
学习目录
一、自定义UDTF函数
1.说明文档
A custom UDTF can be created by extending the GenericUDTF abstract class and then implementing the initialize, process, and possibly close methods. The initialize method is called by Hive to notify the UDTF the argument types to expect. The UDTF must then return an object inspector corresponding to the row objects that the UDTF will generate. Once initialize() has been called, Hive will give rows to the UDTF using the process() method. While in process(), the UDTF can produce and forward rows to other operators by calling forward(). Lastly, Hive will call the close() method when all the rows have passed to the UDTF.
读懂文档 首先我们需要知道object inspector和operators的基本概念
(1)operators
operators:即hive中的一条sql语句会被抽象为一个operators,一个operators由一些列的operator组成
operator:为一个特定的操作,完成整个数据处理的过程中的一个功能,类似于spark中的RDD算子,常见的operator有(select operator 用于选择字段、filter operator 用于过滤、join operator 用来做join操作的、group by 用来做分组操作的)
(2)object inspector
object inspector 对象检察器
- hive会将一条sql抽象为一个operators,即一些列operator;
- 数据会按照计划依次历经每个operator的处理;
- 数据在前后两个operator中间传递时,数据和类型是分离的,数据会保存在Java中的object对象当中,而数据的类型会被保存在object inspector 对象检察器中,object inspector还提供了用以解析Java object对象当中所保存数据的方法
文档说明
一个自定义的UDTF函数需要继承GenericUDTF抽象类,且实现initialize(), process(),close()(可选)方法。initialize()方法会被hive调用去通知UDTF函数将要接收到的参数类型。该UDTF必须返回一个与UDTF函数输出相对应的对象检查器。一旦initialize()方法被调用,hive将通过process()方法把一行行数据传给UDTF。在process()方法中,UDTF可以通过调用forward()方法将数据传给其他的operator。最后,当把所有的数据都处理完以后hive会调用close()方法。
initialize方法会被hive调用去通知UDTF函数将要接收到的参数类型
说明:其实就是hive调用initialize方法,把上一个operator返回的对象检查器 传给UDTF,因为object inspector 对象检查器中保存了数据的类型
UDTF必须返回一个与UDTF函数输出相对应的对象检查器
说明:主要目的是为了通知下一个operator即将接收到的数据类型
在process()方法中
说明:在process()方法中按照自己的逻辑,比如: 分离数据,将数据将一行分离多行,分离之后 再通过调用forward()方法将一行一行的数据传递给其他的operator
2.案例说明
接收的是一个json数组字符串,将数组的中每个json元素作为一行输出,具体如图所示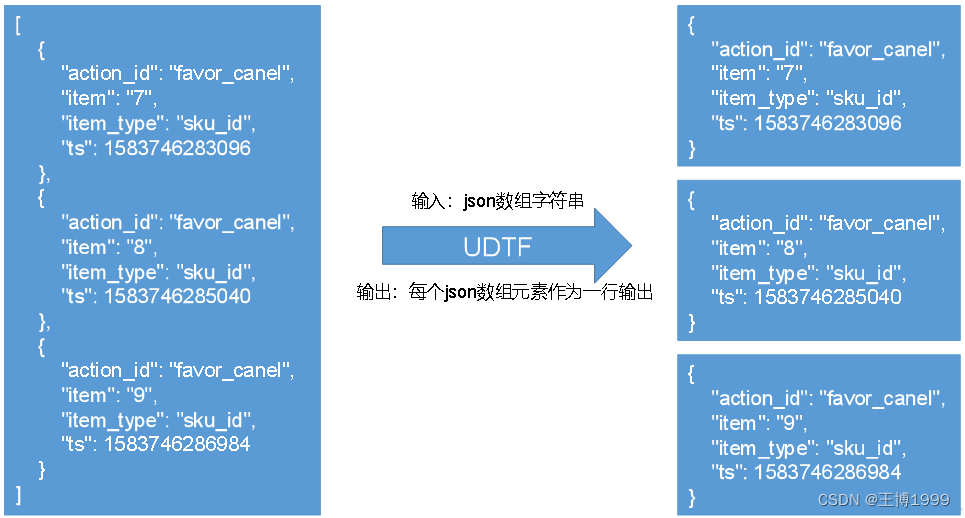
代码依赖
maven中添加hive依赖
<dependencies><!--添加hive依赖--><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency></dependencies>
代码
importorg.apache.hadoop.hive.ql.exec.UDFArgumentException;importorg.apache.hadoop.hive.ql.metadata.HiveException;importorg.apache.hadoop.hive.ql.udf.generic.GenericUDTF;importorg.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;importorg.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;importorg.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;importorg.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;importorg.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;importorg.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;importorg.json.JSONArray;importjava.util.ArrayList;/**
* @author wangbo
* @version 1.0
*/publicclassExplodeJSONArrayextendsGenericUDTF{privatePrimitiveObjectInspector inputOI;@Overridepublicvoidclose()throwsHiveException{}/*
解释说明:
该方法两个功能:
①hive会通过initialize方法通知UDTF函数接收到的数据类型,通过上一个operator传进来的对象检查器argOIs这个参数获取
②该方法返回一个对象检查器,通知下一个operator即将接收到的数据类型
输入参数类型:
ObjectInspector[]是一个对象检查器数组,其实就是上一个operator输出结果的对象检查器
说明:由于UDTF函数可能接收多个参数,所以为对象检查器数组,数组中的元素分别对应输入进来的参数
功能:
①可以通过传进来的对象检查器,校验UDTF函数输入参数的合法性,比如 输入参数的个数、类型等
②可以通过传进来的对象检查器,解析上一个operator传递过来的数据。但解析数据主要是在process方法中处理的
返回值类型:
StructObjectInspector是一个结构体对象检查器
说明:由于UDTF函数输出可能有多列,每一列对应着列名和类型,这个中数据结构对应着hive中的Struct结构体
*/@OverridepublicStructObjectInspectorinitialize(ObjectInspector[] argOIs)throwsUDFArgumentException{/**
* 校验参数
*///通过argOIs数组的长度校验参数的个数,因为数组的每个元素正好对应函数的每个参数//(1)校验接收参数的个数if(argOIs.length !=1){thrownewUDFArgumentException("explode_json_array函数只能接收1个参数");}//获取参数的对象检查器ObjectInspector argOI = argOIs[0];//(2)校验参数的类型,目标类型为String类型//1.判断是否为基本数据类型,argOI.getCategory()获取参数的数据类型if(argOI.getCategory()==ObjectInspector.Category.PRIMITIVE){thrownewUDFArgumentException("explode_json_array函数只能接收基本数据类型");}//2.判断是基本数据类型,将其强转为String数据类型PrimitiveObjectInspector primitiveOI =(PrimitiveObjectInspector) argOI;if(primitiveOI.getPrimitiveCategory()!=PrimitiveObjectInspector.PrimitiveCategory.STRING){thrownewUDFArgumentException("explode_json_array函数只能接收String数据类型");}
inputOI = primitiveOI;/**
* initialize方法返回值是StructObjectInspector结构体对象检查器,所以需要构建一个结构体对象检查器
* 结构体中包含UDTF函数输出的每一列的信息 列名、类型等
*/ArrayList<String> fieldNames =newArrayList<String>();ArrayList<ObjectInspector> fieldOIs =newArrayList<ObjectInspector>();
fieldNames.add("col1");//因为只有一列多有只需要添加一个列名//PrimitiveObjectInspectorFactory是基本数据类型的工厂类
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);//该列的数据类型为String类型//获取标准的结构体对象检查器,ObjectInspectorFactory是对象检查器的工厂类//该工厂类需要传两个ArrayList集合,//由于结构体是多列,第一个集合存放各个字段的列名//每个字段都有自己类型,第二个集合存放各个列的数据类型returnObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);}/**
*
* @param args
* @throws HiveException
* 前面提到过,两个operator之间传递数据时,数据和类型是分离的,数据保存在Object对象中,数据类型保存在ObjectInspector对象中
* 这里Object[] args为什么是数组,因为接收的参数可能是多个,而本次参数只有一个
*/@Overridepublicvoidprocess(Object[] args)throwsHiveException{//因为只有个,所以取第一个元素Object arg = args[0];//由于我们需要得到String类型的数据,需要将Object转为String类型//第一个参数是Object,第二个参数是PrimitiveObjectInspector,//说明:传给getString方法Object对象和与之对应的对象检查器,就可以从Object中解析所需要的数据StringJsonArrayString=PrimitiveObjectInspectorUtils.getString(arg, inputOI);//这个String就是传进来的 json数组的字符串/**
* 然后需要解析JsonArrayString,需要遍历数组中的每个元素,然后每个元素当作一行forward()出去
*///遍历则需要将上面的字符串解析为JSONArray数组,使用hive当中的json的解析工具类JSONArray jsonArray =newJSONArray(JsonArrayString);//遍历jsonArray,通过forward将数组元素发出for(int i =0; i < jsonArray.length(); i++){//jsonArray.getString(i)获取一个一个的json对象,只不过这个json对象放在了字符串中String string = jsonArray.getString(i);/**
* 注意:这里不能直接将string传入进去,因为任何一个operator输出的数据和输出的对象检查器必须得是一致才行
* 因为initialize方法输出的是StructObjectInspector结构体对象检查器,一个结构体中会有多列,每一列的数据可能会有一个值或多个值
* 所以装数据的时候需要用一个数组或者集合去装,即便结构体中只有一列也需要使用数组去装
*/String[] result ={string};forward(result);}}}
版权归原作者 王博1999 所有, 如有侵权,请联系我们删除。