
🍊 Java学习:Java从入门到精通总结
🍊 深入浅出RocketMQ设计思想:深入浅出RocketMQ设计思想
🍊 绝对不一样的职场干货:大厂最佳实践经验指南
📆 最近更新:2022年8月26日
🍊 个人简介:通信工程本硕💪、Java程序员🌕。做过科研paper,发过专利,优秀的程序员不应该只是CRUD
🍊 点赞 👍 收藏 ⭐留言 📝 都是我最大的动力!
作为一个消息中间件,消息存储的效率直接影响到消息存取的效率,
RocketMQ
的单机吞吐量达到10w级别也和其存储设计有关,文本就对其进行一些探索。
文章目录
RocketMQ整体存储架构
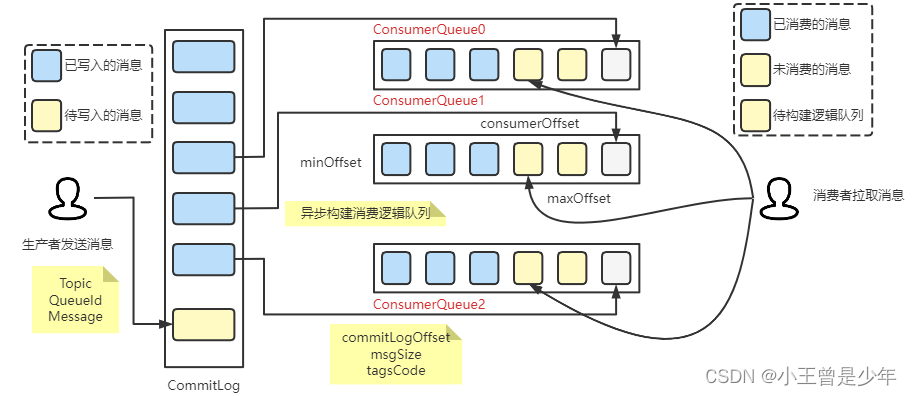
消息生产与消费消息互相隔离
Producer
发送的消息最终写入的是
CommitLog
文件,
Consumer
首先从
ConsumerQueue
里读取持久化消息的
offset
,消息大小、消息
tag
属性的
Hash
值,之后再从
CommitLog
中读取消息的真正内容
CommitLog文件采用混合型存储
所有
Topic
下的消息队列公用同一个
CommitLog
,并通过建立类似索引的方式来区分不同
Topic
下的不同
MessageQueue
的消息。
此外,只有异步线程通过
doDispatch
方法异步生成了
ConsumerQueue
里的元素后,
Consumer
才能进行消息的消费。
由此看来,只要消息写入到
CommitLog
之后,即使
ConsumerQueue
里的消息丢失了,也可以通过
CommitLog
来恢复。
顺序读写
发送消息时,
Producer
发送的消息是按照顺序写入
CommitLog
的;消费消息时,
Consumer
也是顺序从
ConsumerQueue
里读取消息的。
从
CommitLog文件中读取数据时是随机读取,根据消息在
CommitLog文件中的起始
offset来读取消息的内容
在
RocketMQ
集群的并发量很高的情况下,文件的随机IO开销还是很大的,
RocketMQ
会使用其他的手段来避免这个问题,将在后面分析~
总结一下,
RocketMQ
的存储架构设计的优缺点如下:
- 优点:
ConsumerQueue消息逻辑队列比较轻量级;串行访问磁盘避免了磁盘竞争,避免了因为队列个数的增大而导致IO等待时间增大 - 缺点:
CommitLog是随机读取;Consumer如果想要消费一条消息的话,需要先读ConsumerQueue,再读CommitLog,额外增加了一次开销
mmap内存映射技术
mmap
和
write/read
一样需要从
PageCache
中刷盘,但
mmap
可以直接将
PageCache
刷到硬盘上而不需要经过内核态,减少了1次数据复制的过程。
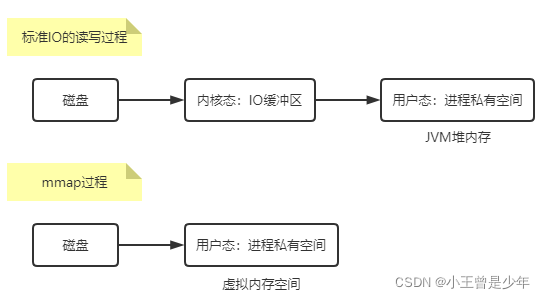
技术特点
mmap
的特点就是他不用像普通IO操作那样将文件中的数据先拷贝到操作系统的内核IO缓冲区,而是直接将客户端进程的私有地址空间中的一块区域和文件对象建立映射关系。
这样一来,程序就像直接从内存中完成对文件的读写操作一样。
当缺页中断发生时,直接将文件从磁盘拷贝到客户端的进程空间内只需要进行一次数据拷贝。对于大文件来说
MappedByteBuffer
分析
JDK中的源码如下:
publicabstractclassMappedByteBufferextendsByteBuffer{privatefinalFileDescriptor fd;// This should only be invoked by the DirectByteBuffer constructors//MappedByteBuffer(int mark,int pos,int lim,int cap,// package-privateFileDescriptor fd){super(mark, pos, lim, cap);this.fd = fd;}MappedByteBuffer(int mark,int pos,int lim,int cap){// package-privatesuper(mark, pos, lim, cap);this.fd =null;}privatevoidcheckMapped(){if(fd ==null)// Can only happen if a luser explicitly casts a direct byte bufferthrownewUnsupportedOperationException();}// Returns the distance (in bytes) of the buffer from the page aligned address// of the mapping. Computed each time to avoid storing in every direct buffer.privatelongmappingOffset(){int ps =Bits.pageSize();long offset = address % ps;return(offset >=0)? offset :(ps + offset);}privatelongmappingAddress(long mappingOffset){return address - mappingOffset;}privatelongmappingLength(long mappingOffset){return(long)capacity()+ mappingOffset;}publicfinalbooleanisLoaded(){checkMapped();if((address ==0)||(capacity()==0))returntrue;long offset =mappingOffset();long length =mappingLength(offset);returnisLoaded0(mappingAddress(offset), length,Bits.pageCount(length));}// not used, but a potential target for a store, see load() for details.privatestaticbyte unused;publicfinalMappedByteBufferload(){checkMapped();if((address ==0)||(capacity()==0))returnthis;long offset =mappingOffset();long length =mappingLength(offset);load0(mappingAddress(offset), length);// Read a byte from each page to bring it into memory. A checksum// is computed as we go along to prevent the compiler from otherwise// considering the loop as dead code.Unsafe unsafe =Unsafe.getUnsafe();int ps =Bits.pageSize();int count =Bits.pageCount(length);long a =mappingAddress(offset);byte x =0;for(int i=0; i<count; i++){
x ^= unsafe.getByte(a);
a += ps;}if(unused !=0)
unused = x;returnthis;}publicfinalMappedByteBufferforce(){checkMapped();if((address !=0)&&(capacity()!=0)){long offset =mappingOffset();force0(fd,mappingAddress(offset),mappingLength(offset));}returnthis;}privatenativebooleanisLoaded0(long address,long length,int pageCount);privatenativevoidload0(long address,long length);privatenativevoidforce0(FileDescriptor fd,long address,long length);}
可以看出,
MappedByteBuffer
继承了
ByteBuffer
,
ByteBuffer
内部维护了一个变量
address
表示逻辑地址。在建立映射关系时,使用
FileChannel
类下的
map()
方法把文件对象映射到虚拟内存
map()
方法底层调用了本地方法来完成文件的映射操作;
get()
方法是通过底层以 地址 + 偏移量 的方式来获取指定映射到内存中的数据。
使用
mmap
的注意点
1. 内存空间释放:
映射的内存空间不属于JVM的堆内存区域,所以不会被JVM的垃圾回收机制所回收,释放这部分空间需要通过系统调用
unmap()
实现,因为该方法是类私有方法,所以
RocketMQ
采用了反射机制调用
sum.misc.Cleaner#clean()
方法来释放空间。
2. 内存映射大小:
内存映射的大小收到操作系统虚拟内存的限制,一般一次只能映射2G以内的文件到用户态的的虚拟内存空间,因此
RocketMQ
的单个
CommitLog
文件大小就是1G
操作系统PageCache机制
Linux对文件的读写会先走
PageCache
,这是一块内存中的区域,这样一来在写入文件文件时就可以写入内存,可以加速写,后续操作系统会自动将数据刷到磁盘上。
1. 读取文件
如果读取文件时未命中
PageCache
,基于局部热点理论,操作系统会从物理磁盘上读取文件,除此之外还会读取相邻的数据文件。这样一来,读取已经被加载到
PageCache
里的文件时,速度就和访问内存差不多。
2. 写入文件
操作系统会先将文件写入到缓存内,之后会通过
pdflush
异步线程将缓存内的数据刷到磁盘上。
RocketMQ里的实现方式
写消息:
首先写入
PageCache
,并通过异步刷盘的方式将消息批量刷盘
读取消息:
大部分消息还是从
PageCache
里读取
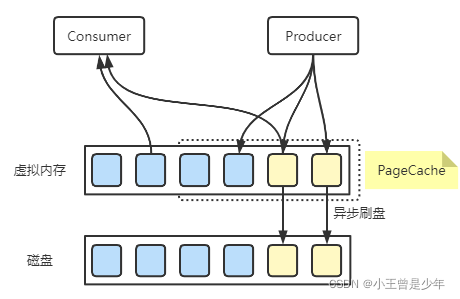
此外,
RocketMQ
还使用了多种优化技术,比如内存预分配、预热等,来尽可能减少
PageCache
可能带来的读写延迟问题。
当操作系统在进行内存回收、内存swap等操作时,
PageCache写入到磁盘的过程可能会遇到延迟
版权归原作者 小王曾是少年 所有, 如有侵权,请联系我们删除。