
目录
管理Kafka
Kafka 提供了一些命令行工具,用于管理集群的变更。这些工具使用 Java 类实现,Kafka 提供了一些脚本来调用这些 Java 类。不过,它们只提供了一些基本的功能,无法完成那 些复杂的操作。
虽然 Kafka 实现了操作主题的认证和授权控制,但还不支持集群的其他大部 分操作。也就是说,在没有认证的情况下也可以使用这些命令行工具,在没 有安全检查和审计的情况下也可以执行诸如主题变更之类的操作。
1、主题操作(kafka-topic.sh)
使用 kafka-topics.sh 工具可以执行主题的大部分操作(配置变更部分已经被弃用并被移动 到 kafka-configs.sh 工具当中)。我们可以用它创建、修改、删除和查看集群里的主题。要使用该工具的全部功能,需要通过 --bootstrap-server 参数提供broker的连接字符串。
1.1、创建主题(–create)
在集群里创建一个主题需要用到 3 个参数。这些参数是必须提供的,尽管有些已经有了broker 级别的默认值。
- 主题名字:题名字可以包含字母、数字、下划线以及英文状态下的破折号和句号。主题名字的开头部分包含两个下划线是合法的,但不建议这么做。具有这种 格式的主题一般是集群的内部主题(比如 __consumer_offsets 主题用于保存 消费者群组的偏移量)。也不建议在单个集群里使用英文状态下的句号和下 划线来命名,因为主题的名字会被用在度量指标上,句号会被替换成下划线 (比如“topic.1”会变成“topic_1”)。
- 复制系数:主题的副本数量。
- 分区:主题的分区数量
语法:
kafka-topics.sh --bootstrap-server <zookeeper connect>--create--topic<string> --replication-factor <integer>--partitions<integer>
示例:
# 使用以下命令创建一个叫作my-topic的主题,主题包含8个分区,每个分区拥有1个副本。
kafka-topics.sh --bootstrap-server localhost:9092 --create--topic my-topic --replication-factor 1 -- partitions 8
忽略重复创建主题的错误
在自动化系统里调用这个脚本时,可以使用 --if-not-exists 参数,这样即 使主题已经存在,也不会抛出重复创建主题的错误。
1.2、增加分区(–alter)
主题基于分区进行伸缩和复制,增加分区主要是 为了扩展主题容量或者降低单个分区的吞吐量。如果要在单个消费者群组内运行更多的消 费者,那么主题数量也需要相应增加,因为一个分区只能由群组里的一个消费者读取。
- 调整基于键的主题 从消费者角度来看,为基于键的主题添加分区是很困难的。因为如果改变了 分区的数量,键到分区之间的映射也会发生变化。所以,对于基于键的主题 来说,建议在一开始就设置好分区数量,避免以后对其进行调整。
- 忽略主题不存在的错误 在使用 --alter 命令修改主题时,如果指定了 --if-exists 参数,主题不存 在的错误就会被忽略。如果要修改的主题不存在,该命令并不会返回任何错 误。在主题不存在的时候本应该创建主题,但它却把错误隐藏起来,因此不 建议使用这个参数。
示例:
#将my-topic主题的分区增加到16
kafka-topics.sh --bootstrap-server localhost:9092 --alter--topic my-topic --partitions16
1.3、减少分区数量(无)
我们无法减少主题的分区数量。因为如果删除了分区,分区里的数据也一并 被删除,导致数据不一致。我们也无法将这些数据分配给其他分区,因为这 样做很难,而且会出现消息乱序。所以,如果一定要减少分区数量,只能删 除整个主题,然后重新创建它。
1.4、删除主题(–delete)
如果一个主题不再被使用,只要它还存在于集群里,就会占用一定数量的磁盘空间和文件 句柄。把它删除就可以释放被占用的资源。为了能够删除主题,broker 的
delete.topic. enable
参数必须被设置为 true。如果该参数被设为 false,删除主题的请求会被忽略。
示例:
# 删除my-topic主题
kafka-topics.sh --bootstrap-server localhost:9092 --delete--topic my-topic
1.5、列出集群里的所有主题(–list)
可以使用主题工具列出集群里的所有主题。每个主题占用一行输出,主题之间没有特定的顺序。
示例:
kafka-topics.sh --bootstrap-server localhost:9092 --list

1.6、列出主题详细信息(–describe)
主题工具还能用来获取主题的详细信息。信息里包含了分区数量、主题的覆盖配置以及 每个分区的副本清单。如果通过 --topic 参数指定特定的主题,就可以只列出指定主题 的详细信息。
示例:
kafka-topics.sh --bootstrap-server localhost:9092 --describe--topic my-topic
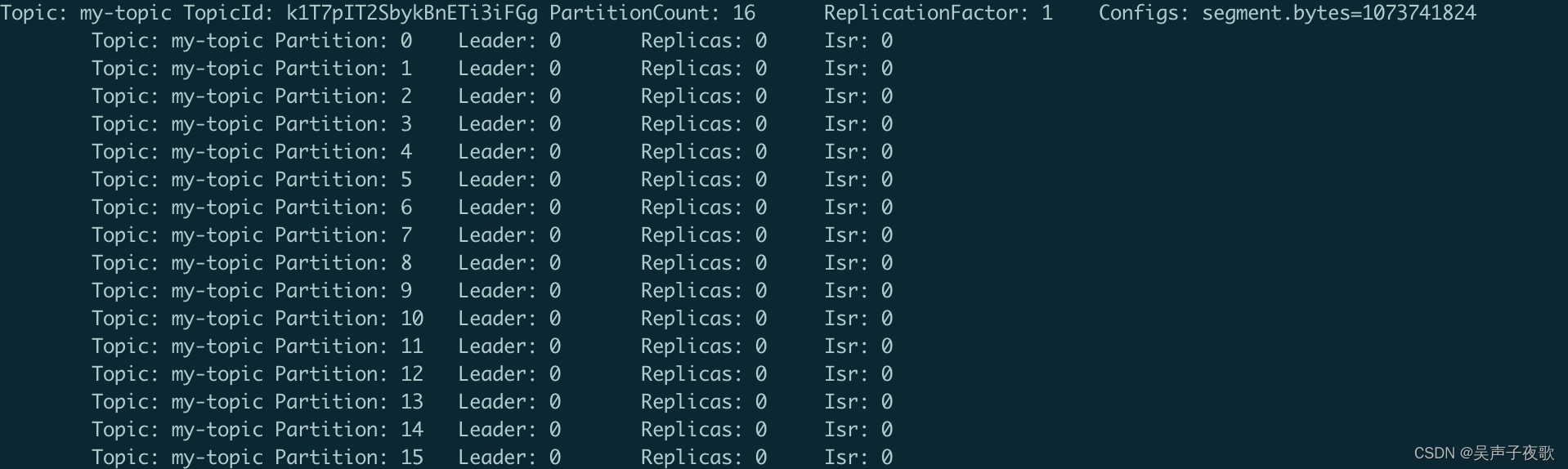
describe 命令还提供了一些参数,用于过滤输出结果,这在诊断集群问题时会很有用。不要为这些参数指定 --topic 参数(因为这些参数的目的是为了找出集群里所有满足条件的 主题和分区)。这些参数也无法与 list 命令一起使用(最后一部分会详细说明原因)。
使用
--topics-with-overrides
参数可以找出所有包含覆盖配置的主题,它只会列出包含了 与集群不一样配置的主题。
有两个参数可用于找出有问题的分区。
--under-replicated-partitions
参数可以列出 所有包含不同步副本的分区。
--unavailable-partitions
参数可以列出所有没有首领 的分区,这些分区已经处于离线状态,对于生产者和消费者来说是不可用的。
# 列出包含不同步副本的分区
kafka-topics.sh --bootstrap-server localhost:9092 --describe --under-replicated-partitions
1.7、修改或删除配置(–config)
覆盖已有的topic参数:
kafka-topics.sh --bootstrap-server zk_host:port --topic TEST --alter--configflush.messages=1
删除topic级别配置参数:
kafka-topics.sh --bootstrap-server zk_host:port --alter--topic TEST --delete-config flush.messages=1
2、消费者群组(kafka- consumer-groups.sh )
在 Kafka 里,有两个地方保存着消费者群组的信息。对于旧版本的消费者来说,它们的信 息保存在 Zookeeper 上;对于新版本的消费者来说,它们的信息保存在 broker 上。kafka- consumer-groups.sh 工具可以用于列出上述两种消费者群组。它也可以用于删除消费者群 组和偏移量信息,不过这个功能仅限于旧版本的消费者群组(信息保存在 Zookeeper 上)。 在对旧版本的消费者群组进行操作时,需要通过 --zookeeper 参数指定 Zookeeper 的地址; 在对新版本的消费者群组进行操作时,则需要使用 --bootstrap-server 参数指定 broker 的 主机名和端口。
语法:
kafka-consumer-groups.sh [-h][--bootstrap-server <server to use>][--command-config <command configuration property file>][--group <consumer-group>][--new-consumer | --zookeeper][--describe][--delete][--reset-offsets][--reset-offsets-by-duration <duration controlling how far back to reset>][--reset-offsets-by-topic <topic to reset>][--reset-offsets-by-times][--all-topics][--topic <topic>][--exclude-internal][--dry-run]
- -–bootstrap-server:Kafka集群的地址,多个地址使用逗号分隔。
- -–command-config:kafka的安全认证配置文件路径。
- -–group:指定要操作的消费组。
- -–describe:列出消费组的详情。
- -–delete:删除消费组。
- -–reset-offsets:重置消费组的偏移量。
- -–reset-offsets-by-duration:指定重置的时间(从现在往前)。
- -–reset-offsets-by-topic:指定重置的topic和partition。
- -–reset-offsets-by-times:指定重置的时间点。
- -–new-consumer:使用新消费者API。
- -–zookeeper:使用旧的Zookeeper API。
- -–all-topics:列出所有topic的所有消费组。
- -–topic:指定要操作的topic。
- -–exclude-internal:不列出.kafka/*的topic。
- -–dry-run:仅输出要执行的操作,不实际运行。
2.1、列出群组(–list)
在使用旧版本的消费者客户端时,可以使用 --zookeeper 和 --list 参数列出消费者群 组;在使用新版本的消费者客户端时,则要使用 --bootstrap-server、–list 参数。
示例:列出旧版本的消费者群组。
kafka-consumer-groups.sh --zookeeper localhost:2181/kafka-cluster --list
示例:列出新版本的消费者群组。
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
2.2、获取群组详细信息(–describe)
使用 --describe,并通过 --group 指定特定的群组, 就可以获取该群组的详细信息。它会列出群组里所有主题的信息和每个分区的偏移量。
示例:获取消费者群组testGroup的详细信息
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe--group testGroup

字段描述GROUP消费者群组的名字TOPIC正在被读取的主题名字PARTITION正在被读取的分区 IDCURRENT-OFFSET消费者群组最近提交的偏移量,也就是消费者在分区里读取的当前位置LOG-END-OFFSET当前高水位偏移量,也就是最近一个被读取消息的偏移量,同时也是最近一个被提 交到集群的偏移量LAG消费者的 CURRENT-OFFSET 和 broker 的 LOG-END-OFFSET 之间的差距CONSUMER-ID消费者群组里正在读取该分区的消费者。这是一个消费者的 IDHOST消费者主机IP
2.3、偏移量管理(–reset-offsets)
能够执行成功的一个前提是 消费组这会是不可用状态;
- 执行模式: –dry-run:这个参数表示预执行,会打印出来将要处理的结果; –excute:真正执行;
- 执行范围: –group:指定具体的消费组; –all-group:指定所有的消费组;
- 重置模式: 相关重置Offset的模式;
参数描述示例--to-earliest重置offset到最开始的offset(未被删除的最早的offset)--to-current直接重置offset到当前的offset,也就是LOE--to-latest重置到最后一个offset--to-detetime重置到指定时间的offset;格式为:YYYY-MM-DDTHH:mm:SS.sss--to-datetime “2021-6-26T00:00:00.000”--to-offset重置到指定的offset,但是通常情况下,匹配到多个分区,这里是将匹配到的所有分区都重置到这一个值;如果目标最大offset < to-offset,这个时候重置为目标最大offset;如果目标最小offset > to-offset,则重置为最小;--to-offset 300--shift-by按照偏移量增加或者减少多少个offsete;正数向前增加、负数向后退--shift-by 100、--shift-by -100--from-file根据CVS文档来重置
示例:将消费组”testGroup”的”testTopic”上的所有分区的偏移量为300。
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --reset-offsets --topic testTopic --to-offset 300--execute
示例:将消费组”testGroup”的”testTopic”上的所有分区的偏移量向前移动100。
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --reset-offsets --topic testTopic --shift-by -100--execute
示例:通过cvs文档配置消费组”testGroup”的”testTopic”上的所有分区的偏移量为10000
offsets.cvs:
格式为:
Topic,分区号,偏移量
testTopic,0,10000
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --reset-offsets --from-file offsets.cvs --execute
2.4、删除偏移量(–delete-offsets)
能够执行成功的一个前提是 消费组这会是不可用状态;
偏移量被删除了之后,Consumer Group下次启动的时候,会从头消费;
示例:将消费组”testGroup”的”testTopic”上的所有分区的偏移量删除
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --topic testTopic --delete-offsets
2.4、查询消费者成员信息(–members)
示例:
kafka-consumer-groups.sh --describe --all-groups --bootstrap-server localhost:9092 --members

2.5、查询消费者状态信息(–state)
示例:
kafka-consumer-groups.sh --describe --all-groups --bootstrap-server localhost:9092 --state

2.6、删除消费组(–delete)
想要删除消费组前提是这个消费组的所有客户端都停止消费/不在线才能够成功删除;否则会报下面异常
示例:删除指定消费组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete--group testGroup
示例:删除所有消费组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --all-groups
3、动态配置变更(kafka-configs.sh)
kafka-configs.sh可以在集群处于运行状态时覆盖主题配置和客户端的配额参数。这样就可以 为特定的主题和客户端指定配置参数。一旦设置完毕,它们就成为集群的永久配置。
参数说明--zookeeper使用zk配置操作集群,支持三种配置类型topics、clients、users--bootstrap使用broker连接方式、仅支持一种配置类型brokers,格式为brokerIp01:port,brokerIp02:port,…--command-config包含要传递给Admin Client的配置的属性文件。仅与--bootstrap-server选项一起使用,用于描述和更改代理配置--alter指定需要修改配置--describe列举出指定的实体配置--entity-type实体配置类型(topics、users、brokers)--entity-nameentity名称(topicName、clientId、userId、brokerId)--add-config要添加的键值对配置。方括号可用于对包含逗号的值进行分组:‘k1=v1,k2=[v1,v2,v2],k3=v3’--entity-defaultclients/users/brokers的默认entity-name,生产zk相对路径的节点<default>--delete-config指定配置项删除’k1,k2’--force禁止控制台提示
3.1、Brokers类型动态配置(–entity-type brokers)


配置brokers只能指定–bootstrap-server,zk不支持。
3.1.1、增加配置项(–add-config)
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-default --add-config 'max.connections.per.ip=200,max.connections.per.ip.overrides=[ip1:100,ip2:120]'
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-name $brokerId --add-config 'max.connections.per.ip=200,max.connections.per.ip.overrides=[ip1:100]'
3.1.2、删除配置项(–delete-config)
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-default --delete-config 'max.connections.per.ip,max.connections.per.ip.overrides'
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type brokers --entity-name $brokerId --delete-config 'max.connections.per.ip,max.connections.per.ip.overrides'
3.1.3、列出配置项详情(–describe)
kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-default --describe
kafka-configs.sh --bootstrap-server localhost:9092 --entity-type brokers --entity-name $brokerId--describe
3.2、Topics类型动态配置(–entity-type topics)
Topics类型配置是Brokers类型配置的子集,Brokers类型包含Topics类型所有配置,brokers只是在topics配置项前加了前缀。


3.2.1、增加配置项(–add-config)
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name testTopic --add-config 'max.message.bytes=50000000,flush.messages=50000,flush.ms=5000'
3.2.2、删除配置项(–delete-config)
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name testTopic --delete-config 'max.message.bytes,flush.messages,flush.ms'
3.2.3、列出配置项(–describe)
kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name testTopic --describe
3.2.4、示例
示例:将主题testTopic的消息保留时间设为一个小时(3600000ms)
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name testTopic --add-config 'retention.ms=3600000'
示例:删除retention.ms配置
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name testTopic --delete-config 'retention.ms'
3.3、Clients类型动态配置(–entity-type clients)
对于 Kafka 客户端来说,只能覆盖生产者配额和消费者配额参数。这两个配额都以字节每 秒为单位,表示客户端在每个 broker 上的生产速率或消费速率。也就是说,如果集群里有 5 个 broker,生产者的配额是 10MB/s,那么它可以以 10MB/s 的速率在单个 broker 上生成 数据,总共的速率可以达到 50MB/s。
配置项描述producer_bytes_rate单个生产者每秒种可以往单个broker上生成的消息字节数consumer_bytes_rate单个消费者每秒钟可以从单个broker读取的消息字节数
3.3.1、新增配置项(–add-config)
示例:broker内所有clientId累加总和最大producer生产速率为20MB/sec
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type clients --entity-default --add-config 'producer_byte_rate=20971520'
示例:broker内clientA的最大producer生产速率为20MB/sec
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type clients --entity-name clientA --add-config 'producer_byte_rate=20971520'
3.3.2、删除配置项(–delete-config)
示例:删除broker内所有clientId的配置项producer_byte_rate
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type clients --entity-default --delete-config 'producer_byte_rate'
3.3.3、列出配置项(–describe)
示例:列出broker内所有clientId的配置
kafka-configs.sh --bootstrap-server localhost:9092 --entity-type clients --entity-default --describe
4、首领选举(kafka-leader-election)
参数:
参数描述例子--bootstrap-server 指定kafka服务指定连接到的kafka服务--bootstrap-server localhost:9092--topic指定Topic,此参数跟--all-topic-partitions和path-to-json-file 三者互斥--partition指定分区,跟--topic搭配使用--election-type两个选举策略(PREFERRED: 优先副本选举,如果第一个副本不在线的话会失败;UNCLEAN: 策略)--all-topic-partitions所有topic所有分区执行Leader重选举; 此参数跟--topic和path-to-json-file 三者互斥--path-to-json-file配置文件批量选举,此参数跟--topic和all-topic-partitions 三者互斥
4.1、指定Topic指定分区用重新PREFERRED:优先副本策略 进行Leader重选举
示例:指定testTopic主题的0分区重新选举
kafka-leader-election.sh --bootstrap-server localhost:9092 --topic testTopic --election-type PREFERRED --partition0
4.2、所有Topic所有分区用重新PREFERRED:优先副本策略 进行Leader重选举
示例:所有Topic重新选举
kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --all-topic-partitions
4.3、设置配置文件批量指定topic和分区进行Leader重选举
配置leader-election.json文件:
{"partitions":[{"topic":"testTopic1","partition":1},{"topic":"testTopic2","partition":2}]}
kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred --path-to-json-file config/leader-election.json
5、分区分配(kafka-reassign-partitions.sh)
Kafka系统提供了一个分区重新分配工具(kafka-reassign-partitions.sh),该工具可用于在Broker之间迁移分区。理想情况下,将确保所有Broker的数据和分区均匀分配。分区重新分配工具无法自动分析Kafka群集中的数据分布并迁移分区以实现均匀的负载均衡。因此,管理员在操作的时候,必须弄清楚应该迁移哪些Topic或分区。
5.1、分区迁移
分区重新分配工具可以在3种互斥模式下运行:
--generate:在此模式下,给定Topic列表和Broker列表,该工具会生成候选重新分配,以将指定Topic的所有分区迁移到新Broker中。此选项仅提供了一种方便的方法,可在给定Topic和目标Broker列表的情况下生成分区重新分配计划。--execute:在此模式下,该工具将根据用户提供的重新分配计划启动分区的重新分配。 (使用–reassignment-json-file选项)。由管理员手动制定自定义重新分配计划,也可以使用–generate选项提供。--verify:在此模式下,该工具将验证最后一次–execute期间列出的所有分区的重新分配状态。状态可以有成功、失败或正在进行等状态。
使用该工具需要经过三个步骤:
- 第一步,根据 broker 清单和主题清单生成一组迁移步骤;
- 第二步,执行这些迁移步骤。
- 第三个步骤是可选的,也就是可以使用生成的迁移步骤验证分区重分配的进度和完成情况。
案例:原两台机器,broker.id分别为0和2。新添加一条机器,broker.id为3。确定要迁移的topic,topic有两个分区,partition:0分区存储在0,2broker上;先要将partiiton:0分区迁移到2,3上
步骤一:为了生成迁移步骤,需要先创建一个包含了主题清单的 JSON 文件topics-to-move.json,文件格式如下(目前的版本号都是 1)
{"topics":[{"topic":"test2"}],"version":1}
执行generate:
kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --topics-to-move-json-file topics-to-move.json --broker-list "2,3"--generate
"2,3"为目标broker.id,填写的个数不能小于副本数量。运行结果(生产两段脚本:当期分区副本分配和建议副本分配配置):
步骤二:这个时候,分区操作还没有开始,它只是告诉你当前分区副本配置和建议的分区副本配置。应该保存当前分区副本配置,以防您想要回滚到它。建议的分区副本配置应该保存在一个json文件(例如topic-reassignment.json)
如对任务编写熟悉:可以直接跳过第一步;手动编写建议的分区副本配置,执行execute:
kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file topic-reassignment.json --execute
该命令会将指定分区的副本重新分配到新的 broker 上。集群控制器通过为每个分区添加 新副本实现重新分配(增加复制系数)。新的副本将从分区的首领那里复制所有数据。根 据分区大小的不同,复制过程可能需要花一些时间,因为数据是通过网络复制到新副本上 的。在复制完成之后,控制器将旧副本从副本清单里移除(恢复到原先的复制系数)。
第三步:在重分配进行过程中或者完成之后,可以使用 kafka-reassign-partitions.sh 工具验证重分配 的状态。它可以显示重分配的进度、已经完成重分配的分区以及错误信息(如果有的话)。 为了做到这一点,需要在执行过程中使用 JSON 对象文件。
kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file topic-reassignment.json --verify
5.2、修改复制系数
分区重分配工具提供了一些特性,用于改变分区的复制系数,这些特性并没有在文档里 说明。如果在创建分区时指定了错误的复制系数(比如在创建主题时没有足够多可用的 broker),那么就有必要修改它们。这可以通过创建一个 JSON 对象来完成,该对象使用分 区重新分配的执行步骤中使用的格式,显式指定分区所需的副本数量。集群将完成重分配 过程,并使用新的复制系数。
例如,假设主题 my-topic 有一个分区,该分区的复制系数为 1。
{"partitions":[{"topic":"my-topic","partition":0,"replicas":[1]}],"version":1}
在分区重新分配的执行步骤中使用以下 JSON 可以将复制系数改为 2。
{"partitions":[{"topic":"my-topic","partition":0,"replicas":[1,2]}],"version":1}
也可以通过类似的方式减小分区的复制系数。
6、删除消息(kafka-delete-records.sh)
示例:删除testTopic的0分区的消息删除至offset为1024
先配置json文件offset-json-file.json
{"partitions":[{"topic":"testTopic","partition":0,"offset":1024}],"version":1}
执行命令:
kafka-delete-records.sh --bootstrap-server localhost:9092 --offset-json-file config/offset-json-file.json
从最开始的地方删除消息到 1024的offset; 是从最前面开始删除的。
7、查看Broker磁盘信息(kafka-log-dirs.sh)
--bootstrap-server:kafka地址--broker-list:要查询的broker地址列表,broker之间逗号隔开,不配置该命令则查询所有broker--topic-list:指定查询的topic列表,逗号隔开--command-config:配置Admin Client--describe:显示详情
示例:查询指定topic磁盘信息 --topic-list testTopic
kafka-log-dirs.sh --bootstrap-server localhost:9092 --describe --topic-list testTopic
结果:
{"version":1,"brokers":[{"broker":0,"logDirs":[{"logDir":"/tmp/kafka-logs","error":null,"partitions":[{"partition":"testTopic-0","size":27090690,"offsetLag":0,"isFuture":false}]}]}]}
示例:查询指定Broker磁盘信息
kafka-log-dirs.sh --bootstrap-server localhost:9092 --describe --topic-list testTopic --broker-list 0
8、查看日志文件(kafka-dump-log.sh)
参数描述例子--deep-iteration--files <String: file1, file2, ...>必需; 读取的日志文件--files 0000009000.log--key-decoder-class如果设置,则用于反序列化键。这类应实现kafka.serializer。解码器特性。自定义jar应该是在kafka/libs目录中提供--max-message-size最大的数据量,默认:5242880--offsets-decoder如果设置了,日志数据将被解析为来自__consumer_offsets主题的偏移量数据。--print-data-log打印内容--transaction-log-decoder如果设置,日志数据将被解析为来自__transaction_state主题的事务元数据--value-decoder-class [String]如果已设置,则用于反序列化消息。这个类应该实现kafka。序列化程序。解码器特性。自定义jar应该在kafka/libs目录中可用。(默认值:kafka.serializer.StringDecoder)--verify-index-only如果设置了,只需验证索引日志,而不打印其内容。
8.1、查询Log文件
kafka-dump-log.sh --files /tmp/kafka-logs/testTopic-0/00000000000000000000.log
下面每条消息都表示的是batchRecord
baseOffset为起始位置,lastOffset为终止位置,count为本次消息数量。
baseOffset: 1044628 lastOffset: 1044676 count: 49 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 27083143 CreateTime: 1691300649226 size: 1139 magic: 2 compresscodec: none crc: 2048338167 isvalid: true
baseOffset: 1044677 lastOffset: 1044773 count: 97 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 27084282 CreateTime: 1691300649228 size: 2228 magic: 2 compresscodec: none crc: 1293136921 isvalid: true
8.2、查询Log文件具体信息(–print-data-log)
kafka-dump-log.sh --files /tmp/kafka-logs/testTopic-0/00000000000000000000.log --print-data-log
下面为每条消息的具体信息:
| offset: 399407 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 0 payload: Message_399408
| offset: 399408 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 1 payload: Message_399409
| offset: 399409 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 2 payload: Message_399410
| offset: 399410 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 3 payload: Message_399411
| offset: 399411 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 4 payload: Message_399412
| offset: 399412 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 5 payload: Message_399413
| offset: 399413 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 6 payload: Message_399414
| offset: 399414 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 7 payload: Message_399415
| offset: 399415 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 8 payload: Message_399416
| offset: 399416 CreateTime: 1691292274339 keySize: 4 valueSize: 14 sequence: -1 headerKeys: [] key: 9 payload: Message_399417
8.3、查询index文件
kafka-dump-log.sh --files /tmp/kafka-logs/testTopic-0/00000000000000000000.index
offset为索引值,position为具体位置,可以看到大概每隔600条消息,就建立一个索引。配置项为log.index.size.max.bytes,来控制创建索引的大小;
offset: 972865 position: 25163202
offset: 973495 position: 25179579
offset: 974125 position: 25195956
offset: 974755 position: 25212333
offset: 975385 position: 25228710
offset: 976015 position: 25245087
offset: 976645 position: 25261464
offset: 977275 position: 25277841
8.4、查询timeindex文件
kafka-dump-log.sh --files /tmp/kafka-logs/testTopic-0/00000000000000000000.timeindex
timestamp: 1691292274425 offset: 475709
timestamp: 1691292274426 offset: 476947
timestamp: 1691292274427 offset: 478255
timestamp: 1691292274428 offset: 479543
timestamp: 1691292274429 offset: 480848
timestamp: 1691292274430 offset: 481767
timestamp: 1691292274431 offset: 483209
timestamp: 1691292274432 offset: 484869
timestamp: 1691292274433 offset: 486408
9、副本一致性验证(kafka-replica-verification.sh)
可以使用 kafka-replica-verification.sh 工具来验证集群分区副本的一致性。它会从指定分区 的副本上获取消息,并检查所有副本是否具有相同的消息。我们必须使用正则表达式将待 验证主题的名字传给它。如果不提供这个参数,它会验证所有的主题。除此之外,还需要 显式地提供 broker 的地址清单。
示例:对 broker 1 和 broker 2 上以 my- 开头的主题副本进行验证。
kafka-replica-verification.sh --broker-list kafka1.example.com:9092,kafka2.example.com:9092 --topic-white-list 'my-.*'
10、控制台消费者(kafka-console-consumer.sh)
kafka-console-consumer.sh 工具提供了一种从一个或多个主题上读取消息的方式。消息被打 印在标准输出上,消息之间以空行分隔。默认情况下,它会打印没有经过格式化的原始消 息字节(使用 DefaultFormatter)。它有很多可选参数,其中有一些基本的参数是必选的。
参数描述例子--group指定消费者所属组的ID--topic被消费的topic--partition指定分区 ;除非指定–offset,否则从分区结束(latest)开始消费--partition 0--offset执行消费的起始offset位置 ;默认值: latest; /latest /earliest /偏移量--offset 10--whitelist正则表达式匹配topic;--topic就不用指定了; 匹配到的所有topic都会消费; 当然用了这个参数,--partition --offset等就不能使用了--consumer-property将用户定义的属性以key=value的形式传递给使用者--consumer-property group.id=test-consumer-group--consumer.config消费者配置属性文件请注意,[consumer-property]优先于此配置--consumer.config config/consumer.properties--property初始化消息格式化程序的属性print.timestamp=true,false 、print.key=true,false 、print.value=true,false 、key.separator=<key.separator> 、line.separator=<line.separator>、key.deserializer=<key.deserializer>、value.deserializer=<value.deserializer>--from-beginning从存在的最早消息开始,而不是从最新消息开始,注意如果配置了客户端名称并且之前消费过,那就不会从头消费了--max-messages消费的最大数据量,若不指定,则持续消费下去--max-messages 100--skip-message-on-error如果处理消息时出错,请跳过它而不是暂停--isolation-level设置为read_committed以过滤掉未提交的事务性消息,设置为read_uncommitted以读取所有消息,默认值:read_uncommitted--formatter格式化器:
kafka.tools.DefaultMessageFormatter有一些非常有用的配置选项,这些选项可以通过--property 命令行参数传给它(print.timestamp:如果被设为 true,就会打印每个消息的时间戳。
print.key:如果被设为 true,除了打印消息的值之外,还会打印消息的键。
key.separator: 指定打印消息的键和消息的值所使用的分隔符。
line.separator: 指定消息之间的分隔符。
key.deserializer: 指定打印消息的键所使用的反序列化器类名。
value.deserializer: 指定打印消息的值所使用的反序列化器类名。
反序列化类必须实现 org.apache.kafka.common.serialization.Deserializer 接口,控制 台消费者会调用它们的 toString() 方法获取输出结果。一般来说,在使用 kafka_console_ consumer.sh 工具之前,需要通过环境变量 CLASSPATH 将这些实现类添加到类路径里。)
kafka.tools.LoggingMessageFormatter将消息输出到日志,而不是输出到标准的输出设备。日志级别为 INFO,并且包含了时 间戳、键和值。
kafka.tools.NoOpMessageFormatter读取消息但不打印消息。
kafka.tools.ChecksumMessageFormatter只打印消息的校验和。
10.1、新客户端从头消费(–from-beginning)
注意这里是新客户端,如果之前已经消费过了是不会从头消费的) 下面没有指定客户端名称,所以每次执行都是新客户端都会从头消费
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
10.2、正则表达式匹配topic进行消费(–whitelist)
示例:消费所有的test开头的topic,监听新的消费:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist'test.*'
示例:费所有的test开头的topic,并且从头消费:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --whitelist'test.*' --from-beginning
10.3、显示key进行消费(–property print.key=true)
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --propertyprint.key=true
10.4、指定分区消费(–partition)
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --partition0
10.5、定起始偏移量消费(–offset)
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --partition0--offset100
10.6、给客户端命名(–group)
注意给客户端命名之后,如果之前有过消费,那么–from-beginning 就不会再从头消费了
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --group test-group
10.7、添加客户端属性(–consumer-property)
这个参数也可以给客户端添加属性,但是注意 不能多个地方配置同一个属性,他们是互斥的;比如在下面的基础上还加上属性–group test-group 那肯定不行
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --consumer-property group.id=test-consumer-group
10.8、添加客户端属性(–consumer.config)
跟–consumer-property 一样的性质,都是添加客户端的属性,不过这里是指定一个文件,把属性写在文件里面, --consumer-property 的优先级大于 --consumer.config
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --consumer.config config/consumer.properties
10.9、读取偏移量主题(旧版本)
有时候,我们需要知道提交的消费者群组偏移量是多少,比如某个特定的群组是否在提交 偏移量,或者偏移量提交的频度。这个可以通过让控制台消费者读取一个特殊的内部主题 __consumer_offsets 来实现。所有消费者的偏移量都以消息的形式写到这个主题上。为了 解码这个主题的消息,需要使用 kafka.coordinator.GroupMetadataManager$OffsetsMessage Formatter 这个格式化器。
示例:从偏移量主题读取一个消息。
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic __consumer_offsets --formatter'kafka.coordinator.GroupMetadataManager$OffsetsMessageFormatter' --max-messages 10
11、控制台生产者(kafka-console-producer.sh)
与控制台消费者类似,kafka-console-producer.sh 工具可以用于向 Kafka 主题写入消息。默认情况下,该工具将命令行输入的每一行视为一个消息,消息的键和值以 Tab 字符分隔 (如果没有出现 Tab 字符,那么键就是 null)。
参数值类型说明有效值--bootstrap-serverString要连接的服务器必需(除非指定--broker-list)如:host1:prot1,host2:prot2--topicString(必需)接收消息的主题名称--batch-sizeInteger单个批处理中发送的消息数200(默认值)--compression-codecString压缩编解码器none、gzip(默认值)snappy、lz4、zstd--max-block-msLong在发送请求期间,生产者将阻止的最长时间60000(默认值)--max-memory-bytesLong生产者用来缓冲等待发送到服务器的总内存33554432(默认值)--max-partition-memory-bytesLong为分区分配的缓冲区大小16384--message-send-max-retriesInteger最大的重试发送次数3--metadata-expiry-msLong强制更新元数据的时间阈值(ms)300000--producer-propertyString将自定义属性传递给生成器的机制如:key=value--producer.configString生产者配置属性文件[--producer-property]优先于此配置 配置文件完整路径--propertyString自定义消息读取器parse.key=true/false key.separator=<key.separator>ignore.error=true/false--request-required-acksString生产者请求的确认方式0、1(默认值)、all--request-timeout-msInteger生产者请求的确认超时时间1500(默认值)--retry-backoff-msInteger生产者重试前,刷新元数据的等待时间阈值100(默认值)--socket-buffer-sizeIntegerTCP接收缓冲大小102400(默认值)--timeoutInteger消息排队异步等待处理的时间阈值1000(默认值)--sync同步发送消息--version显示 Kafka 版本不配合其他参数时,显示为本地Kafka版本--help打印帮助信息
11.1、生产无key消息
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testTopic --producer.config../config/producer.properties
11.2、生产有key消息(–property parse.key=true)
默认消息key与消息value间使用“Tab键”进行分隔,所以消息key以及value中切勿使用转义字符(\t):
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testTopic --producer.config../config/producer.properties --propertyparse.key=true
12、持续批量推送消息(kafka-verifiable-producer.sh)
该脚本可以生产测试数据发送到指定topic,并将数据已json格式打印到控制台。
- –topic:主题名称
- –broker-list:broker列表, HOST1:PORT1,HOST2:PORT2,…
- –max-messages:最大消息数量,默认-1,一直生产消息
- –throughput:设置吞吐量,默认-1
- –acks:指定分区中必须有多少个副本收到这条消息,才算消息发送成功,默认-1
- –producer.config:配置文件
- –message-create-time:设置消息创建的时间,时间戳
- –value-prefix:设置消息前缀
- –repeating-keys:key从0开始,每次递增1,直到指定的值,然后再从0开始
12.1、单次发送100条消息(–max-messages 100)
kafka-verifiable-producer.sh --bootstrap-server localhost:9092 --topic testTopic --max-messages 100
12.2、每秒发送最大吞吐量不超过10 (–throughput 10)
推送消息时的吞吐量,单位messages/sec。默认为-1,表示没有限制
kafka-verifiable-producer.sh --bootstrap-server localhost:9092 --topic testTopic --throughput10
12.3、发送的消息体带前缀(–value-prefix)
kafka-verifiable-producer.sh --bootstrap-server localhost:9092 --topic testTopic --value-prefix 666
注意 --value-prefix 666必须是整数,发送的消息体的格式是加上一个 点号. 例如: 666.
其他参数: --producer.config CONFIG_FILE 指定producer的配置文件 --acks ACKS 每次推送消息的ack值,默认是-1
13、持续批量拉取消息(kafka-verifiable-consumer.sh)
- –bootstrap-server:指定kafka服务 指定连接到的kafka服务;
- –topic:指定消费的topic
- –group-id:消费者id;不指定的话每次都是新的组id
- –group-instance-id:消费组实例ID,唯一值
- –max-messages:单次最大消费的消息数量
- –enable-autocommit:是否开启offset自动提交;默认为false
- –reset-policy:当以前没有消费记录时,选择要拉取offset的策略,可以是earliest, latest,none。默认是earliest
- –assignment-strategy:consumer分配分区策略,默认是org.apache.kafka.clients.consumer.RangeAssignor
- –consumer.config:指定consumer的配置文件
13.1、持续消费
新的groupId,默认从头消费:
kafka-verifiable-consumer.sh --bootstrap-server localhost:9092 --group-id test_consumer --topic testTopic
13.2、单次最大消费(–max-messages)
kafka-verifiable-consumer.sh --bootstrap-server localhost:9092 --group-id test_consumer --topic testTopic --max-messages 10
14、生产者压力测试(kafka-producer-perf-test.sh)
参数描述例子--topic指定消费的topic--num-records发送多少条消息--throughput每秒消息最大吞吐量--producer-props生产者配置, k1=v1,k2=v2--producer-props bootstrap.servers= localhost:9092,client.id=test_client--producer.config生产者配置文件--producer.config config/producer.propeties--print-metrics在test结束的时候打印监控信息,默认false--print-metrics true--transactional-id指定事务 ID,测试并发事务的性能时需要,只有在 --transaction-duration-ms > 0 时生效,默认值为 performance-producer-default-transactional-id--transaction-duration-ms指定事务持续的最长时间,超过这段时间后就会调用 commitTransaction 来提交事务,只有指定了 > 0 的值才会开启事务,默认值为 0--record-size一条消息的大小byte; 和 --payload-file 两个中必须指定一个,但不能同时指定--payload-file指定消息的来源文件,只支持 UTF-8 编码的文本文件,文件的消息分隔符通过 --payload-delimeter 指定,默认是用换行\nl来分割的,和 --record-size 两个中必须指定一个,但不能同时指定 ; 如果提供的消息--payload-delimeter如果通过 --payload-file 指定了从文件中获取消息内容,那么这个参数的意义是指定文件的消息分隔符,默认值为 \n,即文件的每一行视为一条消息;如果未指定--payload-file则此参数不生效;发送消息的时候是随机送文件里面选择消息发送的;
- 发送1024条消息 --num-records 100并且每条消息大小为1KB–record-size 1024 最大吞吐量每秒10000条–throughput 100
kafka-producer-perf-test.sh --topic testTopic --num-records 100--throughput100000 --producer-props bootstrap.servers=localhost:9092 --record-size 1024
2.用指定消息文件–payload-file 发送100条消息最大吞吐量每秒100条–throughput 100
先配置好消息文件batchmessage.txt:
1
2
3
4
5
6
7
8
9
0
然后执行命令 发送的消息会从batchmessage.txt里面随机选择; 注意这里我们没有用参数–payload-delimeter指定分隔符,默认分隔符是\n换行;
kafka-producer-perf-test.sh --topic testTopic --num-records 1024--throughput100 --producer-props bootstrap.servers=localhost:9092 --payload-file config/batchmessage.txt
15、消费者压力测试(kafka-consumer-perf-test.sh)
参数描述例子--bootstrap-server--consumer.config消费者配置文件--date-format结果打印出来的时间格式化默认:yyyy-MM-dd HH:mm:ss:SSS--fetch-size单次请求获取数据的大小默认1048576--topic指定消费的topic--from-latest--group消费组ID--hide-header如果设置了,则不打印header信息--messages需要消费的数量--num-fetch-threadsfeth 数据的线程数(废弃无效)默认:1--print-metrics结束的时候打印监控数据--show-detailed-stats如果设置,则按照--report_interval配置的方式报告每个报告间隔的统计信息--threads消费线程数;(废弃无效)默认 10--reporting-interval打印进度信息的时间间隔(以毫秒为单位)
消费100条消息 --messages 100
kafka-consumer-perf-test.sh -topic testTopic --bootstrap-server localhost:9092 --messages100
16、常用操作
16.1、查看 topic 指定分区 offset 的最大值或最小值
time 为 -1 时表示最大值,为 -2 时表示最小值
kafka-run-class.sh kafka.tools.GetOffsetShell --topic testTopic --time-1 --broker-list 127.0.0.1:9092 --partitions0
16.2、查询topic的offset的范围
查询offset最小值:
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic testTopic --time-2
查询offset最大值:
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic testTopic --time-1
16.3、重置消费者offset
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --reset-offsets --execute --to-offset NEW_OFFSET --topic testTopic
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group testGroup --reset-offsets --execute --to-earliest/--to-latest --topic testTopic
16.4、删除topic下的数据
kafka-topics.sh --bootstrap-server localhost:9092 --alter--topic testTopic --configcleanup.policy=delete
16.5、给指定TOPIC设置消息存储时间 – 针对数据量大,磁盘小的情况
查看某一个topic设置过期时间:
kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-name testTopic --entity-type topics
单独对某一个topic设置过期时间
kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-name testTopic --entity-type topics --add-config retention.ms=86400000
版权归原作者 吴声子夜歌 所有, 如有侵权,请联系我们删除。