
一、实验目标
1、将文件评论分为积极评论和消极评论两类,其中消极评论包括答非所问,省略回答与拒绝回答
(本文中我暂且规定积极评论为0,消极评论为1)
二、实验思路
1、用jieba库,去除停用词等操作处理原始数据,并挑出数据中评论为空的值(nan)可以直接将预测值变为1(消极评论)
2、根据1500条数据量划分出训练集和测试集,对模型进行测试,并选取正确率最高的方法
(我最终选取的是朴素贝叶斯方法)
3、针对30万条数据进行处理,查看算法的可行性
4、处理更大的300万条数据
三、实验预备知识
1、csv文件操作
(1)文件的创建与打开
with open(filepath,mode,encoding="utf8",newline="") as f:
rows = csv.reader(f) #rows为一个迭代器(大列表套着小列表)
for row in rows:
print(rows)
A.mode:文件打开模式
r:只读模式,文件不存在泽报错,默认模式(文件指针位于文件末尾)
r+:只读模式,文件不存在泽报错(文件指针位于文件开头)
w:写入模式,文件不存在则自动报错,每次打开会覆盖原文件内容,文件不关闭则可以进行多次写入(只会在打开文件时清空文件内容)
w+:写入模式,文件不存在则自动报错,每次打开会覆盖原文件内容,文件不关闭则可以进行多次写入(只会在打开文件时清空文件内容,指针位置在文件内容末尾)
a:追加模式,文件不存在则会自动创建,从末尾追加,不可读。
a+:追加且可读模式,刚打开时文件指针就在文件末尾。
B.utf-8和utf-8-sig
”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
“utf-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”, 因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
(2)csv文件的写入
headers=[]
datas=[]
with open(filepath,mode,encoding="utf8",newline="") as f:
rows = csv.reader(f)
rows.writerow(headers)
rows.writerows(datas)
2、大文件的查看与修改
推荐一个软件EmEditor,excel最多打开104万行数据,更大的数据量会导致excel崩溃,对于查看或修改更大的csv文件,此时最好使用EmEditor
3、jieba,sklearn等库的使用
代码里会详细解释
四、实验代码
import jieba
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from pandas import DataFrame
import openpyxl as op
#训练集
new_reply = pd.DataFrame(None,columns=["reply","answer"])
reply = pd.read_excel("sum.xlsx").astype(str)
print("训练集读取成功!")
#新数据
reply1 = pd.read_csv("result297.csv").astype(str)
new_reply1 = pd.DataFrame(None,columns=["reply","answer"])
print("数据集读取成功")
#stopwords的引用
with open("stopwords.txt","r",encoding = "utf-8") as f:
stops = f.readlines()
stopwords = [x.strip() for x in stops]
#利用jieba对文本进行分段
new_reply["reply"] = reply.回答.apply(lambda s:" ".join(jieba.cut(s)))
new_reply["answer"] = reply["answer(人工阅读)"]
new_reply["reply"] = new_reply.reply.apply(lambda s:s if str(s)!="nan" else np.nan)
df = new_reply["reply"]
df=df.to_frame(name="reply")
df_isnull_remark = df[df["reply"].isnull()]
new_reply.dropna(subset=["reply"],inplace=True)
cut_list = new_reply["reply"].apply(lambda s:s.split(" "))
result = cut_list.apply(lambda s:[x for x in s if x not in stopwords]) #result类型为series
new_reply1["reply"] = reply1.回答.apply(lambda s:" ".join(jieba.cut(s)))
# new_reply1["answer"] = reply1["answer(人工)"]
new_reply1["reply"] = new_reply1.reply.apply(lambda s:s if str(s)!="nan" else np.nan)
cf = new_reply1["reply"]
cf=cf.to_frame(name="reply")
cf_isnull_remark = cf[cf["reply"].isnull()]
new_reply1.dropna(subset=["reply"],inplace=True)
cut_list1 = new_reply1["reply"].apply(lambda s:s.split(" "))
result1 = cut_list1.apply(lambda s:[x for x in s if x not in stopwords]) #result1类型为series
# x_train,x_test,y_train,y_test = train_test_split(result,new_reply["answer"],test_size = 0.25,random_state = 3)
x_train = result
y_train = new_reply["answer"]
# test_index = x_test.index
test_index = result1.index
x_train = x_train.reset_index(drop=True)
# print(type(x_test)) #x_test类型为series
words=[]
for i in range(len(x_train)):
words.append(' '.join(x_train[i]))
result1 = result1.reset_index(drop=True)
test_words=[]
for i in range(len(result1)):
test_words.append(' '.join(result1[i]))
# print(test_words)
# vec = CountVectorizer(analyzer='word',max_features=4000,lowercase=False)
# vec.fit(words)
# classifer = MultinomialNB()
# classifer.fit(vec.transform(words),y_train)
# score = classifer.score(vec.transform(test_words),y_test)
# # a=classifer.predict_proba(vec.transform(test_words))
# print(score)
cv = CountVectorizer(ngram_range=(1,2))
cv.fit(words)
classifer = MultinomialNB()
classifer.fit(cv.transform(words),y_train)
# score = classifer.score(cv.transform(test_words),test)
a=classifer.predict_proba(cv.transform(test_words))
# print(score)
# tv = TfidfVectorizer(analyzer='word',max_features = 4000,ngram_range=(1,2),lowercase=False)
# tv.fit(words)
# classifer = MultinomialNB()
# classifer.fit(tv.transform(words),y_train)
# score = classifer.score(tv.transform(test_words),y_test)
# a=classifer.predict_proba(tv.transform(test_words))
# print(score)
# b=[]
# c=[]
# for nums in a:
# for num in nums:
# num = int(num +0.5)
# b.append(num)
# if(b[0] == 1):
# c.append(1)
# if(b[1] == 1):
# c.append(0)
# b=[]
# print(cf_isnull_remark.index)
# tableAll = op.load_workbook('201401.xlsx')
# table1 = tableAll['Sheet1']
# for i in range(len(c)):
# table1.cell(test_index[i]+2, 12, c[i])8i
# for i in range(len(df_isnull_remark.index)):
# table1.cell(df_isnull_remark.index[i]+2, 12, 0)
# tableAll.save('201401.xlsx')
# judge=Ture
# p=1
# with open("result297.csv","r",encoding='utf-8',newline='') as f:
# rows = csv.reader(f)
# with open("help297.csv", 'w',encoding='utf-8',newline='') as file:
# writer = csv.writer(file)
# for row in rows:
# if(p==1):
# row.append("result")
# p+=1
# else:
# for o in range(len(c)):
# if(p==test_index[o]+2):
# row.append(c[o])
# break
# for u in range(len(cf_isnull_remark.index)):
# if(p==cf_isnull_remark.index[u]+2):
# row.append(1)
# break
# p+=1
# writer.writerow(row)
print("ok")
五、部分代码解析
1、jieba分词部分
#利用jieba对文本进行分段
new_reply["reply"] = reply.回答.apply(lambda s:" ".join(jieba.cut(s)))
new_reply["answer"] = reply["answer(人工阅读)"]
cut_list = new_reply["reply"].apply(lambda s:s.split(" "))
#new_reply["reply"]为DataFrame类型,通过使用""切分将cut_list转化为Series类型
jieba分词的作用如下所示,它会将输入的参数自动划分为诸多词块

2、去除停用词
停用词为评论中一些对于结果的分类影响不大的词语,一般在网上都可以查到。
删除的方法为遍历整个列表,找到跟停用词相同的元素立即删除并继续循环,直到去掉评论中的所有停用词
with open("stopwords.txt","r",encoding = "utf-8") as f:
stops = f.readlines()
stopwords = [x.strip() for x in stops]
#strip()删除无意义换行符,空格等等
cut_list1 = new_reply1["reply"].apply(lambda s:s.split(" "))
result1 = cut_list1.apply(lambda s:[x for x in s if x not in stopwords])
3、划分训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(result,new_reply["answer"],test_size = 0.25,random_state = 3)
#此处选取75%数据作训练集,25%数据作测试集
4、利用机器学习方法进行训练
# vec = CountVectorizer(analyzer='word',max_features=4000,lowercase=False)
# vec.fit(words)
# classifer = MultinomialNB()
# classifer.fit(vec.transform(words),y_train)
# score = classifer.score(vec.transform(test_words),y_test)
# # a=classifer.predict_proba(vec.transform(test_words))
# print(score)
cv = CountVectorizer(ngram_range=(1,2))
cv.fit(words)
classifer = MultinomialNB()
classifer.fit(cv.transform(words),y_train)
# score = classifer.score(cv.transform(test_words),test)
a=classifer.predict_proba(cv.transform(test_words))
# print(score)
# tv = TfidfVectorizer(analyzer='word',max_features = 4000,ngram_range=(1,2),lowercase=False)
# tv.fit(words)
# classifer = MultinomialNB()
# classifer.fit(tv.transform(words),y_train)
# score = classifer.score(tv.transform(test_words),y_test)
# a=classifer.predict_proba(tv.transform(test_words))
# print(score)
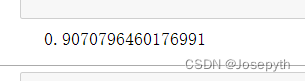
cv.fit函数将训练集划分的词块投喂进去,统计有效词词频。
classifer.predict_proba函数可以统计差异,计算正确率,经计算,利用朴素贝叶斯分类的正确率可以达到91%,效果较为理想。
5、大csv文件的处理操作具体实现
处理三百万条数据时python读入导致计算机卡顿,于是我将数据进行拆分成10000条数据的小csv文件并对小文件进行操作,最后将得到结果的所有文件再进行合并。
A、拆分为300个小文件=========>>
import csv
import os
#准备10000行的csv作为样例,进行拆分
example_path = 'data1.csv' # 需要拆分文件的路径
example_result_dir = 'chaifen' # 拆分后文件的路径
with open(example_path, 'r', newline='',encoding = 'utf-8') as example_file:
example = csv.reader(example_file)
i = j = 1
for row in example:
# print(row)
# print(f'i 等于 {i}, j 等于 {j}')
# 每1000个就j加1, 然后就有一个新的文件名
if i % 10000 == 0:
print(f'第{j}个文件生成完成')
j += 1
example_result_path = example_result_dir + '\\result' + str(j) + '.csv'
# print(example_result_path)
# 不存在此文件的时候,就创建
if not os.path.exists(example_result_path):
with open(example_result_path, 'w', newline='',encoding = 'utf-8-sig') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(['code', '提问', '回答', '回答时间', 'Question', 'NegAnswer_Reg', '查找方式', 'year','DueOccup', 'Gender', 'SOEearly', 'Exchange', 'NegAnswer_Lasso','Length', 'Salary', 'TotleQuestion', 'Analyst', 'NegTone', 'AccTerm','Readability', 'ShareHold', 'InstOwn', 'SOE', '行业名称', '行业代码','industry', 'quarter'])
csvwriter.writerow(row)
i += 1
# 存在的时候就往里面添加
else:
with open(example_result_path, 'a', newline='',encoding = 'utf-8') as file:
csvwriter = csv.writer(file)
csvwriter.writerow(row)
i += 1
B、分别进行处理=========>>
import jieba
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from pandas import DataFrame
import openpyxl as op
import threading
from concurrent.futures import ThreadPoolExecutor
import time
import csv
#训练集
new_reply = pd.DataFrame(None,columns=["reply","answer"])
reply = pd.read_excel("sum.xlsx").astype(str)
print("训练集读取成功!")
# print(reply.head())
with open("stopwords.txt","r",encoding = "utf-8") as f:
stops = f.readlines()
stopwords = [x.strip() for x in stops]
#利用jieba对文本进行分段
new_reply["reply"] = reply.回答.apply(lambda s:" ".join(jieba.cut(s)))
new_reply["answer"] = reply["answer(人工阅读)"]
new_reply["reply"] = new_reply.reply.apply(lambda s:s if str(s)!="nan" else np.nan)
df = new_reply["reply"]
df=df.to_frame(name="reply")
df_isnull_remark = df[df["reply"].isnull()]
new_reply.dropna(subset=["reply"],inplace=True)
cut_list = new_reply["reply"].apply(lambda s:s.split(" "))
result = cut_list.apply(lambda s:[x for x in s if x not in stopwords]) #result类型为series
x_train = result
y_train = new_reply["answer"]
# print(new_reply.head())
time1 = time.time()
x_train = x_train.reset_index(drop=True)
words=[]
for i in range(len(x_train)):
words.append(' '.join(x_train[i]))
cv = CountVectorizer(ngram_range=(1,2))
cv.fit(words)
classifer = MultinomialNB()
classifer.fit(cv.transform(words),y_train)
i=0
# print(words)
#新数据
for i in range(296):
t = time.time()
path = './chaifen/result' + str(i+1) +'.csv'
reply1 = pd.read_csv(path).astype(str)
new_reply1 = pd.DataFrame(None,columns=["reply","answer"])
print(f"第{i+1}个数据集读取成功")
#stopwords的引用
new_reply1["reply"] = reply1.回答.apply(lambda s:" ".join(jieba.cut(s)))
new_reply1["reply"] = new_reply1.reply.apply(lambda s:s if str(s)!="nan" else np.nan)
cf = new_reply1["reply"]
cf=cf.to_frame(name="reply")
cf_isnull_remark = cf[cf["reply"].isnull()]
new_reply1.dropna(subset=["reply"],inplace=True)
cut_list1 = new_reply1["reply"].apply(lambda s:s.split(" "))
result1 = cut_list1.apply(lambda s:[x for x in s if x not in stopwords]) #result1类型为series
test_index = result1.index
# print(result1)
result1 = result1.reset_index(drop=True)
test_words=[]
for j in range(len(result1)):
test_words.append(' '.join(result1[j]))
# print(test_words[0])
a=classifer.predict_proba(cv.transform(test_words))
# print(ad)
b=[]
c=[]
for nums in a:
for num in nums:
num = int(num +0.5)
b.append(num)
if(b[0] == 1):
c.append(1)
if(b[1] == 1):
c.append(0)
b=[]
print(len(c))
p=1
with open(path,"r",encoding='utf-8',newline='') as f:
rows = csv.reader(f)
with open(f"./chaifen/help{i+1}.csv", 'w',encoding='utf-8',newline='') as file:
writer = csv.writer(file)
for row in rows:
if(p==1):
row.append("result")
else:
for o in range(len(c)):
if(p==test_index[o]+2):
row.append(c[o])
break
for u in range(len(cf_isnull_remark.index)):
if(p==cf_isnull_remark.index[u]+2):
row.append(1)
break
writer.writerow(row)
p+=1
print(f"第{i+1}个数据集处理成功,用时{time.time() - t}")
print(f"总计用时{time.time() - time1}")
print("all is over!")
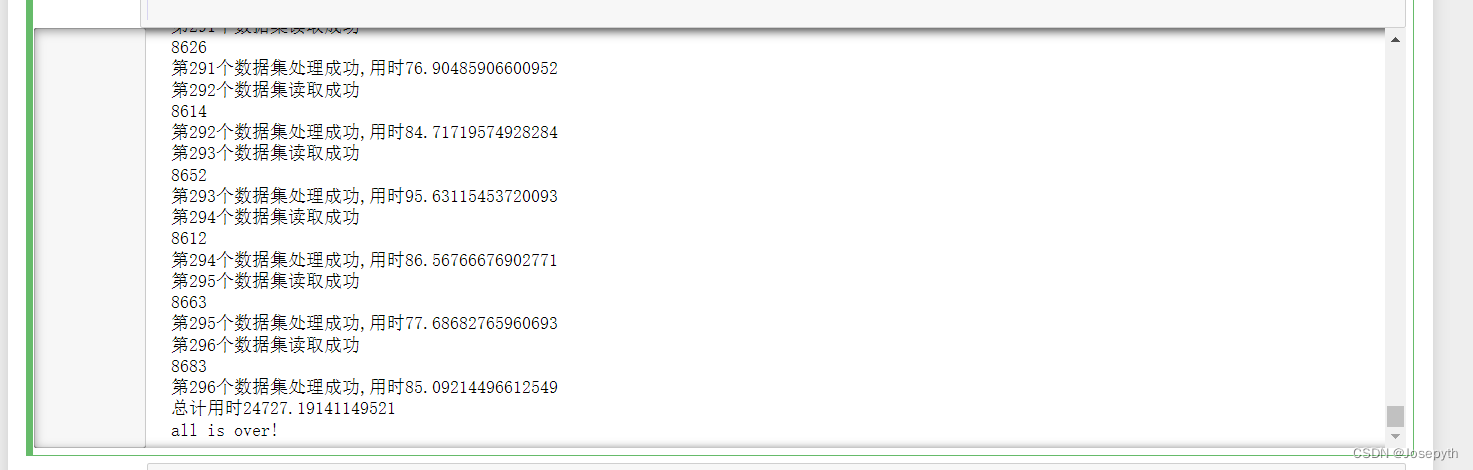
花了我一晚上时间,终于跑出了最终结果
(或许通过多线程可以加快速度,接下来再学习)
C、合并 =========>>
import time
for i in range(297):
time1 = time.time()
with open (f"./chaifen/help{i+1}.csv","r",newline='',encoding = "utf8") as af:
rows = csv.reader(af)
with open("./chaifen/a.csv","a+",encoding = "utf8",newline='') as bf:
for row in rows:
writer = csv.writer(bf)
writer.writerow(row)
print(f"第{i}个数据集已加入,用时{time.time()-time1}")
print(f"all is over,用时{time.time()-time1}")
完结撒花!
版权归原作者 Josepyth 所有, 如有侵权,请联系我们删除。