]。虚拟地址本质,在[start,end]之间的各个地址叫做虚拟地址。所谓的进程地址空间,其实就是OS通过软件的方式,给进程提供一个软件视角,让其认为自己会独占系统的所有资源(内存)。
三、地址空间和物理内存的关系
在Linux内核中,每个进程都有task_struct结构体,该结构体有个指针指向一个结构mm_struct(程序地址空间),我们假设磁盘的一个程序被加载到物理内存,我们需要将虚拟地址空间和物理内存之间建立映射关系,这种映射关系是通过页表(映射表)的结构完成的(操作系统会给每一个进程构建一个页表结构)。
我们的可执行程序里面有没有地址???(在没有加载到内存的时候?)
- 可执行程序还没加载到内存的时候,内部早就已经有地址了。编译器编译你得代码的时候,就是按照虚拟地址空间的方式进行对我们的代码和数据进行编址的。这个地址是我们的程序内部使用的地址,程序加载到内存中,天然就具有一个外部的物理地址。意思就是我们有两套地址:
1、标识物理存在中代码和数据的地址的物理地址,除了栈区和堆区不会申请地址,因为它们是动态的。
2、在程序内部互相跳转的时候使用的是虚拟地址
程序是如何变成进程的?
- 程序被编译出来,没有被加载的时候,程序内部是有地址和区域的。不过这里的地址采用的是相对地址的方式,而区域实际是在磁盘上已经划分好了。加载无非就是按照区域加载到内存。
为什么先前修改一个进程时,地址是一样的,但是父子进程访问的内容却是不一样的?
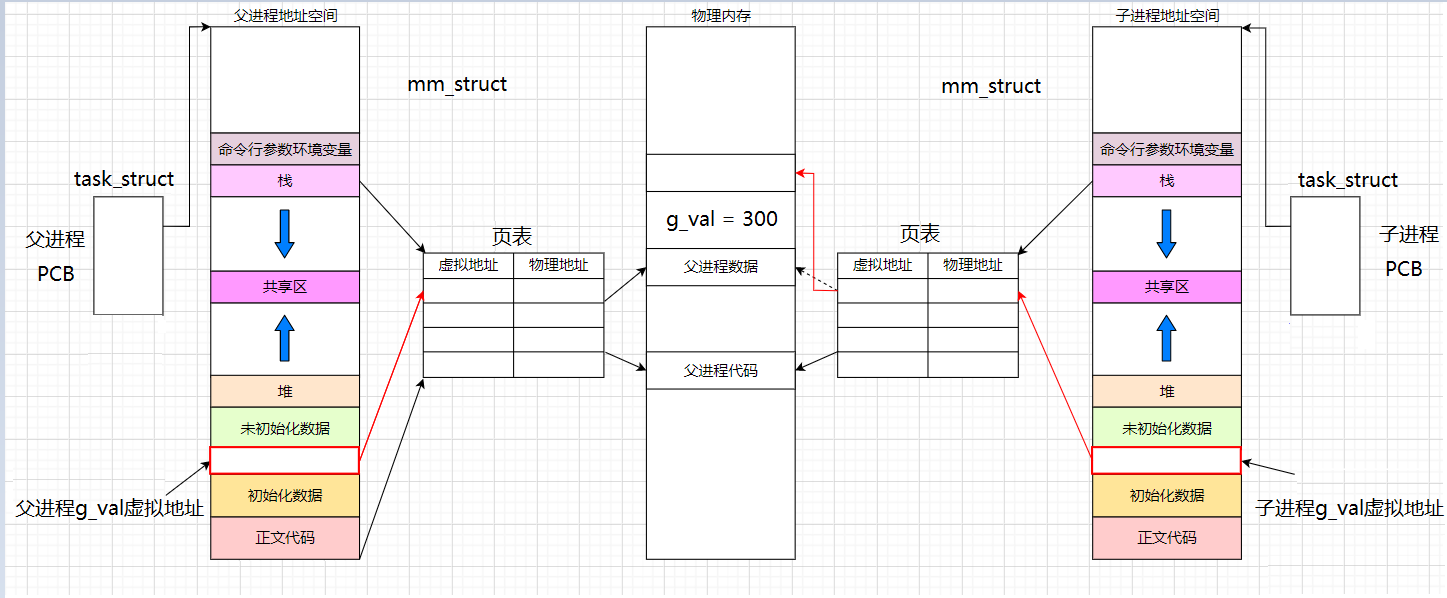
- 当父进程被创建时,有自己的task_struct和地址空间mm_struct,地址空间会通过页表映射到物理内存,当fork创建子进程的时候,也会有自己的task_struct和地址空间mm_struct,以及子进程对应的页表,如下:
- 而当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。所以先前打印的g_val的值和内容均是一样的。当子进程需要修改数据g_val时,结果就变了,先看图:
- 无论父进程还是子进程,因为进程具有独立性,如果子进程把变量g_val修改了,那么就会导致父进程识别此变量的时候出现问题,但是独立性的要求是互不影响,所以此时操作系统会给你子进程重新开辟一块空间,把先前g_val的值100拷贝下来,重新给此进程建立映射关系,所以子进程的页表就不再指向父进程的数据100了,而是指向新的100,此时把100修改为300,无论怎么修改,变动的永远都是右侧,左侧页表间的关系不变,所以最终读到的结果为子进程是300,父进程是100.
- 总结:当父子对数据修改的时候,操作系统会给修改的一方,重新开辟一段空间,并且把原始数据拷贝到新空间中,这种行为我们称之为写时拷贝。通过页表,将父子进程的数据就可以通过写时拷贝的方式,进行了分离。从而做到父子进程具有独立性的特点。
fork有两个返回值,pid_t id,同一个变量,怎么会有不同的值?
- 一般情况下,pid_t id是属于父进程的栈空间中定义的变量,fork内部,return会被执行两次,return的本质就是通过寄存器将返回值写入到接收返回值的变量中!当id = fork()的时候,谁先返回,谁就要发生写时拷贝,所以,同一个变量,会有不同的内容值,本质是因为大家的虚拟地址是一样的,但是大家对应的物理地址是不一样的。
为何fork返回之后,给父进程返回子进程pid,给子进程返回0?
- 举个例子,假如一个父亲有三个孩子,这个父亲想要抱抱其中的某个孩子,那他肯定会直呼某个孩子的名字,否则他说孩子,让爸爸抱抱,这时候三个孩子一拥而上。但是这三个孩子只有一个父亲,所以不会出错。
同一个id,怎么可能会保存两个不同的值,让 if,else if同时执行?
- 返回的本质就是写入。父子进程谁先返回不确定。谁先返回,谁就先写入id,写入就要发生写时拷贝,同一个id,地址是一样的,但是内容却不一样。

四、为什么会存在进程地址空间?
为什么进程不直接访问物理内存呢?这样不行吗?为什么要存在地址空间呢?
- 保护物理内存不受到任何进程内地址的直接访问,在虚拟地址到物理地址的转化过程中方便进行合法性校验
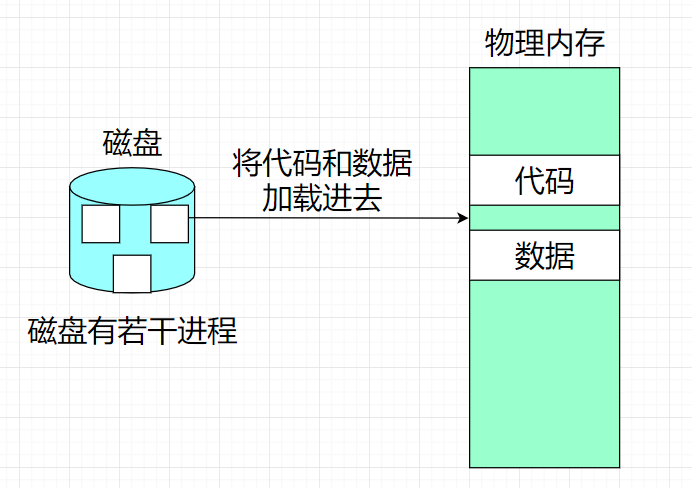
在早些时候是没有地址空间的:
如果进程直接访问物理内存,那么看到的地址就是物理地址,而语言中有指针,如果指针越界了,一个进程的指针指向了另一个进程的代码和数据,那么进程的独立性,便无法保证,因为物理内存暴露,其中就有可能有恶意程序直接通过物理地址,进行内存数据的篡改,如果里面的数据有账号密码就可以改密码,即使操作系统不让改,也可以读取。
后来就发展出来了虚拟地址空间,那么虚拟地址空间如何避免这样的问题呢?
由上面我们所了解的知识,一个进程有它的task_struct,有地址空间,有页表,页表当中有虚拟地址和物理内存的映射关系,有了页表的存在,虚拟地址到物理地址的一个转化,由操作系统来完成的,同时也可以帮系统进行合法性检测
我们在写代码的时候肯定了解过指针越界,我们知道地址空间有各个区域,那么指针越界一定会出现错误吗?
不一定,越界可能他还是在自己的合法区域。比如他本来指向的是栈区,越界后它依然指向栈区,编译器的检查机制认为这是合法的,当你指针本来指向数据区,结果指针后来指向了字符常量区,编译器就会根据mm_struct里面的start,end区间来判断你有没有越界,此时发现你越界了就会报错了,这是其中的一种检查,第二种检查为:页表因为将每个虚拟地址的区域映射到了物理内存,其实页表也有一种权限管理,当你对数据区进行映射时,数据区是可以读写的,相应的在页表中的映射关系中的权限就是可读可写,但是当你对代码区和字符常量区进行映射时,因为这两个区域是只读的,相应的在页表中的映射关系中的权限就是只读,如果你对这段区域进行了写,通过页表当中的权限管理,操作系统就直接就将这个进程干掉。
所以进程地址空间的存在也使得可以通过start和end以及页表的权限管理来判断指针是否合法访问
- 将内存管理和进程管理进行解耦
这里我们主要讲的是进程管理和内存管理:
如果没有进程地址空间,进程直接访问物理内存,当进程退出时,内存管理需要尽快将该进程回收,在这个过程当中必须得保证内存管理得知道某个进程退出了,并且内存管理也得知道某个进程开始了,这样才能给他们及时的分配资源和回收资源,这就意味着内存管理和进程管理模块是强耦合的,也就是说内存管理和进程管理关系比较大,通过我们上面的理解,如果有了进程地址空间,当一个进程需要资源的时候,通过页表映射去要就可以了,内存管理就只需要知道哪些内存区域(配置)是无效的,哪些是有效的(被页表映射的就是有效的,没有被页表映射的就是无效的),当一个进程退出时,它的映射关系也就没了,此时没有了映射关系,物理内存这里就将该进程的数据设置为无效,所以第二个好处就是将内存管理和进程管理进行解耦,内存管理是怎么知道有效还是无效的呢?比如说在一块物理内存区域设置一个计数器count,当页表中有映射到这块区域时,count就++,当一个映射去掉时,就将count–,内存管理只需要检测这个count是不是0,如果为0,说明它是没人用的。
有了进程地址空间后,每个进程都认为自己在独占内存,这样能更好的完成进程的独立性以及合理使用内存空间(当实际需要使用内存空间的时候再在内存进行开辟),并能将进程调度与内存管理进行解耦或分离。
没有进程地址空间时,内存也可以和进程进行解耦,但是代码会设计的特别复杂,所以最终会有进程地址空间
有了进程地址空间后,每个进程都认为看得到都是相同的空间范围,包括进程地址空间的构成和内部区域的划分顺序等都是相同的,这样一来我们在编写程序的时候就只需关注虚拟地址,而无需关注数据在物理内存当中实际的存储位置。
五、Linux2.6内核进程调度队列(选学)
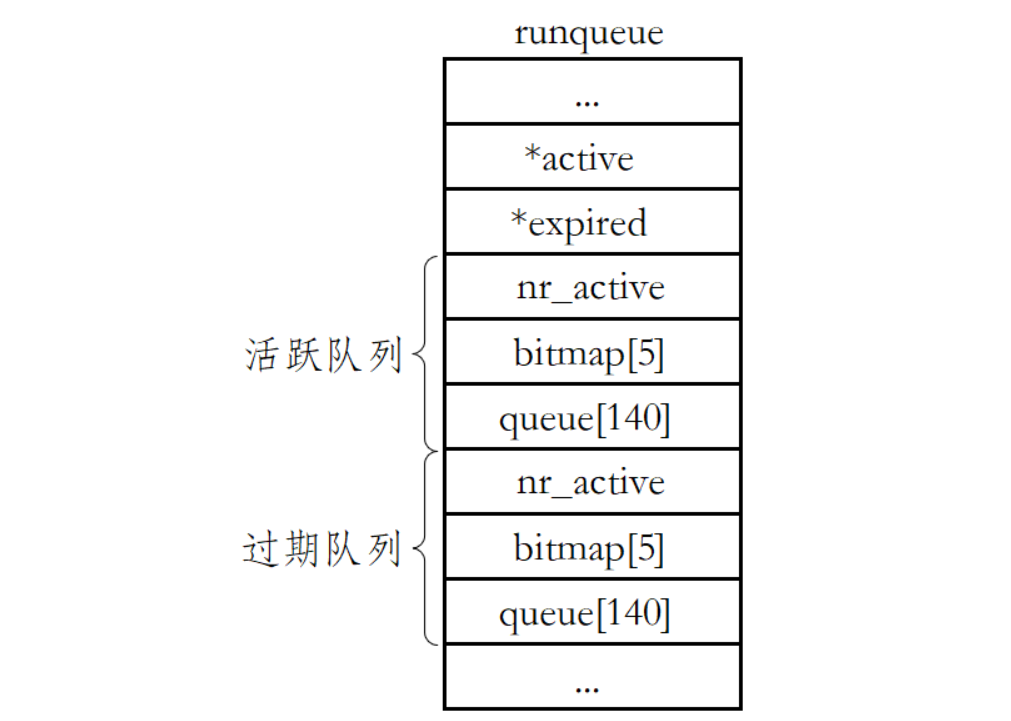
一个CPU拥有一个runqueue
如果有多个CPU就要考虑进程个数的父子均衡问题。
优先级
queue下标说明:
- 普通优先级:100~139。
- 实时优先级:0~99。
我们进程的都是普通的优先级,前面说到nice值的取值范围是-2019,共40个级别,依次对应queue当中普通优先级的下标100139。
注意: 实时优先级对应实时进程,实时进程是指先将一个进程执行完毕再执行下一个进程,现在基本不存在这种机器了,所以对于queue当中下标为0~99的元素我们不关心。
活动队列
时间片还没有结束的所有进程都按照优先级放在该队列
nr_active: 总共有多少个运行状态的进程
queue[140]: 一个元素就是一个进程队列,相同优先级的进程按照FIFO规则进行排队调度,所以,数组下标就是优先级!
从该结构中,选择一个最合适的进程,过程是怎么的呢?
- 从0下表开始遍历queue[140]
- 找到第一个非空队列,该队列必定为优先级最高的队列
- 拿到选中队列的第一个进程,开始运行,调度完成!
- 遍历queue[140]时间复杂度是常数!但还是太低效了!
bitmap[5]:一共140个优先级,一共140个进程队列,为了提高查找非空队列的效率,就可以用5*32个比特位表示队列是否为空,这样,便可以大大提高查找效率!
总结: 在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不会随着进程增多而导致时间成本增加,我们称之为进程调度的O(1)算法。
过期队列
- 过期队列和活动队列结构一模一样
- 过期队列上放置的进程,都是时间片耗尽的进程
- 当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算
active指针和expired指针
active指针永远指向活动队列。
expired指针永远指向过期队列。
可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都存在的。
没关系,在合适的时候,只要能够交换active指针和expired指针的内容,就相当于有具有了一批新的活动进程! 时间成本增加,我们称之为进程调度的O(1)算法。
参考文章:进程地址空间
版权归原作者 beyond->myself 所有, 如有侵权,请联系我们删除。