
Jetson Nano配置YOLOv5并实现FPS=25的实时检测(超详细保姆级)
文章目录
一、版本说明
JetPack 4.6——2021.8
yolov5-v6.0版本
使用的为yolov5的yolov5n.pt,并利用tensorrtx进行加速推理,在调用摄像头实时检测可以达到FPS=25。
二、配置CUDA
sudo gedit ~/.bashrc
在打开的文档的末尾添加如下:
export CUDA_HOME=/usr/local/cuda-10.2
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.2/bin:$PATH
保持并退出,终端执行
source ~/.bashrc
nvcc -V #如果配置成功可以看到CUDA的版本号
三、修改Nano板显存
1.打开终端输入:
sudo gedit /etc/systemd/nvzramconfig.sh
2.修改nvzramconfig.sh文件
修改mem = $((("${totalmem}"/2/"${NRDEVICES}")*1024))
为mem = $((("${totalmem}"*2/"${NRDEVICES}")*1024))
3.重启Jetson Nano
4.终端中输入:
free -h
可查看到swap已经变为7.7G
四、配置Pytorch1.8
1.下载torch-1.8.0-cp36-cp36m-linux_aarch64.whl
下载地址:nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl
网盘分享:链接:https://pan.baidu.com/s/1tS51E3a-a-w9_OdCNraoAg
提取码:30qr
说明:建议在电脑上下载后拷贝到Jetson Nano的文件夹下,因为该网站的服务器在国外,可能下载比较慢或网页加载不出来,可以打开VPN进行下载。
2.安装所需的依赖包及pytorch
打开终端输入:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
因为下面用pip指令安装时用默认选用的国外源,所以下载比较费时间,建议更换一下国内源,这里提供几种源,当使用某种国内源pip无法下载某一包时可以尝试切换再下载。具体步骤如下:
打开终端输入:
mkdir ~/.pip
sudo gedit ~/.pip/pip.conf
在空白文件中输入如下内容保存并退出:
以下为豆瓣源
[global]
timeout=6000
index-url=https://pypi.doubanio.com/simple
trusted-host=pypi.doubanio.com
以下为阿里源
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
以下为清华源
[global]
index-url=https://pypi.tuna.tsinghua.edu.cn/simple/
[install]
trusted-host=https://pypi.tuna.tsinghua.edu.cn
终端输入:
pip3 install --upgrade pip #如果pip已是最新,可不执行
pip3 install Cython
pip3 install numpy
pip3 install torch-1.8.0-cp36-cp36m-linux_aarch64.whl #注意要在存放该文件下的位置打开终端并运行
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision #下载torchvision,会下载一个文件夹
cd torchvision #或者进入到这个文件夹,右键打开终端
export BUILD_VERSION=0.9.0
python3 setup.py install --user #时间较久
#验证torch和torchvision这两个模块是否安装成功
python3
import torch
print(torch.__version__) #注意version前后都是有两个横杠
#如果安装成功会打印出版本号
import torchvision
print(torchvision.__version__)
#如果安装成功会打印出版本号
五、搭建yolov5环境
终端中输入:
git clone https://github.com/ultralytics/yolov5.git #因为不开VPN很容易下载出错,建议在电脑中下载后拷贝到jetson nano中
python3 -m pip install --upgrade pip
cd yolov5 #如果是手动下载的,文件名称为yolov5-master.zip压缩包格式,所以要对用unzip yolov5-master.zip进行解压,然后再进入到该文件夹
pip3 install -r requirements.txt #我的问题是对matplotlib包装不上,解决办法,在下方。如果其他包安装不上,可去重新执行换源那一步,更换另一种国内源。
python3 -m pip list #可查看python中安装的包
以下指令可以用来测试yolov5
python3 detect.py --source data/images/bus.jpg --weights yolov5n.pt --img 640 #图片测试
python3 detect.py --source video.mp4 --weights yolov5n.pt --img 640 #视频测试,需要自己准备视频
python3 detect.py --source 0 --weights yolov5n.pt --img 640 #摄像头测试
问题1:解决matplotlib安装不上问题
解决:下载matplotlib的whl包(下方有网盘分享)
问题2:在运行yolov5的detect.py文件时出现 “Illegal instruction(core dumped)”
解决:
sudo gedit ~/.bashrc
末尾添加
export OPENBLAS_CORETYPE=ARMV8
保持关闭
source ~/.bashrc
网盘分享:
yolov5:链接:https://pan.baidu.com/s/1oGLTyUZ9TzEWO1VfxV70yw
提取码:3ran
yolov5n.pt:链接:https://pan.baidu.com/s/1k-EDuIJgKc_9OYubWOhJcg
提取码:oe0w
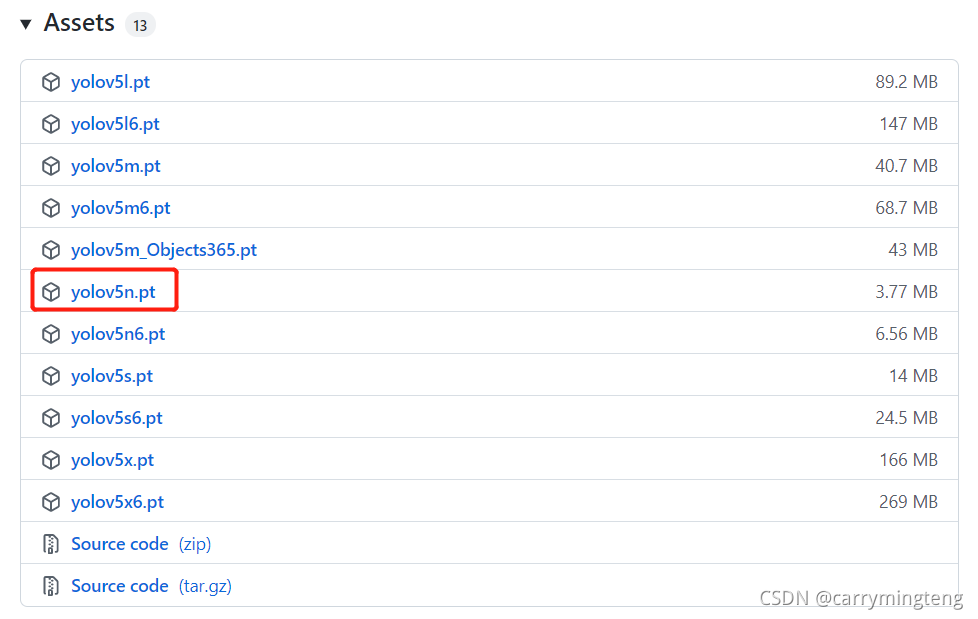
下载yolov5n.pt文件在https://github.com/ultralytics/yolov5中下载,如图位置所示
matplotlib:链接:https://pan.baidu.com/s/19DanfBYMxKerxlDSuIF8MQ
提取码:fp4i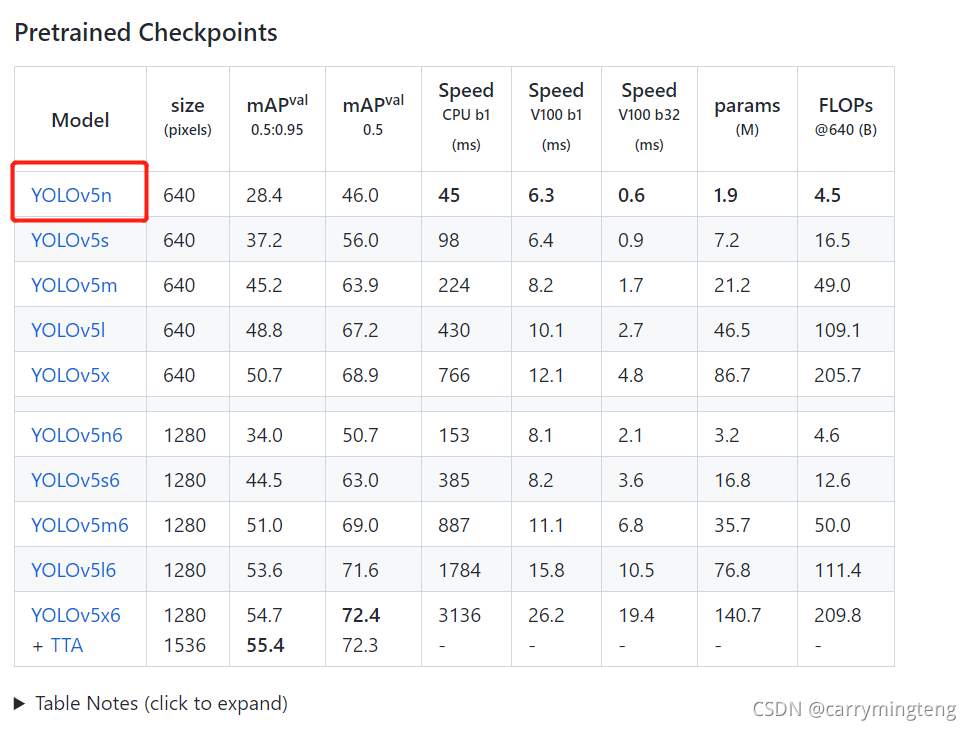
六、利用tensorrtx加速推理
1.下载tensorrtx
下载地址:https://github.com/wang-xinyu/tensorrtx.git
或者
git clone https://github.com/wang-xinyu/tensorrtx.git
网盘分享:链接:https://pan.baidu.com/s/14vCw3V74bWrT_3QQ-Yk–A
提取码:3zom
2.编译
将下载的tensorrtx项目中的yolov5/gen_wts.py复制到上述的yolov5(注意:不是tensorrtx下的yolov5!!!)下,然后在此处打开终端
打开终端输入:
python3 gen_wts.py -w yolov5n.pt -o yolov5n.wts #生成wts文件,要先把yolov5n.pt文件放在此处再去执行
cd ~/tensorrtx/yolov5/ #如果是手动下载的名称可能是tensorrtx-master
mkdir build
cd build
将生成的wts文件复制到build下 #手动下载的,名称为yolov5-master
cmake ..
make -j4
sudo ./yolov5 -s yolov5n.wts yolov5n.engine n #生成engine文件
sudo ./yolov5 -d yolov5n.engine ../samples/ #测试图片查看效果,发现在检测zidane.jpg时漏检,这时可以返回上一层文件夹找到yolov5.cpp中的CONF_THRESH=0.25再进入到build中重新make -j4,再重新运行该指令即可
3.调用USB摄像头
参考了该文章https://blog.csdn.net/weixin_54603153/article/details/120079220
(1)在tensorrtx/yolov5下备份yolov5.cpp文件,因为如果更换模型时重新推理加速时需要用到该文件。
(2)然后对yolov5.cpp文件修改为如下内容
修改了12行和342行
#include<iostream>#include<chrono>#include"cuda_utils.h"#include"logging.h"#include"common.hpp"#include"utils.h"#include"calibrator.h"#define USE_FP32 // set USE_INT8 or USE_FP16 or USE_FP32#define DEVICE 0 // GPU id#define NMS_THRESH 0.4 //0.4#define CONF_THRESH 0.25 //置信度,默认值为0.5,由于效果不好修改为0.25取得了较好的效果#define BATCH_SIZE 1// stuff we know about the network and the input/output blobsstaticconstint INPUT_H = Yolo::INPUT_H;staticconstint INPUT_W = Yolo::INPUT_W;staticconstint CLASS_NUM = Yolo::CLASS_NUM;staticconstint OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT *sizeof(Yolo::Detection)/sizeof(float)+1;// we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1constchar* INPUT_BLOB_NAME ="data";constchar* OUTPUT_BLOB_NAME ="prob";static Logger gLogger;char* my_classes[]={"person","bicycle","car","motorcycle","airplane","bus","train","truck","boat","traffic light","fire hydrant","stop sign","parking meter","bench","bird","cat","dog","horse","sheep","cow","elephant","bear","zebra","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite","baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife","spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza","donut","cake","chair","couch","potted plant","bed","dining table","toilet","tv","laptop","mouse","remote","keyboard","cell phone","microwave","oven","toaster","sink","refrigerator","book","clock","vase","scissors","teddy bear","hair drier","toothbrush"};staticintget_width(int x,float gw,int divisor =8){//return math.ceil(x / divisor) * divisorif(int(x * gw)% divisor ==0){returnint(x * gw);}return(int(x * gw / divisor)+1)* divisor;}staticintget_depth(int x,float gd){if(x ==1){return1;}else{returnround(x * gd)>1?round(x * gd):1;}}
ICudaEngine*build_engine(unsignedint maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt,float& gd,float& gw, std::string& wts_name){
INetworkDefinition* network = builder->createNetworkV2(0U);// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{3, INPUT_H, INPUT_W });assert(data);
std::map<std::string, Weights> weightMap =loadWeights(wts_name);/* ------ yolov5 backbone------ */auto focus0 =focus(network, weightMap,*data,3,get_width(64, gw),3,"model.0");auto conv1 =convBlock(network, weightMap,*focus0->getOutput(0),get_width(128, gw),3,2,1,"model.1");auto bottleneck_CSP2 =C3(network, weightMap,*conv1->getOutput(0),get_width(128, gw),get_width(128, gw),get_depth(3, gd), true,1,0.5,"model.2");auto conv3 =convBlock(network, weightMap,*bottleneck_CSP2->getOutput(0),get_width(256, gw),3,2,1,"model.3");auto bottleneck_csp4 =C3(network, weightMap,*conv3->getOutput(0),get_width(256, gw),get_width(256, gw),get_depth(9, gd), true,1,0.5,"model.4");auto conv5 =convBlock(network, weightMap,*bottleneck_csp4->getOutput(0),get_width(512, gw),3,2,1,"model.5");auto bottleneck_csp6 =C3(network, weightMap,*conv5->getOutput(0),get_width(512, gw),get_width(512, gw),get_depth(9, gd), true,1,0.5,"model.6");auto conv7 =convBlock(network, weightMap,*bottleneck_csp6->getOutput(0),get_width(1024, gw),3,2,1,"model.7");auto spp8 =SPP(network, weightMap,*conv7->getOutput(0),get_width(1024, gw),get_width(1024, gw),5,9,13,"model.8");/* ------ yolov5 head ------ */auto bottleneck_csp9 =C3(network, weightMap,*spp8->getOutput(0),get_width(1024, gw),get_width(1024, gw),get_depth(3, gd), false,1,0.5,"model.9");auto conv10 =convBlock(network, weightMap,*bottleneck_csp9->getOutput(0),get_width(512, gw),1,1,1,"model.10");auto upsample11 = network->addResize(*conv10->getOutput(0));assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
ITensor* inputTensors12[]={ upsample11->getOutput(0), bottleneck_csp6->getOutput(0)};auto cat12 = network->addConcatenation(inputTensors12,2);auto bottleneck_csp13 =C3(network, weightMap,*cat12->getOutput(0),get_width(1024, gw),get_width(512, gw),get_depth(3, gd), false,1,0.5,"model.13");auto conv14 =convBlock(network, weightMap,*bottleneck_csp13->getOutput(0),get_width(256, gw),1,1,1,"model.14");auto upsample15 = network->addResize(*conv14->getOutput(0));assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
ITensor* inputTensors16[]={ upsample15->getOutput(0), bottleneck_csp4->getOutput(0)};auto cat16 = network->addConcatenation(inputTensors16,2);auto bottleneck_csp17 =C3(network, weightMap,*cat16->getOutput(0),get_width(512, gw),get_width(256, gw),get_depth(3, gd), false,1,0.5,"model.17");// yolo layer 0
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);auto conv18 =convBlock(network, weightMap,*bottleneck_csp17->getOutput(0),get_width(256, gw),3,2,1,"model.18");
ITensor* inputTensors19[]={ conv18->getOutput(0), conv14->getOutput(0)};auto cat19 = network->addConcatenation(inputTensors19,2);auto bottleneck_csp20 =C3(network, weightMap,*cat19->getOutput(0),get_width(512, gw),get_width(512, gw),get_depth(3, gd), false,1,0.5,"model.20");//yolo layer 1
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);auto conv21 =convBlock(network, weightMap,*bottleneck_csp20->getOutput(0),get_width(512, gw),3,2,1,"model.21");
ITensor* inputTensors22[]={ conv21->getOutput(0), conv10->getOutput(0)};auto cat22 = network->addConcatenation(inputTensors22,2);auto bottleneck_csp23 =C3(network, weightMap,*cat22->getOutput(0),get_width(1024, gw),get_width(1024, gw),get_depth(3, gd), false,1,0.5,"model.23");
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);auto yolo =addYoLoLayer(network, weightMap,"model.24", std::vector<IConvolutionLayer*>{det0, det1, det2});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16*(1<<20));// 16MB#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);#elif defined(USE_INT8)
std::cout <<"Your platform support int8: "<<(builder->platformHasFastInt8()?"true":"false")<< std::endl;assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H,"./coco_calib/","int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);#endif
std::cout <<"Building engine, please wait for a while..."<< std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network,*config);
std::cout <<"Build engine successfully!"<< std::endl;// Don't need the network any more
network->destroy();// Release host memoryfor(auto& mem : weightMap){free((void*)(mem.second.values));}return engine;}
ICudaEngine*build_engine_p6(unsignedint maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt,float& gd,float& gw, std::string& wts_name){
INetworkDefinition* network = builder->createNetworkV2(0U);// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{3, INPUT_H, INPUT_W });assert(data);
std::map<std::string, Weights> weightMap =loadWeights(wts_name);/* ------ yolov5 backbone------ */auto focus0 =focus(network, weightMap,*data,3,get_width(64, gw),3,"model.0");auto conv1 =convBlock(network, weightMap,*focus0->getOutput(0),get_width(128, gw),3,2,1,"model.1");auto c3_2 =C3(network, weightMap,*conv1->getOutput(0),get_width(128, gw),get_width(128, gw),get_depth(3, gd), true,1,0.5,"model.2");auto conv3 =convBlock(network, weightMap,*c3_2->getOutput(0),get_width(256, gw),3,2,1,"model.3");auto c3_4 =C3(network, weightMap,*conv3->getOutput(0),get_width(256, gw),get_width(256, gw),get_depth(9, gd), true,1,0.5,"model.4");auto conv5 =convBlock(network, weightMap,*c3_4->getOutput(0),get_width(512, gw),3,2,1,"model.5");auto c3_6 =C3(network, weightMap,*conv5->getOutput(0),get_width(512, gw),get_width(512, gw),get_depth(9, gd), true,1,0.5,"model.6");auto conv7 =convBlock(network, weightMap,*c3_6->getOutput(0),get_width(768, gw),3,2,1,"model.7");auto c3_8 =C3(network, weightMap,*conv7->getOutput(0),get_width(768, gw),get_width(768, gw),get_depth(3, gd), true,1,0.5,"model.8");auto conv9 =convBlock(network, weightMap,*c3_8->getOutput(0),get_width(1024, gw),3,2,1,"model.9");auto spp10 =SPP(network, weightMap,*conv9->getOutput(0),get_width(1024, gw),get_width(1024, gw),3,5,7,"model.10");auto c3_11 =C3(network, weightMap,*spp10->getOutput(0),get_width(1024, gw),get_width(1024, gw),get_depth(3, gd), false,1,0.5,"model.11");/* ------ yolov5 head ------ */auto conv12 =convBlock(network, weightMap,*c3_11->getOutput(0),get_width(768, gw),1,1,1,"model.12");auto upsample13 = network->addResize(*conv12->getOutput(0));assert(upsample13);
upsample13->setResizeMode(ResizeMode::kNEAREST);
upsample13->setOutputDimensions(c3_8->getOutput(0)->getDimensions());
ITensor* inputTensors14[]={ upsample13->getOutput(0), c3_8->getOutput(0)};auto cat14 = network->addConcatenation(inputTensors14,2);auto c3_15 =C3(network, weightMap,*cat14->getOutput(0),get_width(1536, gw),get_width(768, gw),get_depth(3, gd), false,1,0.5,"model.15");auto conv16 =convBlock(network, weightMap,*c3_15->getOutput(0),get_width(512, gw),1,1,1,"model.16");auto upsample17 = network->addResize(*conv16->getOutput(0));assert(upsample17);
upsample17->setResizeMode(ResizeMode::kNEAREST);
upsample17->setOutputDimensions(c3_6->getOutput(0)->getDimensions());
ITensor* inputTensors18[]={ upsample17->getOutput(0), c3_6->getOutput(0)};auto cat18 = network->addConcatenation(inputTensors18,2);auto c3_19 =C3(network, weightMap,*cat18->getOutput(0),get_width(1024, gw),get_width(512, gw),get_depth(3, gd), false,1,0.5,"model.19");auto conv20 =convBlock(network, weightMap,*c3_19->getOutput(0),get_width(256, gw),1,1,1,"model.20");auto upsample21 = network->addResize(*conv20->getOutput(0));assert(upsample21);
upsample21->setResizeMode(ResizeMode::kNEAREST);
upsample21->setOutputDimensions(c3_4->getOutput(0)->getDimensions());
ITensor* inputTensors21[]={ upsample21->getOutput(0), c3_4->getOutput(0)};auto cat22 = network->addConcatenation(inputTensors21,2);auto c3_23 =C3(network, weightMap,*cat22->getOutput(0),get_width(512, gw),get_width(256, gw),get_depth(3, gd), false,1,0.5,"model.23");auto conv24 =convBlock(network, weightMap,*c3_23->getOutput(0),get_width(256, gw),3,2,1,"model.24");
ITensor* inputTensors25[]={ conv24->getOutput(0), conv20->getOutput(0)};auto cat25 = network->addConcatenation(inputTensors25,2);auto c3_26 =C3(network, weightMap,*cat25->getOutput(0),get_width(1024, gw),get_width(512, gw),get_depth(3, gd), false,1,0.5,"model.26");auto conv27 =convBlock(network, weightMap,*c3_26->getOutput(0),get_width(512, gw),3,2,1,"model.27");
ITensor* inputTensors28[]={ conv27->getOutput(0), conv16->getOutput(0)};auto cat28 = network->addConcatenation(inputTensors28,2);auto c3_29 =C3(network, weightMap,*cat28->getOutput(0),get_width(1536, gw),get_width(768, gw),get_depth(3, gd), false,1,0.5,"model.29");auto conv30 =convBlock(network, weightMap,*c3_29->getOutput(0),get_width(768, gw),3,2,1,"model.30");
ITensor* inputTensors31[]={ conv30->getOutput(0), conv12->getOutput(0)};auto cat31 = network->addConcatenation(inputTensors31,2);auto c3_32 =C3(network, weightMap,*cat31->getOutput(0),get_width(2048, gw),get_width(1024, gw),get_depth(3, gd), false,1,0.5,"model.32");/* ------ detect ------ */
IConvolutionLayer* det0 = network->addConvolutionNd(*c3_23->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.33.m.0.weight"], weightMap["model.33.m.0.bias"]);
IConvolutionLayer* det1 = network->addConvolutionNd(*c3_26->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.33.m.1.weight"], weightMap["model.33.m.1.bias"]);
IConvolutionLayer* det2 = network->addConvolutionNd(*c3_29->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.33.m.2.weight"], weightMap["model.33.m.2.bias"]);
IConvolutionLayer* det3 = network->addConvolutionNd(*c3_32->getOutput(0),3*(Yolo::CLASS_NUM +5), DimsHW{1,1}, weightMap["model.33.m.3.weight"], weightMap["model.33.m.3.bias"]);auto yolo =addYoLoLayer(network, weightMap,"model.33", std::vector<IConvolutionLayer*>{det0, det1, det2, det3});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16*(1<<20));// 16MB#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);#elif defined(USE_INT8)
std::cout <<"Your platform support int8: "<<(builder->platformHasFastInt8()?"true":"false")<< std::endl;assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H,"./coco_calib/","int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);#endif
std::cout <<"Building engine, please wait for a while..."<< std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network,*config);
std::cout <<"Build engine successfully!"<< std::endl;// Don't need the network any more
network->destroy();// Release host memoryfor(auto& mem : weightMap){free((void*)(mem.second.values));}return engine;}voidAPIToModel(unsignedint maxBatchSize, IHostMemory** modelStream,float& gd,float& gw, std::string& wts_name){// Create builder
IBuilder* builder =createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine =build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);assert(engine != nullptr);// Serialize the engine(*modelStream)= engine->serialize();// Close everything down
engine->destroy();
builder->destroy();
config->destroy();}voiddoInference(IExecutionContext& context, cudaStream_t& stream,void** buffers,float* input,float* output,int batchSize){// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to hostCUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize *3* INPUT_H * INPUT_W *sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE *sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);}
bool parse_args(int argc,char** argv, std::string& engine){if(argc <3)return false;if(std::string(argv[1])=="-v"&& argc ==3){
engine = std::string(argv[2]);}else{return false;}return true;}intmain(int argc,char** argv){cudaSetDevice(DEVICE);//std::string wts_name = "";
std::string engine_name ="";//float gd = 0.0f, gw = 0.0f;//std::string img_dir;if(!parse_args(argc, argv, engine_name)){
std::cerr <<"arguments not right!"<< std::endl;
std::cerr <<"./yolov5 -v [.engine] // run inference with camera"<< std::endl;return-1;}
std::ifstream file(engine_name, std::ios::binary);if(!file.good()){
std::cerr <<" read "<< engine_name <<" error! "<< std::endl;return-1;}char* trtModelStream{ nullptr };
size_t size =0;
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];assert(trtModelStream);
file.read(trtModelStream, size);
file.close();// prepare input data ---------------------------staticfloat data[BATCH_SIZE *3* INPUT_H * INPUT_W];//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)// data[i] = 1.0;staticfloat prob[BATCH_SIZE * OUTPUT_SIZE];
IRuntime* runtime =createInferRuntime(gLogger);assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();assert(context != nullptr);
delete[] trtModelStream;assert(engine->getNbBindings()==2);void* buffers[2];// In order to bind the buffers, we need to know the names of the input and output tensors.// Note that indices are guaranteed to be less than IEngine::getNbBindings()constint inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);constint outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);assert(inputIndex ==0);assert(outputIndex ==1);// Create GPU buffers on deviceCUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE *3* INPUT_H * INPUT_W *sizeof(float)));CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE *sizeof(float)));// Create stream
cudaStream_t stream;CUDA_CHECK(cudaStreamCreate(&stream));
cv::VideoCapture capture("/home/cao-yolox/yolov5/tensorrtx-master/yolov5/samples/1.mp4"); #修改为自己要检测的视频或者图片,注意要写全路径,如果调用摄像头,则括号内的参数设为0,注意引号要去掉。
//cv::VideoCapture capture("../overpass.mp4");//int fourcc = cv::VideoWriter::fourcc('M','J','P','G');//capture.set(cv::CAP_PROP_FOURCC, fourcc);if(!capture.isOpened()){
std::cout <<"Error opening video stream or file"<< std::endl;return-1;}int key;int fcount =0;while(1){
cv::Mat frame;
capture >> frame;if(frame.empty()){
std::cout <<"Fail to read image from camera!"<< std::endl;break;}
fcount++;//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;for(int b =0; b < fcount; b++){//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
cv::Mat img = frame;if(img.empty())continue;
cv::Mat pr_img =preprocess_img(img, INPUT_W, INPUT_H);// letterbox BGR to RGBint i =0;for(int row =0; row < INPUT_H;++row){
uchar* uc_pixel = pr_img.data + row * pr_img.step;for(int col =0; col < INPUT_W;++col){
data[b *3* INPUT_H * INPUT_W + i]=(float)uc_pixel[2]/255.0;
data[b *3* INPUT_H * INPUT_W + i + INPUT_H * INPUT_W]=(float)uc_pixel[1]/255.0;
data[b *3* INPUT_H * INPUT_W + i +2* INPUT_H * INPUT_W]=(float)uc_pixel[0]/255.0;
uc_pixel +=3;++i;}}}// Run inferenceauto start = std::chrono::system_clock::now();doInference(*context, stream, buffers, data, prob, BATCH_SIZE);auto end = std::chrono::system_clock::now();//std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;int fps =1000.0/ std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::vector<std::vector<Yolo::Detection>>batch_res(fcount);for(int b =0; b < fcount; b++){auto& res = batch_res[b];nms(res,&prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);}for(int b =0; b < fcount; b++){auto& res = batch_res[b];//std::cout << res.size() << std::endl;//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);for(size_t j =0; j < res.size(); j++){
cv::Rect r =get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27,0xC1,0x36),2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y -1), cv::FONT_HERSHEY_PLAIN,1.2, cv::Scalar(0xFF,0xFF,0xFF),2);
std::string jetson_fps ="Jetson Nano FPS: "+ std::to_string(fps);
cv::putText(frame, jetson_fps, cv::Point(11,80), cv::FONT_HERSHEY_PLAIN,3, cv::Scalar(0,0,255),2, cv::LINE_AA);}//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);}
cv::imshow("yolov5", frame);
key = cv::waitKey(1);if(key =='q'){break;}
fcount =0;}
capture.release();// Release stream and bufferscudaStreamDestroy(stream);CUDA_CHECK(cudaFree(buffers[inputIndex]));CUDA_CHECK(cudaFree(buffers[outputIndex]));// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();return0;}
4.重新编译
进入到buid下重新make。注意只要修改了yolov5.cpp就要重新make。
执行
sudo ./yolov5 -v yolov5n.engine #注意要提前插好摄像头
问题:出现Failed to load module “canberra-gtk-module”
解决:
sudo apt-get install libcanberra-gtk-module
5.效果
如下的测试,是在一个公用的行人检测的视频上进行的,如果想用可在如下链接下载:
链接:https://pan.baidu.com/s/1HivF1OifVA8pHnGKtkXPfg
提取码:jr7o
七、参考
1.https://www.bilibili.com/read/cv11869887?spm_id_from=333.999.0.0
2.https://blog.csdn.net/weixin_54603153/article/details/120079220
3.https://github.com/wang-xinyu/tensorrtx/blob/master/yolov5/README.md
版权归原作者 carrymingteng 所有, 如有侵权,请联系我们删除。