
提示:hadoop完全分布式的搭建与伪分布式搭建的准备工作是非常相似的,如果不会不会伪分布式搭建,可以去看看我发布的hadoop伪分布式搭建.
注意:前面有 # 的代表注解,可以不写
一、集群规划
这里我们以四个节点为例,其他节点数没原理都一样:
ndoe1node2node3node4HDFSNameNodeSecondaryNameNodeHDFSDataNodeDataNodeDataNodeDataNodeYARNResourceMAnagerYARNNodeManagerNodeManagerNodeManagerNodeManager
SecondaryNameNode的作用之一: NameNode节点意外宕机之后,帮助NameNode快速重启用的,
所以SecondaryNameNode进程不建议与NameNode进程放到同一节点中.
二、环境准备 (hadoop3x,jdk1.8)
- hadoop完全分布式搭建的方式有很多种,这里我们以克隆的方式搭建(如果你想问为什么用克隆,因为克隆是最快的,他只需要搭建好一个节点,其他的节点改一些文件就文件就可以了)
.
- 我们先准备一个伪分布式节点.
提示:在准备伪分布式的时候,我们先不用修改hadoop的配置文件,当然配置了也没关系.我们在搭建完全分布式的时候还需要重新修改配置文件,所有在前面就不要多此一举了
三、修改配置文件
- 进入到hadoop的配置文件目录:
#注意我们每个人存放的路径可能存在差异
cd ~/modules/hadoop-3.3.0/etc/hadoop/
- 修改配置文件,通常修改core,hdfs,mapred,yarn -site.xml文件
hadoop-env.sh
vim hadoop-env.sh
#打开原 hadoop-env.sh 文件,修改 JAVA_HOME
#默认是${JAVA_HOME},读取可能会出问题,直接改成绝对路径 export JAVA_HOME=/home/bduser/modules/jdk1.8
mapred-env.sh
vim mapred-env.sh
#打开原 mapred-env.sh 文件,修改 JAVA_HOME
#默认是${JAVA_HOME},读取可能会出问题,直接改成绝对路径 export JAVA_HOME=/home/bduser/modules/jdk1.8
yarn-env.sh
vim yarn-env.sh
#打开原 mapred-env.sh 文件,修改 JAVA_HOME
#默认是${JAVA_HOME},读取可能会出问题,直接改成绝对路径 export JAVA_HOME=/home/bduser/modules/jdk1.8
core-site.xml
vim core-site.xml
#在文件中添加以下内容
<configuration></configuration><!-- hdfs的集群访问路径 --> <property> <name>fs.default.name</name> <value>hdfs://node1:9820</value> </property> </property> <!-- 【可选配置套项(二)】对外界使用bduser的代理账户访问权限进行把控 --> <!-- 配置该bduser(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.bduser.hosts</name> <value>*</value> </property> <!-- 配置该bduser(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.bduser.groups</name> <value>*</value> </property> <!-- 配置该bduser(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.bduser.users</name> <value>*</value> </property>
hdfs-site.xml
<configuration> <property> <name>dfs.namenode.http-address</name> <value>node101:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node104:9868</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>dfs.namenode.http-address</name> <value>node1:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node4:9868</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/xcj/modules/hadoop-3.3.0/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/xcj/modules/hadoop-3.3.0/dfs/data</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/home/xcj/modules/hadoop-3.3.0/dfs/secondaryName</value> </property> </configuration>
yarn-site.cml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property><property> <name>yarn.nodemanager.env-whitelist</name><!-- 环境变量的继承,让Yarn能够识别常用环境变量地址,防止出错 --><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DI
R,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</va
<property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property>
lue>
</property>Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, software
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property>
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--></configuration><!-- 环境变量的继承,让Yarn能够识别常用环境变量地址,防止出错 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR, CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 【可选配置套项(一)】容器优化配置 --> <!-- 为每个容器请求分配的最小内存限制资源管理器(512M) --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <!-- 为每个容器请求分配的最大内存限制资源管理器(2G) --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- 虚拟内存比例,默认为2.1,此处设置为4倍 --> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> <!-- 【可选配置单项(二)】物理内存管理优化配置 --> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <!-- 【可选配置套项(三)】取消容量限制检查优化配置 --> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property><!-- 除Yarn外,也可以在MapReduce中配置专属的环境变量的配置识别继承,防止报错 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/xcj/modules/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/xcj/modules/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/bduser/modules/hadoop-3.3.0</value>
</property>
</configuration>
workers
命令: vim workers
node1
node2
node3
node4
配置文件改好后,开始克隆(克隆的时候要将虚拟机关掉)
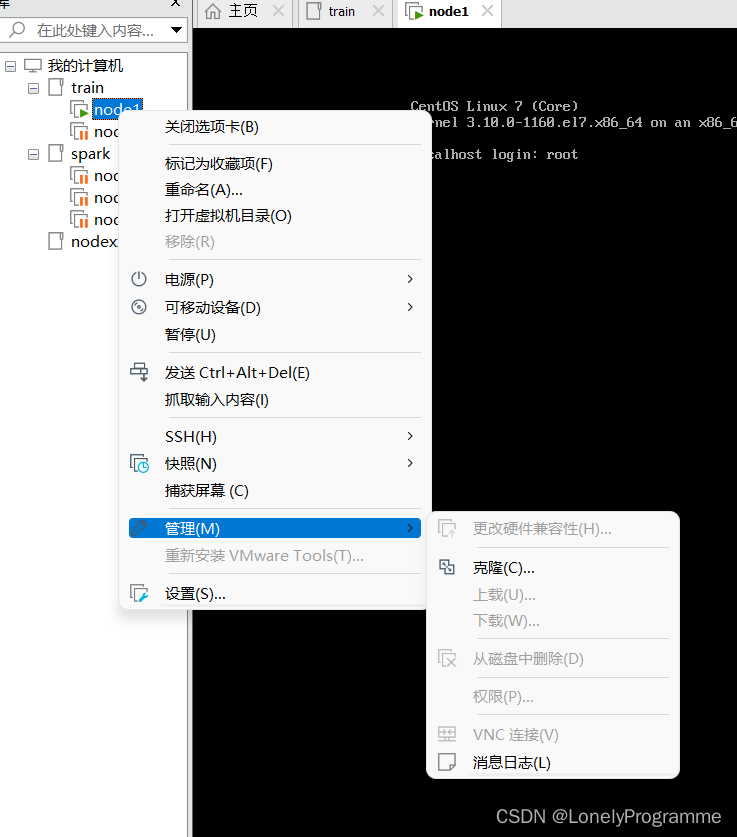

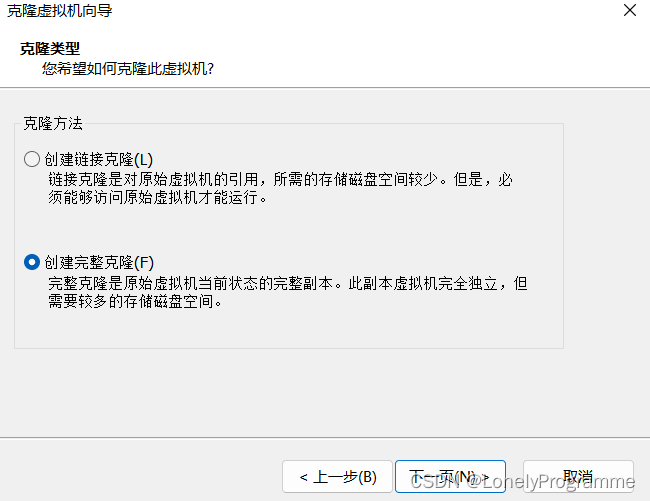
克隆完成以后,修改修改ip地址与名称
#root权限
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#修改IPADDR,修改完成后重启网卡
IPADDR="个人ip地址"
systemctl restart network
#修改名称
vim /etc/hostname
节点名称
修改完成之后刷新配置文件:
命令 : source /etc/hostname
如果没用就关机重启.
#初始化
hdfs namenode -format
#开启进程
start-all.sh
#在每个节点是输入jps命令
jps
#在node1节点是有以下进程
[xcj@node1 ~]$ jps
22705 DataNode
23858 NodeManager
24853 Jps
23654 ResourceManager
22492 NameNode#在node2节点有以下进程
[xcj@node2 ~]$ jps
7097 Jps
5662 DataNode
6335 NodeManage#在node3节点有以下进程
[xcj@node3 ~]$ jps
7360 DataNode
8218 NodeManager
9422 Jps#在node4节点有以下进程
[xcj@node5 ~]$ jps
9539 Jps
7620 SecondaryNameNode
7239 DataNode
8174 NodeManager
如果以上进程你都有,恭喜你太棒了,你的环境搭建完成了.
版权归原作者 LonelyProgramme 所有, 如有侵权,请联系我们删除。