
前面介绍了 PostgreSQL 数据类型和运算符、常用函数、锁操作、执行计划、视图与触发器、存储过程相关的知识点,今天将为大家介绍 PostgreSQL 索引 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
概述
索引主要被用来提升数据库性能,不当的使用会导致性能变差。 PostgreSQL 提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN。每一种索引类型使用了一种不同的算法来适应不同类型的查询。默认情况下,CREATE INDEX 命令创建适合于大部分情况的 B-tree 索引。
- B-树(默认):B-树是一个自平衡树(self-balancing tree),按照顺序存储数据,支持对数时间复杂度(O(logN))的搜索、插入、删除和顺序访问。
- 哈希:哈希索引(Hash index)只能用于简单的等值查找(=),也就是说索引字段被用于等号条件判断。因为对数据进行哈希运算之后不再保留原来的大小关系。
- GiST:GiST 代表通用搜索树(Generalized Search Tree),GiST 索引单个索引类型,而是一种支持不同索引策略的框架。GiST 索引常见的用途包括几何数据的索引和全文搜索。
- SP-GiST:SP-GiST 代表空间分区 GiST,主要用于 GIS、多媒体、电话路由以及 IP 路由等数据的索引。与 GiST 类似, SP-GiST 也支持“最近邻”搜索。
- GIN:GIN 代表广义倒排索引(generalized inverted indexes),主要用于单个字段中包含多个值的数据,例如 hstore、 array、 jsonb 以及 range 数据类型。一个倒排索引为每个元素值都创建一个单独的索引项,可以有效地查询某个特定元素值是否存在。Google、百度这种搜索引擎利用的就是倒排索引。
- BRIN:BRIN 代表块区间索引(block range indexes),存储了连续物理范围区间内的数据摘要信息。BRIN 也相比 B-树索引要小很多,维护也更容易。对于不进行水平分区就无法使用 B-树索引的超大型表,可以考虑 BRIN。
在使用上,除了常见的单列索引,还有多列索引、唯一索引、表达式索引、部分索引、覆盖索引等。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
- 多列索引:目前,只有 B-tree、GiST、GIN 和 BRIN 索引类型支持多列索引,最多可以指定32个列(该限制可以在源代码文件
pg_config_manual.h中修改,但是修改后需要重新编译PostgreSQL)。 - 唯一索引:目前,只有 B-tree 能够被声明为唯一。
- 表达式索引:从表的一列或多列计算而来的一个函数或者标量表达式。索引表达式的维护代价较为昂贵,因为在每一个行被插入或更新时都得为它重新计算相应的表达式。然而,索引表达式在进行索引搜索时却不需要重新计算,因为它们的结果已经被存储在索引中了。
- 部分索引:一个部分索引是建立在表的一个子集上,而该子集则由一个条件表达式(被称为部分索引的谓词)定义。而索引中只包含那些符合该谓词的表行的项。使用部分索引的一个主要原因是避免索引公值(查询结果行在一个表中占比超过一定百分比的值不会使用索引)。
- 覆盖索引:目前,B-树索引总是支持只用索引的扫描。GiST 和 SP-GiST 索引只对某些操作符类支持只用索引的扫描。其他索引类型不支持这种扫描。仅访问索引就可获取查询所需的全部数据,无需回表(Index-Only Scan)。
语法
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( column_name [, ...] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
UNIQUE:唯一索引,在索引被创建时(如果数据已经存在)或者加入数据时检查重复值。
CONCURRENTLY:在构建索引时不会取得任何会阻止该表上并发插入、更新或者删除的锁。而标准的索引构建将会把表锁住以阻止对表的写(但不阻塞读),这种锁定会持续到索引创建完毕。
IF NOT EXISTS:如果一个同名关系已经存在则不要抛出错误。
INCLUDE:指定一个列的列表,其中的列将被包括在索引中作为非键列。不能作为索引扫描的条件,主要作用是相关数据索存储在索引中,访问时无需访问该索引的基表。当前,有B-树和GiST索引访问方法支持这一特性。
name:要创建的索引名称。这里不能包括模式名,因为索引总是被创建在其基表所在的模式中。如果索引名称被省略,PostgreSQL 将基于基表名称和被索引列名称选择一个合适的名称。
ONLY:如果该表是分区表,指示不要在分区上递归创建索引。默认会递归创建索引。
table_name:要被索引的表的名称(可以被模式限定)。
method:要使用的索引方法的名称。可以选择 btree、hash、 gist、spgist、gin以及brin。默认方法是 btree。
column_name:一个表列的名称。
expression:一个基于一个或者更多个表列的表达式。如语法中所示,表达式通常必须被写在圆括号中。不过,如果该表达式是一个函数调用的形式,圆括号可以被省略。
collation:要用于该索引的排序规则的名称。
opclass:一个操作符类的名称。
opclass_parameter:运算符类参数的名称。
ASC:指定上升排序(默认)。
DESC:指定下降排序。
NULLS FIRST:指定把空值排序在非空值前面。在指定DESC时,这是默认行为。
NULLS LAST:指定把空值排序在非空值后面。在没有指定DESC时,这是默认行为。
storage_parameter:索引方法相关的存储参数的名称。可选的WITH子句为索引指定存储参数。每一种 索引方法都有自己的存储参数集合。
B-树、哈希、GiST以及SP-GiST索引方法都接受这个参数:
fillfactor (integer):索引的填充因子是一个百分数,它决定索引方法将尝试填充索引页面的充满程度。对于B-树,在初始的索引构建过程中,叶子页面会被填充至该百分数,当在索引右端扩展索引(增加新的最大键值)时也会这样处理。如果页面后来被完全填满,它们就会被分裂,导致索引的效率逐渐退化。B-树使用了默认的填充因子 90,但是也可以选择为 10 到 100 的任何整数值。如果表是静态的,那么填充因子 100 是最好的,因为它可以让索引的物理尺寸最小化。但是对于更新负荷很重的表,较小的填充因子有利于最小化对页面分裂的需求。其他索引方法以不同但是大致类似的方式使用填充因子,不同方法的默认填充因子也不相同。
deduplicate_items (boolean)
:B 树重复数据删除技术的使用。设置为 ON 或 OFF 以启用或禁用优化。默认值为ON。
vacuum_cleanup_index_scale_factor
:指定在以前的统计信息收集过程中计数到的堆元组总数的一个分数,插入不超过这一数量所代表的元组不会导致VACUUM清理阶段的索引扫描。这个设置当前仅适用于B-树索引。
buffering (enum)
:适用于 GiST 索引,决定是否用缓冲构建技术来构建索引。OFF 会禁用它,ON 则启用该特性,如果设置为 AUTO 则初始会禁用它,但是一旦索引尺寸到达 effective_cache_size 就会随时打开。默认值是 AUTO。
fastupdate (boolean)
:适用于 GIN 索引,这个设置控制快速更新技术的使用。它是一个布尔参数:ON 启用快速更新,OFF 禁用。默认是 ON。
gin_pending_list_limit (integer)
:适用于 GIN 索引,设置 fastupdate 被启用时可以使用的 GIN 索引的待处理列表的最大尺寸。 如果该列表增长到超过这个最大尺寸,会通过批量将其中的项移入索引的主 GIN 数据结构来清理列表。 如果指定值时没有单位,则以千字节为单位。默认值是四兆字节(4MB)。可以通过更改索引的存储参数来为个别 GIN 索引覆盖这个设置。
pages_per_range (integer)
:使用于 BRIN 索引,定义用于每一个BRIN索引项的块范围由多少个表块组成。默认是128。
autosummarize (boolean)
:定义是否只要在下一个页面上检测到插入就为前面的页面范围运行概要操作。
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
B-tree 索引
Btree 结构
meta page和root page是一定有的,meta page需要一个页来存储,表示指向root page的page id。随着记录数的增加,一个root page可能存不下所有的heap item,就会有leaf page,甚至branch page,甚至多层的branch page。一共有几层branch和 leaf,可以用btree page元数据的level来表示。
安装扩展准备数据
--使用pageinspect扩展工具查看结构,数据准备
create extension pageinspect;
--主键索引使用的是btree索引,索引名字 tb_order_pkey
create table tb_order(id int primary key, order_no varchar(255));
insert into tb_order select generate_series(1,100), md5(random()::varchar);
--analyze 统计数据库表数据,统计结果存储到pg_statistic系统表中
--vacuum 用于清理死亡元组占用的存储空间
vacuum analyze tb_order;
btree索引演变过程
btree索引一层结构
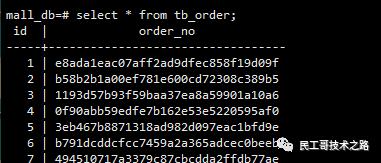
1、查看meta块
select * from bt_metap('tb_order_pkey');--查看meta块
此时level为0即高度为1,root块为1。

2、根据root 的 page id =1查看 root page的stats
select * from bt_page_stats('tb_order_pkey', 1);--查看page的统计状态信息

图中参数说明如下:
ive_items:存活的索引行
dead_items:死亡的索引行
avg_item_size:平均索引行大小
page_size:块大小,详细看最后说明
free_size:块空余大小
btpo_prev:块左边
btpo_next:块右边
btpo:当前块层次,0代表处于0层
btpo_flags:当前块类型,3代表:他既是leaf又是root,即2+1
meta page
root page:表示为btpo flags=2
branch page :表示为btpo flags=0
leaf page:表示为btpo flags=1
3、查看指定索引块内容
select * from bt_page_items('tb_order_pkey', 1);--查看指定索引块内容
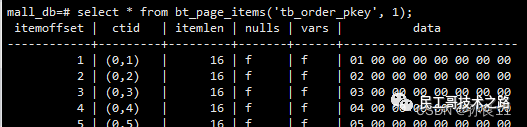
索引:ctid+索引列的值
4、通过索引ctid访问数据
select * from tb_order where ctid='(0,1)'; --通过索引ctid访问数据

btree索引二层结构
包括 meta page, root page, leaf page
--使用pageinspect扩展工具查看结构,数据准备
create extension pageinspect;
--主键索引使用的是btree索引,索引名字 tb_order_pkey
create table tb_order2(id int primary key, order_no varchar(255));
insert into tb_order2 select generate_series(1,10000), md5(random()::varchar);
--analyze 统计数据库表数据,统计结果存储到pg_statistic系统表中
--vacuum 用于清理死亡元组占用的存储空间
vacuum analyze tb_order2;
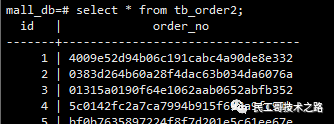
1、查看meta块
Vacuum用于清理死亡元组占用的存储空间,默认删除或因更新过期(为了MVVC)的元组不会被物理删除。因此需要周期性的进行Vacuum,尤其是频繁更新的表。
Analyze命令用于统计数据库表数据,统计结果存储到pg_statistic系统表中。数据库进行基于成本的优化(CBO)时通过统计数据优化SQL语句的解释计划。
select * from bt_metap('tb_order2_pkey');
此时level为1即高度为2,root块id为3

2、根据root 的 page id =3查看 root page的stats**
select * from bt_page_stats('tb_order2_pkey', 3);--根据root 的 page id =3查看stats

live_items:存活的页块
dead_items:死亡的页块
avg_item_size:平均索引行大小
page_size:块大小,详细看最后说明
free_size:块空余大小
btpo_prev:块左边
btpo_next:块右边
btpo:当前块层次,1代表处于2层,表示下面还有一层
btpo_flags:当前块类型,3代表:他既是leaf又是root,即2+1
- meta page
- root page:表示为btpo flags=2
- branch page :表示为btpo flags=0
- leaf page:表示为btpo flags=1
3、查看指定索引块内容
select * from bt_page_items('tb_order2_pkey', 3);
总共28个页块,
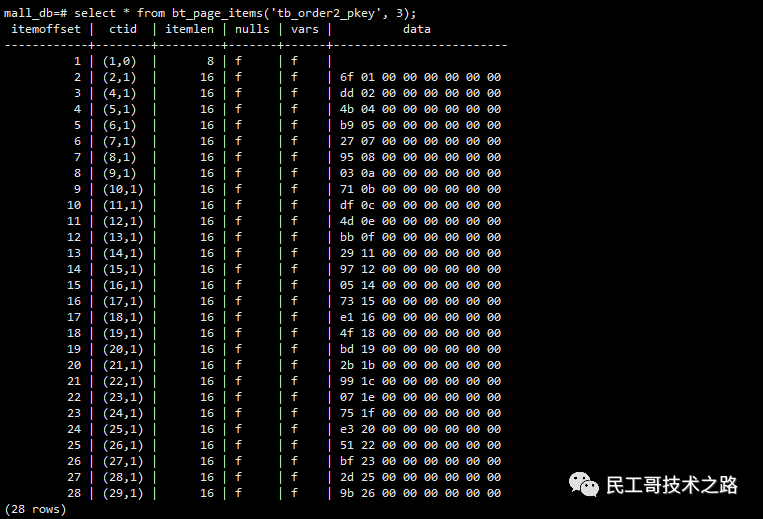
4、查看每个的页块统计
select * from bt_page_stats('tb_order2_pkey', 1);
btpo flags=1表示为leaf page
btpo_prev:0
btpo_next:2
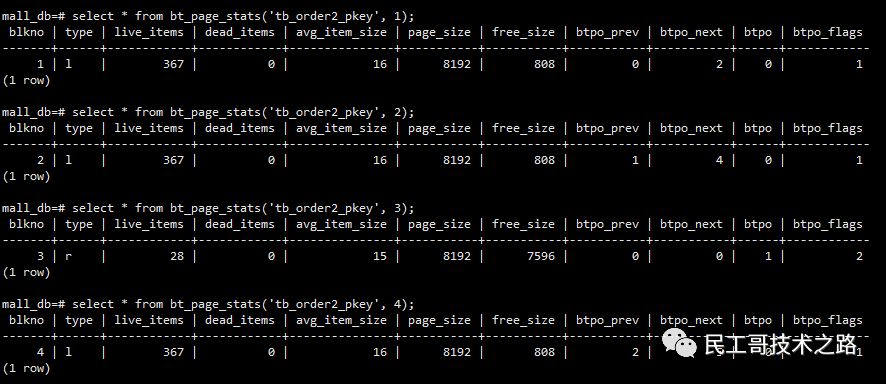
5、查看每个的页块内容
select * from bt_page_items('tb_order2_pkey', 1);
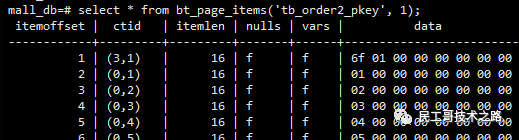
6、通过ctid查看数据
select * from tb_order2 where ctid='(3,1)';

btree索引三层结构
包括 meta page, root page, leaf page,branch page。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
实例
postgres=# create index idx_test_id on test(id);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_id" btree (id)
postgres=# explain analyze select * from test where id between 100 and 200;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_test_id on test (cost=0.43..10.49 rows=103 width=15) (actual time=0.006..0.058 rows=101 loops=1)
Index Cond: ((id >= 100) AND (id <= 200))
Planning Time: 0.408 ms
Execution Time: 0.072 ms
(4 rows)
Hash 索引
Hash索引结构
哈希索引项只存储每个索引项的哈希代码,而不是实际的数据值
应用场景
- hash索引存储的是被索引字段VALUE的哈希值,只支持等值查询。
- hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个索引行,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。
实例
postgres=# create index idx_test_id on test using hash(id);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_id" hash (id)
postgres=# explain analyze select * from test where id = 100;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Index Scan using idx_test_id on test (cost=0.00..8.02 rows=1 width=15) (actual time=0.014..0.015 rows=1 loops=1)
Index Cond: (id = 100)
Planning Time: 0.142 ms
Execution Time: 0.029 ms
(4 rows)
GiST 索引
GiST的意思是通用的搜索树(Generalized Search Tree)。 它是一种平衡树结构的访问方法,在系统中作为一个基本模版,可以使用它实现任意索引模式。B-trees, R-trees和许多其它的索引模式都可以用GiST实现。
与Btree索引比较的优缺点
优点
Gist索引适用于多维数据类型和集合数据类型,和Btree索引类似,同样适用于其他的数据类型。和Btree索引相比,Gist多字段索引在查询条件中包含索引字段的任何子集都会使用索引扫描,而Btree索引只有查询条件包含第一个索引字段才会使用索引扫描。
缺点
Gist索引创建耗时较长,占用空间也比较大。
实例
postgres=# create index idx_t_gist_pos on t_gist using gist(pos);
CREATE INDEX
postgres=# \d t_gist
Table "public.t_gist"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
pos | point | | |
Indexes:
"idx_t_gist_pos" gist (pos)
postgres=# explain analyze select * from t_gist where circle '((100,100) 10)' @> pos;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t_gist (cost=5.06..271.70 rows=100 width=20) (actual time=0.048..0.092 rows=29 loops=1)
Recheck Cond: ('<(100,100),10>'::circle @> pos)
Heap Blocks: exact=29
-> Bitmap Index Scan on idx_t_gist_pos (cost=0.00..5.03 rows=100 width=0) (actual time=0.027..0.027 rows=29 loops=1)
Index Cond: (pos <@ '<(100,100),10>'::circle)
Planning Time: 0.092 ms
Execution Time: 0.136 ms
(7 rows)
SP-GiST 索引
SP-GiST 中的GiST说明它跟 GiST 访问方法有一些相似性。两者的相似性在于,都是通用搜索树,都为构建各种访问方法提供了框架。SP代表空间分区(space partitioning),这里的空间,就是我们常说的空间,比如二维平面。我们将会看到,它可以表示任意搜索空间。
GIST索引不是单独一种索引类型,而是一种架构,可以在这种架构上实现很多不同的索引策略。因此,可以使用GIST索引的特定操作符类型高度依赖于索引策略(操作符类)。
GIST是广义搜索树generalized search tree的缩写。这是一个平衡搜索树。
用于解决一些B-tree,GIN难以解决的数据减少问题,例如,范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点。
Postgresql也实现了以下几种类型的SP-Gist索引的操作类,我们可以在这些类型上直接建立SP-Gist索引。
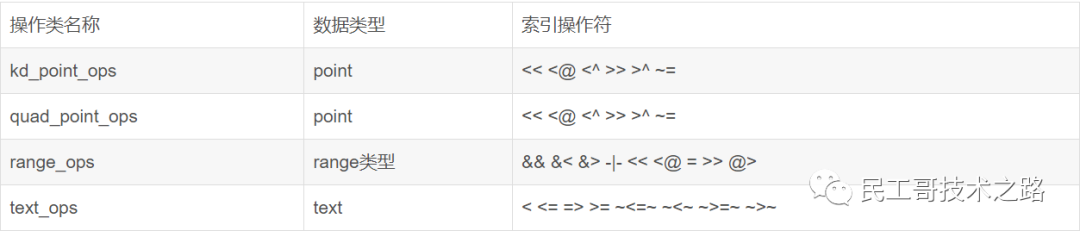
实例
postgres=# create index idx_t_spgist_p on t_spgist using spgist(p);
CREATE INDEX
postgres=# \d t_spgist
Table "public.t_spgist"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
p | point | | |
Indexes:
"idx_t_spgist_p" spgist (p)
postgres=# explain analyze select * from t_spgist where p >^ point '(2,7)';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t_spgist (cost=305.78..1067.78 rows=10000 width=20) (actual time=7.387..15.011 rows=99245 loops=1)
Recheck Cond: (p >^ '(2,7)'::point)
Heap Blocks: exact=637
-> Bitmap Index Scan on idx_t_spgist_p (cost=0.00..303.28 rows=10000 width=0) (actual time=7.302..7.303 rows=99245 loops=1)
Index Cond: (p >^ '(2,7)'::point)
Planning Time: 0.124 ms
Execution Time: 17.611 ms
(7 rows)
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
GIN 索引
gin索引结构
GIN是Generalized lnverted Index的缩写。就是所谓的倒排索引,它处理的数据类型的值不是原来的,而是由元素构成。我们称之为复合类型。
存储被索引字段的VALUE或VALUE的元素,以及行号的list或tree。
col_val:(tid_list or tid_tree),col_val_elements:(tid_list or tid_tree)
比如('hank','15:3 21:4')中,表示hank在15:3和21:4这两个位置出现过
应用场景
- 当需要搜索多值类型内的VALUE时,适合多值类型,例如数组、全文检索、TOKEN。(根据不同的类型,支持相交、包含、大于、在左边、在右边等搜索)
- 当用户的数据比较稀疏时,如果要搜索某个VALUE的值,可以适应btree_gin支持普通btree支持的类型。(支持btree的操作符)
- 当用户需要按任意列进行搜索时,gin支持多列展开单独建立索引域,同时支持内部多域索引的bitmapAnd, bitmapor合并,快速的返回按任意列搜索请求的数据。
实例
postgres=# create index idx_ts_doc_tsv on ts using gin(doc_tsv);
CREATE INDEX
postgres=# \d ts
Table "public.ts"
Column | Type | Collation | Nullable | Default
---------+----------+-----------+----------+---------
doc | text | | |
doc_tsv | tsvector | | |
Indexes:
"idx_ts_doc_tsv" gin (doc_tsv)
postgres=# set enable_seqscan = off;
SET
postgres=# explain analyze select * from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on ts (cost=12.25..16.51 rows=1 width=64) (actual time=0.046..0.047 rows=1 loops=1)
Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
Heap Blocks: exact=1
-> Bitmap Index Scan on idx_ts_doc_tsv (cost=0.00..12.25 rows=1 width=0) (actual time=0.042..0.042 rows=1 loops=1)
Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
Planning Time: 0.176 ms
Execution Time: 0.071 ms
(7 rows)
BRIN 索引
简介
BRIN 索引是块级索引,有别于B-TREE等索引,BRIN记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小。
BRIN属于LOSSLY索引,当被索引列的值与物理存储相关性很强时,BRIN索引的效果非常的好。例如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很好。与我们已经熟悉的索引不同,BRIN避免查找绝对不合适的行,而不是快速找到匹配的行。BRIN是一个不准确的索引:不包含表行的tid。
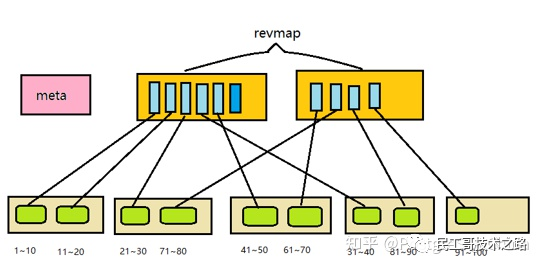
表被分割成ranges(好多个pages的大小):因此被称作block range index(BRIN)。在每个range中存储数据的摘要信息。作为规则,这里是最小值和最大值,但有时也并非如此。假设执行了一个查询,该查询包含某列的条件;如果所查找的值没有进入区间,则可以跳过整个range;但如果它们确实在,所有块中的所有行都必须被查看以从中选择匹配的行。在元数据页和摘要数据之间,是reverse range map页(revmap)。是一个指向相应索引行的指针(TIDs)数组。
在BRIN索引中,PostgreSQL会为每个8k大小的存储数据页面读取所选列的最大值和最小值,然后将该信息(页码以及列的最小值和最大值)存储到BRIN索引中。一般可以不把BRIN看作索引,而是看作顺序扫描的加速器。 如果我们把每个range都看作是一个虚拟分区,那么我们可以把BRIN看作分区的替代方案。BRIN适合单值类型,当被索引列存储相关性越接近1或-1时,数据存储越有序,块的边界越明显,BRIN索引的效果就越好。
实例
postgres=# create index idx_test_id on test using brin(id);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_id" brin (id)
postgres=# explain analyze select * from test where id between 100 and 200;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=12.03..27651.36 rows=1 width=15) (actual time=0.079..4.006 rows=101 loops=1)
Recheck Cond: ((id >= 100) AND (id <= 200))
Rows Removed by Index Recheck: 23579
Heap Blocks: lossy=128
-> Bitmap Index Scan on idx_test_id (cost=0.00..12.03 rows=23585 width=0) (actual time=0.067..0.067 rows=1280 loops=1)
Index Cond: ((id >= 100) AND (id <= 200))
Planning Time: 0.240 ms
Execution Time: 4.045 ms
(8 rows)
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
其他用法
多列索引
postgres=# create index idx_test_dl on test(id,name);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_dl" btree (id, name)
postgres=# explain analyze select * from test where id = 100 and name = 'val:100';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_test_dl on test (cost=0.43..8.45 rows=1 width=15) (actual time=0.086..0.087 rows=1 loops=1)
Index Cond: ((id = 100) AND (name = 'val:100'::text))
Heap Fetches: 1
Planning Time: 0.224 ms
Execution Time: 0.104 ms
(5 rows)
唯一索引
postgres=# create unique index idx_test_wy on test(id);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_wy" UNIQUE, btree (id)
postgres=# explain analyze select * from test where id = 100;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Index Scan using idx_test_wy on test (cost=0.43..8.45 rows=1 width=15) (actual time=0.099..0.101 rows=1 loops=1)
Index Cond: (id = 100)
Planning Time: 0.350 ms
Execution Time: 0.119 ms
(4 rows)
表达式索引
postgres=# create index idx_test_bds on test((id+1000));
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_bds" btree ((id + 1000))
postgres=# explain analyze select * from test where id+1000 > 10000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=31205.10..83233.11 rows=1666667 width=15) (actual time=578.175..1501.361 rows=4991000 loops=1)
Recheck Cond: ((id + 1000) > 10000)
Heap Blocks: exact=26980
-> Bitmap Index Scan on idx_test_bds (cost=0.00..30788.43 rows=1666667 width=0) (actual time=574.862..574.863 rows=4991000 loops=1)
Index Cond: ((id + 1000) > 10000)
Planning Time: 0.110 ms
Execution Time: 1633.012 ms
(7 rows)
部分索引
postgres=# create index idx_test_bf on test(id) where (id between 1000 and 2000);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_bf" btree (id) WHERE id >= 1000 AND id <= 2000
postgres=# explain analyze select * from test where id between 1500 and 2000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_test_bf on test (cost=0.28..27.29 rows=515 width=15) (actual time=0.035..0.090 rows=501 loops=1)
Index Cond: (id >= 1500)
Planning Time: 0.265 ms
Execution Time: 0.110 ms
(4 rows)
postgres=# explain analyze select * from test where id between 500 and 1000;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Seq Scan on test (cost=10000000000.00..10000102028.00 rows=272 width=15) (actual time=0.035..427.097 rows=501 loops=1)
Filter: ((id >= 500) AND (id <= 1000))
Rows Removed by Filter: 4999499
Planning Time: 0.107 ms
Execution Time: 427.120 ms
(5 rows)
覆盖索引
postgres=# create index idx_test_fg on test(id) include(name);
CREATE INDEX
postgres=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"idx_test_fg" btree (id) INCLUDE (name)
postgres=# explain analyze select * from test where id = 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_test_fg on test (cost=0.43..8.45 rows=1 width=15) (actual time=0.031..0.032 rows=1 loops=1)
Index Cond: (id = 100)
Heap Fetches: 1
Planning Time: 0.264 ms
Execution Time: 0.047 ms
(5 rows)
常用管理操作
--查询
postgres=# select * from pg_indexes where tablename = 'test';
schemaname | tablename | indexname | tablespace | indexdef
------------+-----------+-------------+------------+-------------------------------------------------------------------------
public | test | idx_test_fg | | CREATE INDEX idx_test_fg ON public.test USING btree (id) INCLUDE (name)
(1 row)
--重建
postgres=# reindex index idx_test_fg;
REINDEX
--重命名
postgres=# alter index idx_test_fg rename to idx_test_id;
ALTER INDEX
--修改表空间
postgres=# alter index idx_test_id set tablespace tab1;
ALTER INDEX
--删除
postgres=# drop index idx_test_id;
DROP INDEX
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
版权归原作者 pgdba 所有, 如有侵权,请联系我们删除。