
新的社会分层
- AI使用者:人人可以
- AI产品开发者:课程的定位也在这里
- 基础模型相关:门槛特别高,机会特别难遇到
AI产品开发者的核心能力模型
三懂:
- 懂业务:就是懂用户、懂客户、懂需求、懂市场、懂运营、懂商业模式
- 懂AI:就是懂AI能做什么,不能做什么;怎样才能做得更好,更快,更便宜
- 懂编程:就是懂如何编程实现一个符合业务需求的产品
三种人:
- AI全栈工程师:懂业务、懂AI、懂编程
- 业务向:懂业务、懂AI - 试试学编程,自主性更强;- 两个门槛:科学上网;编程环境搭建
- 编程向:懂编程、懂AI - 纯工程师,不太吃香了(CTO失业)
核心就是懂业务,懂编程,懂AI并不难,需要从业务中去实践
行业共识:
- 确定未来-AI必然重构世界
- 确定进入-想收获红利,必须马上进入
- 不确定落地-解决什么问题,用什么技术路线,产品策略是什么,确定性都不高
——「不确定」确定了,代码的价值才大
思考:「智能冰箱」是AI吗?
一种观点:基于机器学习、神经网络的是AI,基于规则、搜索的你是AI。
大语言模型能做什么?
本课第一个专业向要求:分清对话产品和大模型。
- 信息抽取
- 文本分类
- 文本聚类
- 持续互动(如下棋)
找落地场景的思路
- 从最熟悉的领域入手
- 找「文本进、文本出」的场景
- 别求大而全。将任务拆解,先解决小任务、小场景
- 让AI学最厉害员工的能力,再让ta辅助其他员工,实现降本增效
大语言模型的原理
用不严密但通俗的语言描述训练和推理的原理:
训练
- 大模型阅读了人类说过的所有的话。这就是「机器学习」
- 训练过程会把不同token同时出现的概率存入「神经网络」文件。保存的数据就是「参数」,也叫「权重」
推理
- 我们给推理程序若干token,程序会加载大模型权重,算出出概率最高的下一个token是什么
- 用生成的token,再加上上文,就能继续生成下一个token。以此类推,生成更多文字
Token是什么?
- 可能是一个英文单词,也可能是半个,三分之一个
- 可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至至三分之一个汉字
- 大模型在开训前,需要先训练一个tokenizer模型。它能把所有的文本,切成token
思考:
- AI做对的事,怎么用这个原理解释?
- Al的幻觉,一本正经地胡说八道,怎么用这个原理解释?
这套生成机制的内核叫「Transformer架构」。Transformer仍是主流,但其实已经不是最先进的了。
——但目前只有transformer被证明了符合scaling-law
"scaling-law",它是指模型性能与模型大小、数据量和计算资源之间的关系。在NLP领域,研究人员发现,对于Transformer模型,其性能与模型参数量、训练数据量和计算量之间存在一定的可预测关系。这意味着,如果我们按照一定的比例增加模型的规模,我们可以在一定程度上预测模型性能的提升。这种可预测性为模型的开发和优化提供了重要的指导。
用AI的三个模式
- 三个模式- AI Embedded模式 - 这种模式指的是将人工智能技术嵌入到一个设备或一个系统中。嵌入式AI可以在各种设备中找到,如智能手机、家用电器、汽车等,它们在本地执行AI算法,而不依赖于云服务。这种模式的优势在于它可以即时处理信息,减少延迟,并且可以在没有网络连接的情况下工作。- AI Copilot模式 - AI Copilot模式通常是指一个人工智能系统,它作为人类的辅助,可以在各种复杂任务中提供支持。这个术语灵感来源于飞机的副驾驶,它帮助飞行员执行飞行任务,确保飞行的安全和效率。在AI领域,Copilot模式可以是任何形式的辅助系统,如智能助手、推荐系统或决策支持系统,它通过分析大量数据来提供建议或辅助决策,但最终的控制权仍在人类手中。- AI Agent模式 - AI Agent是一种自主的智能体,它可以在没有人类直接指导的情况下运行,并能够执行一系列复杂的任务。这种模式下的AI系统通常具有学习能力,能够根据环境变化调整自己的行为。AI代理可以是虚拟的,比如软件应用程序,也可以是物理的,比如机器人。它们在执行任务时不需要人类干预,能够自主做出决策并解决问题。
- 点评 - Agent还太超前,Copilot值得追求。
大模型应用技术架构
纯prompt
agent+function calling- agent:AI主动提要求;- Function Calling:Al要求执行某个函数- 当人看:你问ta过年去哪玩,ta先问你有多少预算
RAG (Retrieval-Augmented Generation)- Embeddirgs:把文字转换为更易于相似度计算的编码。这种编码叫向量- 向量数据库:把向量存起来,方便查找- 向量搜索:根据输入向量,找到最相似的向量- 当人看:考试答题时,到书上找相关内容,再结合题目组成答案,,然后,就都忘了
Fine-tuning(精调/微调)- 当人看:努力学习考试内容,长期记住,活学活用。
学习微调和RAG模式是让自己能够和其他用AI人的关键
ai做应用的步骤
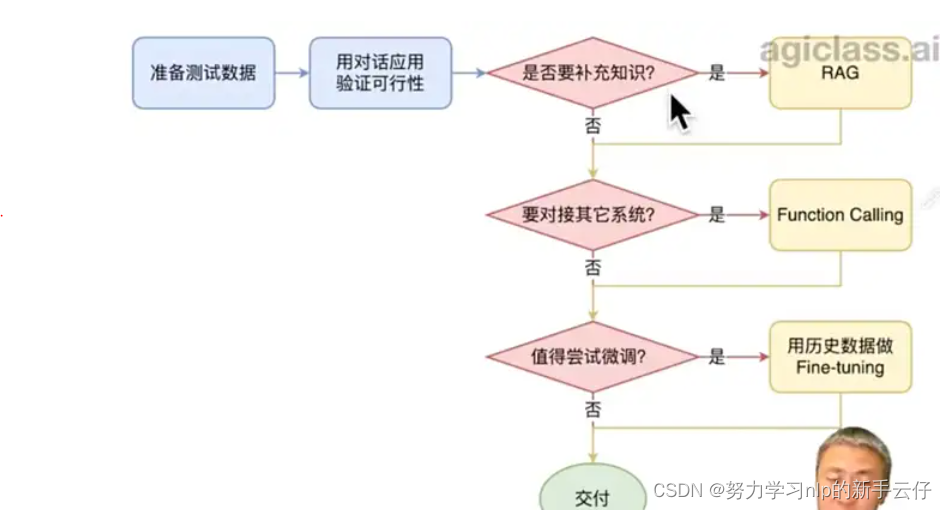
步骤可以按照 提示词→RAG→微调 来使得ai能够完成某个任务
值得尝试fine-tune的场景:
- 提高模型输出的稳定性
- 用户量大,降低推理成本的意义很大
- 提高大模型的生成速度
- 需要私有部署
选择大模型的依据
没有最好的大模型,只有最适合的大模型,能够在成本和效率取得最优化的大模型!
标签:
笔记
本文转载自: https://blog.csdn.net/u014397365/article/details/139104859
版权归原作者 努力学习nlp的新手云仔 所有, 如有侵权,请联系我们删除。
版权归原作者 努力学习nlp的新手云仔 所有, 如有侵权,请联系我们删除。