
对于个人开发者而言,一般手头上没有多台服务器,有人可能会有云服务器,不过一般也只会买一台来用用就好;有人可能更习惯将本机当作服务器来玩。都可以。那么如何通过一台服务器或本机来搭建Kafka集群呢?
无外乎两种方式,一是通过docker来搭建,每台kafka broker用不同的端口来启动,即可组成集群;二是通过虚拟机来搭建,即用VMware在服务器或本机上启动多台虚拟机,每台虚拟机都安装一个kafka broker。笔者采用的是第一种方式。
1、环境说明及架构说明
Linux系统:centos 8
Zookeeper:wurstmeister/zookeeper
Kafka:wurstmeister/kafka
如下图,笔者准备搭建一台Zookeeper以及三个Kafka broker组成的Kafka Cluster。

2、docker搭建Zookeeper
(1)查看镜像
首先用docker search命令来查找docker上有哪些可用的Zookeeper镜像。
docker search zookeeper
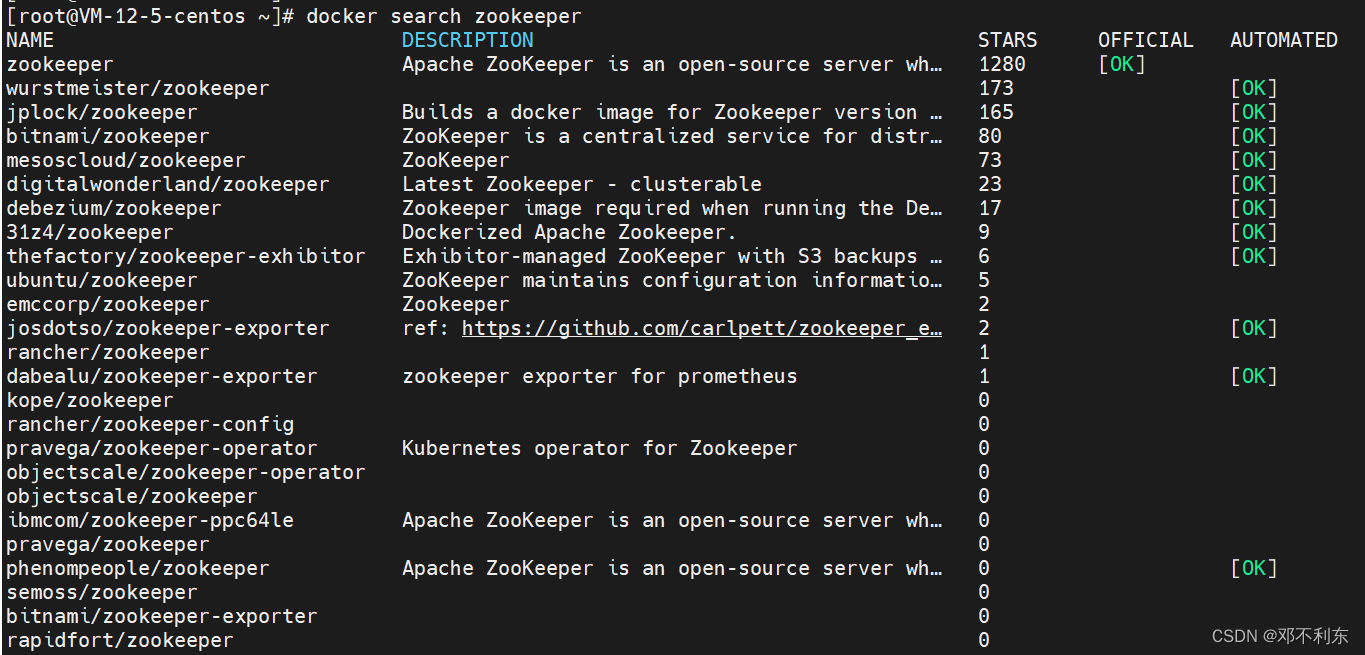
照理说,镜像最好选择官方镜像,也就是上图中的第一个。但是笔者这里选择第二个镜像wurstmeister/zookeeper,那是因为我发现用docker查找Kafka的镜像时是没有官方镜像的,而Kafka镜像中排在第一的也是以wurstmeister为开头的。也就是说,这两个镜像是出自同一家机构或个人的。
(2)拉取镜像
然后拉取镜像,默认拉取最新版本的。
docker pull wurstmeister/zookeeper
(3)启动镜像
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper

3、docker搭建Kafka Cluster
启动好了Zookeeper服务之后,来开始搭建Kafka Cluster了。
(1)查找镜像
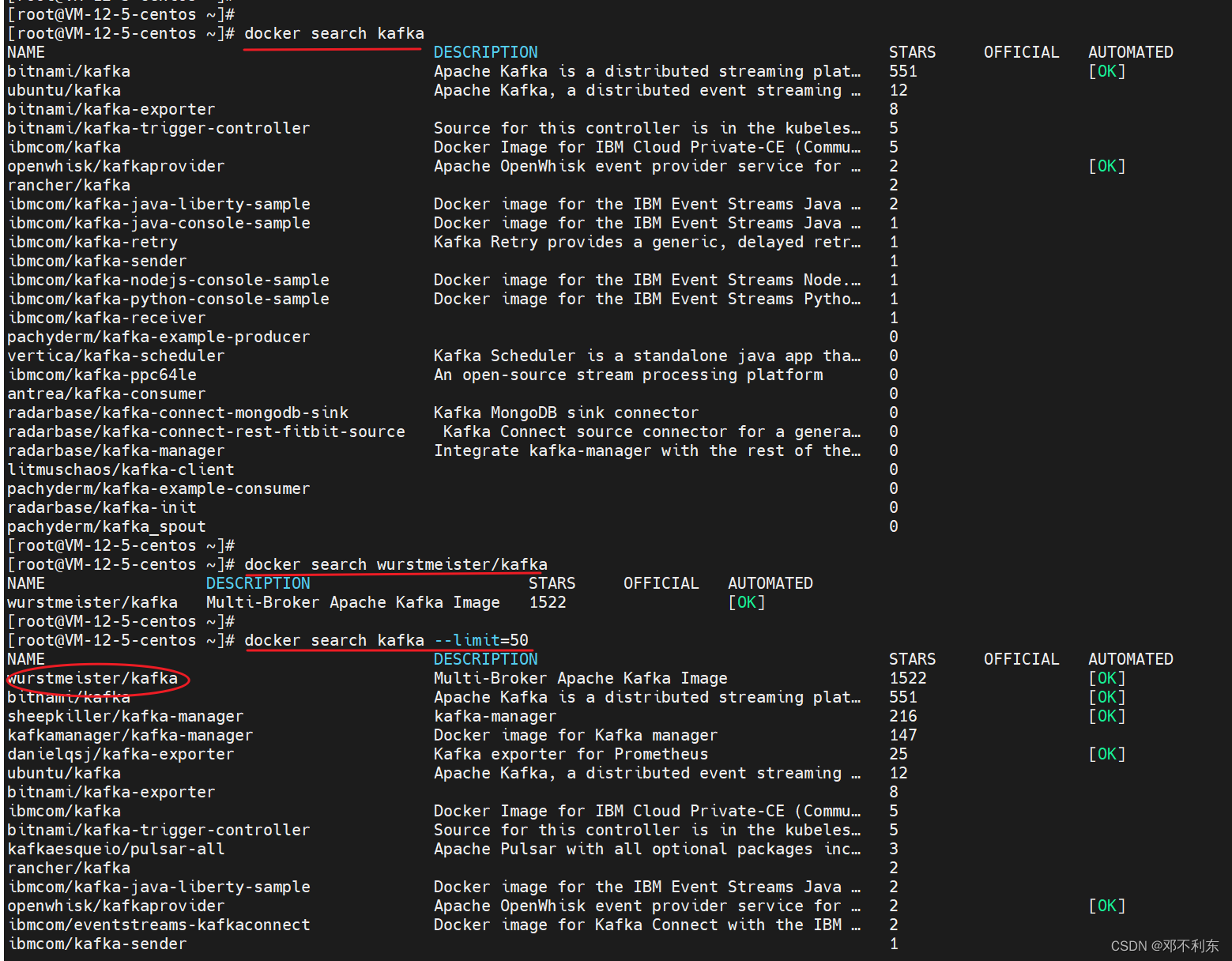
同样用docker search命令来查找Kafka的镜像,这里有个小插曲,笔者发现个问题。
直接用docker search查找,结果集中并未有wurstmeister/kafka,而用
docker search kafka --limit=50
这条命令查找,结果集的第一条就是wurstmeister/kafka,且收藏数最多。也就是说,docker search这条命令返回的结果集在默认情况下是有条数限制的。但奇怪的是,就算有条数限制,为什么不按照收藏量(STARS)优先返回镜像的结果集呢?这个疑惑暂且放下,知道的同学麻烦在评论区告知一下哈。
(2)拉取镜像
docker pull wurstmeister/kafka

(3)启动三个broker
命名为:kafka0 端口:9092 brokerId: 0
docker run -d --name kafka0 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=xxx:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://xxx:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
命名为:kafka1 端口:9093 brokerId: 1
docker run -d --name kafka1 -p 9093:9093 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=xxx:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://xxx:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 -t wurstmeister/kafka
命名为:kafka2 端口:9094 brokerId: 2
docker run -d --name kafka2 -p 9094:9094 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=xxx:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://xxx:9094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 -t wurstmeister/kafka
【Attention:以上三条命令中的xxx用自己的服务器ip替换】
执行上面三条命令后,分别在9092 / 9093 / 9094三个端口启动了kafka broker,执行docker ps查看结果。
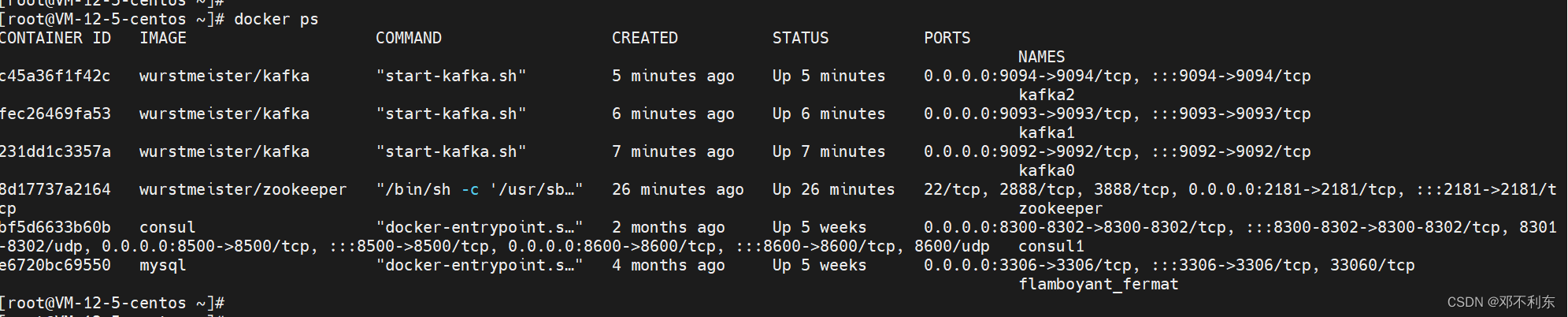 至此,三个broker节点的Kafka集群搭建完成。
至此,三个broker节点的Kafka集群搭建完成。
(4)小插曲:kafka启动失败
笔者一开始在启动kafka的时候,一直启动失败。报错如下:
kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING
大概翻译过来就是kafka服务在启动的时候连接Zookeeper服务超时,说白了,就是连不上。
btw,如果容器没起来的话,无法通过docker exec进入容器查看容器日志,此时可以用
docker logs 容器id 查看docker容器的日志(注意是容器id,并不是镜像id)。
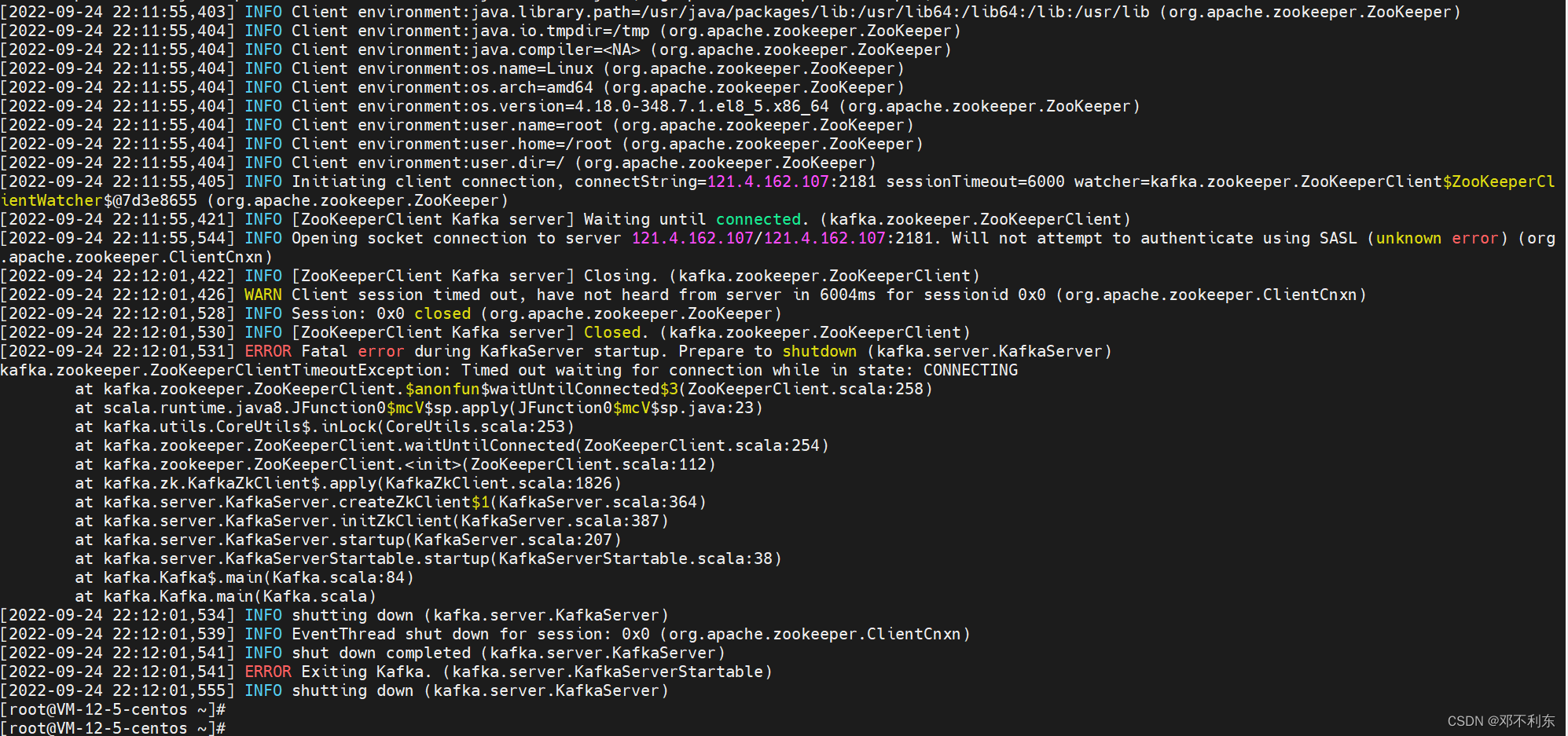
笔者在这个问题上搞了将近一个小时,才想起来是云服务器的网络安全组的规则忘记配置了。
于是立马登上云服务器配置了一下,然后kafka就能启动成功了。
4、效果测试
执行docker exec命令随意进入一个broker的容器内,再进入opt目录。
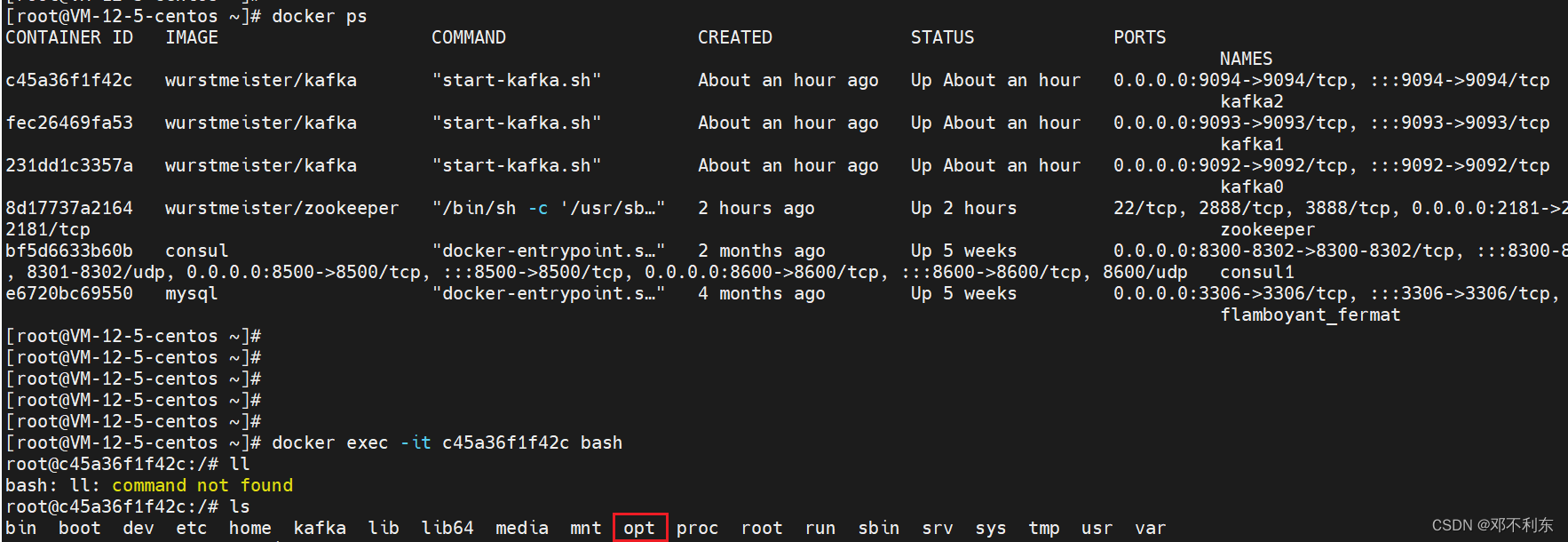
进入opt目录后发现有两个kafka,对比了一下,两个kafka目录差不多,都有bin下的各种可执行脚本,都有config下的各种properties配置文件。这里,笔者选择了kafka_2.13-2.8.1目录。

笔者创建了一个名为 topic-demo 的主题,该主题有3个分区,3个副本因子。
从 describe 命令可以看到3个分区均匀地分布在三个broker中。可见,这三个broker已经成功地组成了Kafka集群了。

执行操作主题等相关命令,可参考:Kafka学习——梳理bin目录下各个脚本的用法(五)
版权归原作者 邓不利东 所有, 如有侵权,请联系我们删除。