
一、前言
每到年底国债逆回购的利息都会来一波高涨,利息会比银行的T+0的理财产品的利息高,所以可以考虑写个脚本每天定时启动爬取逆回购数据,实时查看利息,然后在利息高位及时去下单。
二、环境搭建
详情请看《python爬虫进阶篇:Scrapy中使用Selenium模拟Firefox火狐浏览器爬取网页信息》
三、代码实现
- items
classBondSpiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 股票代码
bond_code = scrapy.Field()# 股票名称
bond_name = scrapy.Field()# 最新价
last_price = scrapy.Field()# 涨跌幅
rise_fall_rate = scrapy.Field()# 涨跌额
rise_fall_price = scrapy.Field()
- middlewares
def__init__(self):# ----------------firefox的设置------------------------------- #
self.options = firefox_options()defspider_opened(self, spider):
spider.logger.info('Spider opened: %s'% spider.name)
spider.driver = webdriver.Firefox(options=self.options)# 指定使用的浏览器defprocess_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be called
spider.driver.get(request.url)returnNonedefprocess_response(self, request, response, spider):# Called with the response returned from the downloader.# Must either;# - return a Response object# - return a Request object# - or raise IgnoreRequest
response_body = spider.driver.page_source
return HtmlResponse(url=request.url, body=response_body, encoding='utf-8', request=request)
- settings设置
SPIDER_MIDDLEWARES ={'bond_spider.middlewares.BondSpiderSpiderMiddleware':543,}
DOWNLOADER_MIDDLEWARES ={'bond_spider.middlewares.BondSpiderDownloaderMiddleware':543,}
ITEM_PIPELINES ={'bond_spider.pipelines.BondSpiderPipeline':300,}
- middlewares中间件
from selenium.webdriver.firefox.options import Options as firefox_options
spider.driver = webdriver.Firefox(options=firefox_options())# 指定使用的浏览器
- spider文件
defparse(self, response):# 股票代码
bond_code = response.css("table.table_wrapper-table tbody tr td:nth-child(2) a::text").extract()# 股票名称
bond_name = response.css("table.table_wrapper-table tbody tr td:nth-child(3) a::text").extract()# 最新价
last_price = response.css("table.table_wrapper-table tbody tr td:nth-child(4) span::text").extract()# 涨跌幅
rise_fall_rate = response.css("table.table_wrapper-table tbody tr td:nth-child(6) span::text").extract()# 涨跌额
rise_fall_price = response.css("table.table_wrapper-table tbody tr td:nth-child(5) span::text").extract()for i inrange(len(bond_code)):
item = BondSpiderItem()
item["bond_code"]= bond_code[i]
item["bond_name"]= bond_name[i]
item["last_price"]= last_price[i]
item["rise_fall_rate"]= rise_fall_rate[i]
item["rise_fall_price"]= rise_fall_price[i]yield item
print()defclose(self, spider):
spider.driver.quit()
- pipelines持久化
def__init__(self):
self.html ='<html><head><meta charset="utf-8"></head><body><table>'
self.html = self.html +'<tr>'
self.html = self.html +'<td>%s</td>'%"代码"
self.html = self.html +'<td>%s</td>'%"名称"
self.html = self.html +'<td>%s</td>'%"最新价"
self.html = self.html +'<td>%s</td>'%"涨跌幅"
self.html = self.html +'<td>%s</td>'%"涨跌额"
self.html = self.html +'</tr>'defprocess_item(self, item, spider):
self.html = self.html +'<tr>'
self.html = self.html +'<td>%s</td>'% item["bond_code"]
self.html = self.html +'<td>%s</td>'% item["bond_name"]
self.html = self.html +'<td>%s</td>'% item["last_price"]
self.html = self.html +'<td>%s</td>'% item["rise_fall_rate"]
self.html = self.html +'<td>%s</td>'% item["rise_fall_price"]
self.html = self.html +'</tr>'return item
defclose_spider(self, spider):
self.html = self.html +'</table></body></html>'
self.send_email(self.html)print()defsend_email(self, html):# 设置邮箱账号
account ="xxx"# 设置邮箱授权码
token ="xxx"# 实例化smtp对象,设置邮箱服务器,端口
smtp = smtplib.SMTP_SSL('smtp.qq.com',465)# 登录qq邮箱
smtp.login(account, token)# 添加正文,创建简单邮件对象
email_content = MIMEText(html,'html','utf-8')# 设置发送者信息
email_content['From']='xxx'# 设置接受者信息
email_content['To']='技术总是日积月累的'# 设置邮件标题
email_content['Subject']='来自code_space的一封信'# 发送邮件
smtp.sendmail(account,'xxx', email_content.as_string())# 关闭邮箱服务
smtp.quit()
四、测试结果
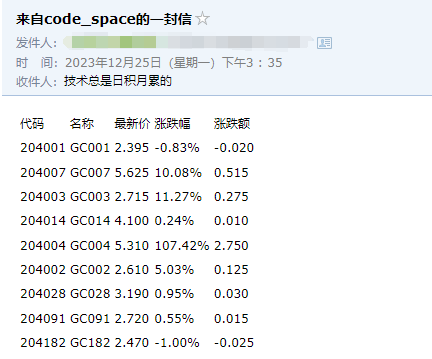
本文转载自: https://blog.csdn.net/qq_23730073/article/details/135201827
版权归原作者 code_space 所有, 如有侵权,请联系我们删除。
版权归原作者 code_space 所有, 如有侵权,请联系我们删除。