
一.安装部署
在安装前先确保Hadoop是启动状态。
1.下载flume安装包
自行去官网下载即可Download — Apache Flume,我下载的是flume1.11.0
2.上传安装包并解压
上传后解压
tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /opt/server
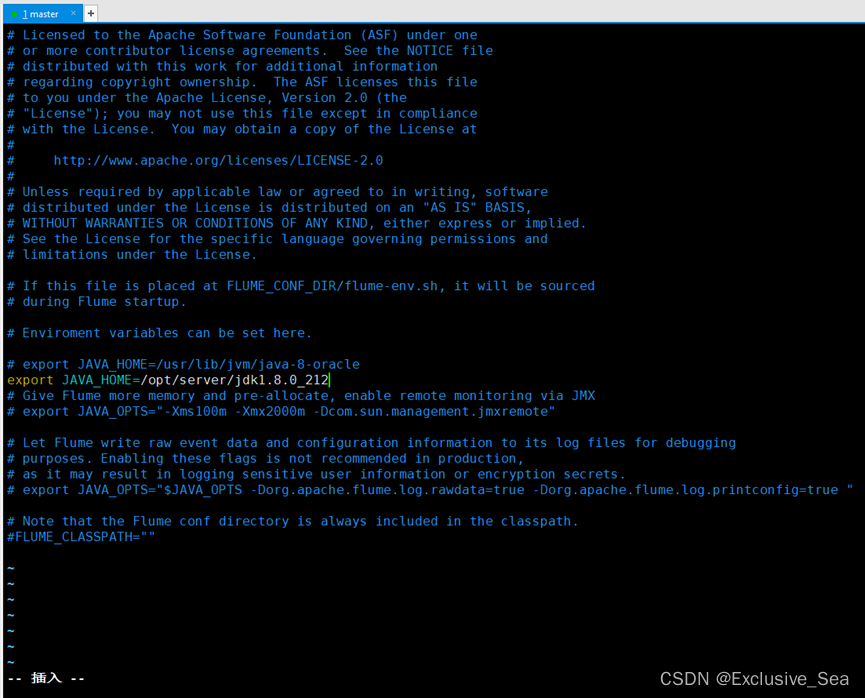
3.进入flume目录,修改conf下的flume-env.sh,配置JAVA_HOME
cd /opt/server/apache-flume-1.11.0-bin/conf
# 先复制一份flume-env.sh.template文件
cp flume-env.sh.template flume-env.sh
# 修改
vim flume-env.sh
export JAVA_HOME=/opt/server/jdk1.8.0_212
二.采集Nginx日志数据至HDFS
1.安装Nginx
yum install epel-release
yum update
yum -y install nginx
以下是Nginx的一些基本命令:
systemctl start nginx #开启nginx服务
systemctl stop nginx #停止nginx服务
systemctl restart nginx #重启nginx服务
Nginx服务器默认占用80端口,开启Nginx后去浏览器输入虚拟机ip:80查看如果有如下页面说明开启
网站日志文件位置:
cd /var/log/nginx
可访问文件位置查看日志:

2.编写配置文件
将flume下的lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop3.1.3,flume1.11.0
cd /opt/server/apache-flume-1.11.0-bin/lib
然后将Hadoop中的jar包复制到flume文件夹中,这里根据自己的flume位置和Hadoop位置进行修改
cp /opt/hadoop/hadoop/share/hadoop/common/*.jar /opt/server/apache-flume-1.11.0-bin/lib
cp /opt/hadoop/hadoop/share/hadoop/common/lib/*.jar /opt/server/apache-flume-1.11.0-bin/lib
cp /opt/hadoop/hadoop/share/hadoop/hdfs/*.jar /opt/server/apache-flume-1.11.0-bin/lib

有需要覆盖的jar包直接按y覆盖即可
接下来创建配置文件,taildir-hdfs.conf用于监控 /var/log/nginx 目录下的日志文件
先cd /opt/server/apache-flume-1.11.0-bin/conf
然后vim taildir-hdfs.conf粘贴以下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.filegroups = f1
# 此处支持正则
a3.sources.r3.filegroups.f1 = /var/log/nginx/access.log
# 用于记录文件读取的位置信息
a3.sources.r3.positionFile = /opt/server/apache-flume-1.11.0-bin/tail_dir.json
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://server:8020/user/tailDir
a3.sinks.k3.hdfs.fileType = DataStream
# 设置每个文件的滚动大小大概是 128M,默认值:1024,当临时文件达到该大小(单位:bytes)时,滚动
成目标文件。如果设置成0,则表示不根据临时文件大小来滚动文件。
a3.sinks.k3.hdfs.rollSize = 134217700
# 默认值:10,当events数据达到该数量时候,将临时文件滚动成目标文件,如果设置成0,则表示不根据
events数据来滚动文件。
a3.sinks.k3.hdfs.rollCount = 0
# 不随时间滚动,默认为30秒
a3.sinks.k3.hdfs.rollInterval = 10
# flume检测到hdfs在复制块时会自动滚动文件,导致roll参数不生效,要将该参数设置为1;否则HFDS文
件所在块的复制会引起文件滚动
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
hdfs://server:8020/user/tailDir中的server改为自己的主机名,虚拟机可以改为自己的虚拟机ip地址
三.查看自己的版本并启动flume
1.查看版本
首先
cd /opt/server/apache-flume-1.11.0-bin
然后输入以下命令查看flume版本
bin/flume-ng version
若可以显示如下界面,则说明安装成功

2.启动flume
同样是在/opt/server/apache-flume-1.11.0-bin下输入
bin/flume-ng agent -c ./conf -f ./conf/taildir-hdfs.conf -n a3-Dflume.root.logger=INFO,console

本文转载自: https://blog.csdn.net/qq_60968494/article/details/129923480
版权归原作者 Exclusive_Sea 所有, 如有侵权,请联系我们删除。
版权归原作者 Exclusive_Sea 所有, 如有侵权,请联系我们删除。