
创建Hadoop用户
2.1 创建Hadoop 用户(简单)
如果安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为
hadoop 的用户
首先按 **ctrl+alt+t **打开终端窗口,输入如下命令创建新用户:
$ sudo useradd –m hadoop –s /bin/bash
上面这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
$ sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较
棘手的权限问题:
$ sudo adduser hadoop sudo
2.2 安装 Hadoop 前的准备工作(如果网络没问题就很简单)
本节介绍安装Hadoop之前的一些准备工作,包括更新APT、安装vim编辑器、SSH。
2.2.1 更新 APT
为了确保Hadoop安装过程顺利进行,建议执行下面命令更新APT软件:
$ sudo apt-get update
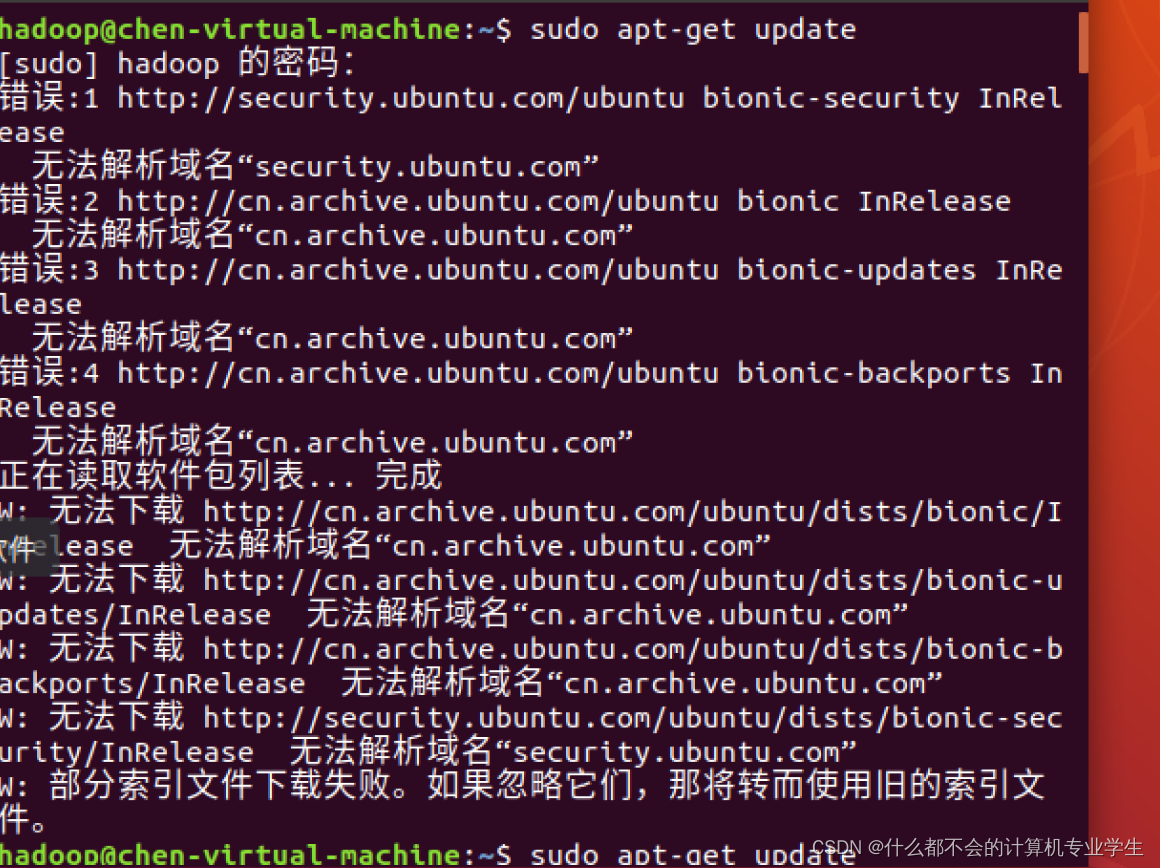
在这里我出现了问题,在安装好Ubuntu之后:
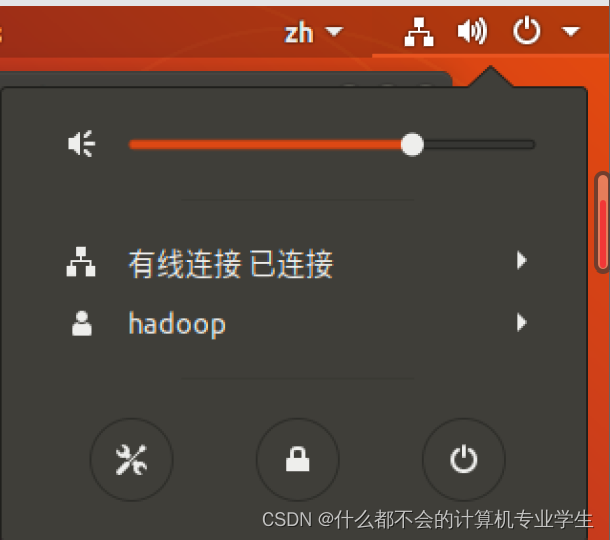
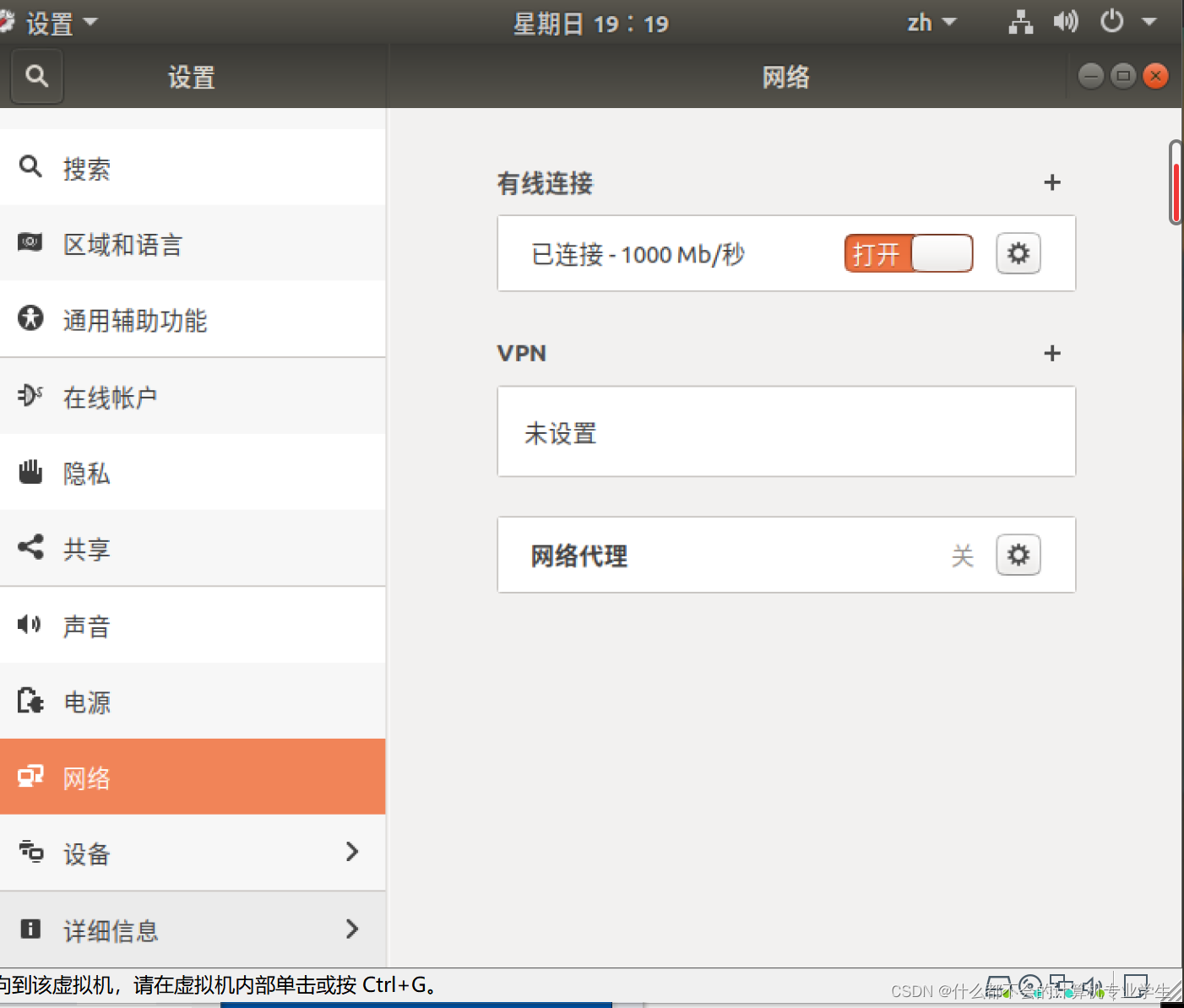
然后在网上找了许多方法都不可行,最后发现一个博主说要确定连网!!!!
连网:点击设置(左下角工具图标)--找到并打开网络(右下角网络适配器要连接并且是NAT)
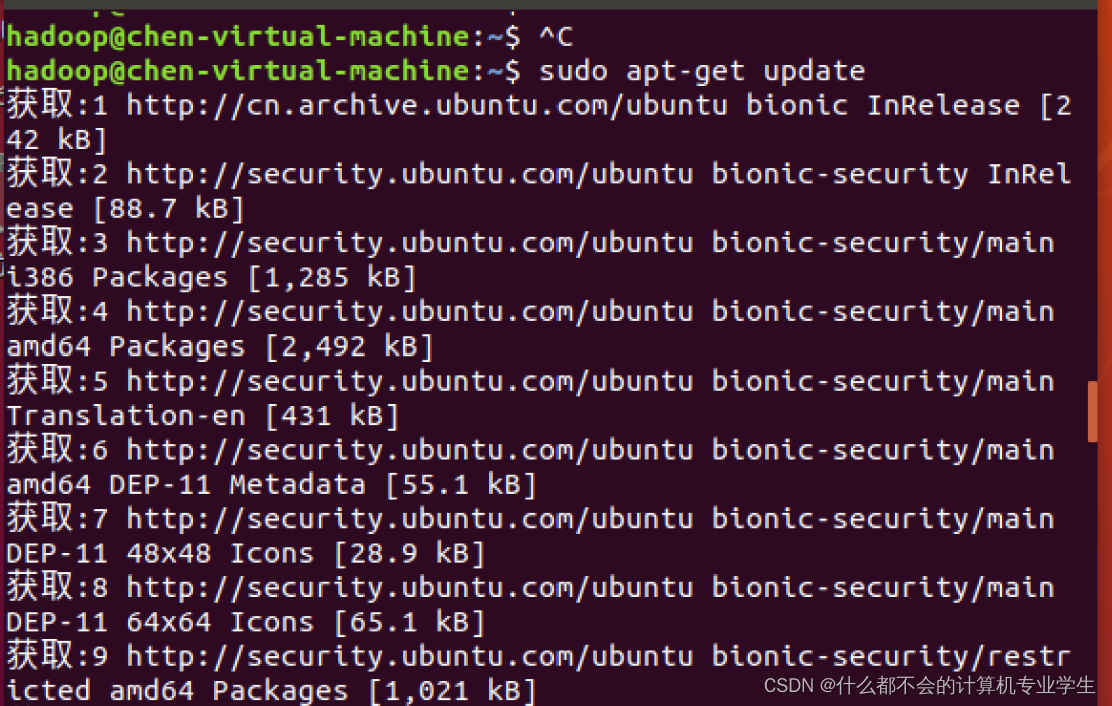
以上才确保了是在连网状态下!!!!然后当你在输入更新命令时会是这样:
这会花费一定的时间!!!
2.2.2 安装vim编辑器
在Ubuntu操作系统中,可以使用vim编辑器来创建文件和修改文件,执行如下命令安装vim编辑器
$ sudo apt-get install vim
安装时需要输入密码,若需要确认,在提示处输入y即可(耐心等待);
2.2.3安装 SSH
Ubuntu默认已安装了SSH客户端,因此,这里还需要安装SSH服务端,请在Linux的终端中执行以下命令:
$ sudo apt-get install openssh-server
安装后,可以使用如下命令登录本机:
$ ssh localhost
如果使用的就是stu账户目标登陆账户也是stu,登陆之后用户没有变化,会造成没有反馈的感觉。
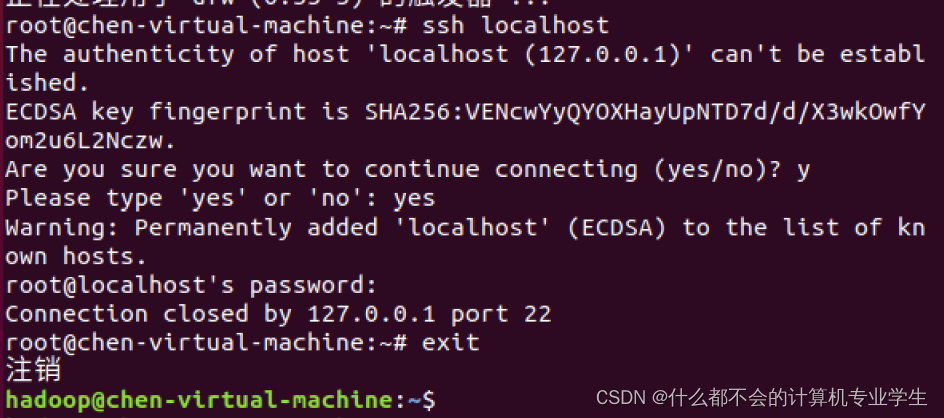
然后,请输入命令
exit
退出刚才的SSH,就回到了原先的终端窗口;然后,可以利用
ssh-keygen
生成密钥,并将密钥加入到授权中,命令如下:
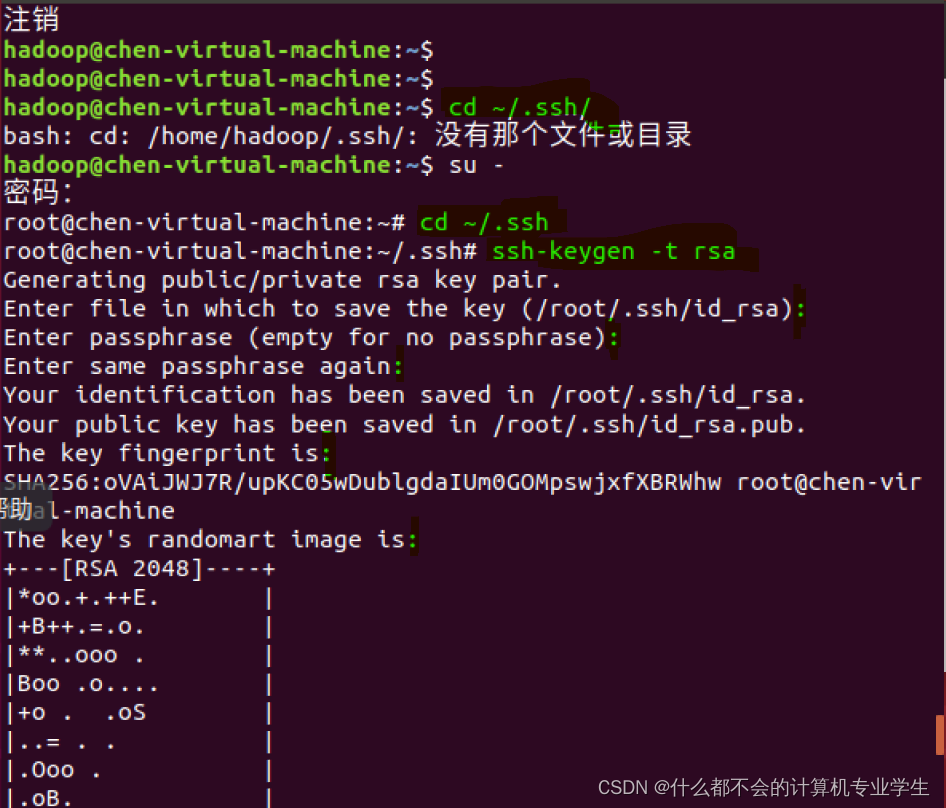
$exit
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车即可
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
在root用户下执行以上操作(:后边都敲回车)
中间用cat命令追加,然后ssh localhost就能实现免密登陆了
exit退出ssh!
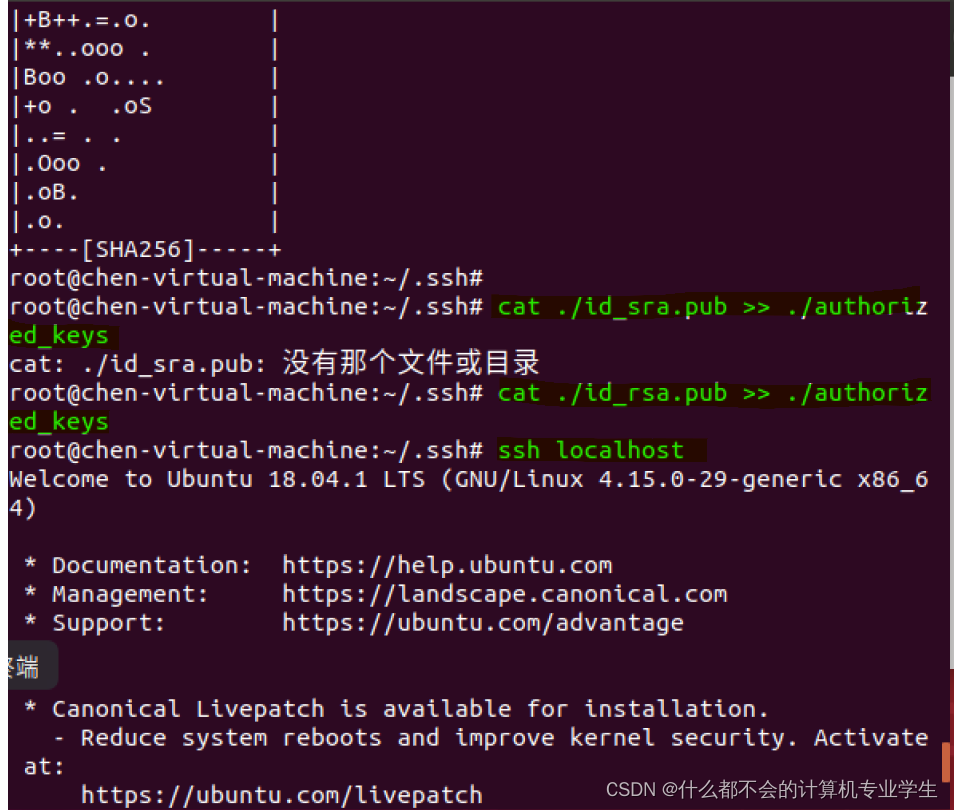

此时,再执行
ssh localhost
命令,无需输入密码就可以直接登录了。
2.3 安装 Java 环境
由于Hadoop本身是使用Java语言编写的,因此,
Hadoop
的开发和运行都需要Java的支持,对于
Hadoop3.1.3
而言,要求使用
JDK1.8
或者更新的版本。
可从Oracle官网下载
JDK1.8
安装包也可从课程准备好的镜像地址下载,执行如下命令创建
/usr/lib/jvm
目录用来存放JDK文件:
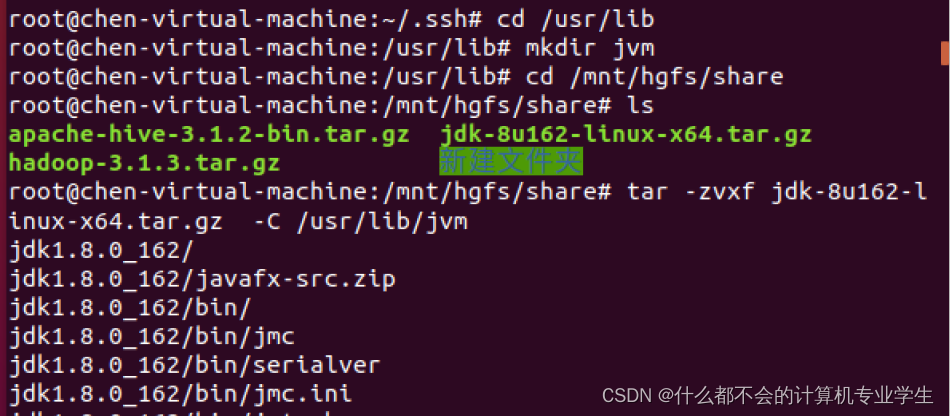
$ cd /usr/lib
$ sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
执行如下命令对安装文件进行解压缩:(提前设置好共享文件夹)
我也有总结---原文链接:https://blog.csdn.net/m0_59865073/article/details/128192013
$ cd ~ #进入stu用户的主目录
$ cd Downloads #切换到压缩包所在目录
$ sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
以上两步操作的代码运行截图:
下面继续执行如下命令,设置环境变量:
$ vim ~/.bashrc
如果
vim使用不熟悉,同学们可以使用
gedit
上面命令使用vim编辑器打开了
hadoop
这个用户的环境变量配置文件,请在这个文件的末尾位置(刚开始复制添加在文件开头,但是不成功,就自己输入进了文件末尾,也有可能是不允许复制粘贴,会有错误;注意不要写在哪个函数中了,例如if fi),添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存
.bashrc
文件并退出vim编辑器。然后,继续执行如下命令让
.bashrc
文件的配置立即生效:
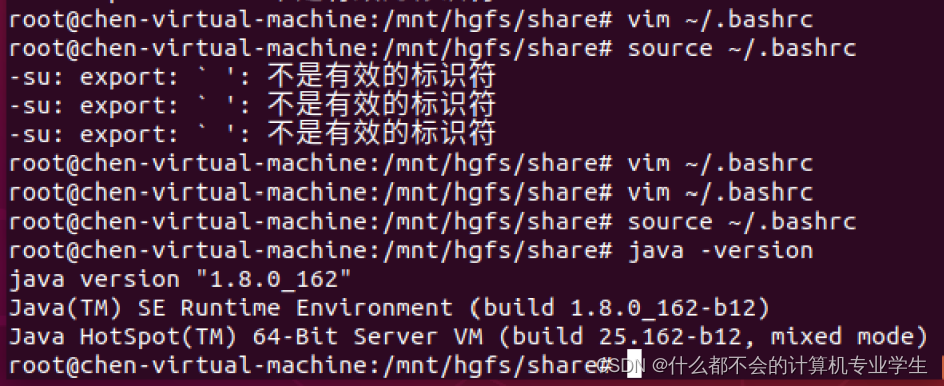
$ source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
$ java -version
如果能够在屏幕上返回如下信息,则说明安装成功:
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
以上几步代码运行截图:
至此,就成功安装了Java环境。下面就可以进入
Hadoop
的安装。
2.4 安装Hadoop
Hadoop包括三种安装模式:
- 单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统
HDFS; - 伪分布式模式:存储采用分布式文件系统
HDFS,但是HDFS的名称节点和数据节点都在同一台机器上; - 分布式模式:存储采用分布式文件系统
HDFS,而且HDFS的名称节点和数据节点位于不同机器上。
本节介绍Hadoop的具体安装方法,包括安装单机Hadoop、Hadoop伪分布式安装。
2.4.1 安装单机Hadoop
可从Hadoop官网下载安装文件
hadoop-3.1.3.tar.gz
,假设下载得到的安装文件为
hadoop-3.1.3.tar.gz
。下载完安装文件以后,需要对文件进行解压。按照Linux系统使用的默认规范,用户安装的软件一般都是存放在
/usr/local/
目录下。
请使用stu/root用户登录Linux系统,打开一个终端,执行如下命令:(虚线以上笼统,以下具体)
$ cd ~/Downloads # 进入下载目录
$ wget -c http://res.aihyzh.com/大数据技术原理与应用3/02/hadoop-3.1.3.tar.gz #下载资源
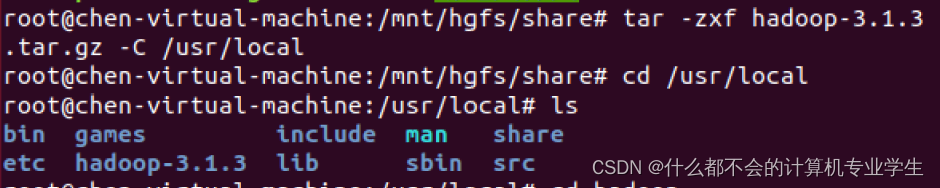
$ sudo tar -zxf ~/Downloads/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
-----------------------------------------------------------------------------------------
$ sudo tar -zxf */hadoop-3.1.3.tar.gz -C /usr/local #将共享文件夹里的压缩包解压到、usr/local中
$ cd /usr/local/
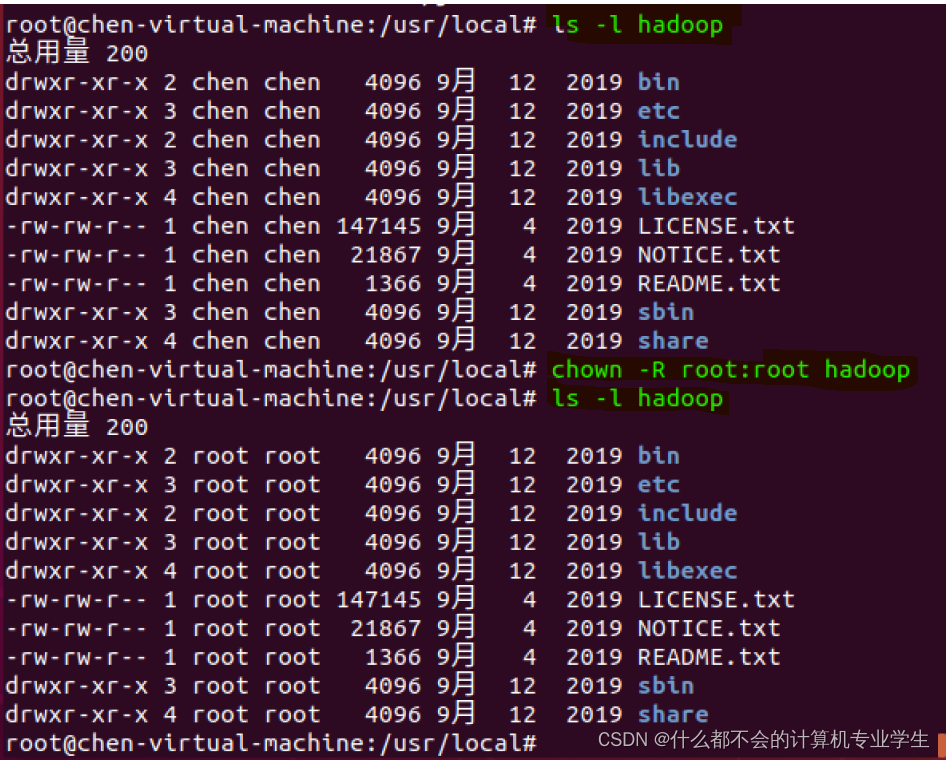
$ sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop(./表示当前路径下的)
$ sudo chown -R stu:stu ./hadoop # 修改文件权限(-R 递归处理,对指定目录下的所有文件及子目录一并进行处理)
Hadoop解压后即可使用,可以输入如下命令来检查 Hadoop是否可用,成功则会显示 Hadoop版本信息:
$ ./bin/hadoop version #查看版本信息
以上几步代码运行截图:
修改权限具体看管理员账户id,不同的操作系统管理员账户不同,但管理员账户都有一切权限:


2.4.2Hadoop伪分布式安装
Hadoop可以在单个节点(一台机器)上以伪分布式的方式运行,同一个节点既作为名称节点
(NameNode)
,也作为数据节点
(DataNode)
,读取的是分布式文件系统 HDFS 中的文件。
2.4.2.1修改配置文件
需要配置相关文件,才能够让Hadoop在伪分布式模式下顺利运行。Hadoop的配置文件位于
/usr/local/hadoop/etc/hadoop/
中,进行伪分布式模式配置时,需要修改3个配置文件,即
hadoop-env.sh
,
core-site.xml
和
hdfs-site.xml
。
可以使用vim编辑器打开
hadoop-env.sh
文件,进行修改
JAVA_HOME
配置,添加一行代码:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
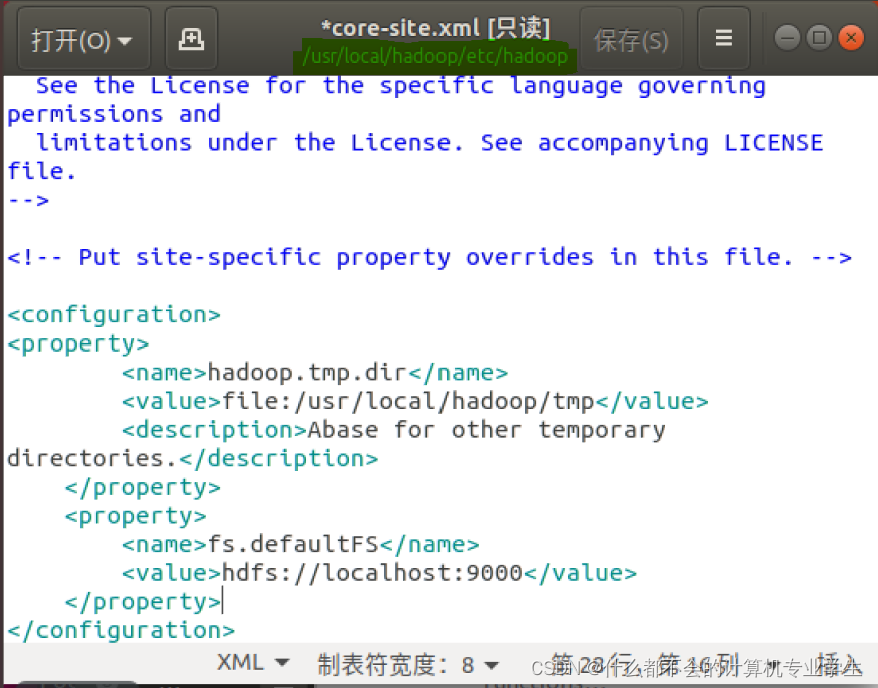
可以使用vim编辑器打开
core-site.xml
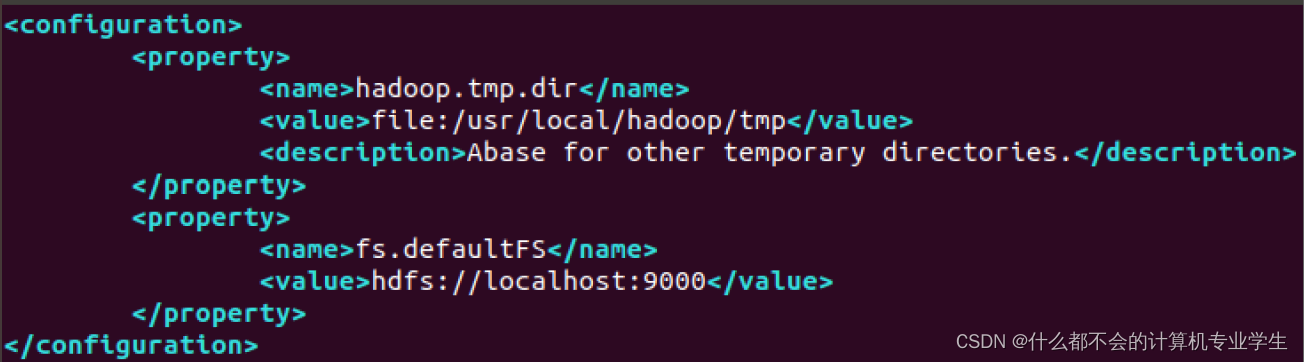
文件,修改以后,
core-site.xml
文件的内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property> #人为定义一个存放集群数据的磁盘空间tmp(自定义)
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property> #定义整个集群管理集的IP和端口号
</configuration>
在
core-site.xml
文件中,
hadoop.tmp.dir
用于保存临时文件,若没有配置
hadoop.tmp.dir
这个参数,则默认使用的临时目录为
/tmp/hadoo-hadoop
,而这个目录在Hadoop重启时有可能被系统清理掉,导致一些意想不到的问题,因此,必须配置这个参数。
fs.defaultFS
这个参数,用于指定
HDFS的
访问地址,其中,
9000
是端口号。
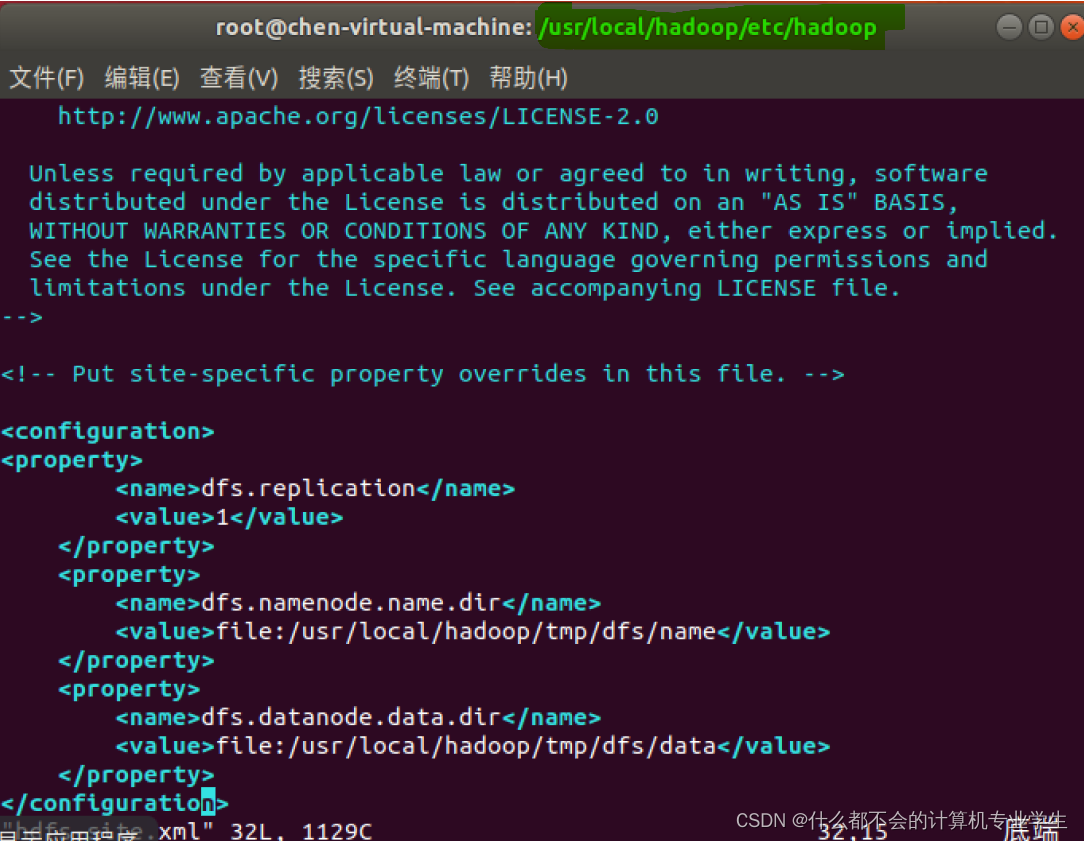
同样,需要修改配置文件
hdfs-site.xml
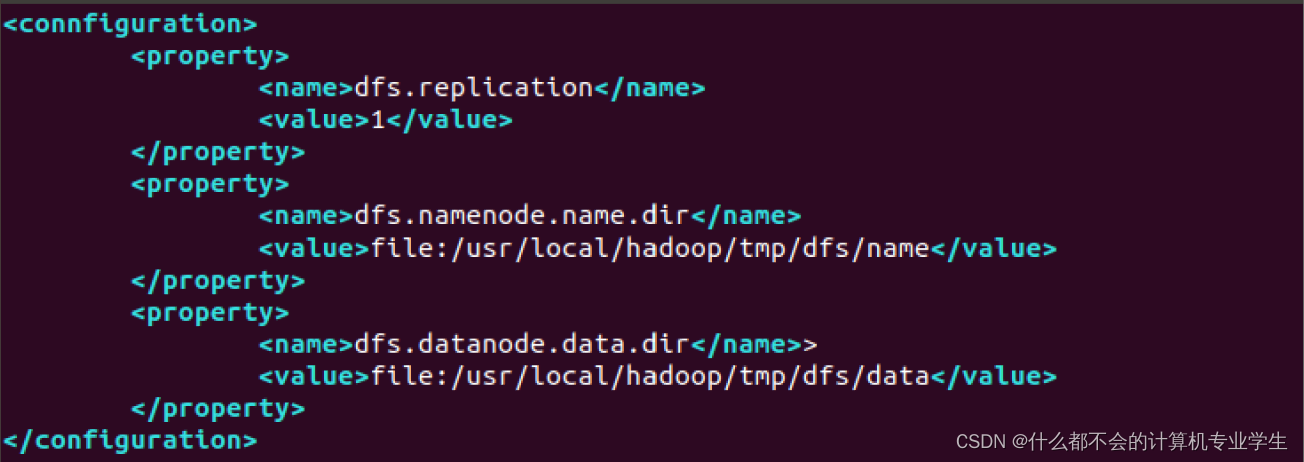
,修改后的内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value> #管理集数据
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value> #真正存放数据的目录
</property>
</configuration>
在
hdfs-site.xml
文件中,
dfs.replication
这个参数用于指定副本的数量,因为,在分布式文件系统
HDFS
中,数据会被冗余存储多份,以保证可靠性和可用性。但是,由于这里采用伪分布式模式,只有一个节点,因此,只可能有1个副本,因此,设置
dfs.replication
的值为1。
dfs.namenode.name.dir
用于设定名称节点的元数据的保存目录,
dfs.datanode.data.dir
用于设定数据节点的数据保存目录,这两个参数必须设定,否则后面会出错。
代码截图:(这里我没有将路径切换到
/usr/local/hadoop/etc/hadoop/)所以后续出了错


需要指出的是,Hadoop的运行方式(比如运行在单机模式下还是运行在伪分布式模式下),是由配置文件决定的,启动Hadoop时会读取配置文件,然后根据配置文件来决定f运行在什么模式下。因此,如果需要从伪分布式模式切换回单机模式,只需要删除
core-site.xml
中的配置项即可。
2.4.2.2初始化文件系统
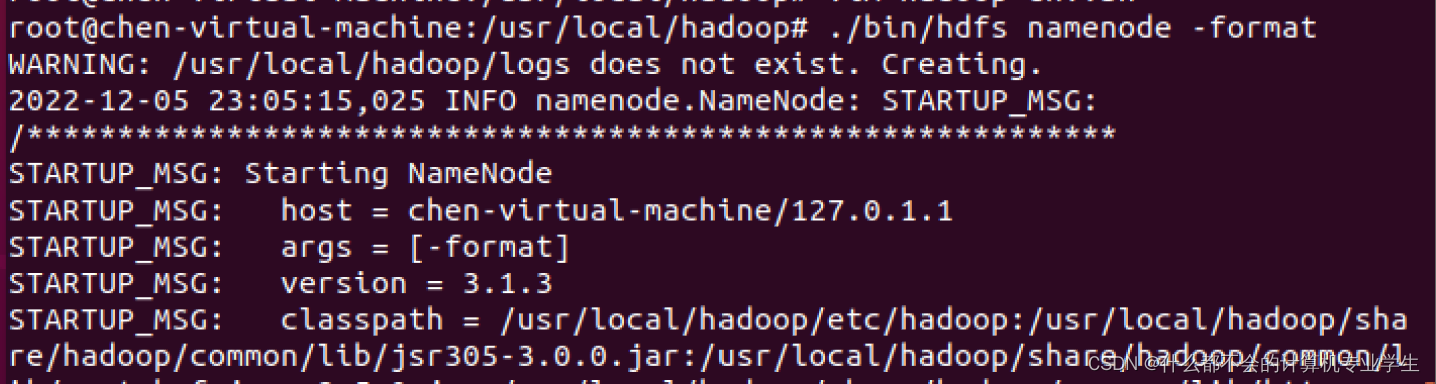
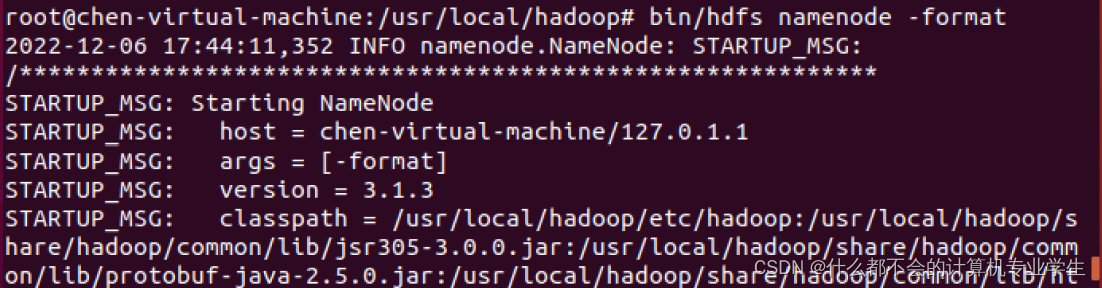
修改配置文件以后,要执行名称节点的格式化,命令如下:
$ cd /usr/local/hadoop
$ ./bin/hdfs namenode -format
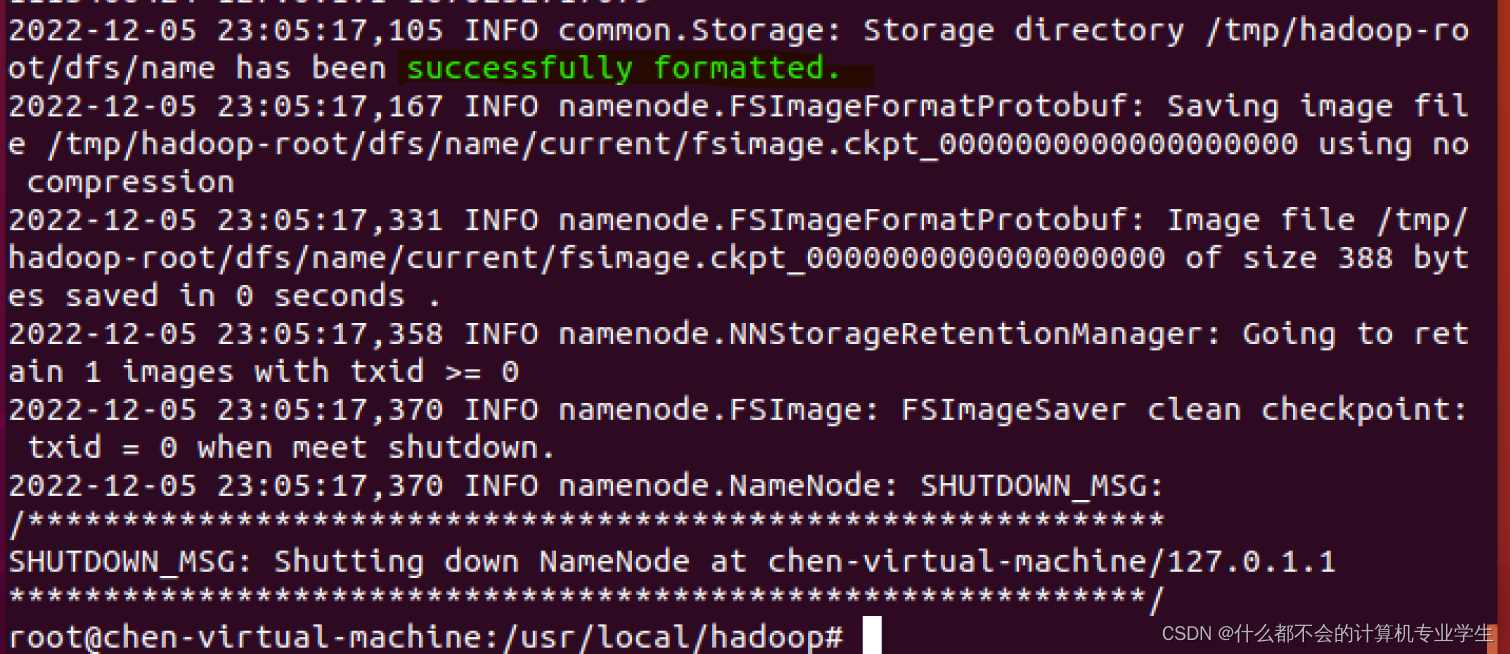
如果格式化成功,会看到
successfully formatted
和
Exitting with status 0
的提示信息,若为
Exitting with status 1
,则表示出现错误。
如果在执行这一步时提示错误信息
Error: JAVA_HOME is not set and could not be found
,则说明之前设置
JAVA_HOME环境变量
的时候,没有设置成功,请按前面的教程先设置好
JAVA_HOME变量
,否则,后面的过程都无法顺利进行。
格式化成功:

2.4.2.3启动Hadoop(第一次会出现很多问题,所以附上解决方法)
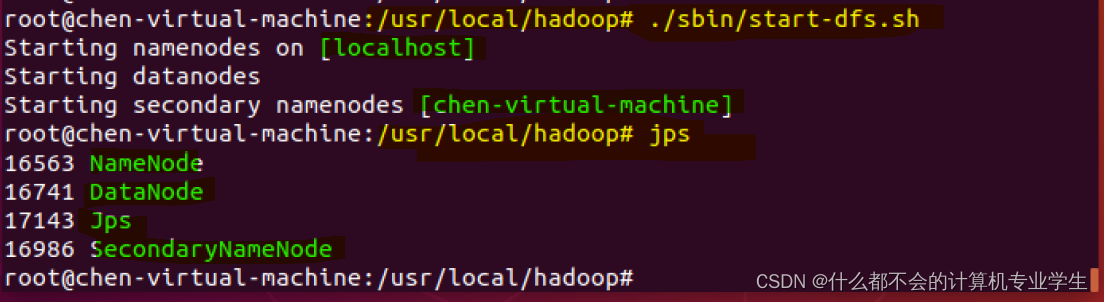
执行下面命令启动Hadoop:
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
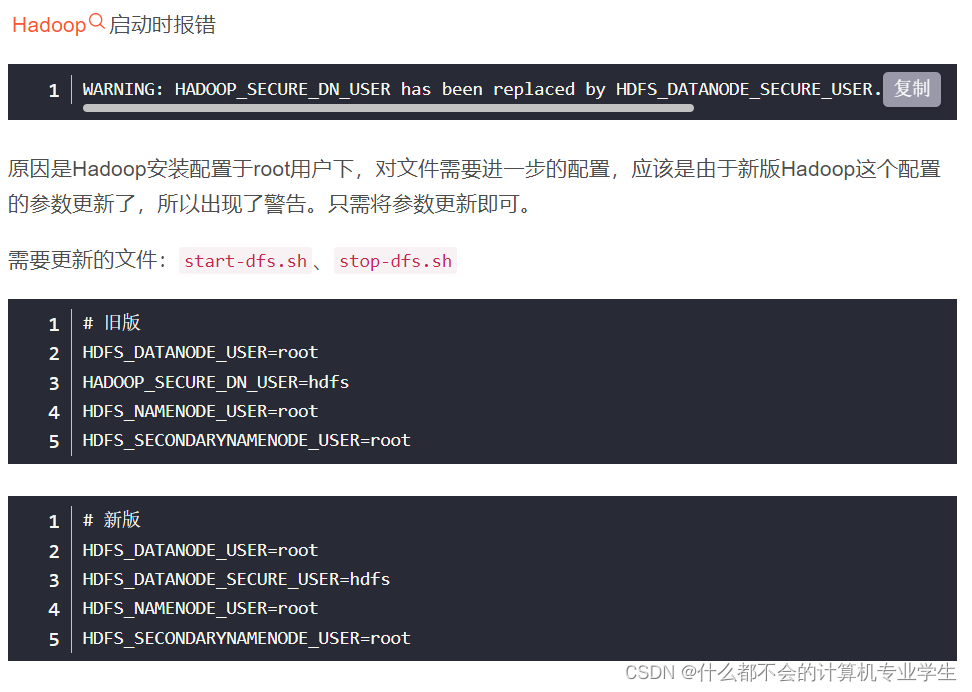
启动时可能会出现如下(1)警告信息:
Starting namenodes on [chen-virtual-machine]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [chen-virtual-machine]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
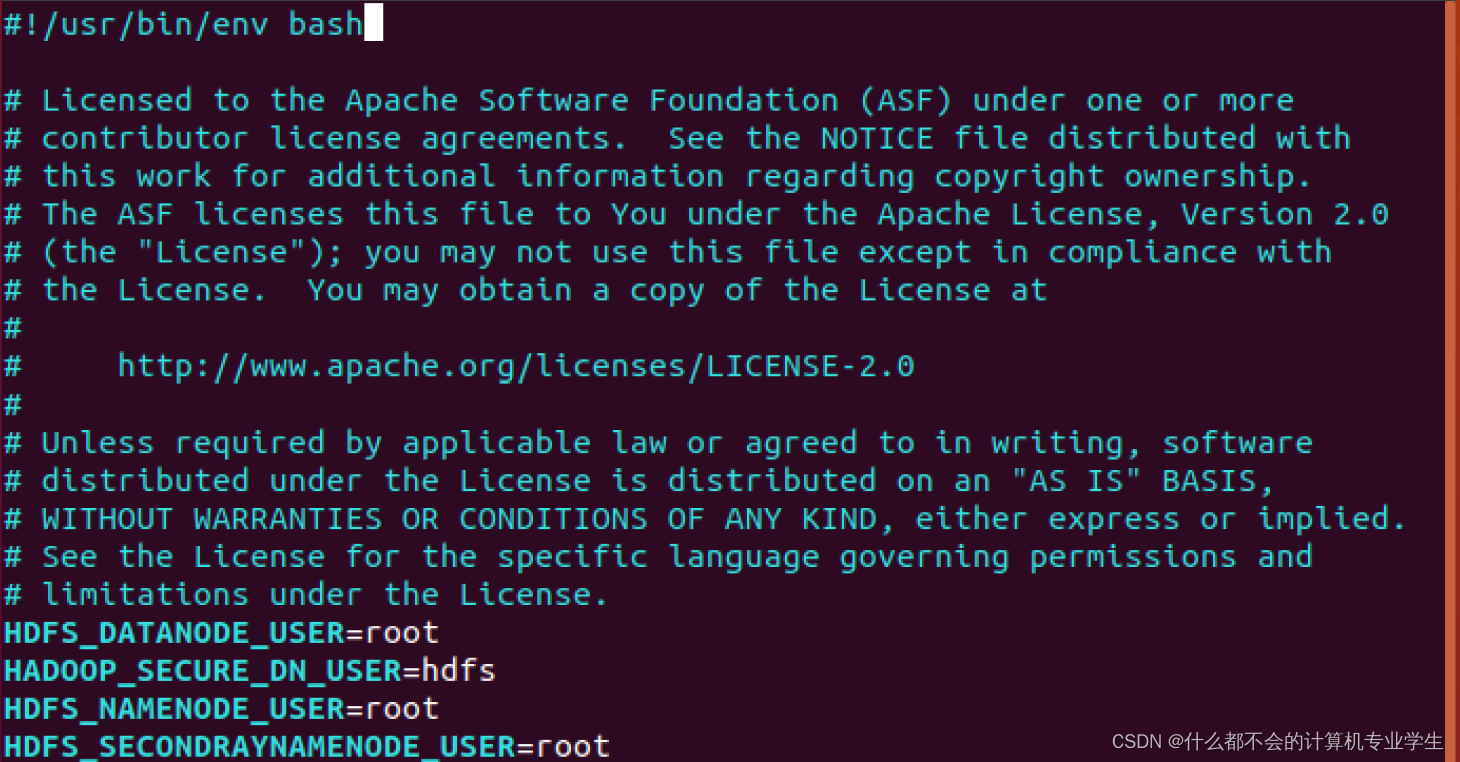
这个警告提示信息不可以忽略,会影响Hadoop正常使用。这是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本:
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
原文链接:https://blog.csdn.net/u013725455/article/details/70147331(2)仍然报错:
原文链接:https://blog.csdn.net/UZDW_/article/details/107380367
(3)仍然报错:ERROR: JAVA_HOME is not set and could not be found.
具体修改成的路径根据自己的设置,保存后退出。
原文链接:https://blog.csdn.net/dianzishijian/article/details/52094569(4)仍然报错:chen-virtual-machine: Warning: Permanently added 'chen-virtual-machine' (ECDSA) to the list of known hosts.
解决方法: 将 /etc/ssh/ssh_config 中的
StrictHostKeyChecking ask 改成 StrictHostKeyChecking no
(5)继续报错:
解决方法:命令行输入 sudo gedit /etc/ssh/sshd_configr 然后修改文件内容


Hadoop启动完成后,可以通过命令 jps 来判断是否成功启动,命令如下:
$ jps
若成功启动,则会列出如下进程:
NameNode
、
DataNode
和
SecondaryNameNode
。
如果看不到
SecondaryNameNode进程,请运行命令
./sbin/stop-dfs.sh关闭
Hadoop相关进程,然后,再次尝试启动。如果看不到
NameNode或
DataNode进程,则表示配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。如果少线程,先关闭集群stop-dfs.sh;然后删除tmp,再重新格式化!!!!!
一、缺少三个线程(配置文件时路径错误):(6)
发现上边修改配置文件时,直接vim core-site.xml而不是在指定目录下配置文件 :
这样才是修改hadoop的配置文件,而不是直接在/usr/local/hadoop文件夹下创建配置文件:
这是之前“仍然报错:ERROR: JAVA_HOME is not set and could not be found.”时已经修改过的:
二、缺少namenode线程(修改好配置文件之后):
(7)关闭集群--删除tmp文件夹--重新格式化
重新格式化成功:



通过
start-dfs.sh
命令启动
Hadoop
以后,就可以运行
MapReduce
程序处理数据,此时是对
HDFS
进行数据读写,而不是对本地文件进行读写。
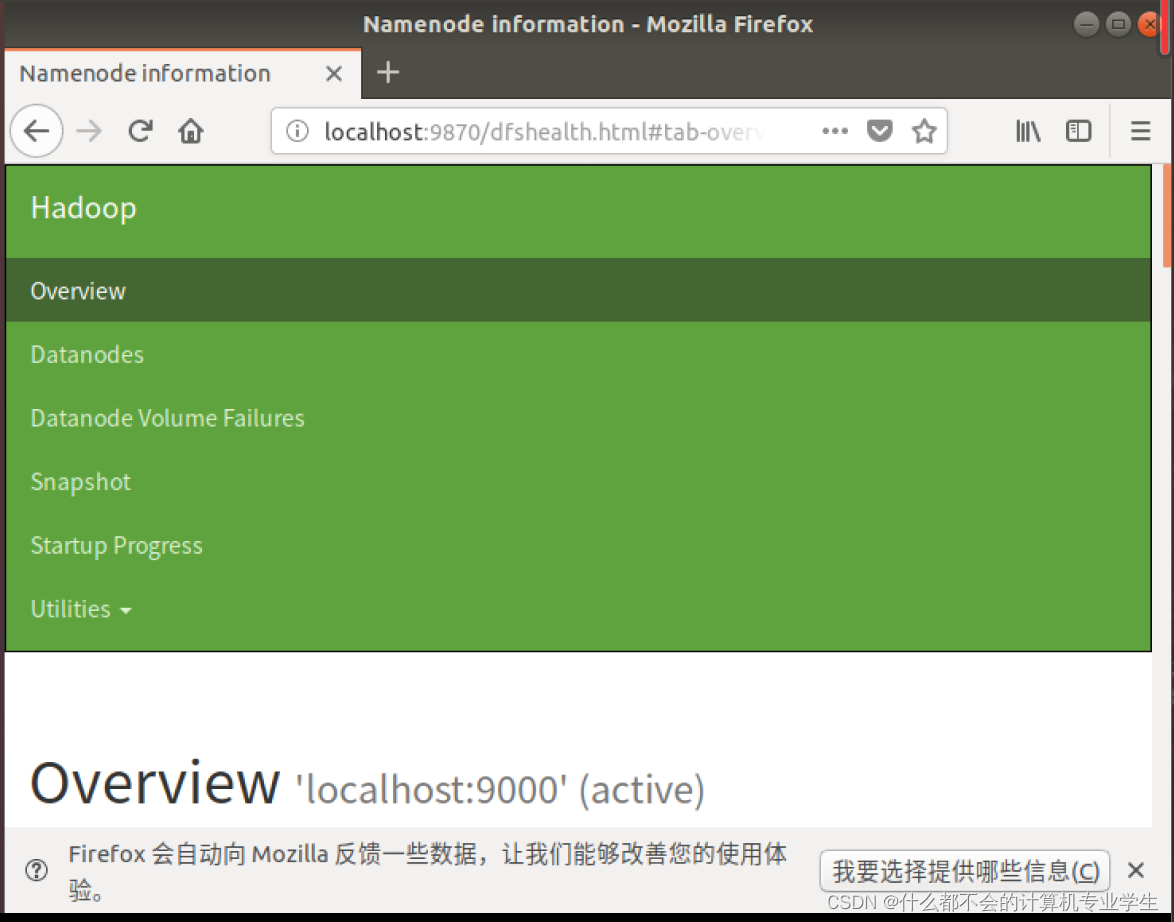
2.4.2.4使用Web界面查看HDFS信息
Hadoop成功启动后,可以在Linux系统中(不是Windows系统)打开一个浏览器,在地址栏输入地址
http://localhost:9870
,就可以查看名称节点和数据节点信息,还可以在线查看 HDFS 中的文件。
hadoop3.X的Web UI端口为:9870
hadoop2.X的Web UI端口为:50070
旧版本与新版本之间端口号有不一致的地方,但Ubuntu18.0.4是如图所示:
2.4.2.5运行Hadoop伪分布式实例
单机模式中,
grep
例子读取的是本地数据,但在伪分布式模式下,读取的则是分布式文件系统
HDFS
上的数据。要使用
HDFS
,首先需要在
HDFS
中创建用户目录,命令如下:
$ cd /usr/local/hadoop
$ ./bin/hdfs dfs -mkdir -p /user/hadoop
接着需要把本地文件系统的
/usr/local/hadoop/etc/hadoop
目录中的所有xml文件作为输入文件,复制到分布式文件系统HDFS中的
/user/stu/input
目录中,命令如下:
$ cd /usr/local/hadoop
$ ./bin/hdfs dfs -mkdir /user/hadoop/input #在HDFS中创建hadoop用户对应的input目录
$ ./bin/hdfs dfs -put ./etc/hadoop/*.xml input #把本地文件复制到HDFS中
复制完成后,可以通过如下命令查看HDFS中的文件列表:
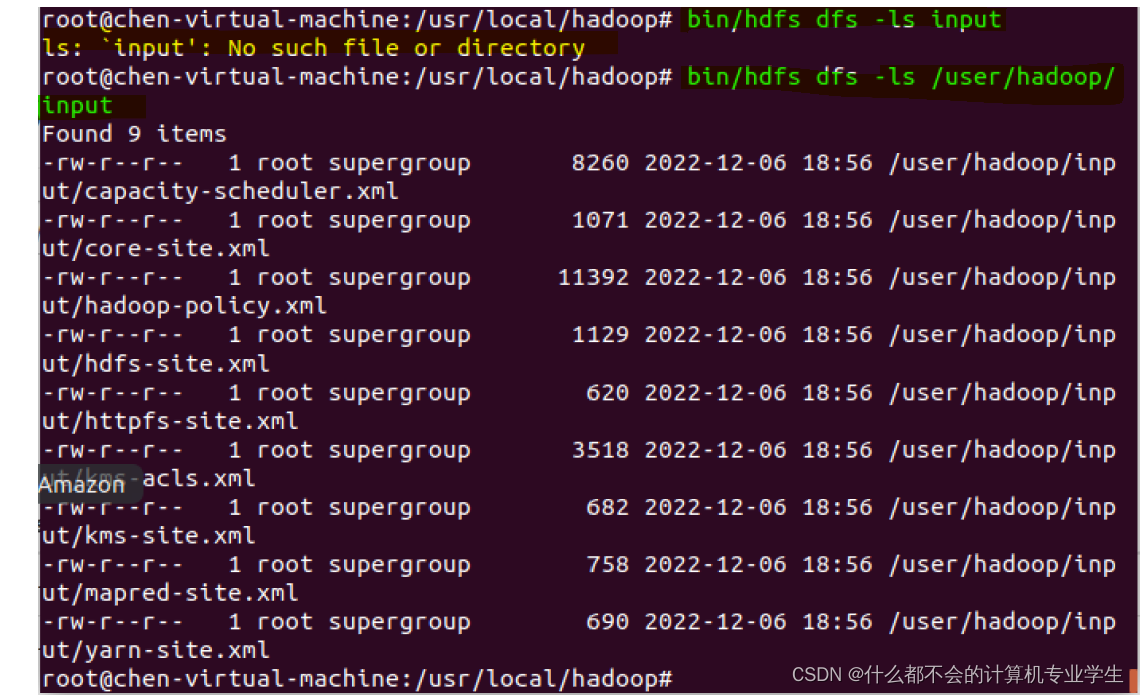
$ ./bin/hdfs dfs -ls input
执行上述命令以后,可以看到
input
目录下的文件信息。
现在就可以运行
Hadoop
自带的
grep
程序,命令如下:
$ ./bin/hadoop
jar
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
grep input output 'dfs[a-z.]+'
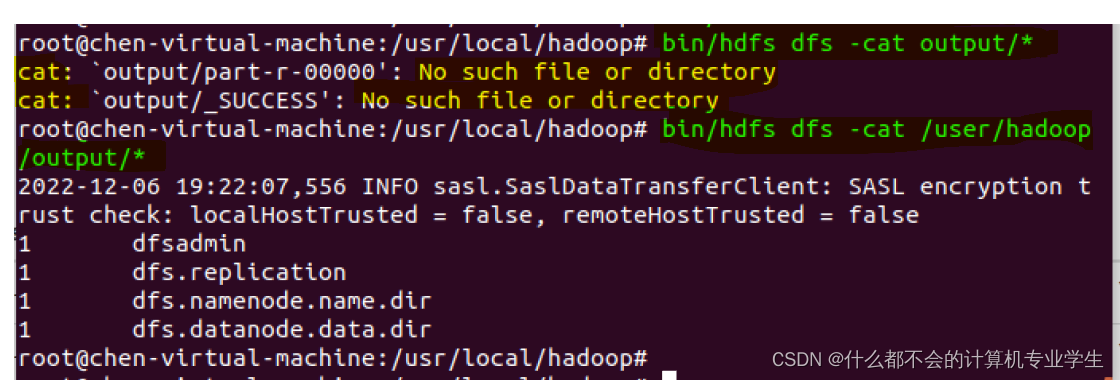
运行结束后,可以通过如下命令查看HDFS中的
output
文件夹中的内容:
$ ./bin/hdfs dfs -cat output/*
需要强调的是,Hadoop运行程序时,输出目录不能存在,否则会提示如下错误信息:

以上代码运行截图:
(8)报错:hdfs 不识别/user/hadoop为默认那个文件夹
解决:每次操作都具体到绝对路径(从根目录开始)




因此,若要再次执行grep程序,需要执行如下命令删除HDFS中的output文件夹:
$ ./bin/hdfs dfs -rm -r output # 删除 output 文件夹
2.4.2.6关闭Hadoop
如果要关闭Hadoop,可以执行下面命令:
$ cd /usr/local/hadoop
$ ./sbin/stop-dfs.sh
下次启动Hadoop时,无需进行名称节点的初始化(否则会出错),也就是说,不要再次执行
hdfs namenode -format
命令,每次启动Hadoop只需要直接运行./sbin/
start-dfs.sh
命令即可。
2.4.2.7配置PATH变量(便于执行命令,可略)
前面在启动Hadoop时,都要加上命令的路径,比如,
./sbin/start-dfs.sh
这个命令中就带上了路径,实际上,通过设置PATH变量,就可以在执行命令时,不用带上命令本身所在的路径。
比如,我们打开一个Linux终端,在任何一个目录下执行
ls
命令时,都没有带上
ls
命令的路径,实际上,执行
ls
命令时,是执行
/bin/ls
这个程序,之所以不需要带上路径,是因为Linux系统已经把
ls
命令的路径加入到PATH变量中,当执行
ls
命令时,系统是根据 PATH 这个环境变量中包含的目录位置,逐一进行查找,直至在这些目录位置下找到匹配的
ls
程序(若没有匹配的程序,则系统会提示该命令不存在)。
知道了这个原理以后,我们同样可以把
start-dfs.sh
、
stop-dfs.sh
等命令所在的目录
/usr/local/hadoop/sbin
,加入到环境变量PATH中,这样,以后在任何目录下都可以直接使用命令
start-dfs.sh
启动Hadoop,不用带上命令路径。
具体操作方法是,首先使用vim编辑器打开
~/.bashrc
这个文件,然后,在这个文件的最前面位置加入如下单独一行:
export PATH=$PATH:/usr/local/hadoop/sbin
在后面的学习过程中,如果要继续把其他命令的路径也加入到PATH变量中,也需要继续修改
~/.bashrc
这个文件。当后面要继续加入新的路径时,只要用英文冒号“:”隔开,把新的路径加到后面即可,比如,如果要继续把
/usr/local/hadoop/bin
路径增加到PATH中,只要继续追加到后面,如下所示:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
添加后,执行命令
source ~/.bashrc
使设置生效。设置生效后,在任何目录下启动Hadoop,都只要直接输入
start-dfs.sh
命令即可,同理,停止Hadoop,也只需要在任何目录下输入
stop-dfs.sh
命令即可。
版权归原作者 什么都不会的计算机专业学生 所有, 如有侵权,请联系我们删除。