
Elasticsearch 系列文章
1、介绍lucene的功能以及建立索引、搜索单词、搜索词语和搜索句子四个示例实现
2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、Elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、Elasticsearch7.6.1 Java api操作ES(CRUD、两种分页方式、高亮显示)和Elasticsearch SQL详细示例
5、Elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
7、Elasticsearch7.6.1收集nginx日志及监测指标示例
8、Elasticsearch7.6.1收集mysql慢查询日志及监控
9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop
文章目录
本文简单的介绍了ES-hadoop组件功能使用,即通过ES-hadoop实现相互数据写入示例。
本文依赖es环境、hadoop环境好用。
本文分为三部分,即ES-hadoop介绍、ES数据写入hadoop和hadoop数据写入ES。
一、ES-Hadoop介绍
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。
本文介绍如何通过ES-Hadoop实现Hadoop的Hive服务读写Elasticsearch数据。
Hadoop生态的优势是处理大规模数据集,但是其缺点也很明显,就是当用于交互式分析时,查询时延会比较长。而Elasticsearch擅长于交互式分析,对于很多查询类型,特别是对于Ad-hoc查询(即席查询),可以达到秒级。ES-Hadoop的推出提供了一种组合两者优势的可能性。使用ES-Hadoop,您只需要对代码进行很小的改动,即可快速处理存储在Elasticsearch中的数据,并且能够享受到Elasticsearch带来的加速效果。
ES-Hadoop的原理是将Elasticsearch作为MR、Spark或Hive等数据处理引擎的数据源,在计算存储分离的架构中扮演存储的角色。这和 MR、Spark或Hive的数据源并无差异,但相对于这些数据源,Elasticsearch具有更快的数据选择过滤能力。这种能力正是分析引擎最为关键的能力之一。
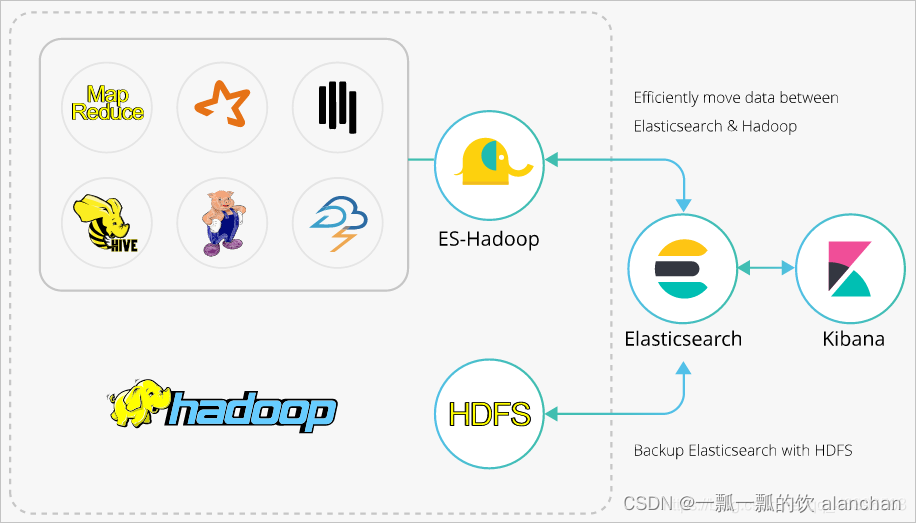
二、ES写入HDFS
假设es中已经存储具体索引数据,下面仅仅是将es的数据读取并存入hdfs中。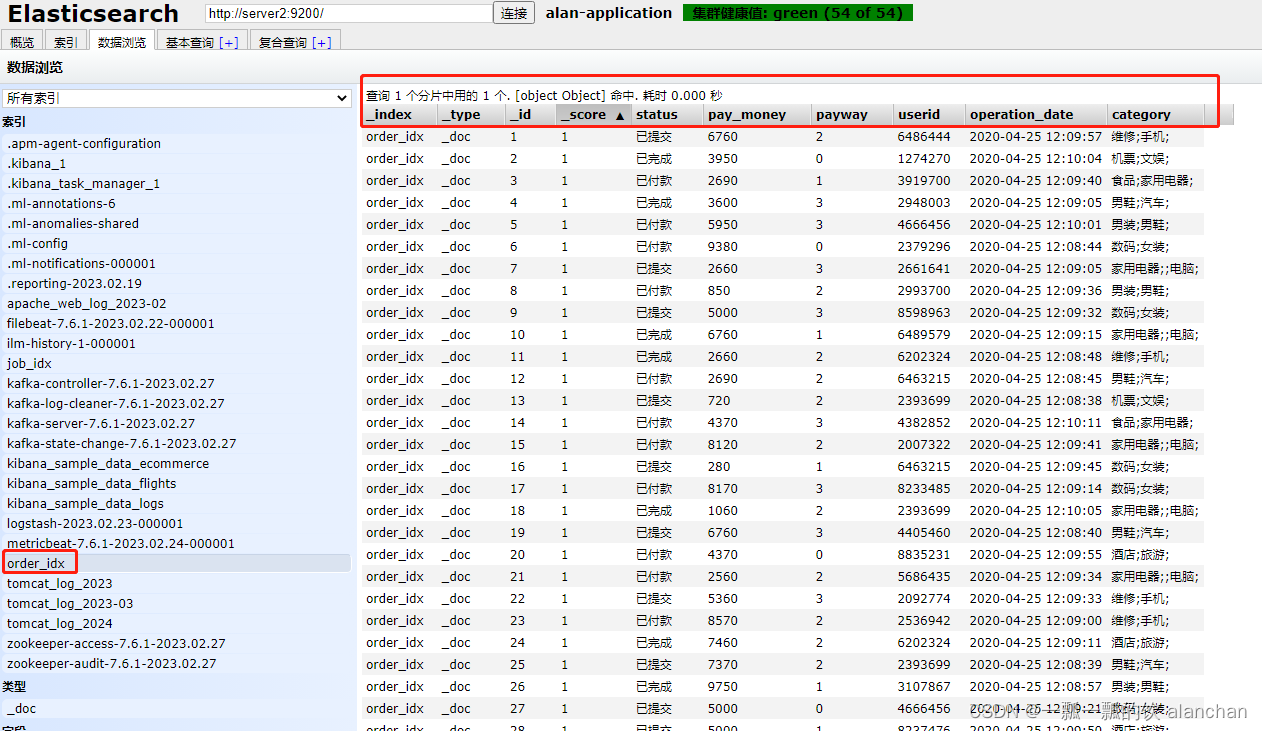
1、txt文件格式写入
1)、pom.xml
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-hadoop</artifactId><version>7.6.1</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>7.6.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.1.4</version></dependency><!-- https://mvnrepository.com/artifact/commons-httpclient/commons-httpclient --><dependency><groupId>commons-httpclient</groupId><artifactId>commons-httpclient</artifactId><version>3.1</version></dependency><!-- https://mvnrepository.com/artifact/com.google.code.gson/gson --><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.10.1</version></dependency>
2)、示例1:order_idx
将ES中的order_idx索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key 5000,value {status=已付款, pay_money=3820.0, payway=3, userid=4405460,operation_date=2020-04-25 12:09:51, category=维修;手机;}
- 实现
importjava.io.IOException;importjava.util.Iterator;importjava.util.Map;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.hadoop.util.Tool;importorg.apache.hadoop.util.ToolRunner;importorg.elasticsearch.hadoop.mr.EsInputFormat;importorg.elasticsearch.hadoop.mr.LinkedMapWritable;importlombok.Data;importlombok.extern.slf4j.Slf4j;@Slf4jpublicclassESToHdfsextendsConfiguredimplementsTool{privatestaticString out ="/ES-Hadoop/test";publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();int status =ToolRunner.run(conf,newESToHdfs(), args);System.exit(status);}staticclassESToHdfsMapperextendsMapper<Text,LinkedMapWritable,NullWritable,Text>{Text outValue =newText();protectedvoidmap(Text key,LinkedMapWritable value,Context context)throwsIOException,InterruptedException{// log.info("key {} , value {}", key.toString(), value);Order order =newOrder();// order.setId(Integer.parseInt(key.toString()));Iterator it = value.entrySet().iterator();
order.setId(key.toString());String name =null;String data =null;while(it.hasNext()){Map.Entry entry =(Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();switch(name){case"userid":
order.setUserid(Integer.parseInt(data));break;case"operation_date":
order.setOperation_date(data);break;case"category":
order.setCategory(data);break;case"pay_money":
order.setPay_money(Double.parseDouble(data));break;case"status":
order.setStatus(data);break;case"payway":
order.setPayway(data);break;}}//log.info("order={}", order);
outValue.set(order.toString());
context.write(NullWritable.get(), outValue);}}@DatastaticclassOrder{// key 5000 value {status=已付款, pay_money=3820.0, payway=3, userid=4405460, operation_date=2020-04-25 12:09:51, category=维修;手机;}privateString id;privateint userid;privateString operation_date;privateString category;privatedouble pay_money;privateString status;privateString payway;publicStringtoString(){returnnewStringBuilder(id).append(",").append(userid).append(",").append(operation_date).append(",").append(category).append(",").append(pay_money).append(",").append(status).append(",").append(payway).toString();}}@Overridepublicintrun(String[] args)throwsException{Configuration conf =getConf();
conf.set("fs.defaultFS","hdfs://HadoopHAcluster");
conf.set("dfs.nameservices","HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster","nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1","server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2","server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");System.setProperty("HADOOP_USER_NAME","alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution",false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution",false);
conf.set("es.nodes","server1:9200,server2:9200,server3:9200");// ElaticSearch 索引名称
conf.set("es.resource","order_idx");// 查询索引中的所有数据,也可以加条件
conf.set("es.query","{ \"query\": {\"match_all\": { }}}");Job job =Job.getInstance(conf,ESToHdfs.class.getName());// 设置作业驱动类
job.setJarByClass(ESToHdfs.class);// 设置ES的输入类型
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfsMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);FileOutputFormat.setOutputPath(job,newPath(out));
job.setNumReduceTasks(0);return job.waitForCompletion(true)?0:1;}}
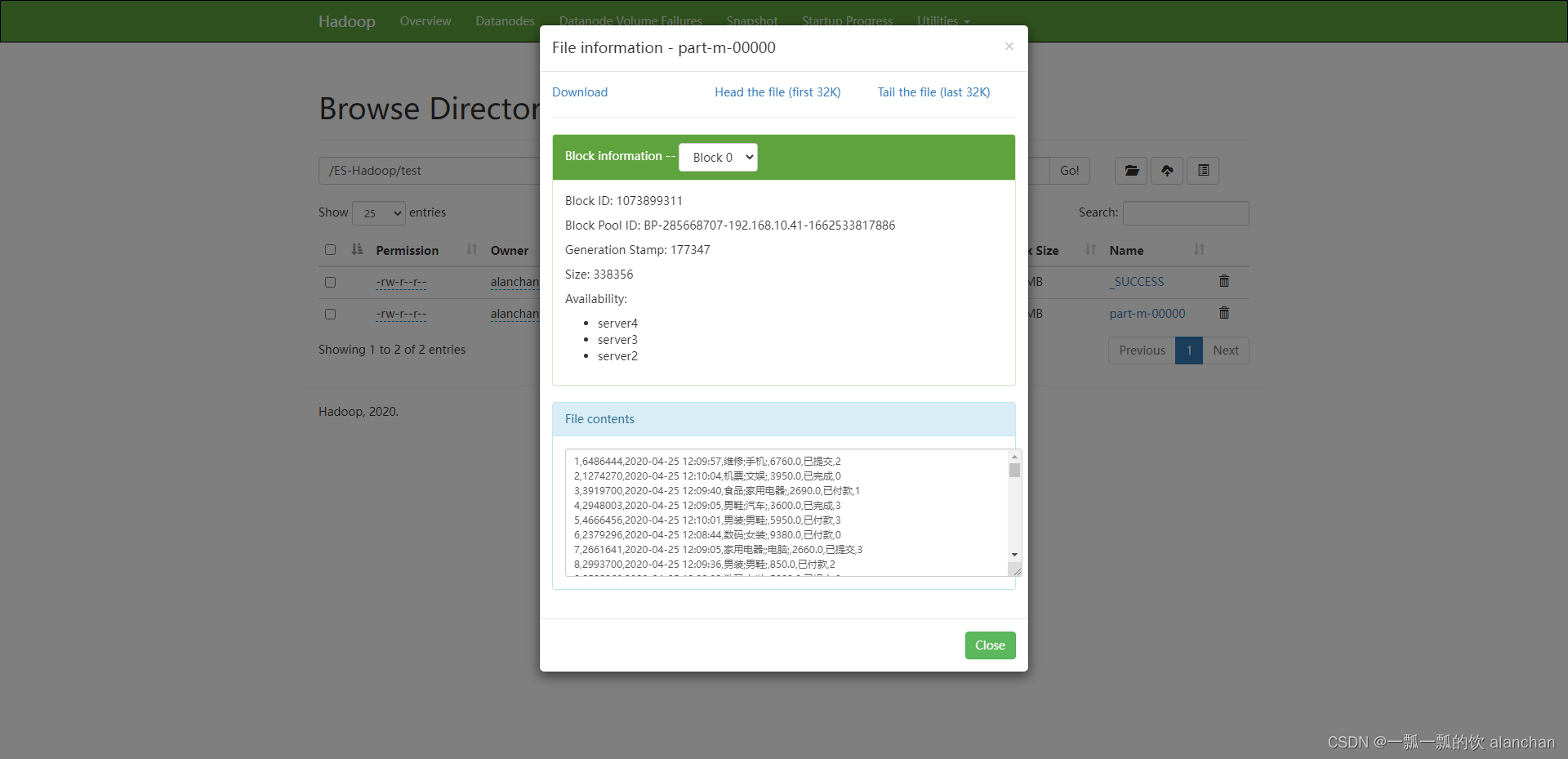
- 验证 结果如下图
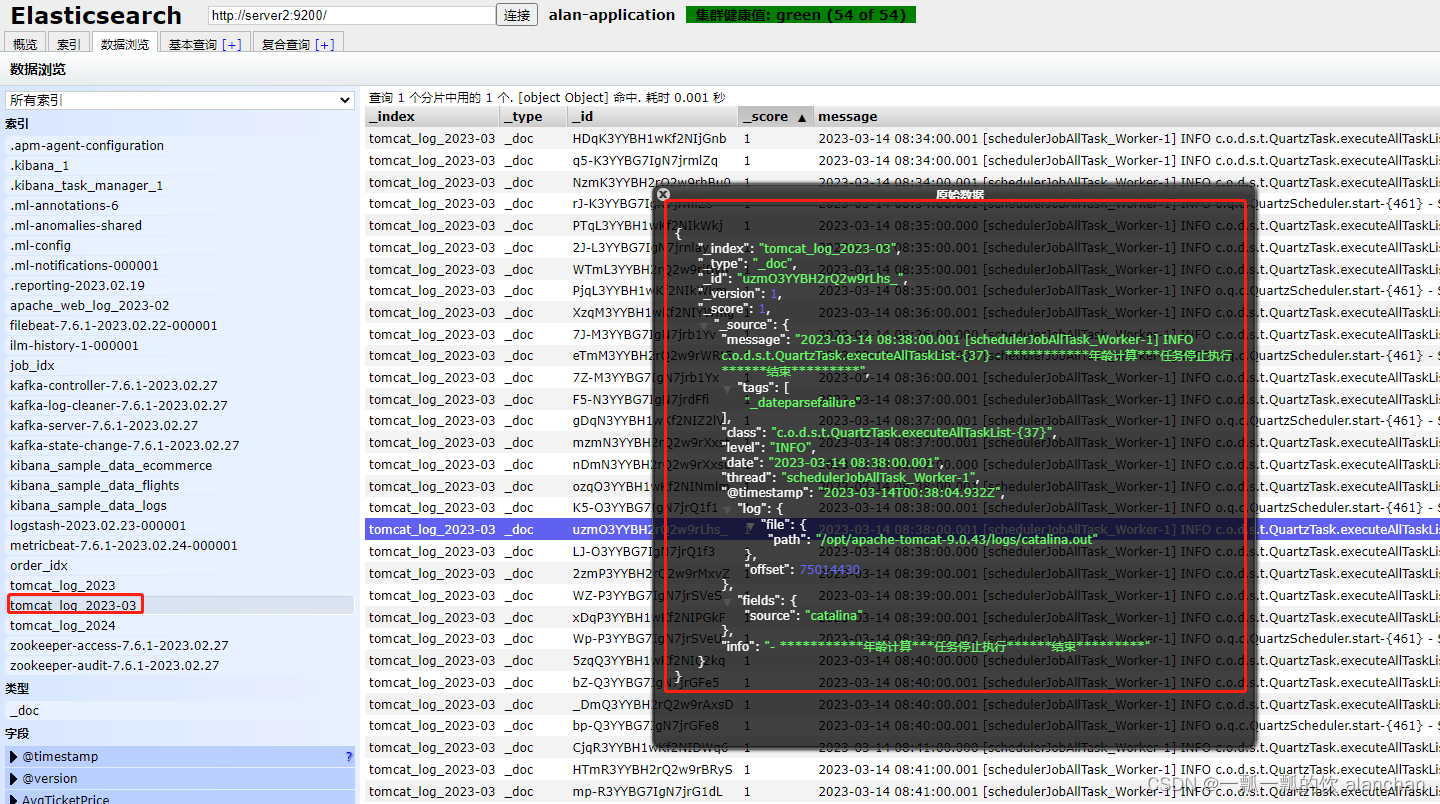
3)、示例2:tomcat_log_2023-03
将ES中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以txt形式存储的,其中数据用逗号隔离
- 其数据结构
key Uzm_44YBH2rQ2w9r5vqK, value {message=2023-03-1513:30:00.001[schedulerJobAllTask_Worker-1] INFO c.o.d.s.t.QuartzTask.executeAllTaskList-{37}- 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure],class=c.o.d.s.t.QuartzTask.executeAllTaskList-{37}, level=INFO, date=2023-03-1513:30:00.001, thread=schedulerJobAllTask_Worker-1, fields={source=catalina},@timestamp=2023-03-15T05:30:06.812Z, log={file={path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
importjava.io.IOException;importjava.util.Iterator;importjava.util.Map;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.hadoop.util.Tool;importorg.apache.hadoop.util.ToolRunner;importorg.elasticsearch.hadoop.mr.EsInputFormat;importorg.elasticsearch.hadoop.mr.LinkedMapWritable;importlombok.Data;importlombok.extern.slf4j.Slf4j;@Slf4jpublicclassESToHdfs2extendsConfiguredimplementsTool{privatestaticString out ="/ES-Hadoop/tomcatlog";staticclassESToHdfs2MapperextendsMapper<Text,LinkedMapWritable,NullWritable,Text>{Text outValue =newText();protectedvoidmap(Text key,LinkedMapWritable value,Context context)throwsIOException,InterruptedException{// log.info("key {} , value {}", key.toString(), value);TomcatLog tLog =newTomcatLog();Iterator it = value.entrySet().iterator();String name =null;String data =null;while(it.hasNext()){Map.Entry entry =(Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();switch(name){case"date":
tLog.setDate(data.replace('/','-'));break;case"thread":
tLog.setThread(data);break;case"level":
tLog.setLogLevel(data);break;case"class":
tLog.setClazz(data);break;case"info":
tLog.setLogMsg(data);break;}}
outValue.set(tLog.toString());
context.write(NullWritable.get(), outValue);}}@DatastaticclassTomcatLog{privateString date;privateString thread;privateString logLevel;privateString clazz;privateString logMsg;publicStringtoString(){returnnewStringBuilder(date).append(",").append(thread).append(",").append(logLevel).append(",").append(clazz).append(",").append(logMsg).toString();}}publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();int status =ToolRunner.run(conf,newESToHdfs2(), args);System.exit(status);}@Overridepublicintrun(String[] args)throwsException{Configuration conf =getConf();
conf.set("fs.defaultFS","hdfs://HadoopHAcluster");
conf.set("dfs.nameservices","HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster","nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1","server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2","server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");System.setProperty("HADOOP_USER_NAME","alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution",false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution",false);
conf.set("es.nodes","server1:9200,server2:9200,server3:9200");// ElaticSearch 索引名称
conf.set("es.resource","tomcat_log_2023-03");
conf.set("es.query","{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");Job job =Job.getInstance(conf,ESToHdfs2.class.getName());// 设置作业驱动类
job.setJarByClass(ESToHdfs2.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfs2Mapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);FileOutputFormat.setOutputPath(job,newPath(out));
job.setNumReduceTasks(0);return job.waitForCompletion(true)?0:1;}}
- 验证
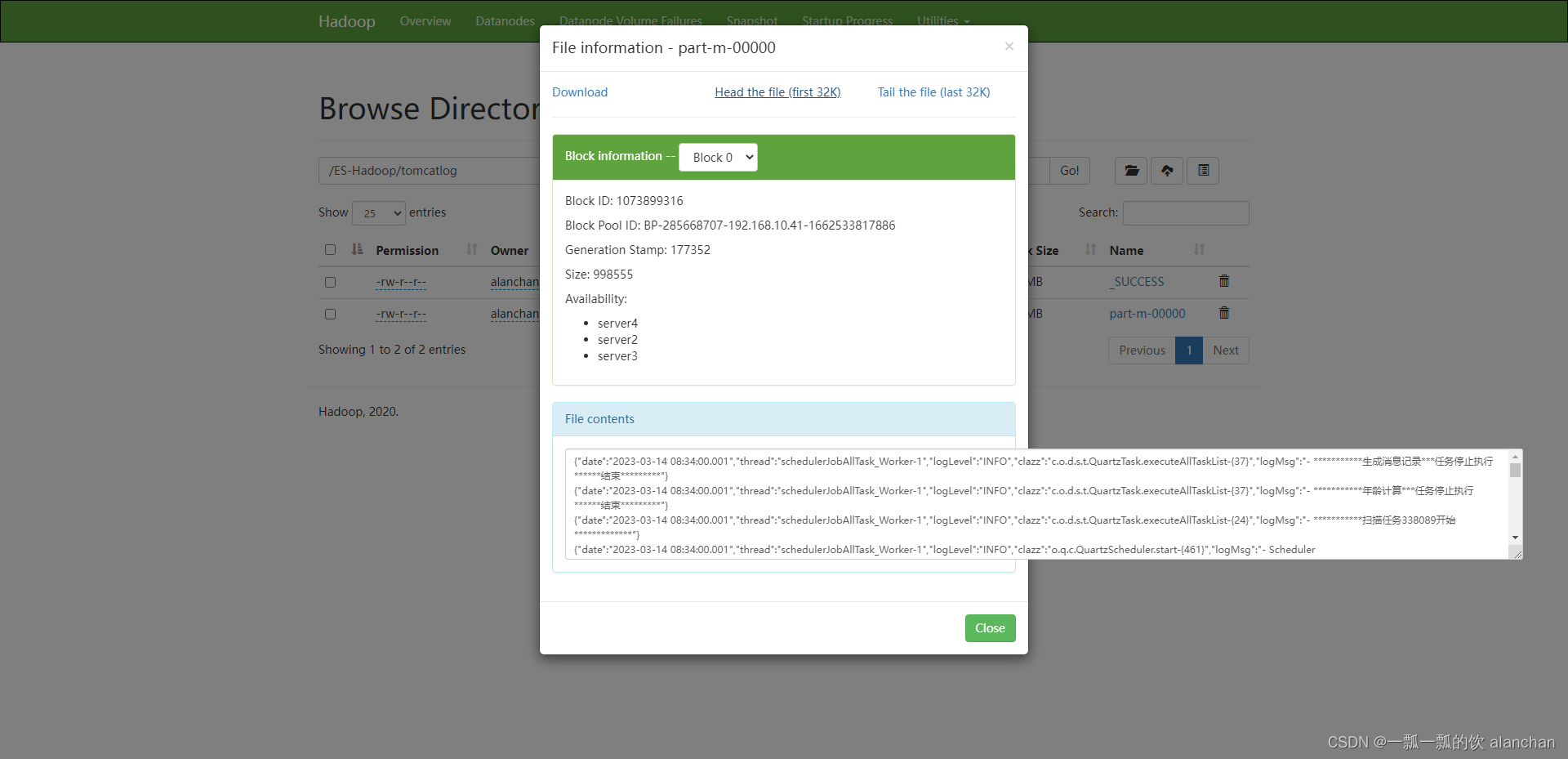
2、json文件格式写入
将ES中的tomcat_log_2023-03索引数据存储至hdfs中,其中hdfs是HA。hdfs中是以json形式存储的
- 其数据结构
key Uzm_44YBH2rQ2w9r5vqK, value {message=2023-03-1513:30:00.001[schedulerJobAllTask_Worker-1] INFO c.o.d.s.t.QuartzTask.executeAllTaskList-{37}- 生成消息记录任务停止执行结束*******, tags=[_dateparsefailure],class=c.o.d.s.t.QuartzTask.executeAllTaskList-{37}, level=INFO, date=2023-03-1513:30:00.001, thread=schedulerJobAllTask_Worker-1, fields={source=catalina},@timestamp=2023-03-15T05:30:06.812Z, log={file={path=/opt/apache-tomcat-9.0.43/logs/catalina.out}, offset=76165371}, info=- 生成消息记录任务停止执行结束*******}
- 实现
importjava.io.IOException;importjava.util.Iterator;importjava.util.Map;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.hadoop.util.Tool;importorg.apache.hadoop.util.ToolRunner;importorg.elasticsearch.hadoop.mr.EsInputFormat;importorg.elasticsearch.hadoop.mr.LinkedMapWritable;importcom.google.gson.Gson;importlombok.Data;publicclassESToHdfsByJsonextendsConfiguredimplementsTool{privatestaticString out ="/ES-Hadoop/tomcatlog_json";publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();int status =ToolRunner.run(conf,newESToHdfsByJson(), args);System.exit(status);}@Overridepublicintrun(String[] args)throwsException{Configuration conf =getConf();
conf.set("fs.defaultFS","hdfs://HadoopHAcluster");
conf.set("dfs.nameservices","HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster","nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1","server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2","server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");System.setProperty("HADOOP_USER_NAME","alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution",false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution",false);
conf.set("es.nodes","server1:9200,server2:9200,server3:9200");// ElaticSearch 索引名称
conf.set("es.resource","tomcat_log_2023-03");
conf.set("es.query","{\"query\":{\"bool\":{\"must\":[{\"match_all\":{}}],\"must_not\":[],\"should\":[]}},\"from\":0,\"size\":10,\"sort\":[],\"aggs\":{}}");Job job =Job.getInstance(conf,ESToHdfs2.class.getName());// 设置作业驱动类
job.setJarByClass(ESToHdfsByJson.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(ESToHdfsByJsonMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);FileOutputFormat.setOutputPath(job,newPath(out));
job.setNumReduceTasks(0);return job.waitForCompletion(true)?0:1;}staticclassESToHdfsByJsonMapperextendsMapper<Text,LinkedMapWritable,NullWritable,Text>{Text outValue =newText();privateGson gson =newGson();protectedvoidmap(Text key,LinkedMapWritable value,Context context)throwsIOException,InterruptedException{// log.info("key {} , value {}", key.toString(), value);TomcatLog tLog =newTomcatLog();// tLog.setId(key.toString());Iterator it = value.entrySet().iterator();String name =null;String data =null;while(it.hasNext()){Map.Entry entry =(Map.Entry) it.next();
name = entry.getKey().toString();
data = entry.getValue().toString();switch(name){case"date":
tLog.setDate(data.replace('/','-'));break;case"thread":
tLog.setThread(data);break;case"level":
tLog.setLogLevel(data);break;case"class":
tLog.setClazz(data);break;case"info":
tLog.setLogMsg(data);break;}}
outValue.set(gson.toJson(tLog));
context.write(NullWritable.get(), outValue);}}@DatastaticclassTomcatLog{// private String id ;privateString date;privateString thread;privateString logLevel;privateString clazz;privateString logMsg;}}
- 验证
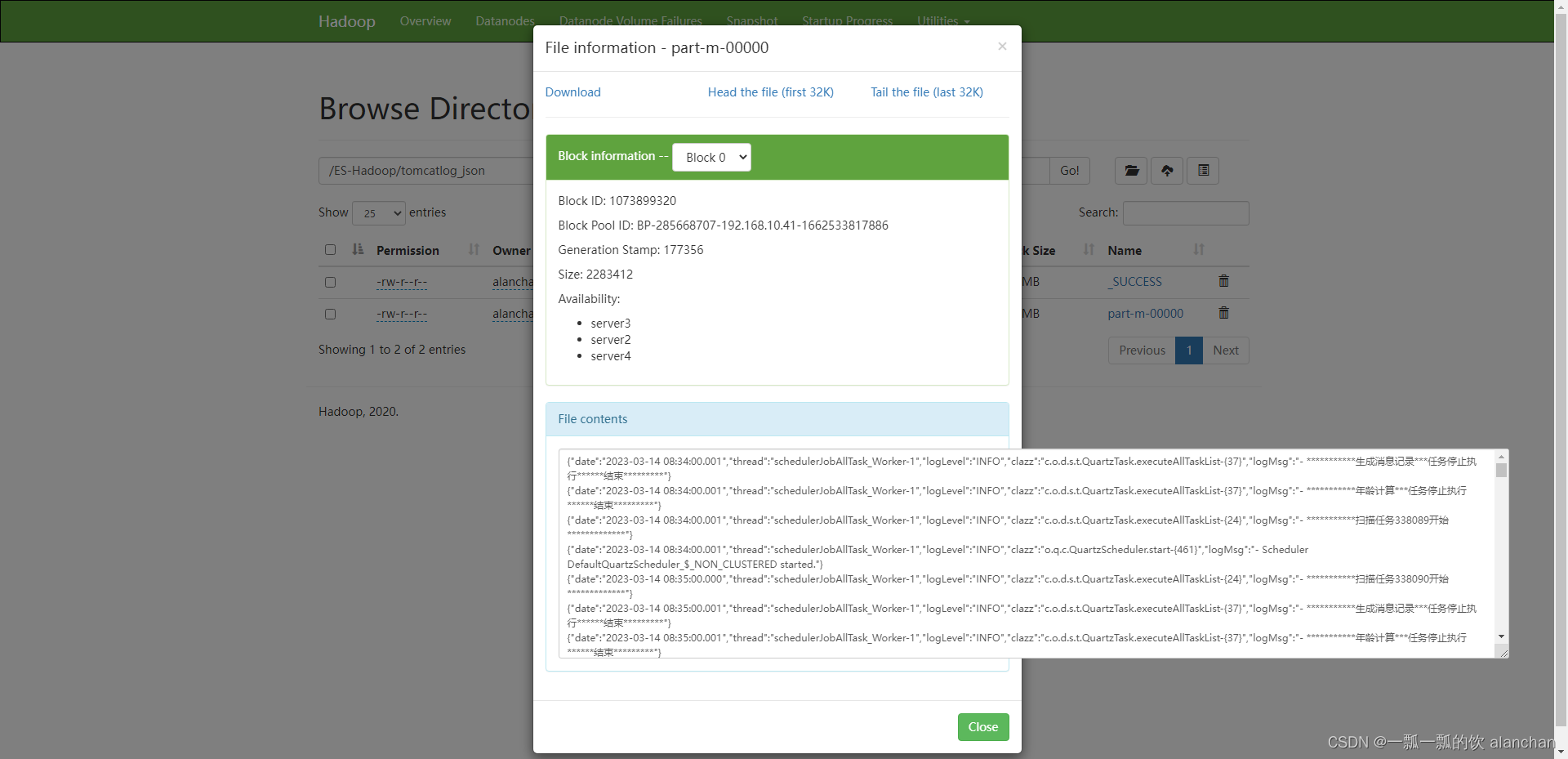
三、HDFS写入ES
本示例以上述例子中存入hdfs的数据。经过测试,ES只能将json的数据导入。
pom.xml参考上述例子
1、txt文件写入
先将数据转换成json后存入
importjava.io.IOException;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.util.Tool;importorg.apache.hadoop.util.ToolRunner;importorg.elasticsearch.hadoop.mr.EsOutputFormat;importcom.google.gson.Gson;importlombok.Data;importlombok.extern.slf4j.Slf4j;@Slf4jpublicclassHdfsTxtDataToESextendsConfiguredimplementsTool{privatestaticString out ="/ES-Hadoop/tomcatlog";publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();int status =ToolRunner.run(conf,newHdfsTxtDataToES(), args);System.exit(status);}@DatastaticclassTomcatLog{privateString date;privateString thread;privateString logLevel;privateString clazz;privateString logMsg;}@Overridepublicintrun(String[] args)throwsException{Configuration conf =getConf();
conf.set("fs.defaultFS","hdfs://HadoopHAcluster");
conf.set("dfs.nameservices","HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster","nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1","server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2","server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");System.setProperty("HADOOP_USER_NAME","alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution",false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution",false);
conf.set("es.nodes","server1:9200,server2:9200,server3:9200");// ElaticSearch 索引名称,可以不提前创建
conf.set("es.resource","tomcat_log_2024");// Hadoop上的数据格式为JSON,可以直接导入
conf.set("es.input.json","yes");Job job =Job.getInstance(conf,HdfsTxtDataToES.class.getName());// 设置作业驱动类
job.setJarByClass(HdfsTxtDataToES.class);// 设置EsOutputFormat
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(HdfsTxtDataToESMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);FileInputFormat.setInputPaths(job,newPath(out));
job.setNumReduceTasks(0);return job.waitForCompletion(true)?0:1;}staticclassHdfsTxtDataToESMapperextendsMapper<LongWritable,Text,NullWritable,Text>{Text outValue =newText();TomcatLog tLog =newTomcatLog();Gson gson =newGson();protectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{
log.info("key={},value={}", key, value);// date:2023-03-13 17:33:00.001,// thread:schedulerJobAllTask_Worker-1,// loglevel:INFO,// clazz:o.q.c.QuartzScheduler.start-{461},// logMsg:- Scheduler DefaultQuartzScheduler_$_NON_CLUSTERED started.String[] lines = value.toString().split(",");
tLog.setDate(lines[0]);
tLog.setThread(lines[1]);
tLog.setLogLevel(lines[2]);
tLog.setClazz(lines[3]);
tLog.setLogMsg(lines[4]);
outValue.set(gson.toJson(tLog));
context.write(NullWritable.get(), outValue);}}}
2、json文件写入
importjava.io.IOException;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.util.Tool;importorg.apache.hadoop.util.ToolRunner;importorg.elasticsearch.hadoop.mr.EsOutputFormat;importlombok.extern.slf4j.Slf4j;@Slf4jpublicclassHdfsJsonDataToESextendsConfiguredimplementsTool{privatestaticString out ="/ES-Hadoop/tomcatlog_json";publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();int status =ToolRunner.run(conf,newHdfsJsonDataToES(), args);System.exit(status);}@Overridepublicintrun(String[] args)throwsException{Configuration conf =getConf();
conf.set("fs.defaultFS","hdfs://HadoopHAcluster");
conf.set("dfs.nameservices","HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster","nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1","server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2","server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");System.setProperty("HADOOP_USER_NAME","alanchan");
conf.setBoolean("mapred.map.tasks.speculative.execution",false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution",false);
conf.set("es.nodes","server1:9200,server2:9200,server3:9200");// ElaticSearch 索引名称,可以不提前创建
conf.set("es.resource","tomcat_log_2023");//Hadoop上的数据格式为JSON,可以直接导入
conf.set("es.input.json","yes");Job job =Job.getInstance(conf,HdfsJsonDataToES.class.getName());// 设置作业驱动类
job.setJarByClass(HdfsJsonDataToES.class);
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(HdfsJsonDataToESMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);FileInputFormat.setInputPaths(job,newPath(out));
job.setNumReduceTasks(0);return job.waitForCompletion(true)?0:1;}staticclassHdfsJsonDataToESMapperextendsMapper<LongWritable,Text,NullWritable,Text>{protectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{
log.info("key={},value={}",key,value);
context.write(NullWritable.get(), value);}}}
以上,简单的介绍了ES-hadoop组件功能使用,即通过ES-hadoop实现相互数据写入示例。
版权归原作者 一瓢一瓢的饮 alanchan 所有, 如有侵权,请联系我们删除。