
一、确认目标网页
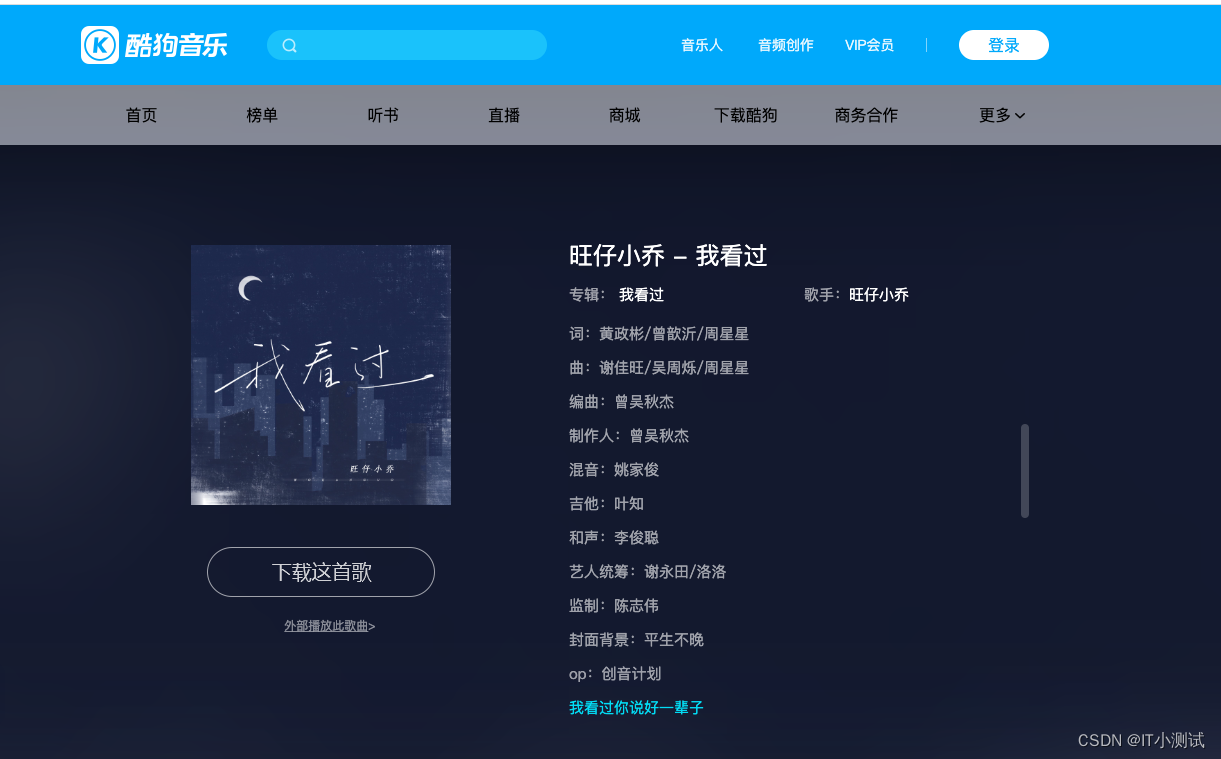
目标:爬取酷狗音乐
url='https://www.kugou.com/song/#911lljc3'
二、分析网页找到对应音乐链接
- 右键-->检查
- 进入网络,查看所有请求,事先先清空历史数据 1.
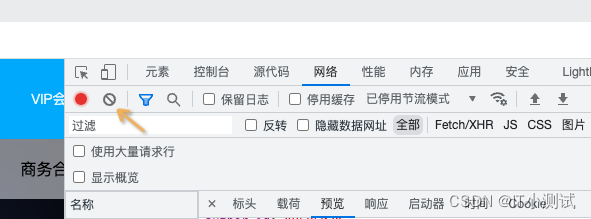
- 点击刷新,重新进入页面
- 找到index请求,在预览中可以看到 > 1. play_backup_url:"https://webfs.tx.kugou.com/202308251554/97c6fef48119300dd2a238ee8025c521/v2/409ebc56ea4ba76e58d8c89af8d03b6a/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3"> 2. play_url:"https://webfs.hw.kugou.com/202308251554/86bc88ad8da8c89302286567ea92bf94/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3"1.

- 然后再 标头 和 载荷 中拿到对应url和请求参数 > 1.
 > 2. 请求网址: https://wwwapi.kugou.com/yy/index.phpr=play/getdata&callback=jQuery1910009914641215163833_1692950107734&dfid=3exUvM3tv8Ms22pf5b2n00JB&appid=1014&mid=a1dd2b6ab4362156489644e5687fc1e4&platid=4&encode_album_audio_id=911lljc3&_=1692950107735> 3.
> 2. 请求网址: https://wwwapi.kugou.com/yy/index.phpr=play/getdata&callback=jQuery1910009914641215163833_1692950107734&dfid=3exUvM3tv8Ms22pf5b2n00JB&appid=1014&mid=a1dd2b6ab4362156489644e5687fc1e4&platid=4&encode_album_audio_id=911lljc3&_=1692950107735> 3. 
- 一步一步简化url 1. 直接复制请求网址请求: 1. https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery1910009914641215163833_1692950107734&dfid=3exUvM3tv8Ms22pf5b2n00JB&appid=1014&mid=a1dd2b6ab4362156489644e5687fc1e4&platid=4&encode_album_audio_id=911lljc3&_=16929501077352. 减少&_=1692950107735===>发现可以 1. https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery1910009914641215163833_1692950107734&dfid=3exUvM3tv8Ms22pf5b2n00JB&appid=1014&mid=a1dd2b6ab4362156489644e5687fc1e4&platid=4&encode_album_audio_id=911lljc3
.................
3. 最后简化成:
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery1910009914641215163833_1692950107734&encode_album_audio_id=911lljc3
三、框架封装
1、封装获取音乐函数
1.1 请求参数
data = {
'r': 'play/getdata',
'callback':'jQuery1910009914641215163833_1692950107734',
'encode_album_audio_id': '911lljc3'
}
其中:callback参数 1692950107734 是一个时间计时 拼接而成,可以对应time库里面的.time方法。由此可以自己创造一个时间计时(代表着访问时间)
print(time.time()*1000)
输出:1692953156733.728
# 通过 match.floor()方法向下取整
print(math.floor(time.time()*1000))
输出:1692953156733
最终拼接拿到的请求参数为:
data = {
'r': 'play/getdata',
'callback':'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)),
'encode_album_audio_id': '911lljc3'
}
1.2 请求头

dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4;kg_dfid=3exUvM3tv8Ms22pf5b2n00JB;kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e;Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=162943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
2、封装音乐下载函数
# 封装请求获取返回的文本
def get_music():
# 域名
url = 'https://wwwapi.kugou.com/yy/index.php'
# 通过简化后的网址得到的请求参数:
data = {
'r': 'play/getdata',
'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)),
'encode_album_audio_id': '911lljc3'
}
dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4; kg_dfid=3exUvM3tv8Ms22pf5b2n00JB; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1692943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
html_music = requests.get(url=url,params=data,headers=dic_headers)
print(html_music.text)
if __name__ == '__main__':
a=get_music()
输出结果与简化网页请求时候的一样
jQuery19108922952455208721_1692953502918({"status":1,"err_code":0,"data":{"hash":"409EBC56EA4BA76E58D8C89AF8D03B6A","timelength":167732,"filesize":2684376,"audio_name":"\u65fa\u4ed4\u5c0f\u4e54 - \u6211\u770b\u8fc7","have_album":1,"album_name":"\u6211\u770b\u8fc7","album_id":"77435914","img":"http://imge.kugou.com/stdmusic/20230821/20230821175541814897.jpg","have_mv":0,"video_id":0,"author_name":"\u65fa\u4ed4\u5c0f\u4e54","song_name":"\u6211\u770b\u8fc7","lyrics":"\ufeff[id:$00000000]\r\n[ar:\u65fa\u4ed4\u5c0f\u4e54]\r\n[ti:\u6211\u770b\u8fc7]\r\n[by:]\r\n[hash:409ebc56ea4ba76e58d8c89af8d03b6a]\r\n[al:]\r\n[sign:]\r\n[qq:]\r\n[total:167805]\r\n[offset:0]\r\n[00:00.00]\u6211\u770b\u8fc7\r\n[00:00.05]\u6f14\u5531\uff1a\u65fa\u4ed4\u5c0f\u4e54\r\n[00:00.17]\u539f\u5531\uff1a\u5468\u661f\u661f\r\n[00:00.27]\u8bcd\uff1a\u9ec4\u653f\u5f6c/\u66fe\u6b46\u6c82/\u5468\u661f\u661f\r\n[00:00.50]\u66f2\uff1a\u8c22\u4f73\u65fa/\u5434\u5468\u70c1/\u5468\u661f\u661f\r\n[00:00.73]\u7f16\u66f2\uff1a\u66fe\u5434\u79cb\u6770\r\n[00:00.85]\u5236\u4f5c\u4eba\uff1a\u66fe\u5434\u79cb\u6770\r\n[00:00.99]\u6df7\u97f3\uff1a\u59da\u5bb6\u4fca\r\n[00:01.10]\u5409\u4ed6\uff1a\u53f6\u77e5\r\n[00:01.18]\u548c\u58f0\uff1a\u674e\u4fca\u806a\r\n[00:01.29]\u827a\u4eba\u7edf\u7b79\uff1a\u8c22\u6c38\u7530/\u6d1b\u6d1b\r\n[00:01.48]\u76d1\u5236\uff1a\u9648\u5fd7\u4f1f\r\n[00:01.59]\u5c01\u9762\u80cc\u666f\uff1a\u5e73\u751f\u4e0d\u665a\r\n[00:01.74]op\uff1a\u521b\u97f3\u8ba1\u5212\r\n[00:01.87]\u6211\u770b\u8fc7\u4f60\u8bf4\u597d\u4e00\u8f88\u5b50\r\n[00:05.70]\u6211\u770b\u8fc7\u4f60\u7684\u65e0\u5fae\u4e0d\u81f3\r\n[00:18.03]\u4f60\u7684\u56de\u7b54\u90fd\u72b9\u8c6b\u4e86\u4e00\u4e0b\r\n[00:25.73]\u5728\u6211\u9762\u524d\u600e\u4e48\u5f00\u59cb\u5bb3\u6015\u8bf4\u9519\u8bdd\r\n[00:33.54]\u4f60\u5728\u773a\u671b\u7a97\u5916\u65e0\u5173\u7684\u666f\u8c61\r\n[00:40.74]\u4fdd\u6301\u6c89\u9ed8\u548c\u4f60\u7684\u4f18\u96c5\r\n[00:48.39]\u60f3\u966a\u4f60\u5047\u88c5\u6ca1\u4e8b\r\n[00:52.33]\u5929\u771f\u628a\u5206\u5f00\u5ef6\u8fdf\r\n[00:56.22]\u73b0\u5b9e\u5374\u6bd4\u6211\u4eec\u8bda\u5b9e\r\n[01:03.96]\u6211\u770b\u8fc7\u4f60\u8bf4\u597d\u4e00\u8f88\u5b50\r\n[01:07.68]\u6211\u770b\u8fc7\u4f60\u7684\u65e0\u5fae\u4e0d\u81f3\r\n[01:11.54]\u6211\u770b\u8fc7\u4f60\u8bf4\u60f3\u8981\u65f6\u95f4\u505c\u6b62\r\n[01:15.62]\u62c9\u7740\u6211\u7684\u624b\u558a\u6211\u540d\u5b57\r\n[01:19.34]\u6211\u770b\u8fc7\u4f60\u8bf4\u8c0e\u7684\u65b9\u5f0f\r\n[01:23.14]\u6211\u770b\u8fc7\u7231\u60c5\u81ea\u7136\u53d8\u8d28\r\n[01:27.05]\u5c31\u7b97\u9519\u8fc7\u8fd9\u6837\u5230\u6b64\u4e3a\u6b62\r\n[01:34.76]\u81f3\u5c11\u6211\u770b\u8fc7\u4f60\u7231\u6211\u7684\u6837\u5b50\r\n[01:40.55]\u6c89\u9ed8\u7a7a\u6c14\u6233\u7834\u4f60\u7684\u5fc3\u4e8b\r\n[01:44.47]\u4f60\u96be\u8fc7\u4f24\u5fc3\u53c8\u6709\u51e0\u6b21\r\n[01:48.37]\u4f60\u8138\u4e0a\u7684\u964c\u751f\u8868\u60c5\r\n[01:50.19]\u662f\u4f60\u7ed9\u7684\u8be0\u91ca\r\n[01:54.21]\u6211\u770b\u7740\u4f60\u98d8\u5ffd\u7684\u5fc3\u601d\r\n[01:58.03]\u4e5f\u770b\u89c1\u6211\u65e0\u8c13\u7684\u575a\u6301\r\n[02:01.83]\u4eb2\u7231\u7684\u4e0d\u8981\u518d\u8bf4\u4f60\u8fd8\u7231\u6211\r\n[02:05.78]\u56e0\u4e3a\u770b\u8fc7\u4f60\u7231\u6211\u7684\u6837\u5b50\r\n[02:09.62]\u6211\u770b\u8fc7\u7684\u6700\u7f8e\u7684\u843d\u65e5\r\n[02:13.45]\u662f\u4f60\u966a\u6211\u770b\u6d77\u7684\u6837\u5b50\r\n[02:17.37]\u5c31\u7b97\u9519\u8fc7\u8fd9\u6837\u5230\u6b64\u4e3a\u6b62\r\n[02:25.09]\u81f3\u5c11\u6211\u770b\u8fc7\u4f60\u7231\u6211\u7684\u6837\u5b50\r\n","author_id":"958503","privilege":8,"privilege2":"1000","play_url":"https://webfs.hw.kugou.com/202308251647/689118ce57eb8f3edd6b7e76464587a0/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3","authors":[{"author_id":"958503","author_name":"\u65fa\u4ed4\u5c0f\u4e54","is_publish":"1","sizable_avatar":"http://singerimg.kugou.com/uploadpic/softhead/{size}/20230621/20230621153031153.jpg","e_author_id":"T817KABBB5C71","avatar":"http://singerimg.kugou.com/uploadpic/softhead/400/20230621/20230621153031153.jpg"}],"is_free_part":0,"bitrate":128,"recommend_album_id":77435914,"store_type":"audio","album_audio_id":545949847,"is_publish":1,"e_author_id":"T817KABBB5C71","audio_id":"272898223","has_privilege":true,"play_backup_url":"https://webfs.tx.kugou.com/202308251647/7a9190b23578365621122b7f7389b9f4/v2/409ebc56ea4ba76e58d8c89af8d03b6a/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3","small_library_song":1,"encode_album_id":"1a3pxm66","encode_album_audio_id":"911lljc3","e_video_id":"0df"}});
编写清洗数据语句
使用字符串index方法,找到对应位置,然后通过切片形式拿到数据。最后把json字符串转为json对象。
start = html_music.text.index('{')
end = html_music.text.index('})') + 1
json_data = json.loads(html_music.text[start:end])
得到一个json
{
'status': 1,
'err_code': 0,
'data': {
'hash': '409EBC56EA4BA76E58D8C89AF8D03B6A',
'timelength': 167732,
'filesize': 2684376,
'audio_name': '旺仔小乔 - 我看过',
'have_album': 1,
'album_name': '我看过',
'album_id': '77435914',
'img': 'http://imge.kugou.com/stdmusic/20230821/20230821175541814897.jpg',
'have_mv': 0,
'video_id': 0,
'author_name': '旺仔小乔',
'song_name': '我看过',
'lyrics': '\ufeff[id:$00000000]\r\n[ar:旺仔小乔]\r\n[ti:我看过]\r\n[by:]\r\n[hash:409ebc56ea4ba76e58d8c89af8d03b6a]\r\n[al:]\r\n[sign:]\r\n[qq:]\r\n[total:167805]\r\n[offset:0]\r\n[00:00.00]我看过\r\n[00:00.05]演唱:旺仔小乔\r\n[00:00.17]原唱:周星星\r\n[00:00.27]词:黄政彬/曾歆沂/周星星\r\n[00:00.50]曲:谢佳旺/吴周烁/周星星\r\n[00:00.73]编曲:曾吴秋杰\r\n[00:00.85]制作人:曾吴秋杰\r\n[00:00.99]混音:姚家俊\r\n[00:01.10]吉他:叶知\r\n[00:01.18]和声:李俊聪\r\n[00:01.29]艺人统筹:谢永田/洛洛\r\n[00:01.48]监制:陈志伟\r\n[00:01.59]封面背景:平生不晚\r\n[00:01.74]op:创音计划\r\n[00:01.87]我看过你说好一辈子\r\n[00:05.70]我看过你的无微不至\r\n[00:18.03]你的回答都犹豫了一下\r\n[00:25.73]在我面前怎么开始害怕说错话\r\n[00:33.54]你在眺望窗外无关的景象\r\n[00:40.74]保持沉默和你的优雅\r\n[00:48.39]想陪你假装没事\r\n[00:52.33]天真把分开延迟\r\n[00:56.22]现实却比我们诚实\r\n[01:03.96]我看过你说好一辈子\r\n[01:07.68]我看过你的无微不至\r\n[01:11.54]我看过你说想要时间停止\r\n[01:15.62]拉着我的手喊我名字\r\n[01:19.34]我看过你说谎的方式\r\n[01:23.14]我看过爱情自然变质\r\n[01:27.05]就算错过这样到此为止\r\n[01:34.76]至少我看过你爱我的样子\r\n[01:40.55]沉默空气戳破你的心事\r\n[01:44.47]你难过伤心又有几次\r\n[01:48.37]你脸上的陌生表情\r\n[01:50.19]是你给的诠释\r\n[01:54.21]我看着你飘忽的心思\r\n[01:58.03]也看见我无谓的坚持\r\n[02:01.83]亲爱的不要再说你还爱我\r\n[02:05.78]因为看过你爱我的样子\r\n[02:09.62]我看过的最美的落日\r\n[02:13.45]是你陪我看海的样子\r\n[02:17.37]就算错过这样到此为止\r\n[02:25.09]至少我看过你爱我的样子\r\n',
'author_id': '958503',
'privilege': 8,
'privilege2': '1000',
'play_url': 'https://webfs.tx.kugou.com/202308272348/d1659e0afe765481bc9a362777d2d66a/v2/409ebc56ea4ba76e58d8c89af8d03b6a/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3',
'authors': [{
'author_id': '958503',
'author_name': '旺仔小乔',
'is_publish': '1',
'sizable_avatar': 'http://singerimg.kugou.com/uploadpic/softhead/{size}/20230621/20230621153031153.jpg',
'e_author_id': 'T817KABBB5C71',
'avatar': 'http://singerimg.kugou.com/uploadpic/softhead/400/20230621/20230621153031153.jpg'
}],
'is_free_part': 0,
'bitrate': 128,
'recommend_album_id': 77435914,
'store_type': 'audio',
'album_audio_id': 545949847,
'is_publish': 1,
'e_author_id': 'T817KABBB5C71',
'audio_id': '272898223',
'has_privilege': True,
'play_backup_url': 'https://webfs.hw.kugou.com/202308272348/d4054c9cbb7ec554ef20bf4be3598e2a/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.mp3',
'small_library_song': 1,
'encode_album_id': '1a3pxm66',
'encode_album_audio_id': '911lljc3',
'e_video_id': '0df'
}
}
从清洗得到数据可以看到音乐播放链接(play_url)和名称(audio_name)
audio_name = json_data['data']['audio_name']
play_url = json_data['data']['play_url']
最后最终的函数:
def get_music():
# 域名
url = 'https://wwwapi.kugou.com/yy/index.php'
# 通过简化后的网址得到的请求参数:
data = {
'r': 'play/getdata',
'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)),
'encode_album_audio_id': '1i5tjz66'
}
dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4; kg_dfid=3exUvM3tv8Ms22pf5b2n00JB; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1692943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
html_music = requests.get(url=url,params=data,headers=dic_headers)
start = html_music.text.index('{')
end = html_music.text.index('})') + 1
json_data = json.loads(html_music.text[start:end])
audio_name = json_data['data']['audio_name']
play_url = json_data['data']['play_url']
music_dict={}
music_dict['audio_name']=audio_name
music_dict['play_url']=play_url
return music_dict
3、封装下载音乐函数
def music_down(play_url,audio_name):
with open(f'{audio_name}.mp3','wb') as f:
f.write(requests.get(play_url).content)
print('音乐下载完毕')
四、拓展
发现只要更换请求参数里面的encode_album_audio_id 值就可以跳不同的音乐。同时在html页面上发现了每个歌曲对应的id:
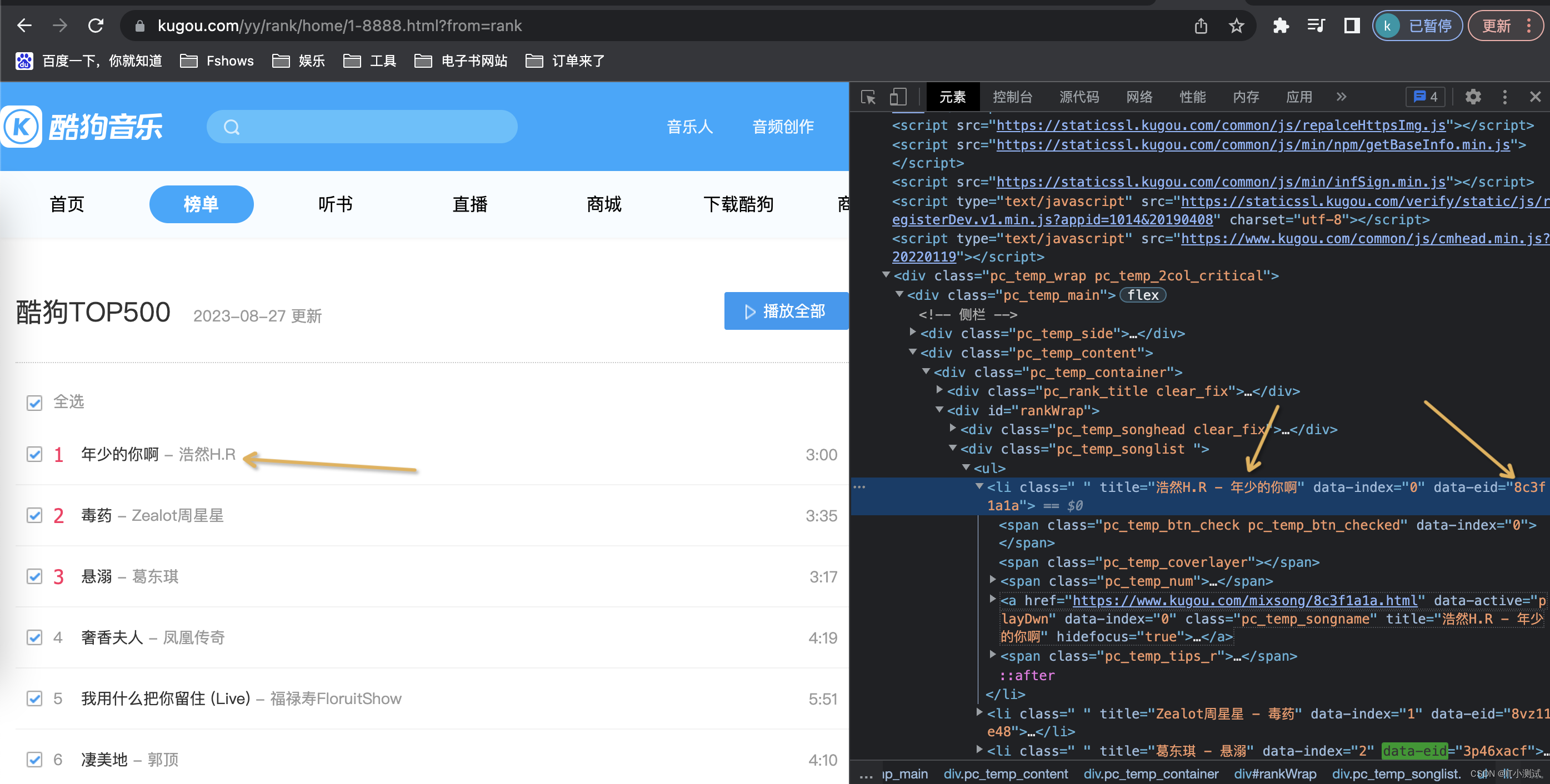
思路:从榜单htm里面拿到每个的 data-eid,然后循环写入参数里面进行调用,得到了每首歌曲的mps链接,从而实现批量下载歌曲。
1、封装获取data-eid值的函数
注意:一定要配一个请求头,不然会被反爬虫机制识别返回404了!!!
def get_encode_album_audio_id( url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=rank'):
dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4; kg_dfid=3exUvM3tv8Ms22pf5b2n00JB; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1692943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
response = requests.get(url,headers=dic_headers)
html=response.text
encode_album_audio_id= re.findall(r'data-eid="(.*?)"',html)
return encode_album_audio_id
这时候你得到了一个全是有data-eid值组成的列表:
['8c3f1a1a', '8vz11e48', '3p46xacf', 'j7f9ae1', '4jhcq350', 'nvgsv3d', '1i5tjz66', '7hn18ob3', '8oe7kh9f', '7f28o17a', '48b0ao4a', 'iy6qude', '4he72a9e', '8wv16y78', '8utk00de', '8d7rfa48', '8kof7e8c', '7z36fm39', '2pn1aiaf', '8mpl8j10', '74gnio05', 'gj6ht10']
然后封装一个批量下载运行函数,调用获取data-eid值的函数拿到data-eid值,for循环遍历然后调用获取音乐函数,最后调用音乐下载函数。
最后成品代码:
import requests,time,math,re,os,json
from bs4 import BeautifulSoup
# 爬取音乐
# 简化后的音乐请求网址
music_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery1910009914641215163833_1692950107734&encode_album_audio_id=911lljc3'
# 封装请求获取返回的文本
def get_music(encode_album_audio_id):
# 域名
url = 'https://wwwapi.kugou.com/yy/index.php'
# 通过简化后的网址得到的请求参数:
data = {
'r': 'play/getdata',
'callback': 'jQuery19108922952455208721_{}'.format(math.floor(time.time()*1000)),
'encode_album_audio_id': encode_album_audio_id
}
dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4; kg_dfid=3exUvM3tv8Ms22pf5b2n00JB; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1692943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
html_music = requests.get(url=url,params=data,headers=dic_headers)
start = html_music.text.index('{')
end = html_music.text.index('})') + 1
json_data = json.loads(html_music.text[start:end])
audio_name = json_data['data']['audio_name']
play_url = json_data['data']['play_url']
music_dict={}
music_dict['audio_name']=audio_name
music_dict['play_url']=play_url
return music_dict
def music_down(play_url,audio_name):
with open(f'./music/{audio_name}.mp3','wb') as f:
f.write(requests.get(play_url).content)
print('音乐下载完毕')
def get_encode_album_audio_id( url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=rank'):
dic_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'cookie': 'kg_mid=a1dd2b6ab4362156489644e5687fc1e4; kg_dfid=3exUvM3tv8Ms22pf5b2n00JB; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1692943898; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1692950108',
'referer': 'https://www.kugou.com/'
}
response = requests.get(url,headers=dic_headers)
html=response.text
encode_album_audio_id= re.findall(r'data-eid="(.*?)"',html)
def run_1():
encode_album_audio_id = get_encode_album_audio_id()
for i in encode_album_audio_id:
music_dic = get_music(i)
music_down(music_dic['play_url'],music_dic['audio_name'])
if __name__ == '__main__':
a=run_1()
版权归原作者 IT小测试 所有, 如有侵权,请联系我们删除。