
课程地址:Python 工程师进阶技术图谱
文章目录
类Flask框架请求封装
Web服务器
- 本质是个TCP服务器,监听在特定端口上
- 支持HTTP协议,能够将HTTP请求报文进行解析,能够把响应数据进行HTTP协议的报文封装并返回浏览器端。
APP程序内部也可以请求其它Server,此时就是代理作用。总之,app里面就可以实现各种复杂的功能,只要最后满足WSGI的要求就行。
上一节中实现的app,不论收到什么反馈,都产生一样的响应,这一节将尝试对请求进行解析。
HTTP请求解析的python实现
1、解析查询字符串
查询字符串
- 例
?name=tom&id=1000,不同的参数之间使用&分隔开。
代码:
from wsgiref.simple_server import make_server
defsimple_app(environ:dict, start_response):# 读取“请求方法”和“查询字符串”,并提前查询字符串中的信息
method = environ.get('REQUEST_METHOD')print(method)
query_string = environ.get('QUERY_STRING')print(query_string)# 解析查询字符串
d ={}for item in query_string.split('&'):
k,_,v = item.partition('=')
d[k]= v
print(d)
status ='200 OK'
headers =[('Content-type','text/plain; charset=utf-8')]
start_response(status, headers)
ret =[query_string.encode('utf-8')]return ret # 报文的正文部分,即网页内容with make_server('0.0.0.0',9000, simple_app)as httpd:print("Serving on port 9000...")try:
httpd.serve_forever()except Exception as e:print(e)except KeyboardInterrupt:print('stop')
httpd.server_close()
然后使用我Edge的Postwoman工具发起一个GET请求,url为
http://127.0.0.1:9000/?name=tom&id=1000
。
程序在python端就输出解析的查询字符串(第三行),我们将它解析成了一个字典
'''
GET
name=tom&id=1000&age=20
{'name': 'tom', 'id': '1000'}
'''
对于解析查询字符串的一段代码也可以使用下面两种写法,更加简单(行数更少,但感觉可读性不太好):
d ={k:v for k, _, v inmap(lambda x:x.partition('='), query_string.split('&'))}
d ={k:v for k, _, v in[item.partition('=')for item in query_string.split('&')]}
或者使用库:
from urllib.parse import parse_qs
qs = parse_qs(query_string)
改用库后,再次发起请求,python端输出解析后的字典:
'''
{'name': ['tom'], 'id': ['1000']}
'''
2、多值问题
此时字典中的value值变成了一个列表,这是因为在url中可以对一个参数传入多值,例如将我们请求的url改成
http://127.0.0.1:9000/?name=tom&id=1000&id=666
,python端的输出将变成:
{'name':['tom'],'id':['1000','666']}
使用webob库解析请求
前面,我们获取请求的信息还需要记下信息的名称
method = environ.get('REQUEST_METHOD')
这显然十分麻烦。而使用webob库,我们可以通过对象的属性来访问请求的信息,只需将
environ
参数传给webob库中的Request对象,就可以自动实现解析。代码如下:
from wsgiref.simple_server import make_server
from webob import Request
defsimple_app(environ:dict, start_response):
request = Request(environ)
query_string = request.query_string
methon = request.method
print('methon, query_string: ', methon, query_string)print('request: ', request.GET)# 来自查询字符串的参数print('type(request.GET): ',type(request.GET))# dictprint('request.POST: ', request.POST)# 来自POST的参数print('request.params: ', request.params)# 所有的参数,包含url的查询字符串,和POST的正文print('request.path: ', request.path)print('request.headers: ', request.headers)# 请求头
status ='200 OK'
headers =[('Content-type','text/plain; charset=utf-8')]
start_response(status, headers)
ret =[query_string.encode('utf-8')]return ret # 报文的正文部分,即网页内容with make_server('0.0.0.0',9000, simple_app)as httpd:print("Serving on port 9000...")try:
httpd.serve_forever()except Exception as e:print(e)except KeyboardInterrupt:print('stop')
httpd.server_close()
我使用Postwoman测试工具发送了一个POST请求,它url的查询字符串中有参数,POST也传输了一个参数
age
:
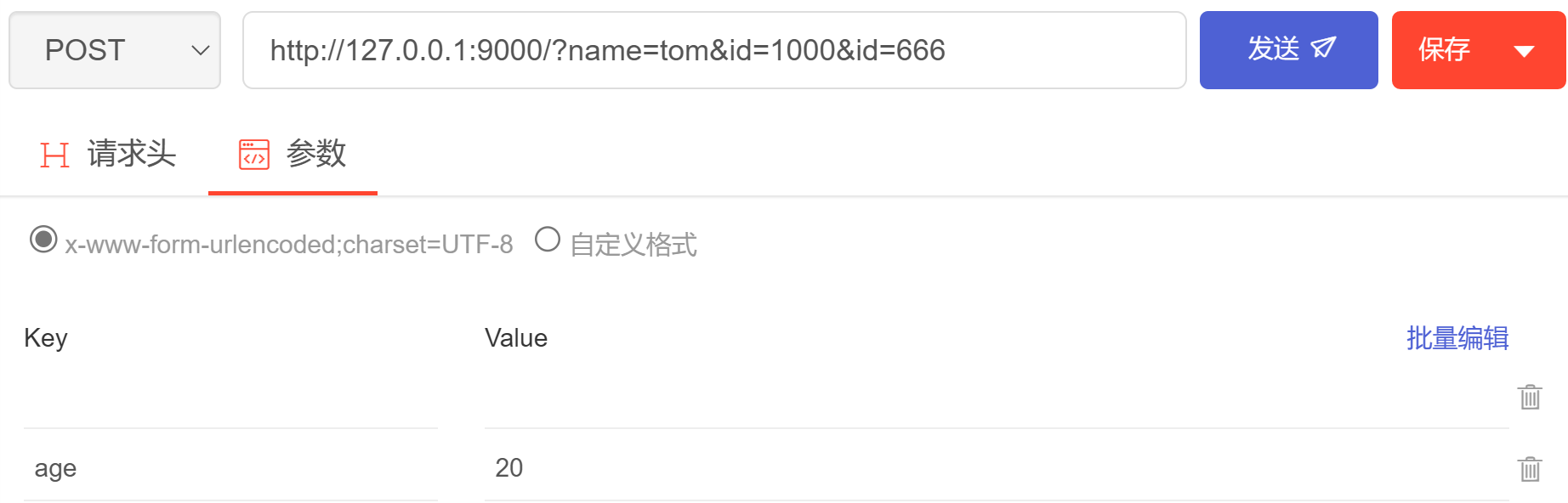
下面是python端的输出
'''
Serving on port 9000...
methon, query_string: POST name=tom&id=1000&id=666
request: GET([('name', 'tom'), ('id', '1000'), ('id', '666')])
type(request.GET): <class 'webob.multidict.GetDict'>
request.POST: MultiDict([('age', '20')])
request.params: NestedMultiDict([('name', 'tom'), ('id', '1000'), ('id', '666'), ('age', '20')])
request.path: /
request.headers: <webob.headers.EnvironHeaders object at 0x000002A24D1D1F00>
'''
Bug记录
bug:AttributeError: module ‘cgi’ has no attribute ‘parse_qs’
错误代码如下
from cgi import parse_qs
qs = parse_qs(query_string)
点进cgi的库查找parse_qs,发现了下面这段代码:
if sys.version_info <(3,8):defparse_qs(qs:str, keep_blank_values:bool=..., strict_parsing:bool=...)->dict[str,list[str]]:...defparse_qsl(qs:str, keep_blank_values:bool=..., strict_parsing:bool=...)->list[tuple[str,str]]:...if sys.version_info >=(3,7):defparse_multipart(
fp: IO[Any], pdict: SupportsGetItem[str,bytes], encoding:str=..., errors:str=..., separator:str=...)->dict[str,list[Any]]:...
显然,当
s
y
s
.
v
e
r
s
i
o
n
_
i
n
f
o
>
=
(
3
,
8
)
sys.version\_info >= (3, 8)
sys.version_info>=(3,8)的时候,函数
parse_qs
是不会被定义的。应该是python版本的问题,我换成python3.7版本时,就可以正常运行了。
其实,
cgi
库已经过期了,使用
urllib
库就好。
本文转载自: https://blog.csdn.net/m0_63238256/article/details/128886296
版权归原作者 清风莫追 所有, 如有侵权,请联系我们删除。
版权归原作者 清风莫追 所有, 如有侵权,请联系我们删除。