
一、题目背景和意义 二、国内外研究现状 (略)
三、MIPS指令集处理器设计与实现
(一).MIPS指令集功能性梳理
1.MIPS指令集架构
(1).mips基础指令集格式总结
MIPS是(Microcomputer without interlocked pipeline stages)[10]的缩写,含义是无互锁流水级微处理器。MIPS 是最早、最成功的RISC处理器之一[11],源于Stanford 大学的John Hennessy 教授的研究成果。(Hennessy 于1984年在硅谷创建了MIPS公司)。MIPS的指令系统经过通用处理器指令体系MIPS I、 MIPS II、MIPS III、MIPS IV到MIPS V,嵌入式指令体系MIPS16、MIPS32到MIPS64的发展 已经十分成熟。应用广泛的32位MIPS CPU包括R2000,R3000 其ISA都是MIPS I,另一个广泛使用的、含有许多 重要改进的64位MIPS CPU R4000及其后续产品,其ISA版本为MIPS III。MIPS指令集编码规范。要完成一个完整最小系统的搭建,首先应参考MIPS官方文档[12],将要实现的指令从功能角度、数据通路角度、编码角度归类。功能角度分类,目的是为了方便对指令类别进行归类梳理,对设计勾勒出框架性思维;从数据通路角度归类,是为了方便控制单元的编程设计,如“ADD、SUB、AND、OR...”等指令只是ALU工作方式码不同,数据通路完全一致。而从编码角度分类,是为了方便处理器的HDL编程设计,将同一类指令归在一个代码块下,避免代码长度过于冗余。从功能角度看,MIPS32基础指令分为算术运算指令、逻辑运算指令、访存指令、转移指令、分支指令和跳转指令。其中,分支指令和跳转指令不是同一类指令:MIPS 体系架构的跳转、分支和子程序调用指令沿用了 Motorola标准的命名规则[17]:
a.PC 相对地址跳转指令称为“分支”,绝对地址跳转指令称为“跳转”,相应的助记符分别以 b(branch) 和 j (jump)开头。
b.子程序调用称为 “跳转并链接” 或 “分支并链接”,相应的助记符以 al 结尾。
MIPS 32位处理器的指令格式分为Reg型(寄存器型)、Imm型(立即数型)和Jump型(跳转型)。R型为寄存器型,即两个源操作数和目的操作数都是寄存器性。I型为操作数含有立即数。而J型特指转移类型指令,如下表1所示。
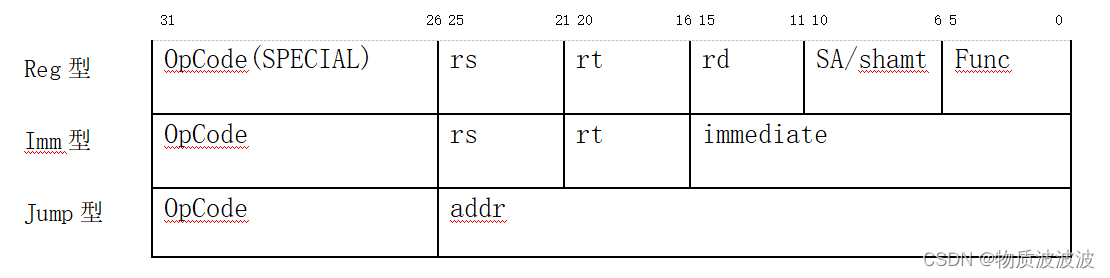
表1 MIPS指令类型[13]
基本MIPS 指令集(共52条)助记符指令编码格式操作及其解释Bit #31..2625..2120..1615..1110..65..0Reg-typeOprsrtrdshamtfuncadd0rsrtrd0100000ADD rd, rs, rtrd←rs + rtaddu0rsrtrd0100001ADDU rd, rs, rtrd←rs + rt(unsigned)sub0rsrtrd0100010SUB rd, rs, rtrd←rs - rtsubu0rsrtrd0100011SUB rd, rs, rtrd←rs - rt(unsigned)and0rsrtrd0100100AND rd, rs, rtrd←rs and rtor0rsrtrd0100101OR rd, rs, rtrd←rs or rtxor0rsrtrd0100110XOR rd, rs, rtrd←rs xor rtnor0rsrtrd0100111NOR rd, rs, rtrd←rs nor rtslt0rsrtrd0101010SLT rd, rs, rtrd ← (rs < rt)sltu0rsrtrd0101011SLTU rd, rs, rtrd ← (rs < rt)sll00rtrdshamt0SLL rd, rs, rtrd ← rt << sasrl00rtrdshamt10SRL rd, rs, rtrd ← rt >> sasra00rtrdshamt11SRA rd, rs, rtrd← rt>>sa(arithmetic)sllv0rsrtrd0100SLLV rd, rs, rtrd ← rt << rssrlv0rsrtrd0110SRLV rd, rs, rtrd ← rt >> sasrav0rsrtrd0111SRAV rd, rs, rtrd← rt>>sa(arithmetic)jr0rs0001000JR rsPC ← rsclo11100rsrtrd0100001CLO rd, rs, rtrd← count_leading_ones rsclz11100rsrtrd0100000CLZ rd, rs, rtrd←count_leading_zeros rsmult0rsrt0011000MULT rs, rt(HI, LO) ← rs × rtmultu0rsrt0011001MULTU rs, rt(HI, LO) ← rs × rtmul11100rsrtrd010MUL rd, rs, rtrd ← rs × rtdiv0rsrt0011010DIV rs, rt (HI, LO) ← rs / rtdivu0rsrt0011011DIV rs, rt(HI, LO) ← rs / rtjalr0rs0rd01001JALR rd, rsrd ← return_addr,PC ← rsmovn0rsrtrd01011MOVN rd, rs, rtif rt ≠ 0 then rd ← rsmovz0rsrtrd01010MOVZ rd, rs, rtif rt = 0 then rd ← rsmflo000rd010010MFLO rdrd ← LOmfhi000rd010000MFHI rdrd ← HImtlo0rs00010011MTLO rsLO ← rsmthi0rs00010001MTHI rsHI ← rsnop000000NOPTo perform no operationImm-typeoprsrt immediateaddi1000rsrtimmediateADDI rt,rs,immediatert ← rs + immediateaddiu1001rsrtimmediateADDIU rt,rs,immediatert ← rs + immediateandi1100rsrtimmediateANDI rt,rs,immediatert ← rs and immediateori1101rsrtimmediateORI rt,rs,immediatert ← rs or immediatexori1110rsrtimmediateXORI rt,rs,immediatert ← rs xor immediatelui11110rtimmediateLUI rt, immediatert ← immediate || 0000Hlw100011rsrtimmediateLW rt,rs,immediatert←memory[pc+offset]sw101011rsrtimmediateSW rt,rs,immediatememory[pc+offset]←rtbeq100rsrtoffsetBEQ rs, rt, offsetif rs = rt then branchbne101rsrtoffsetBNE rs, rt, offsetif rs ≠ rt then branchslti1010rsrtimmediateSLTI rt,rs,immediatert ← (rs < immediate)sltiu1011rsrtimmediateSLTI rt,rs,immediatert ← (rs < immediate)bgez1rs1offsetBGEZ rs, offsetif rs ≥ 0 then branchbgtz111rs0offsetBGTZ rs, offsetif rs > 0 then branchblez110rs0offsetBLEZ rs, offsetif rs ≤ 0 then branchbltz1rs0offsetBLTZ rs, offsetif rs < 0 then branchbgezal1rs11offsetBGEZAL rs, offsetIf rs≥0 then callbltzal1rs10offsetBLTZAL rs, offsetif rs< 0 then callJump-typeopaddressj10addressJ targetPC←PCGPRLEN-1..28|| instr_index||00jal11addressJAL targetPC ←PCGPRLEN-1..28|| instr_index||00,GPR[31]← PC + 8
表2 MIPS指令编码分类[14]
(2).mips通用寄存器协议总结

表3 通用寄存器用途协议[15]
MIPS体系结构下的寄存器都是32位字长。且其为RISC系统结构,特点为寄存器很多,以减少访存指令的执行频率。0--31共32个寄存器,对应地址为五位通用寄存器地址码,rs、rt、rd寄存器地址都是五位字长。
2.MIPS系统架构设计
为了体现层次递进、逐步扩展的设计思路,以MIPScpu_core为核心,先设计支持18条指令的处理器-零号机,在其基础上扩展设计支持五级流水线的初号机,以支持54条基础MIPS指令。在初号机的基础上,增加系统控制硬件模块,以保证RTOS的实时性。最后在CPU外补充外围电路,设计SOC顶层。
从设计步骤上,基于quartus 17.1先编写每个模块的verilog文件,并仿真测试其时序是否符号预期,然后在顶层MIPScpu_core.v中根据数据通路进行布线,顶层采用布线可更直观展示CPUcore各个部件引脚之间的关系及信号的传递。完成数据通路设计后续的扩展工作则先增加模块,再在Control_Unit.v中增加相应的控制线,以实现控制。
从CPU核心core出发,由于MIPS指令集都是等字长、等周期指令,为了将RISC流水线的控制规范化[16],故选择将其设计成单周期处理机。在此先讨论单周期MIPS处理机的设计:
单周期CPU是指一条指令在一个时钟周期内执行完毕,然后开始执行下一条指令。时钟周期一般也称振荡周期。单周期处理器的设计,关键是确定数据通路以及确定哪些操作可以并行完成、哪些操作必须分时序完成。例如ALU的两个操作数送入和运算,可以用组合逻辑实现,在同一时刻完成[17],但是对于 General_Register的读和写就需要区别对待。对于一般的算术逻辑指令,一般流程是“Read-Operation-WriteBack”,即“读-算-写回”的流水线执行流程。读和算可以安排在一个时钟边沿,但是读写如果共用一个数据端口,读和写都各自需要一个时钟周期,那就无法实现单周期的处理器。所以 General_Register采用“错位拍”方式,即读写时钟rclk、wclk分开,读操作为上跳边沿敏感;而写操作为下跳边沿敏感,恰好错开半个节拍,这一个方法也称“快慢拍”方法。当然,除了快慢拍之外,还有其他方式来解决多周期修改成单周期:如写操作采用时序逻辑,而读操作采用组合逻辑[18],即地址由效即可数据有效。

图1 MIPScpu节拍时序
如上为主时钟与辅时钟仿真时序:clk为读时钟,上跳延完成取指、译码工作(标注1),执行阶段同步进行。当clk下跳延到达时,完成访存、写回等工作(标注2)。在下一个时钟上跳延到达前,检查是否有软硬件中断,并在这一时刻完成中断隐指令。为了代码的结构统一,在模块内统一采用上跳延敏感,而辅时钟与主时钟恰好错开半个周期,在FPGA设计中,采用延迟触发器完成时钟的统一精确控制。
从Program_Counter的角度出发,标准的MIPS架构要求以字节编址,而每条指令长为32bit,如果只有一个数据端口,则需四个时钟周期才能取出一条指令,无法实现单周期的处理器。故单周期MIPScpu采用32位编址,一次读出32bit,即一条指令。而此时相邻两条指令也不是MIPS要求的PC+4,而是PC+1。
从运算部件的角度看:乘除法指令也要安排在一个时钟周期内完成,那就必须采用并行乘法器、除法器的结构。
从数据通路角度看,由于读写要在同一个执行周期(即时钟周期)内完成,故cpu必须选择三总线(内总线)结构:如下图,单总线、双总线结构数据通路必须分时复用,故只能采用多周期实现。而三总线结构有两个源数据总线,和一个目标数据总线,两个操作数故可以在一个周期内执行结束;
将每条指令的位宽、时长统一,符合RISC指令集规范。
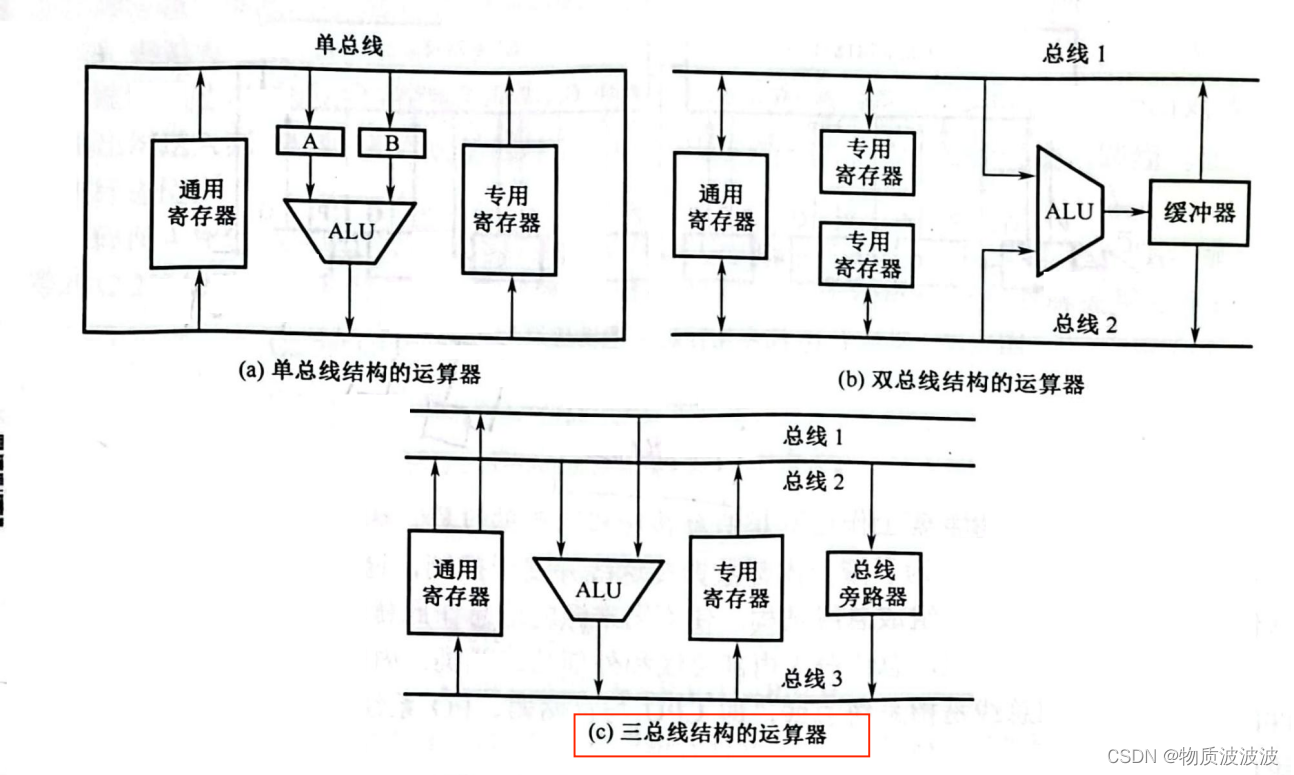
图2 运算器基本数据通路[18]
(二).MIPS处理器核心基础设计(零号机type0)
1.零号机****MIPScpu_core架构设计
零号机属于实验性质的设计作品,其目的在于验证基本的数据通路框架和基础指令,为了体现层次递进、逐步扩展的硬件设计理念,同时为后续扩展和提升设计铺垫。零号机支持的18条基本指令主要为算术逻辑类,还包含两条分支指令beq和bne。
在明确了零号机支持指令集的基础上,将指令的数据通路归类:左表3中,Reg型算术逻辑运算指令数据通路完全一致,同理Imm型算术逻辑指令数据通路也完全一致:由这些指令的数据通路,可以绘制得出顶层文件示意:如下图3所示
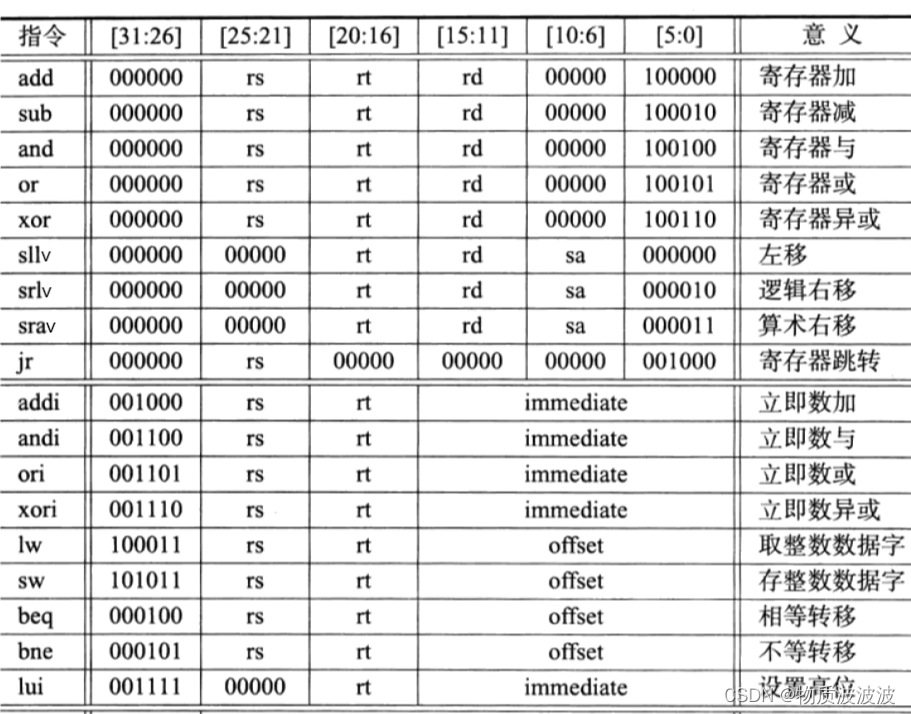
表3 零号机支持指令
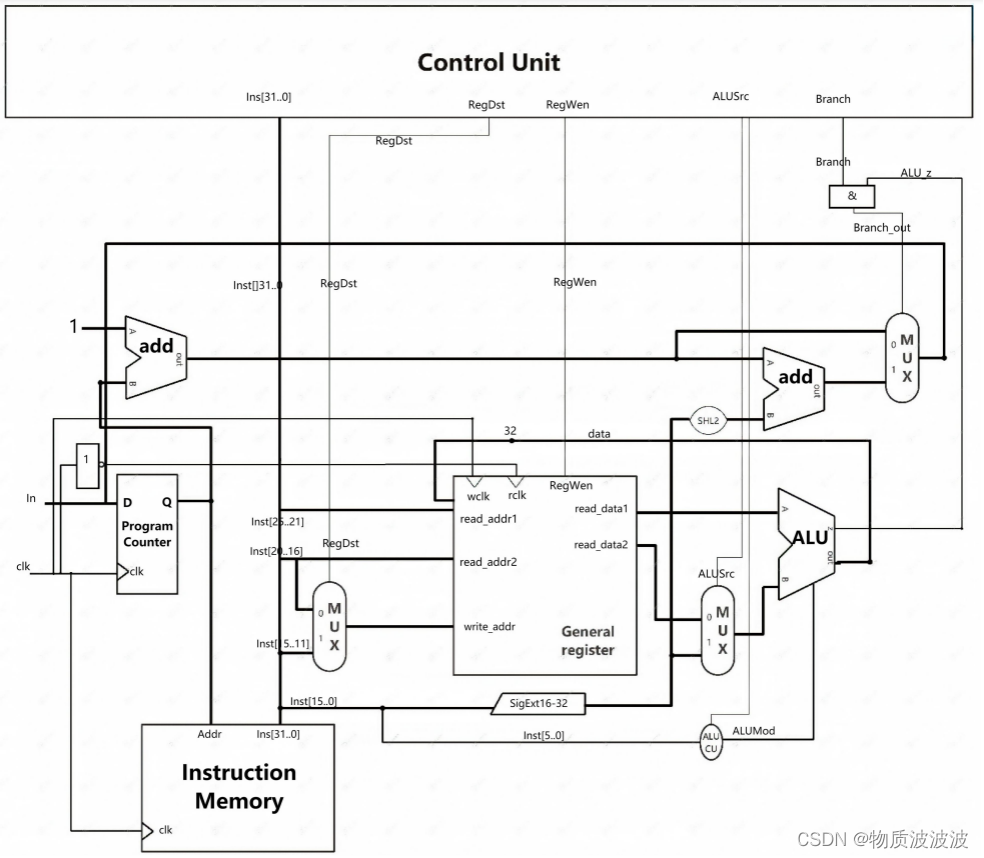
图3 零号机数据通路
2.零号机设计步骤
在绘制完成零号机顶层示意后,逐个落实该图中的核心部件:如ALU、General_Register、Program_Counter等部件,每完成一个部件,新建一个工程“test”,在其中仿真验证。确认无误后在在顶层布线,完成设计结构。为了后续扩展设计的方便,不将数据通路安排在模块内编写verilog代码,而是在顶层完成布线,这样设计的优势在于顶层调用关系更直观;同时封装完成的代码结构后续不会大幅改动。
零号机的数据通路非常简单,其完成了初步对MIPS体系结构的验证。但是零号机的功能并不完善,没有达到课题的基本要求,故扩展设计初号机是非常必要的。初号机支持的指令更多,故初号机的数据通路将增多。而初号机的设计流程与零号机类似,但是由于其支持指令数目更多,设计工作量也会更大。
但是如前分析:初号机的各部分代码结构不会大幅改动,故每个子模块详细分析将在初号机的设计部分详细阐述。
(三).MIPS处理器核心优化设计(初号机type1)
1.初号机****MIPScpu_core架构设计
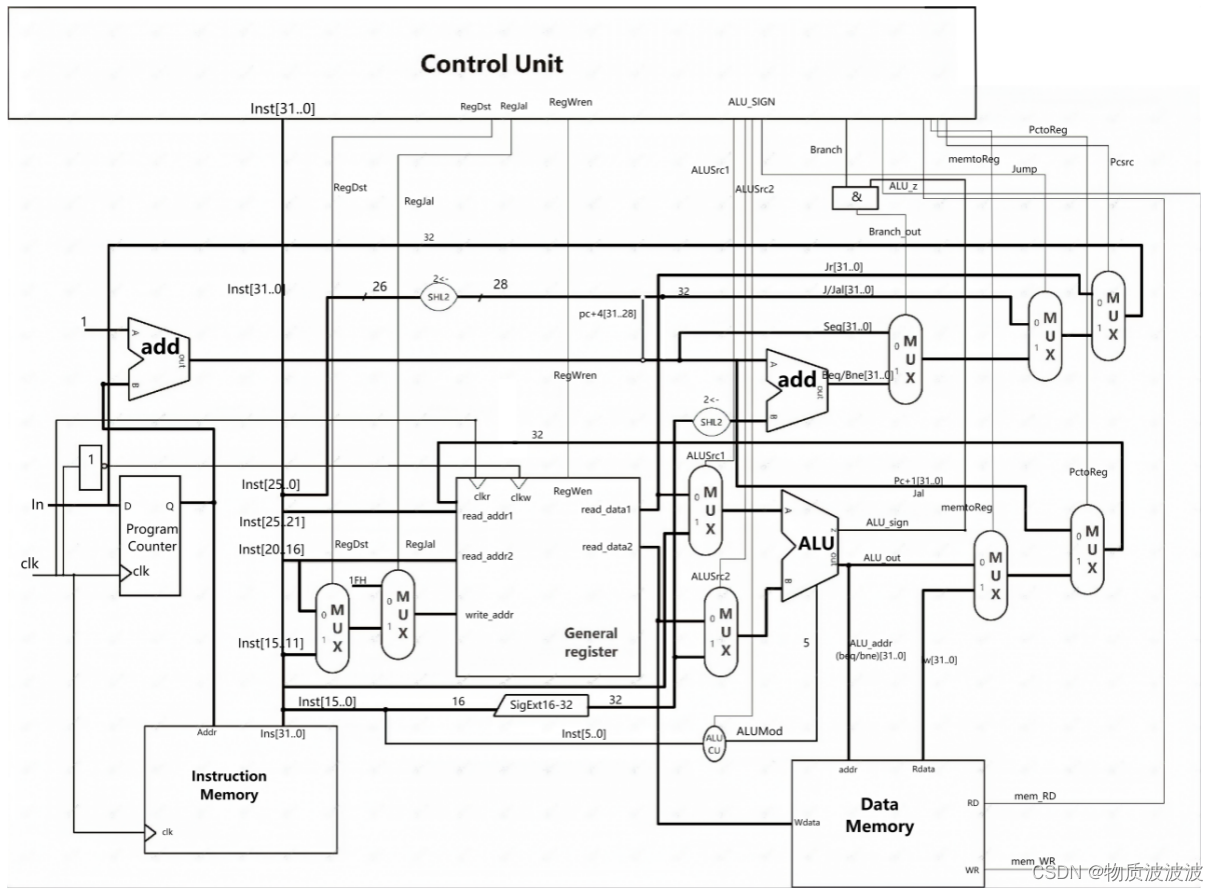
图4 初号机数据通路
在零号机的基础上,初号机扩展至54条汇编指令,其主处理器数据通路如上图所示:(图中未标出并行乘除法部件)
2.初号机设计步骤
顺承零号机的设计思路,在绘制完成初号机顶层示意后,修改该图中的ALU、部件,以支持新指令,每完成一个部件,同样在“test”工程下仿真验证。确认无误后在在顶层布线,完成设计结构。
3.子模块结构与数据通路分析
(1)******.ALU模块**
ALU(算术逻辑单元)模块是处理器运算的核心部件,其衡量指标是功能强大,故设计32位ALU,设置五位工作方式选择码,共可以实现19种算术逻辑运算模式:
其要求在时钟的控制下完成各类运算,故采用时序结构,当clk上跳延到达时,根据模式码选择工作方式,同时输出结果。其verilog伪代码如下:
moduleALU(clk,input_data1[31..0],input_data2[31..0],output_data[31..0],mod_code[4..0])
always @(posedge clk)
begin
case(mod_code)
If(mod_code==00000) add begin;
If(mod_code==00001) sub begin;
If(mod_code==00010) and begin;
else ...
endcase
end
endmodule
其封装逻辑接口如下图:inputdata1、inputdata2为两个32位数据输入,z_singal为运算判断输出标志,该信号将送入CU,作为条件转移指令的判断依据。Parameter为宏定义的常量编码

图5 初号机ALU模块封装示意
仿真结果如下图所示:当第一个上跳时钟边沿尚未到达时,输出高阻态。当1.时刻到达后,模式码为5’b00001,运算模式为求和运算,根据输入随机数:C47F_2B02H + 1E2A_97A7H = E2A9_C2A9H,与预期相符,后2处为减法,同样符合预期,不再赘述。
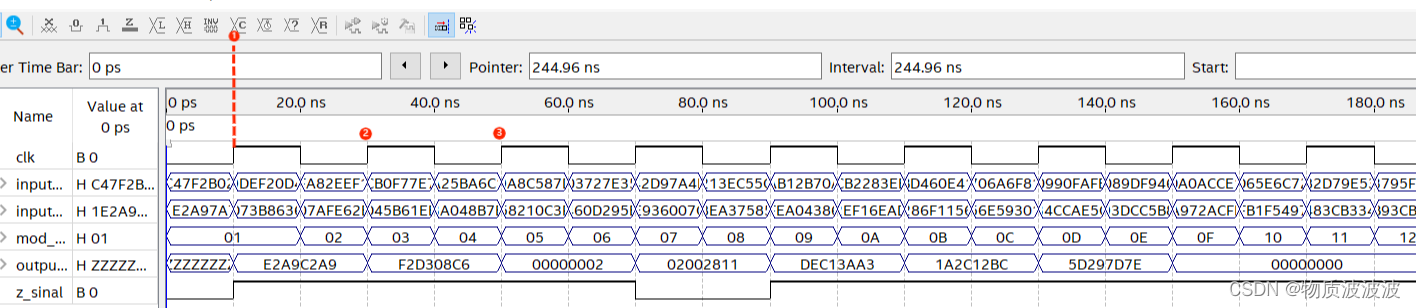
图6 初号机ALU仿真时序
从数据通路的角度出发,ALU的数据源只有四种来源:其中,一般的Reg型指令两个操作数都从寄存器中来,一般的Imm型指令一个操作数从Reg中来,而一个操作数从指令的立即数中来。对于特殊的移位指令sll、srl,其第一操作数来自指令的shamt位。故数据通路如下图,将两个busmux的选择端口命名为Src1、Src2,由CU发出控制信号。

图7 初号机ALU模块数据通路
(2)******.General_Register模块(通用寄存器)**
通用寄存器是CPU中的核心部件之一,其核心功能为完成读写工作即可。按前述系统结构的思路进行设计,时钟分为读时钟和写时钟,且读写时钟错开半拍,为了代码复用性强,统一采用上跳延敏感编写,伪代码如下所示:
moduleGeneral_Register(read_addr1, read_addr2, write_addr, write_data, output_data1, output_data2, rclk, reg_write,wclk);
always @(posedge wclk) //写模块由写时钟控制
begin
if(reg_write) begin
case(write_addr)
If(read_addr1==00000): reg[] = write_data;
else...
endcase
end
end
always @(posedge rclk) //读模块由写时钟控制,且两个读端口互不影响
begin
case(read_addr1)
If(read_addr1==00000) : output_data1 = reg[];
else...
endcase
case(read_addr2)
If(read_addr2==00000) : output_data1 = reg[];
else...
endcase
end
endmodule
其封装逻辑接口如下图:output_data1与output_data2为两个数据读出端口,以支持三总线结构。其中clk为读时钟,clk2为写时钟。为了控制方便,将clk取反后接入clk2,其封装如下:
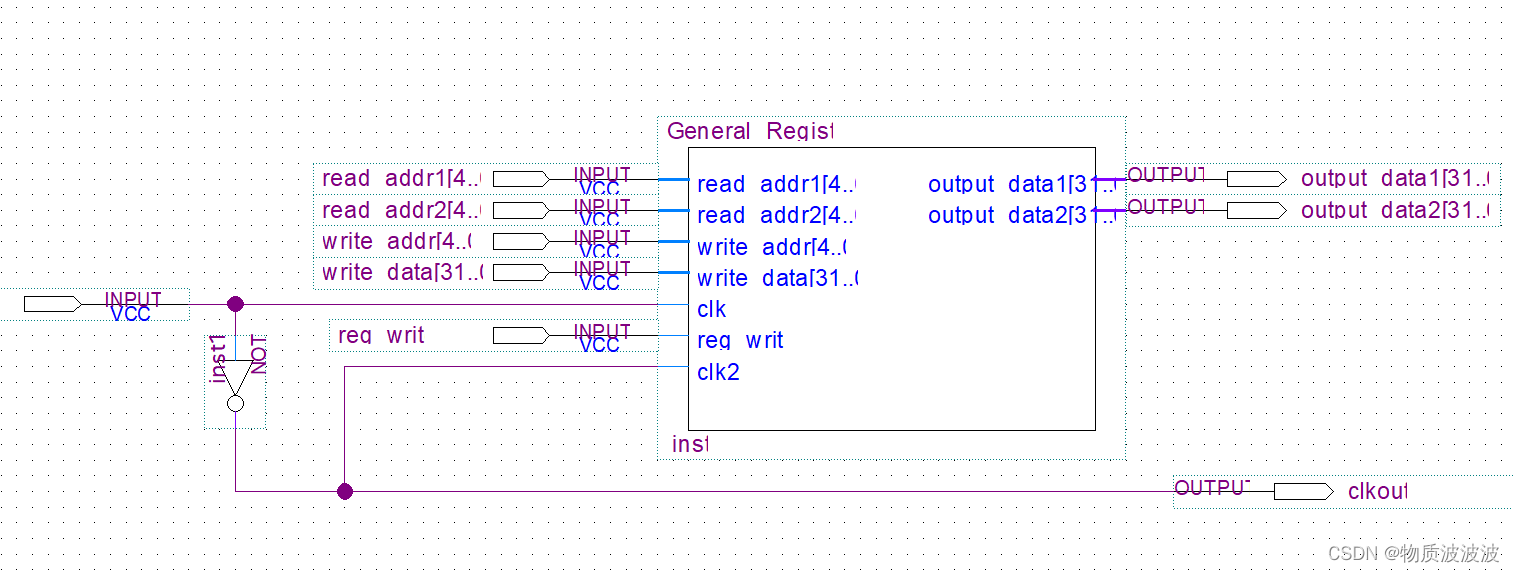
图8 初号机通用寄存器模块封装示意
仿真时序如下图所示:clkout为clk取反后的结果,分析可知:clk的下跳延恰好为clk2上跳延,实现了错开半拍的逻辑;且输入随机地址,数据读出成功。当reg_write为高电平时,数据成功写入,此后读出数据含非零数据,为写周期时写入,实现了读写互不干扰。
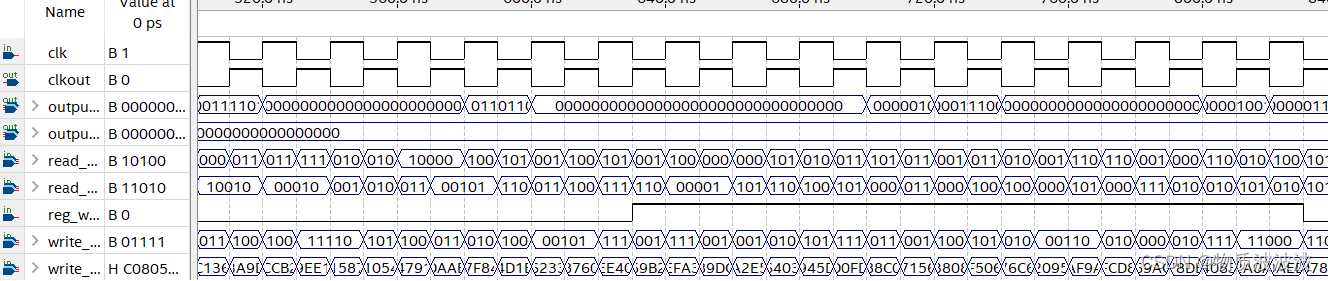
图9 初号机通用寄存器仿真时序
从数据通路的角度出发,General_Register的数据源有五种来源:HI[31..0]、LO[31..0]为特殊寄存器HI、LO,其用于存储乘除法输出结果。而PC+2是来自跳转指令的返回地址,jal、jalr指令在跳转到指定地址实现子程序调用的同时,需要将返回地址(当前指令地址+2)保存到 ra($31)寄存器中。因为MIPS标准下,紧随跳转指令之后有一条立即执行的延迟槽指令(例如nop占位指令),加2刚好是延迟槽后面的那条有效指令。而送往写地址端口的数据源有三种来源:对Reg型指令,写入地址应该为rd,而对Imm型指令,写入地址应该为rt。特别的,对JAL、JALR指令,还要将PC+2送入$31号寄存器,故还有一个数据源为固定的5’b11111。
如下图,将通向数据端口的各个BUSMUX的控制信号分别命名为memtoReg、pctoReg、hilotoReg、HI_LO,由CU负责发出控制信号。而通向写地址端口的两个BUSMUX分别命名为RegDst、JalRst。

图10 初号机通用寄存器模块数据通路
****(3)********.program_counter模块(程序计数器)****及其转移逻辑[不包含中断及返回]
程序计数器是处理器取指令的地址。Program_Count其本身并不复杂,仅在时钟上跳延完成PC的写入即可。程序计数器的输出是作为Imem的地址使用。Program counter的地址分为两种类型:顺序下地址与跳转地址:当指令顺序执行时:PC以时钟自增:而PC+1还是+x,取决于Imem的编址方式:常见的编址方式有按字编址和按字节编址:通常情况下,存储器系统是按照字节(Byte)编址,但CPU访问时,通常按照字(Word)读取,因此地址就有字节地址和字地址的区别。以32位处理器为例,如下图所示;而由于cache采用字编址方式:即一个地址下存储32bit,故顺序指令方式下PC+1即可。但是在MIPS体系结构下,其转移相对复杂:从数据通路的角度出发,其数据源有四类:
当指令为非跳转、分支指令时,PC=PC+1;而当指令为分支指令时,PC=PC+1+Offset。同理,为Jump指令时,将address左移两位与PC[31..28]拼接后送入PC。其中,在MIPS官方文档上,可以总结发现:由于PC按字节编址,相邻两个指令PC地址相差4,为了字节对齐,J指令的address要左移两位(*4)在MIPScpu_core中,由于PC按32位编址,故不需要进行字节对齐,直接高位补两个0即可与PC+1[31..28]拼接。
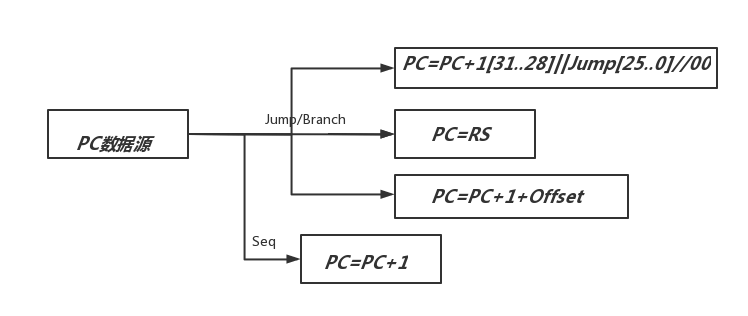
图11 初号机PC模块数据来源
故数据通路如左图所示:将三个BUSMUX的控制信号线分别命名为Branch_out、Jump、Pcsrc由CU发出控制信号进行控制。在二号机的扩展中,还要增加中断隐指令以及中断返回指令ERET。其数据通路在后续单独分析。
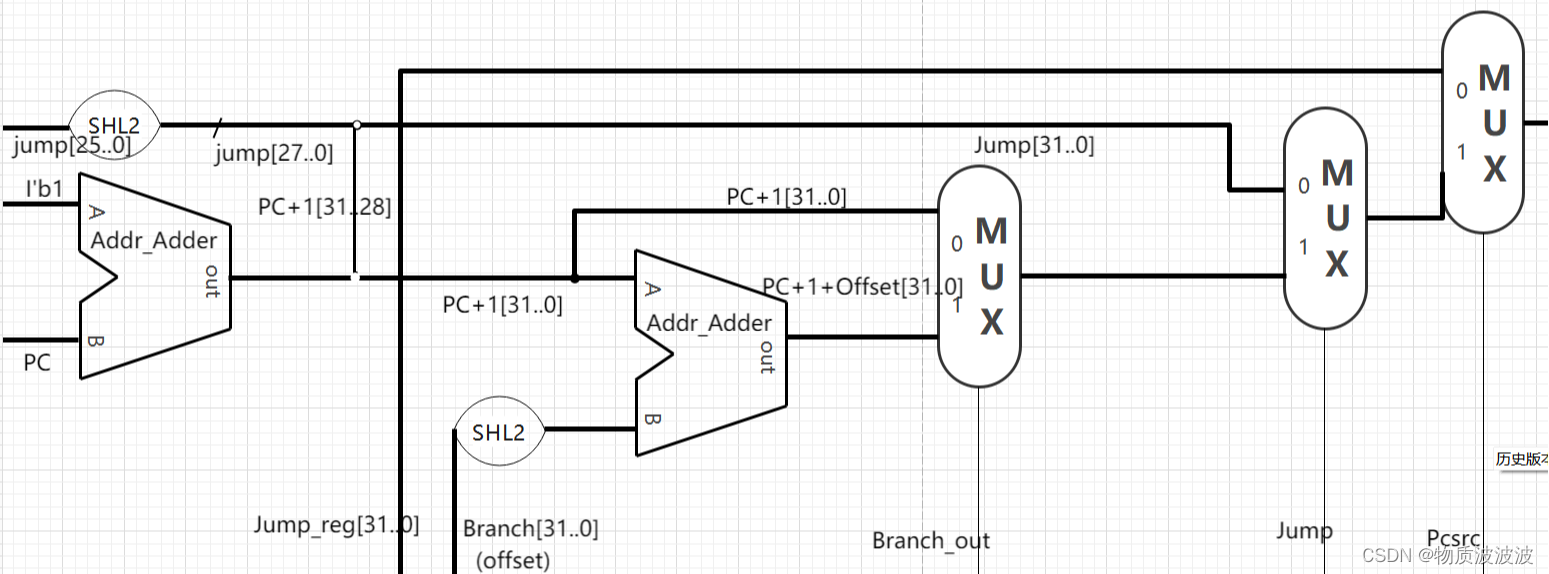
图12 初号机PC模块数据通路
(4).Sig_Exit符号扩展****模块
在MIPS指令集的Imm指令中,立即数占指令的15-0共16位,而MIPS32体系结构下,所有数据都是32bit。查阅官方文档得知16位立即数扩展到32位数据的扩展方式有两类:一类称为“无符号扩展”,在数据高位补16个‘0’即可。另一类称为“符号扩展”:符号扩展就是高位填充的值取决于这个数扩展前的最高位。扩展前的数高位为1,那么扩展出来的高位就都是1,扩展前的数高位为0,那么扩展出来的高位就都是0。
而无符号扩展就是无论扩展前的数是多少,扩展出来的高位都是0。由于这一逻辑是分简洁,故直接采用布线方式实现:如下左为无符号扩展内部逻辑,图右为符号扩展内部逻辑。将两个扩展用的bdf文件分别命名为“Sig_Exit_signed.bdf”、“Sig_Exit_unsigned.bdf”并封装。然后在输出端口补上一个位宽32bit的BUSMUX(Intel IP生成),当BUSMUX选择线置‘1’时,选择有符号输出,为‘0’则是无符号输出,将控制端口命名为ExtSel,由CU发出控制命令。
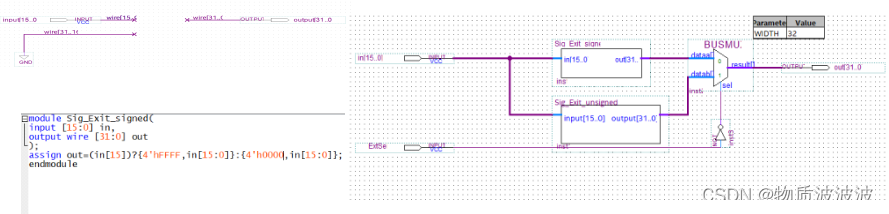
图13 初号机立即数符号扩展模块封装示意与内部结构
其仿真结果如下所示:当ExtSel为‘0’时,表示无符号扩展,高位填0000H即可,反之,当ExtSel为‘1’时,表示符号扩展,如果输入数据为负数,高位填FFFFH;如果输入数据为正数,高位填0000H。

图14 初号机立即数扩展模块仿真时序
(5)MUL _DIV&HI_LO模块(并行乘除法器)
在MIPS体系结构中,乘法运算指令分为两类:MUL指令为等位宽乘法运算,一般无符号二进制数32bit*32bit->64bit,输出截取低32位,在ALU中可以实现。而MULT指令要求按64位运算结果,其中低32位存入LO,高32位存入HI。DIV除法指令类似,商存入LO,余数存入HI。为了ALU模块代码和接口的工整性,这两个特殊的指令不在ALU中实现,独立设计两个并行乘法、除法阵列。
LO和HI为两个32位的特殊寄存器,其数据通路非常简单:其数据来源只可能是乘除法运算阵列输出、或者来自通用寄存器rs,而LO、HI去向只可能是通用寄存器。由于quartus 集成的乘除法器IP时延较高,至少为5个时钟周期。故采用verilog实现并行乘法器和并行除法器。并行乘法器原理如下:将n*n个全加器先行求和,将结果按位排列即为结果。故verilog伪代码如下:

图15 并行乘法器逻辑结构[25]
module mult(input clk,input mult_rst,input [31:0] a,input [31:0] b,output [63:0] z);
always @(posedge clk)begin
for(i=0;i<32;i++)
for(j=0;j<32;j=j+1)
and[i][j]=a[i]&b[j]; //一位全加器阵列
end
assign z=(~mult_rst)?64'b0: //按树型阵列拼接结果并输出
endmodule
同理,并行除法器逻辑结构与并行乘法器原理类似,但是其输出由商和余数两部分构成。
Mult乘法模块仿真时序如下所示:
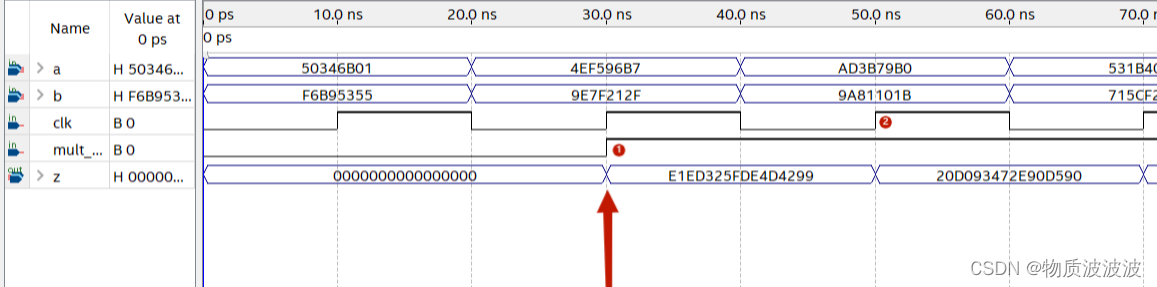
图16 初号机并行乘法器模块仿真时序
当mult_rst为低电平时,除法器不使能,输出‘0000_0000_0000_0000H’当mult_rst为高电平时,乘法法开始运算,以标号1为例:无符号乘法4EF5_96B7H * 9E7F_212FH = E1ED_325F_DE4D_4299H,结果符合预期,且在一个时钟脉冲上完成运算,满足单周期处理器的要求。
Div除法模块仿真时序如下所示:
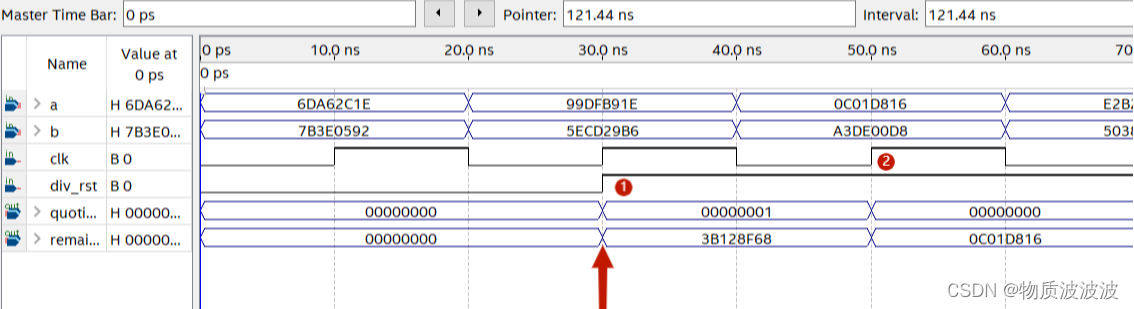
图17 初号机并行除法器模块仿真时序
当div_rst为低电平时,除法器不使能,输出‘0000_0000H’当div_rst为高电平时,除法开始运算,以标号1为例:无符号除法99DF_B91EH/5ECD_29B6H=0000_0001H,余数为3B128F68H,结果符合预期,且在一个时钟脉冲上完成运算,满足单周期处理器的要求。
(6)****.Contro****l_Unit模块(控制单元******)**
控制单元是整个处理器的核心单元。控制信号由其按时序发出。由时序逻辑电路产生控制命令的控制单元称为“硬布线控制器”,其逻辑框架如下图所示:指令经过译码,再加上时序节拍的控制和ALU的运算输出反馈,构成控制网络的输入。在这些输入的作用下,控制单元发出一系列的微命令以操作各个部件。这是是早期设计计算机的一种方法[19];是计算机中最复杂的逻辑部件,且一旦构成,无法增加新的控制功能。
但是在FPGA编程设计过程中,其核心电路由verilog生成,设计的复杂度大大降低,可扩展性也大大增强。相较于微程序控制器,其纯粹由电路产生控制命令,故时延更低,适合单周期处理器使用。对MIPS指令归类可知:从数据通路的角度看:算术逻辑运算类指令数据通路完全一致,不同的仅仅只是ALU的工作码不同而已。从这种角度出发,将Control_Unit划分为Control_Mod和ALUdecoder两个模块。其中,Control_Mod部分控制数据通路的开合,而ALUdecoder控制ALU工作信号。Control_Mod伪代码如下所示:
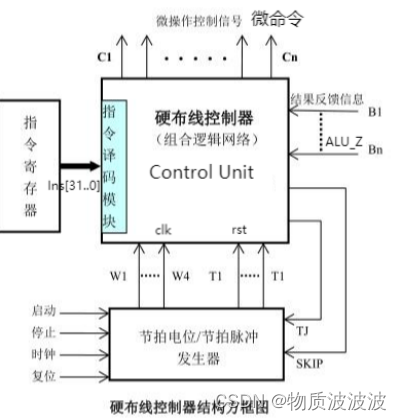
图18 硬布线控制器逻辑结构[20]
module Control_Mod(input ALU_zero, input [5:0] op,input [5:0] func,input rst, input clk,input [4:0]branch,
output singals; //输入op码、func码、时钟、ALU输出信号
);
always @(posedge clk)
begin
if(op==6’b000001) begin:
If(func==5’b00000) begin:
ALUSrc1 =0;
ALUSrc2 =0; //产生一系列微命令,用于控制数据通路
Jump =1;
Branch =0;
Pcsrc =1;
...
If(func==5’b00001) begin: ...
If(func==5’b00010) begin: ...
If(func==5’b00011) begin: ...
If(op==6’b000010) begin:
If(func==5’b00001) begin: ...
If(func==5’b00010) begin: ...
If(func==5’b00011) begin: ...
...
endmodule
同理,ALUdecoder伪代码类似,如下:
module ALUdecoder(input clk,input [5:0] op,input [5:0] func,input [4:0] branch,
output reg [4:0] alu_ctrl_sinal //输入op码、func码、时钟、ALU输出信号
);
always @(posedge clk)
begin
if(op==6’b000001) begin:
If(func==5’b00000) begin:alu_ctrl_sinal = 5'b00001;//产生一系列微命令,用于控制
If(func==5’b00001) begin: alu_ctrl_sinal = 5'b00010; ALU工作方式
...
endmodule
将ALUdecoder与Control_Mod分开设计,可以通过排列组合实现同类指令的控制信号,防止整体代码量过大。封装结构如下图示:
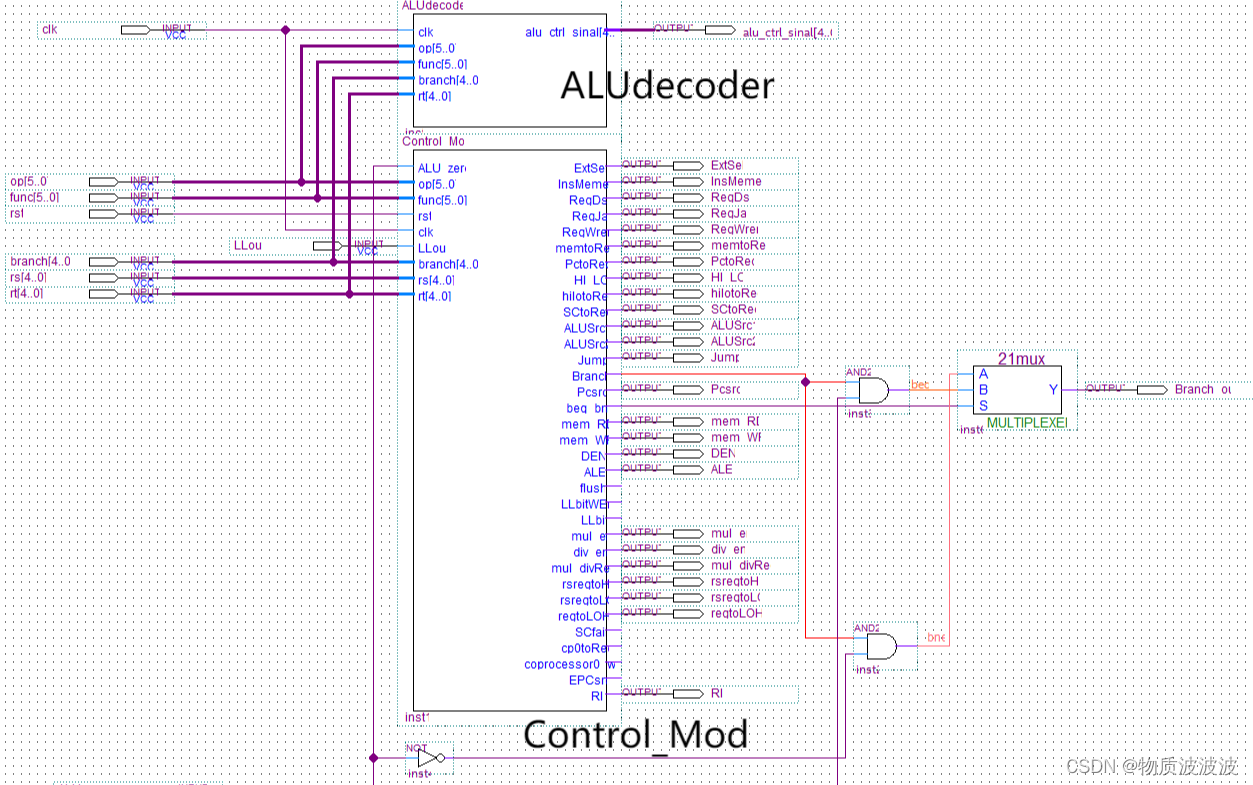
图19 初号机CU模块封装示意与内部结构
同时,为了防止ALU的工作方式超出32种编码范围(5位工作方式码)beq、bne两个条件跳转指令的执行决策,利用的是同一个ALU工作方式(后续很多成对的条件转移指令也采用了这一类设计思路)宏定义为:ALU_comparer,其工作方式是将源操作数1与源操作数2比较大小,相等则在标志位输出‘1’,否则输出‘0’。Control_Mod里输出的Branch是一个跳转锁:
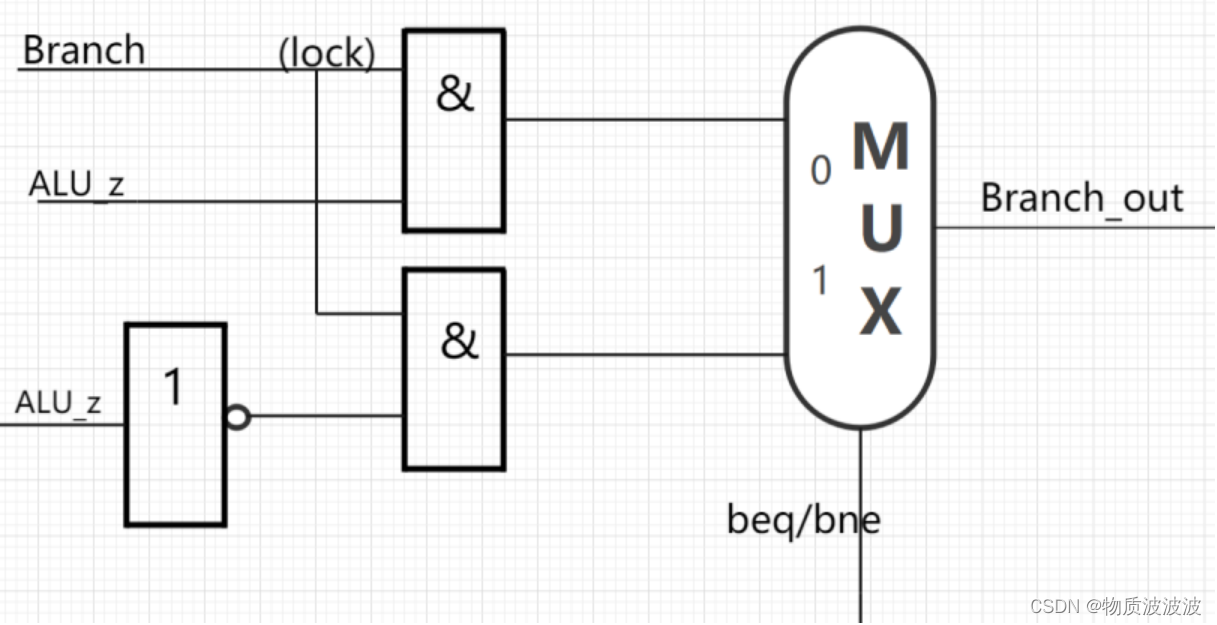
图20 初号机CU模块内跳转控制信号
非转移指令置‘0’。Branch还要结合ALU的判断输出,故在Control_Mod外添加一层组合电路,以实现对转移逻辑的控制。将输出命名为“branch_out”。其基本数字逻辑结构如上图20:Branch为分支转移锁(lock),beq/bne为转移选择线,非转移指令、beq指令该线置‘0’,bne指令该线置‘1’。因为非转移指令Branch为‘0’,两个与门均被锁住,输出全为‘0’,无论MUX选择哪个输出,都不会发生跳转。故上图20所示结构可以实现转移控制。
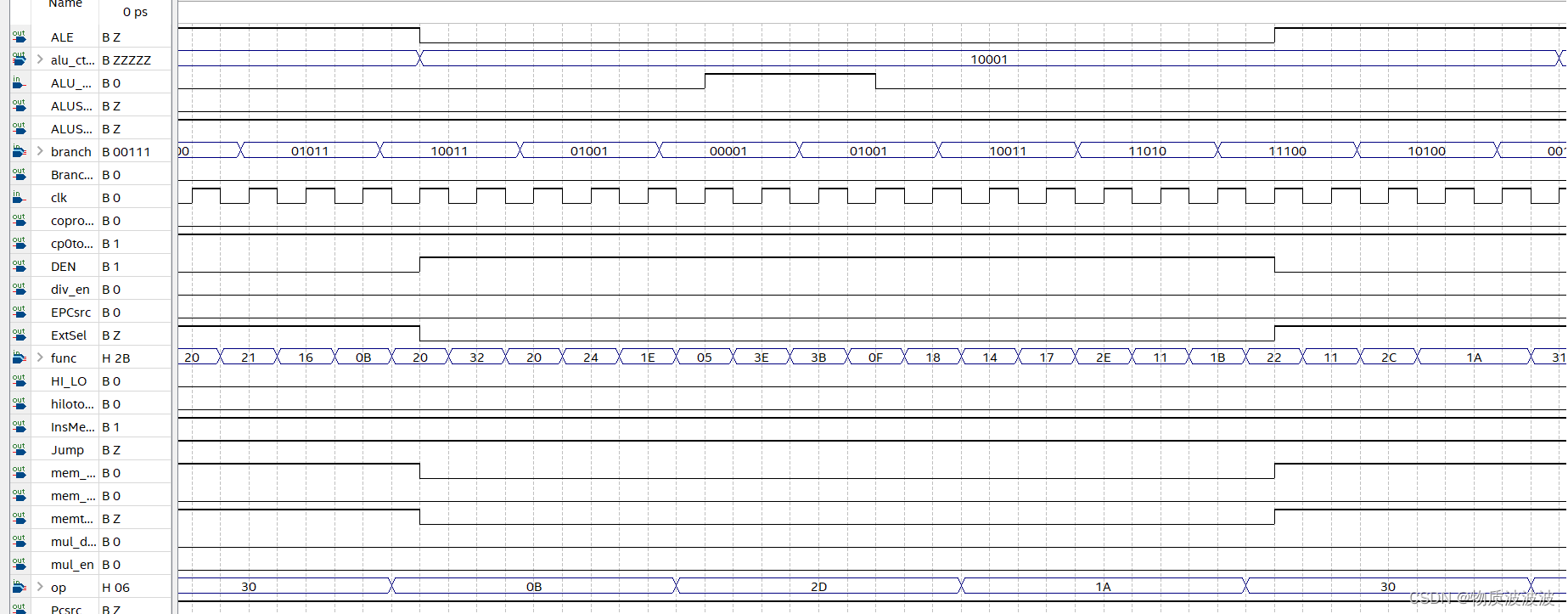
图21 初号机CU模块仿真时序
将上述结构封装为“Control_Unit”后,其仿真时序如上图:在时钟和指令的驱动下,CU发出了一系列微命令。CU是处理器的核心,将其与各个部件的控制信号线相接,可得最终顶层结构。MIPScpu_core顶层结构如下图:各个数据通路由BUSMUX进行选择,BUSMUX为Intel IP,直接调用库函数可得。根据控制微命令,搭建数据通路,初号机顶层文件如下所示:
下图中,绿色数据通路表示PC的来源通路,而红色数据通路表示数据流通路,蓝色数据通路表示指令流通路。为了压缩总管脚数量,初号机有一个面向外设的32位双向数据线data[31..0],32位输出地址线addr[31..0]。以及面向指令存储器的32位指令地址线(PC[31..0])和32位指令输入线Ins[31..0]。DEN为数据输出/输入三态使能。ALE为地址输出许可线;mem_RD、mem_WR分别为存储器读、写选择线。这些接口在命名上借鉴了8086处理器的命名习惯。
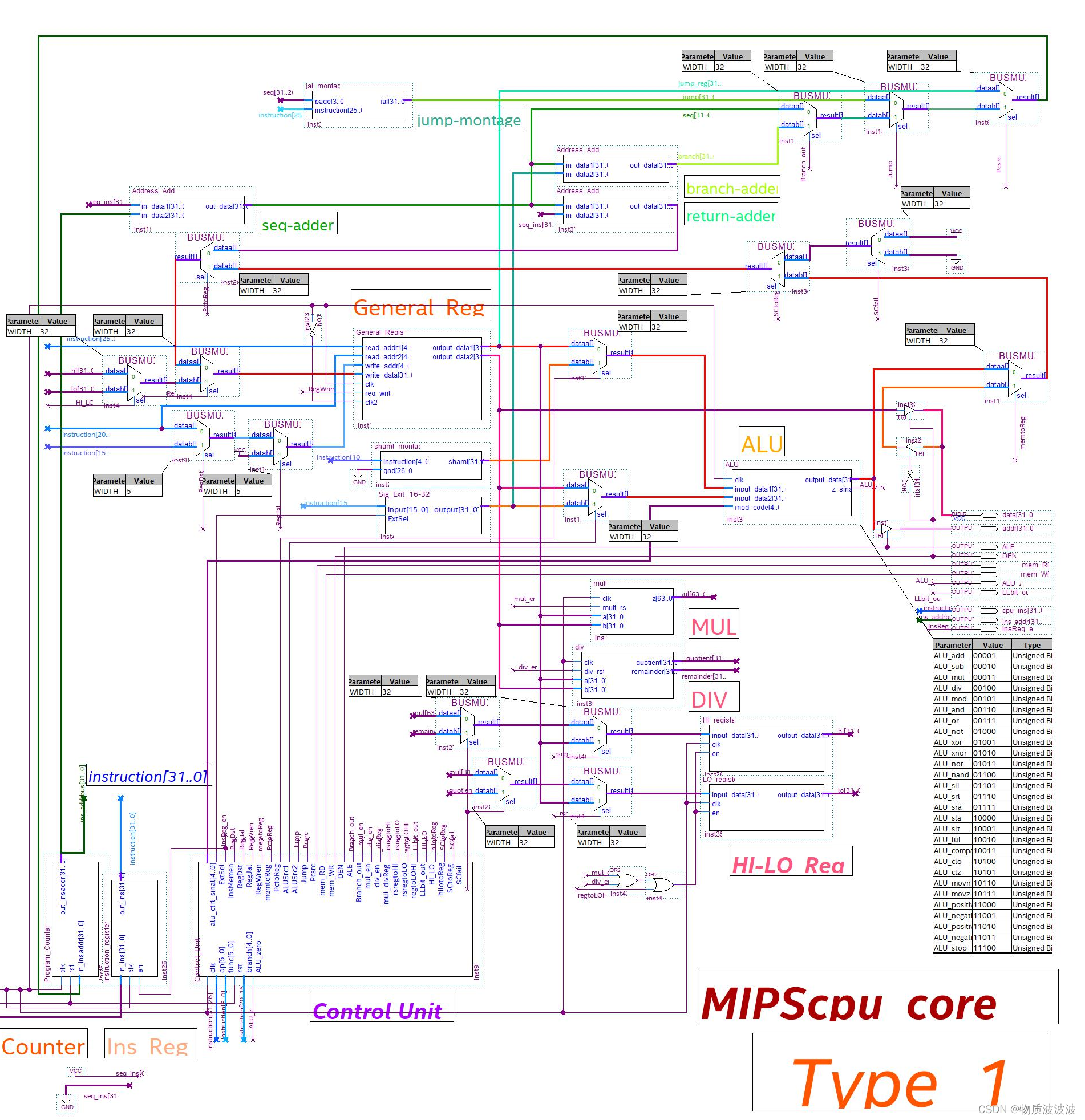
图22 初号机顶层示意
初号机完成了表2中总结的52条基本MIPS汇编指令(由于b指令和beq指令编码相同,bal指令和bgezal指令编码相同,故初号机实现了54条汇编指令)。
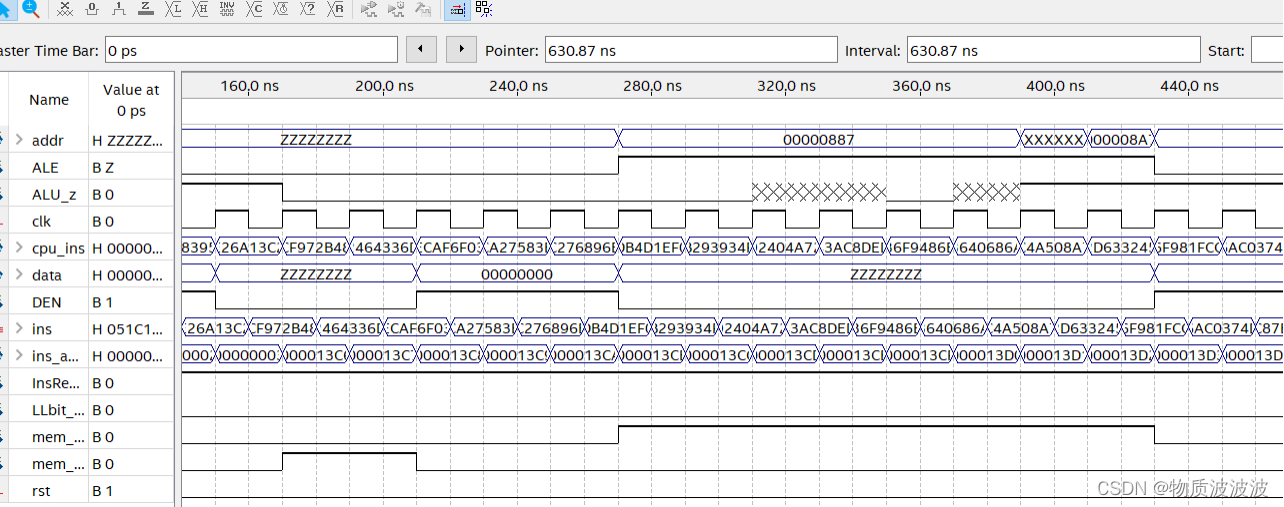
图23 初号机顶层模块仿真时序
MIPScpu_core_type1仿真结果如上图23所示:在指令正常输入的情况下,初号机完成工作。lw与sw指令正常发出mem_RD、mem_WR信号,在MIPSsoc中,MIPScpu的接口将与总线驱动器进行交互。在顶层结构下,MIPScpu_core初号机文件调用系统如左图所示:这样的布局一方面是为了保证数据通路的清晰明了,另一方面使系统层次鲜明、模块封装复用性强。
初号机可以胜任大多数MIPS基本指令,但是其缺乏对操作系统的硬件化支撑部件:如中断相关硬件、MMU、TLB、由于缺乏中断机构,指令错误只会延迟一个周期,产生一个周期高阻态,并不会引发一次异常过程。
二号机的扩展设计是本课题的提升设计部分,设计二号机旨在补充系统支撑模块,以实现对操作系统的支撑:操作系统是和硬件直接交互的底层软件[21],支持操作系统是一个完整体系结构所不可缺少的。

图24 初号机文件调用系统示意
(四).系统控制模块设计(二号机type2)
1.ll与sc原子指令原理与设计
ll与sc原子指令是MIPS体系结构下操作系统硬件化的核心之一,MIPS体系结构下依赖这两条指令实现信号量相关函数。在没有这两条指令的系统中,信号量函数用纯软件实现,总会出现难以避免的BUG[22]。
在cpu里面完成原子操作有很多办法。最最常见的方法,就是关中断、开中断。这个方法可以实现,且非常简单,但是它不够好。关闭了中断会影响系统的灵活性。在MIPS体系结构下,提供了一对用于原子操作的指令:ll与sc:
CLI;//关中断
//body
STI;//开中断
图25 8086-8088系统下原子函数硬件实现方法[23]
在多线程系统中,需要RMW(Read-Modify-Write)操作序列保证对某个资源的独占性,RMW操作序列的含义是,读取内存某个地址的数据,读取的数据经过修改,然后再保存回内存原地址,这个过程不能有任何打扰,因此需要建立一个临界区域(Critical Region),临界区域中完成的操作通常称为原子操作,原子操作不被打扰。操作系统建立临界区域的方式通常是信号量机制,其软件逻辑如下:
wait(semaphore**);**
原子操作;** ****//body**
** signal(semaphore);**
atomic_signal:
ll $31,0
addu $31,1
sc $31,0
beq $31,0,atomic_signal
nop //延迟槽
eret //返回主函数
图26 MIPS系统下原子函数硬件实现方法[24]
semaphore是一个信号量,为0表示信号量使用中,为1表示信号量空闲。进行原子操作前,使用wait函数查询semaphore的值,如果为0,则等待,否则,将其置为0,开始执行原子操作,操作结束后,signal函数将semaphore置为1,这样其它线程就可以执行原子操作了。除了上述临界区,wait函数的执行本身也是一个原子操作[23],是一种“先检测后设置”操作(test-and-set operation),这种操作不允许被外设中断,也不允许被其它线程打断。
很多指令集都有专门的指令用来实现“先检测后设置”操作,但是MIPS32架构采用特殊的方式实现信号量机制,对于原子操作,MIPS32架构并不保证它一定是原子性的,但确保原子性的情况下原子操作才能成功发生。MIPS32架构采用链接加载指令ll、条件存储指令sc来实现这种信号量机制。
ll指令同一般的加载指令一样,从内存中加载一个字,同时,ll指令还会将处理器内部的一个链接状态触发器LLbit置为1,表明发生了一个链接加载操作,并将链接加载的地址保存到一个特殊寄存器LLAddr中(这个寄存器在多处理器中有作用,但是MIPScpu_core是单处理器系统,所以未实现LLAddr寄存器)。ll指令执行完毕后,会安排原子操作的核心动作(body),然后执行sc指令。但是,在单cpu系统中,如果出现了异常、中断,处理器会设置链接状态位LLbit为0。
执行sc指令时,会判断LLbit是否为1,如果没有受到任何干扰,LLbit保持为1,那么操作是原子的,sc指令会对ll指令加载数据的地址进行写回操作,并设置一个通用寄存器的值为1,表示成功,反之不进行写回操作,并设置一个通用寄存器的值为0,表示失败。即ll、sc指令不保证ll与sc之间不会发生中断,但是保证如果原子函数成功运行,其一定是原子的。原子指令过程最为精妙的地方在于两点:
1)ll和sc一定要配对使用,单独使用是不成立的;
2)影子寄存器(shadow-trigger)对用户来说是不可见的,并且sc中写入数据的那个寄存器,同时担当了返回值的作用。
ll与sc指令格式如下所示:

表4 LL与SC指令格式
其功能描述为:
ll:rt ← memory[base+offset],LLbit ← 1
sc: if LLbit =1 memory[base+offset] ← rt, rt ← 1 else rt ← 0
由于影子触发器LLbit(shadow-trigger)对软件开发人员不可见,故将其集成在CU模块内,由CU对其进行控制:但是要实现上述功能,LLbit不能仅仅只是一个d触发器(DFF)其应该为含异步功能端的触发器:异步端命名为“flush”,当中断或异常发生时,将该触发器直接置‘0’。
之所以要将LLbit触发器安排在CU模块内,而不是后续设计的CP0协处理器内,是为了最大程度上提升中断隐指令的并行度,如果将所有部件安排在协处理器内,会出现资源冲突问题。
在明确了LL、SC指令的编码、功能后,首先要编写LLbit触发器的verilog代码,由于其为1bit触发器,结构非常简单,在此不再赘述。完成了LLbit的编写和封装、测试后,在CU模块下扩展相应LL与SC部分的代码,在接口部分增加对LLbit的控制信号线,最后完成搭建。
a.CU模块修改:
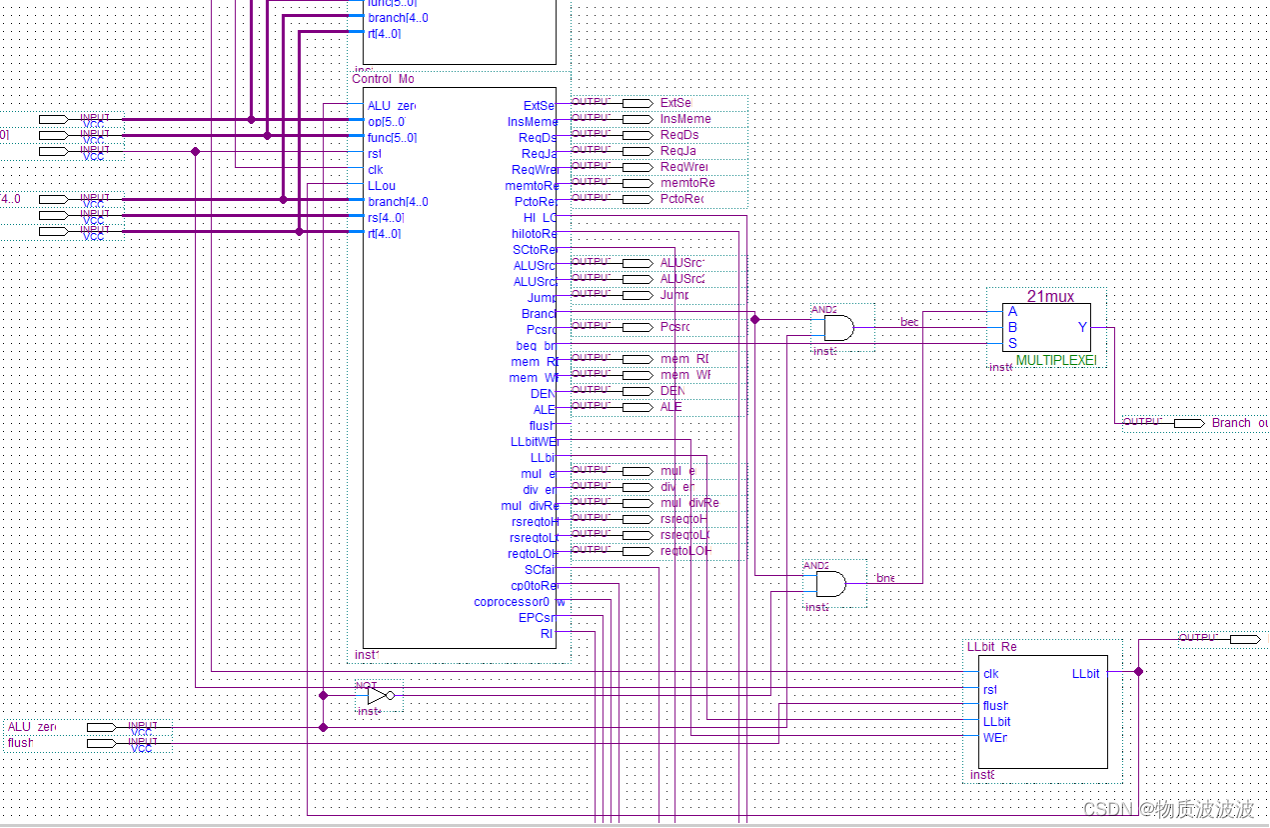
图27 二号机CU模块结构修改
如上图27,为LLbit集成进入CU的封装结构:
其同步端由Control_Mod全权控制,任何一般指令都没有权限对LLbit进行操作,故其控制线上输出总保持上一次LL/SC指令的操作信号。其输出又作为Control_Mod的输入信号,以作为SC指令执行与否的决策依据。
flush为LLbit异步功能端,由外界中断模块输入,若MIPScpu响应中断,flush置‘1’。
b.数据通路修改:
在General_Register的写入数据源中,多了一个SC指令的数据返回值:如上图5 原子函数atomic_signal中,SC指令后紧跟一条转移指令beq $31,0,atomic_signal。即当返回值为0000_0000H时,SC指令执行失败,跳转至标号atomic_signal处重新执行。SC指令的返回值只有两种可能性:0000_0000H、FFFF_FFFFH故采用下图所示数据通路:在General_Register外补上两个BUSMUX,控制信号分别为SCfail、SCtoReg,SCfail表示SC指令执行是否成功,而SCtoReg表示是否打开SC指令数据通路。在CU中补上代码:当SC指令译码后,SCtoReg置‘0’,其余时候置‘1’。SCfail为‘0’表示成功,‘1’表示失败。
至此,LL-SC指令完成设计,接下来是协处理器和中断模块的设计。
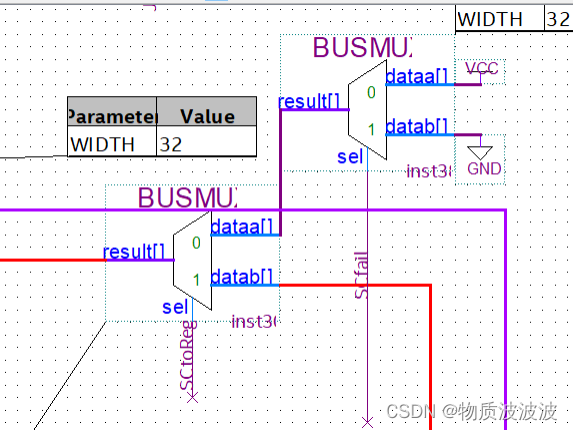
图28 二号机数据通路修改
2.CP0协处理器模块设计
(1).CP0寄存器协议
协处理器(coprocessor)通常表示处理器的一个可选部件,负者处理指令集的某个扩展,具有与处理器核独立的寄存器。MIPS32官方文档的体系结构,定义了最多4个协处理器,分别是CP0~CP3,如下表所示:
协处理器
作用
CP0
系统控制与中断支持
CP1
FPU(浮点数处理单元)
CP2
留空
CP3
FPU(浮点数处理单元)
表5 MIPS体系结构协处理器功能[25]
CP0负责的主要工作:
- Cache控制:集成缓存控制器,来控制、读、写缓存
- 异常、中断控制:异常发生时的检测和处理都由CP0中的一些控制寄存器来控制
- 存储管理单元控制:对系统的存储区域进行合理的控制、管理和分配,主要是对MMU,TLB的一些配置、管理、访问
- 其他:当要把额外功能集成在CPU中,但又不方便当作外设访问时,常常在CP0中增加一些模块来实现这些功能。(例如:时钟、时间计数器、奇偶校验错误检测等)
(2).CP0_Reg模块
MIPSCP0协处理器中与通用寄存器类似,也同样定义了32个寄存器,从表中可以发现很多寄存器都是与Cache、MMU、TLB的调试有关。其中与中断相关的寄存器使用定义如下:
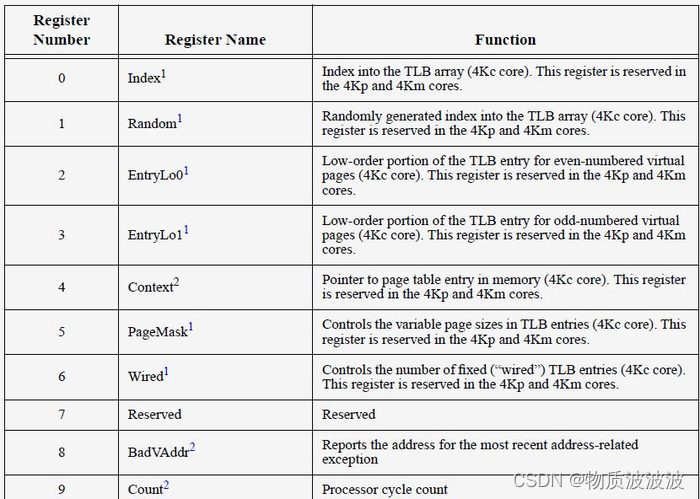
图29 cp0寄存器定义[26]
Count寄存器地址5’b01001,是一个不断计数的32位可读可写寄存器,计数频率一般与CPU频率相同。计数达32位无符号上限时,从0重新开始。 Compare寄存器地址5’b01011,是一个32位可读可写寄存器,与Count一起完成定时器中断功能。当“Coumt == Compare”,会产生一次实时钟中断。这个中断会一直保持。直到有数据被写入Compare寄存器。
Status寄存器地址5’b01100,是一个32位可读可写寄存器,用于控制处理器的操作模式、中断使能以及诊断状态。 Cause 寄存器地址5’b01101,是一个用于记录最近一次异常发生原因的寄存器,也用于控制软件中断请求。Cause寄存器的各字段如部分可读可写,部分是只读的。 EPC寄存器地址5’b01110,是一个异常程序计数器,存储异常返回地址。 Status寄存器和Cause寄存器是和中断异常相关的寄存器:Status寄存器的CU3-CU0表示协处理器是否可用,分别控制协处理器CP3,CP2,CP1,CP0。为0时,表示相应的协处理器不可用,为1时,表示相应的协处理器可用。只有协处理器CP0可用时,设置本字段为4'b0001
SR表示是否软重启,为1表示重启异常是有软重启引起的,NMI表示 是否不可屏蔽中断,为1表示重启异 常是由不可屏蔽中断引起的。
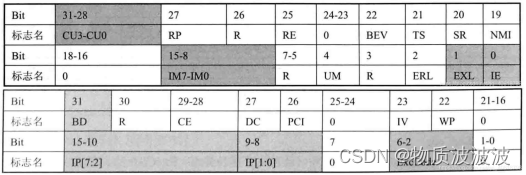
图30 Status寄存器用途[27]
图31 Cause寄存器用途[28]
(上图中除灰色部分外,其余只读,‘R’表示留空)
IM7-IM0表示是否屏蔽相应中断,0表示屏蔽,1表示不屏蔽,MIPS处理器有8个中断源,对应IM字段的8位,其中6个中断源是处理器外部硬件中断,另外2个是软件中断。
EXL表示手处于异常级,当异常发生时,会设置本字段为1,表示处理器处于异常级,此时,处理器会进入内核模式下工作,并且禁止中断。
IE表示是否使能中断,这是全局中断使能标志位,为1表示中断使能,为0表示中断禁止。
Cause寄存器是原因寄存器,寄存最近一次发生异常或中断的原因,以便操作系统或硬件指令查询。其中Cause[31] BD位表示指令是否在延迟槽内,当发生异常时,指令恰好位于延迟槽内,则该标志位置‘1’。
而IP[7..0]为中断挂起字段,记录8个中断申请是否发生。ExcCode是五位编码,标志发生异常的类型。
实现中断管理是Cp0协处理器的重要工作,由于MIPScpu_core暂时尚未实现Cache、MMU、TLB相关部件,所以与MMU、TLB相关寄存器暂未实现。在CP0_Reg模块内,只实现了5个寄存器,其功能定义如下表6所示:
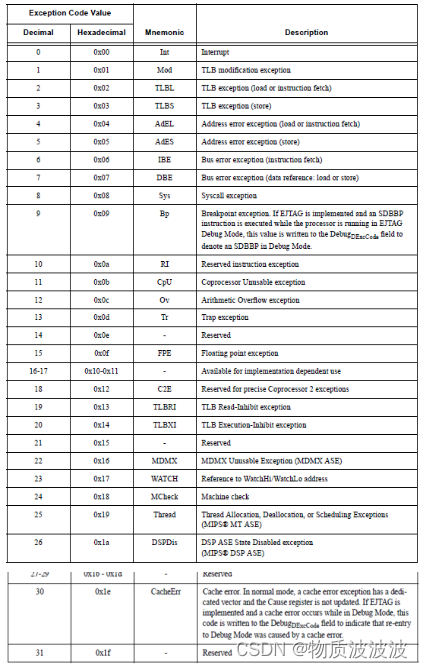
表6 ExcCode编码含义[29]
其中,由于cp0中各个寄存器有很多重要的标志位须作为决策依据,不可以有时延,故写入采用时序逻辑实现,而读出采用组合逻辑实现;而中断是否响应,由Status寄存器和Cause寄存器共同决定的,如果Status寄存器的IM字段与Cause寄存器的IP字段的相应位都为1,而且Status寄存器的IE字段也为1时,处理器才相应中断。
实现寄存器地址
寄存器助记符
功能描述
9
Count
处理器计数周期
11
Compare
定时中断控制
12
Status
处理器状态和控制寄存器
13
Cause
保存上一次异常原因
14
EPC
保存上一次异常前的程序计数器
表7 CP0_Reg内包含寄存器及其功能[30]
同时,协处理器的结构与中断流程密切相关。参考官方文档,可知:MIPS32体系结构中,打断程序的正常的执行流程,如中断、陷阱、系统调等情况,统称为“异常”。和8086系统[27]处理方式不同,中断和异常采用同样处理机制:如下图8所示:为MIPS体系结构下基本的中断时序流程。但是观察可以发现:该流程中 很多步骤互相没有依赖关系,完全可以并行,由不同部件完成。
中断类型码的来源,MIPScpu_core采用两类来源:硬件直接产生、由外部PIC中断控制器送ExcCode。
异常类型
描述
中断向量
reset
硬件复位
x
Interrupt
中断
0x20
Sys
Syscall指令
0x40
RI
指令无效
0x60
Ov
算术运算溢出
0x80
Trap
自陷指令
0xA0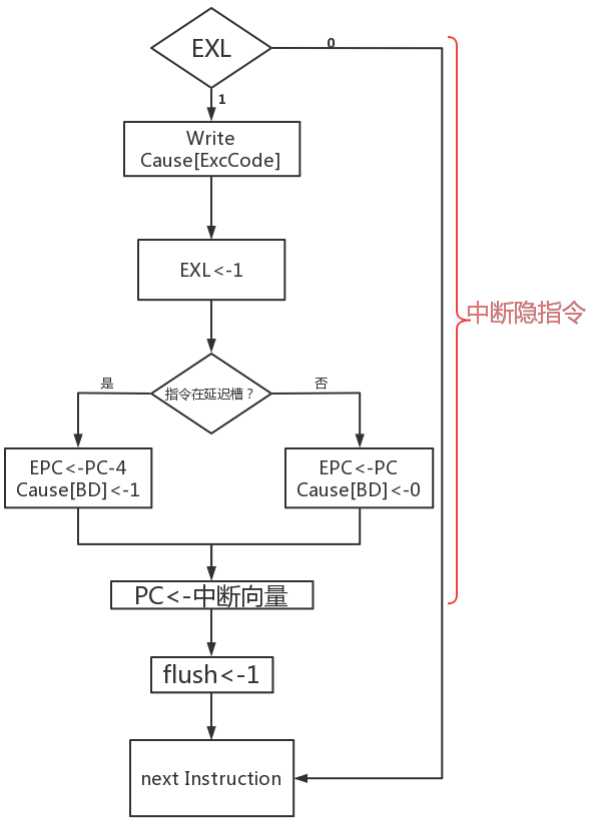
表7 MIPScpu_core支持异常类型及其中断向量
图32 MIPScpu_core中断流程[31]
因为MIPScpu_core是单周期处理器,所以要提高中断隐指令的并行度,减少时间开销:半个时钟周期内必须完成中断隐指令,在下个时钟上跳延到达之前,必须完成送PC的工作,不可以有一点拖沓:故拆解步骤使其并行化,是一个关键步骤。
将图32的串行中断流程按操作相关部件进行拆解,得到如下图9所示的并行化流程:流程中与cp0寄存器相关的操作与CU、PC相关的操作无资源冲突,在EXL==0的条件下,可以并行完成。而指令是否在延迟槽内,也可以通过verilog if语句来实现,保证硬件时效。MIPScpu_core的中断部件如下:
coprocessor0:其中核心部件为cp0_reg。中断隐指令与cp0寄存器相关的操作完全由cp0_reg实现,其只需要接收ExcCode编码和是否处于延迟槽的判断信号‘delayslot’即可完成EXL置‘1’、保存返回地址、写Cause[BD]操作。其还有一个附属模块cp0_delay,用于判断异常时刻指令是否处于延迟槽内。
****Interrupt_unit:****其中核心部件为Interruptdecoder,中断隐指令与CU、PC相关的操作完全由Interruptdecoder实现,其接收中断申请、自陷指令以及检测cp0_reg相关输出,判断是否响应异常,送异常类型码ExcCode、送中断向量进入PC、将LLbit置‘0’。
由硬件直接产生ExcCode的异常包含两类:syscall指令,在操作系统中通常使用该指令进入系统内核态、Trap指令,MIPS体系结构下的自陷指令有条件自陷和无条件自陷。这些指令在正常执行阶段无操作(条件自陷会进行运算)而在中断周期内才可能触发异常。
而中断向量的产生完全由硬件产生。单周期处理器没有访存的时间,故不可以仿照8086-8088[32]系统一样,访问内存内的数据结构-中断向量表,再取出中断向量。MIPScpu_core的中断向量在硬件设计时已经确定,由Interruptdecoder硬件模块直接产生,中断向量安排如左表7所示:在指令寄存器的低地址区间安排一些处理例程,发生异常时,由中断隐指令将这些地址直接置入PC内。
完整cp0-中断模块文件结构如下图10所示:(蓝色为cp0寄存器相关核心部件,绿色为CU、PC相关核心部件,其余为外围电路)
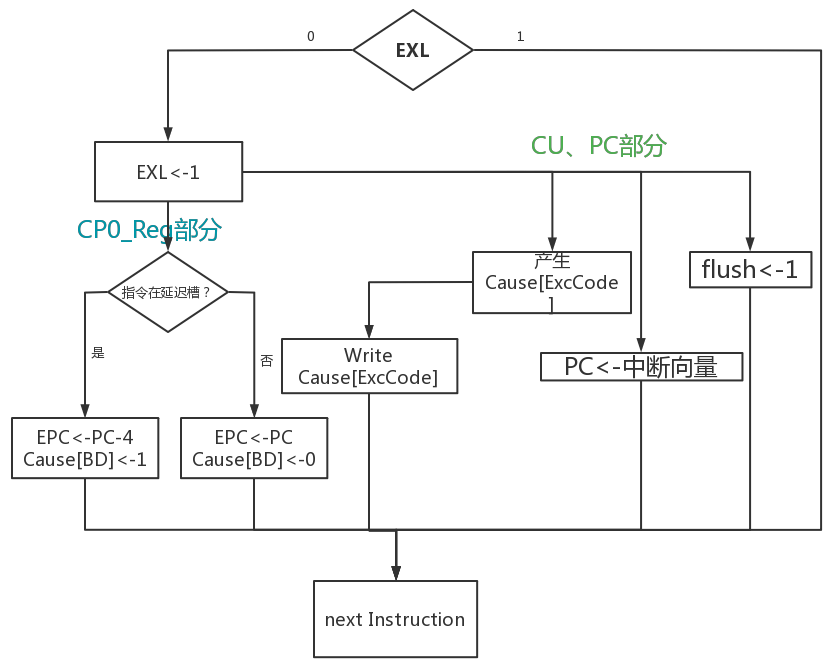
图33 中断流程并行拆解
指令实现:Interruptdecoder模块功能为异常解析译码:其可以完成以下指令:在指令译码阶段,由CU发出控制命令,由ALU运算是否满足条件,在中断周期到达时,结合ALU运算输出和EXL位,判断是否触发异常过程:对syscall指令,只需检测EXL位是否为‘0’即可。而eret指令为中断子程序返回指令,将cp0_reg寄存器清零、并且将EPC寄存器送回PC即可。为了统一操作流程,不产生新的数据通路,eret指令清理cp0寄存器的操作还是由cpo_reg完成:上表6中,部分编码留空,故定义5'b01110为eret指令异常码,将该码发送给cp0_reg后,由其清理EXL标志位。送回PC的操作由Interruptdecoder模块完成。
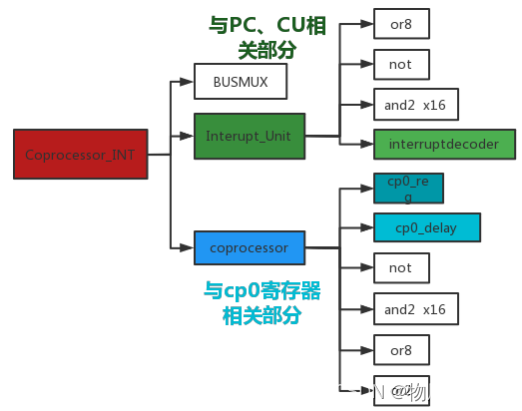
图34 CP0文件结构
封装结构如下图所示:中断申请有效位外为一系列硬件锁:当且仅当EXL==0&&IE==1&&中断屏蔽位为1时,中断申请才有效。在MIPS体系结构下,中断无优先级,由或门or8相连。优先级完全由软件实现。
将CP0_INT模块集成进入MIPScpu_core中后,形成二号机,其顶层结构如下图37所示:相较于初号机,二号机增加了ll、sc指令。还增加了6条自陷指令,以及一条无条件异常指令syscall、中断返回指令eret。共计支持64条汇编指令。
此外,由于实时钟中断是一个硬件中断,故在MIPScpu_core的设计中,将实时钟中断接入INT0上。实际面对外设的硬件中断只有四个中断管脚,如果后续设计要扩展外设,要通过8259PIC中断控制器实现扩展。在最开始的设计中就考虑到扩展问题,所以ExcCode编码可以通过外部送入。与初号机数据通路类似,下图37中,绿色数据通路表示PC的来源通路,而红色数据通路表示数据流通路,蓝色数据通路表示指令流通路。
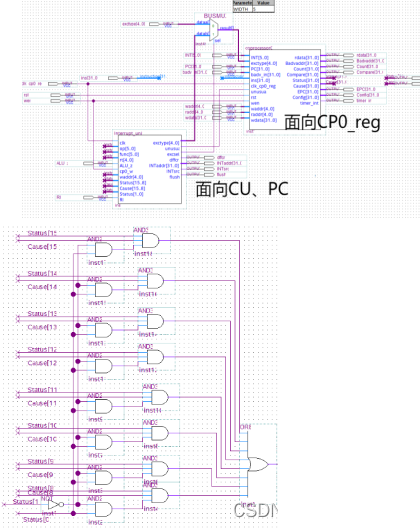
图35 中断控制模块封装结构
二号机虽然对操作系统有了硬件支持,但是相较于现代处理器,其缺乏MMU、TLB等加速处理流程的模块。在后续设计中会考虑扩展这些部分。在扩展了cp0模块后,顶层调用文件结构如下图所示:除了增加cp0协处理器模块外,还将LO_HI寄存器封装了一层结构,使顶层文件结构更加鲜明;MIPS体系结构是开源的体系结构,为了使设计符合开源理念[33],笔者将这一课题上传至CSDN、Gitee,将其打造为“OPENMips”项目。

图36 二号机文件调用系统示意
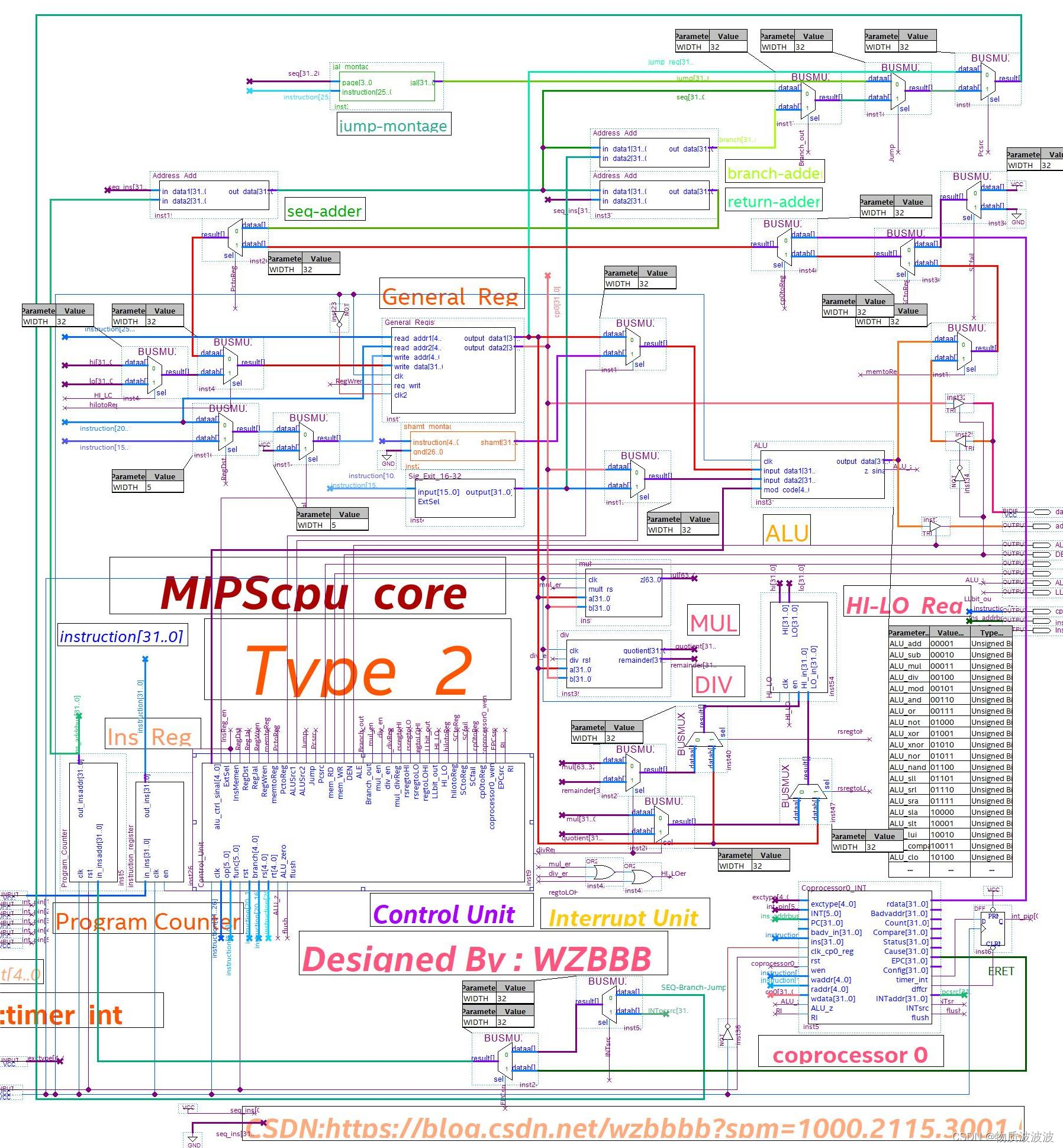
图37 二号机顶层结构
至此,二号机也完成设计。二号机源代码尚未发布,初号机代码已上传至Gitee。
初号机源工程体量过大,已上传至gitee,详细请访问:MIPScpu_core_type1: MIPScpu_core_type1是支持56条基本汇编指令的MIPS处理器,基于Quartus (Quartus Prime 17.1) Standard Edition版本开发设计。c
参考文献:
[1-9] 略(与背景意义相关)
[10-15]MIPS32™ Architecture For Programmers Volume II: The MIPS32™ Instruction Set Document Number: MD00086.Revision 2.00,June 9, 2003
[17]严海洲.基于FPGA的MIPS单周期处理器的实现[J].电脑知识与技术,2021,17(19):5-8+13.DOI:10.14004/j.cnki.ckt.2021.1846.
[16、18-20]白中英,戴志涛.计算机组成原理(第六版·立体化教材):科学出版社,2019:
[22-24]计算机操作系统(第三版),西安电子科技大学出版社
[25-30]MIPS32™ Architecture For Programmers Volume II: The MIPS32™ Instruction Set Document Number: MD00086.Revision 2.00,June 9, 2003
[31]郑宜嘉. 一种兼容MIPS32指令集的RISC微处理器的设计与验证[D].西安电子科技大学,2017.
[32]微机原理与接口技术(第2版)/21世纪高等学校计算机规划教材
[33]胡伟武,汪文祥,吴瑞阳等.龙芯指令系统架构技术[J].计算机研究与发展,2023,60(01):2-16.
[34]MIPS32™ Architecture For Programmers Volume II: The MIPS32™ Instruction Set Document Number: MD00086.Revision 2.00,June 9, 2003
[36]刘明,刘学明.基于FPGA的专用软件硬件化技术探讨[J].赤峰学院学报(自然科学版),2015,31(13):38-39.DOI:10.13398/j.cnki.issn1673-260x.2015.13.017.
[37]刘少飞,王玉欢,杨海波等. 基于SoC的内存管理单元应用与验证[C]//中国航空学会.2019年(第四届)中国航空科学技术大会论文集.中航出版传媒有限责任公司(China Aviation Publishing & Media Co.,2019:6.
[38]《高等学校计算机科学与技术系列教材·计算机系统结构》,2008.6.1高等教育出版社出版,张晨曦、王志英
版权归原作者 物质波波波 所有, 如有侵权,请联系我们删除。