
目录
什么是MPP?
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。 MPP数据库是一款 Shared Nothing架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统
特性
并行处理
在数据库集群中,首先每个节点都有独立的磁盘存储系统和内存系统,其次业务数据根据数据库模型和应用特点划分到各个节点上,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
超大规模
每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。整个集群称为非共享数据库集群,非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
数据仓库真正适合什么
典型的分析工作量
MPP数据库非常擅长最常见的分析工作负载,这些工作负载通常以对子集的查询为特征,并在广泛的行范围内进行汇总。这是由于它们的列式体系结构允许他们仅访问完成查询所需的字段(与事务性数据库相反,事务性数据库必须连续访问所有字段)。 列式体系结构还为MPP数据库提供了对分析工作负载有用的其他功能。这些功能因数据库而异,但通常包括压缩类似数据值,有效索引非常大的表以及处理宽的非规范化表的功能。
数据集中化
组织通常使用分析型MPP数据库作为数据仓库或集中式存储库,其中包含组织内部生成的所有数据,例如交易销售数据,Web跟踪数据,营销数据,客户服务数据,库存/后勤数据,人力资源/招聘数据以及系统日志数据。由于分析MPP数据库可以处理大量数据,因此组织可以轻松地依靠这些数据库来存储数据,还可以支持来自这些各种业务功能的分析工作负载。
线性可伸缩性
通过向系统添加更多服务器,分析MPP数据库可以轻松地线性扩展其计算和存储功能。这与垂直扩展计算和存储功能相反,后者涉及升级到更大,功能更强大的单个服务器,并且通常会在规模上遇到障碍。分析型MPP数据库能够如此快速,轻松和高效地进行横向扩展,以使按需数据库供应商能够根据查询的大小自动执行该过程来按比例放大或缩小系统。
MPP架构技术特性
MPP 具备以下技术特征:
- 相对低的硬件成本:完全使用 x86 架构的 PC Server,不需要昂贵的Unix 服务器和磁盘阵列;
- 集群架构与部署:完全并行的 MPP + Shared Nothing 的分布式架构,采用 Non-Master 部署,节点对等的扁平结构;
- 海量数据分布压缩存储:可处理 PB 级别以上的结构化数据,采用 hash分布、random 存储策略进行数据存储;同时采用先进的压缩算法,减少存储数据所需的空间,可以将所用空间减少 1~20 倍,并相应地提高 I/O 性能;
- 数据加载高效性:基于策略的数据加载模式,集群整体加载速度可达2TB/h;
- 高扩展、高可靠:支持集群节点的扩容和缩容,支持全量、增量的备份/恢复;
- 高可用、易维护:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作;
- 高并发:读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300 用户;
- 行列混合存储:提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时;
- 标准化:支持SQL92 标准,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
数据库架构分析
数据库构架设计中主要有Shared Everything、Shared Disk、Share Memory和Shared Nothing等,我们简要分析一下这几种架构的区别。
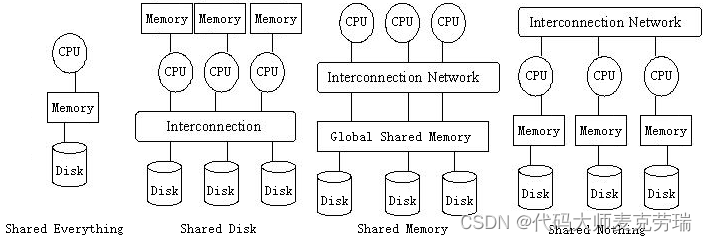
Shared Everything
Shared Everything指单个主机独立支配CPU、内存、磁盘等硬件资源,其优势是架构简单,搭建方便。但该种架构的缺陷是数据并行处理能力较差,扩展性较低。Shared Everything的典型代表的产品为SQLserver。
Shared Disk
在Shared Disk架构中,CPU和内存对于各个处理单元私有,但各节点共享磁盘系统。该种架构的典型代表为DB2 pureScale和Oracle Rac。这种共享架构具备一定的扩展能力,可通过节点的增加来提升数据并行处理能力。但当存储器接口使用饱和时,磁盘IO成为了系统资源瓶颈,节点的扩充并不能提升系统性能。
Share Memory
Shared Memory指多个节点共享内存,各CPU间通过内部通讯网络(Interconnection network)进行通讯。但与Shared Disk类似,但当节点数量过高时,内存竞争(Memory contention)将成为该系统的瓶颈,单纯地堆砌节点数量并不能提升整体数据处理性能。
Shared Nothing
Shared Nothing的核心思想是各个数据库单元中不存在共享资源,数据处理单元对于各节点完全私有化。早在1986年加州大学伯克利分校的论文中,Michael Stonebraker从当时的数仓原型中对比了Shared Disk,Shared Memory,Shared Nothing架构,并论证了Shared Nothing在数据并行处理中的优势。各单元通过通信协议层交互,处理后的数据会逐步向上层汇总或通过通信层流转于节点间。Teradata公司在1982年申请了YNET技术专利,为无共享的大规模数据并行处理(Massive Parallel Processing)提供了先决基础。在TD数仓架构中,各节点单元通过MPL(Message Passing Layer)的BYNET物理层实现。BYNET是一个双冗余、全双工的网络,以松耦合方式将多个数据处理节点与处理引擎(Parsing Engine)高速连接起来。G行的多元化大数据平台中的TD集群正是采取该架构设计。
Shared Nothing数据库架构优势
1)
大数据分析需求传统数据库无法支持大规模集群与 PB 级别数据量,且性能受限、扩展性受限,MPP架构数据支持大规模集群以及PB级别数据,性能根据扩展节点性能呈线性关系2)
软硬件一体机成本高昂、扩展受限高性能单机服务器的成本十分高昂,生产扩容、测试、开发、容灾都需新购同型号一体机(机柜),并且跨代兼容性问题目前也没有得到很好的解决。MPP架构数据库可根据需要无限扩展。3)
In-memory 技术太贵而且不成熟内存成本过高,TB 级别以下,不适合大数据量;MPP架构成本可控,对于TB级数据支持优秀,很适合大数据量。4)
Hadoop 技术的先天不足Hive 等 sql-on-hadoop 性能太慢,SQL 兼容性与支持不足,数据安全性无法保证。MPP架构数据库支持通用标准SQL,数据可冗余备份,具有高可用,高安全性。
版权归原作者 代码大师麦克劳瑞 所有, 如有侵权,请联系我们删除。