
hadoop下载与安装
注意这是windows上运行hadoop,如果只是向通过idea远程连接虚拟机上的hadoop请跳过。
hadoop下载官网
清华大学镜像下载
进入官网点击Binary download是运行在windows上的。在Apache里面下东西经常会有binary和source的版本,binary是编译好的可以直接使用,source是还没编译过的源代码,需要自行编译。
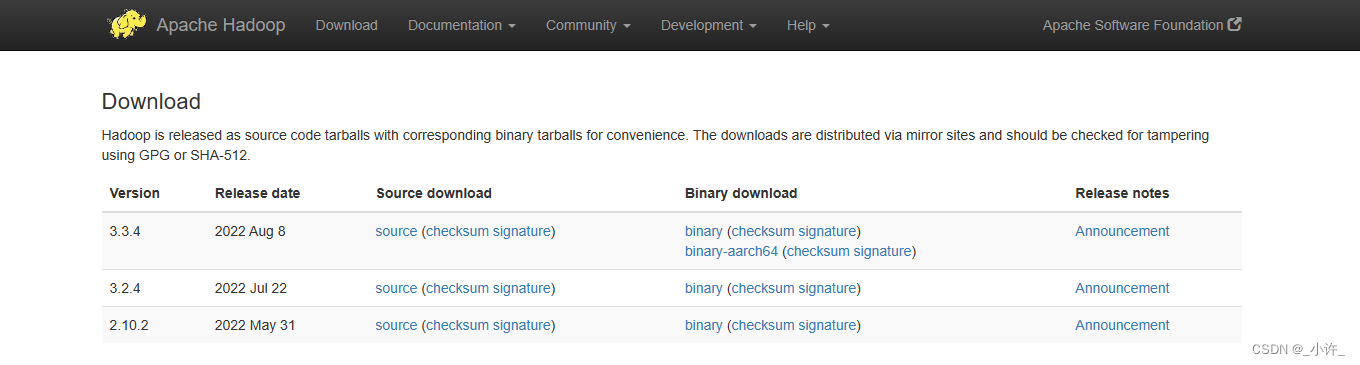
镜像下载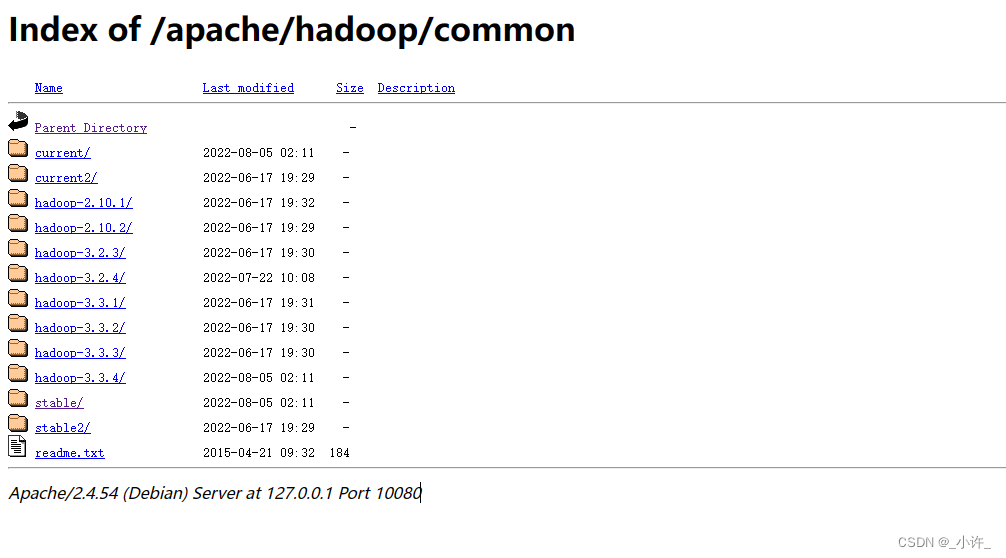
选择合适的版本
解压
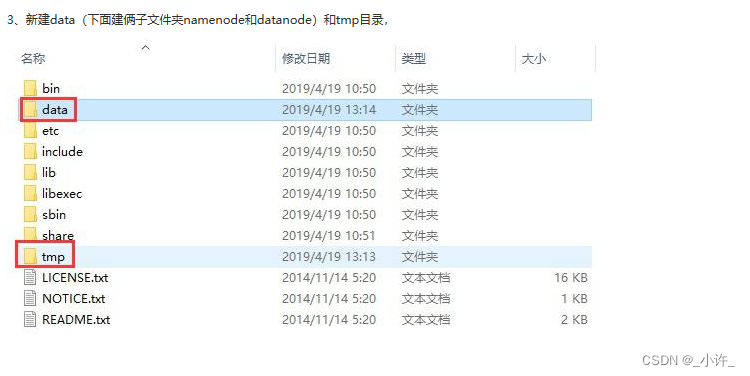
hadoop是分布式的,有datanode和namenode两个节点,需要新建目录代替
配置环境变量
一定要配置hadoop的环境变量,不然在启动是会出现下面的错误:
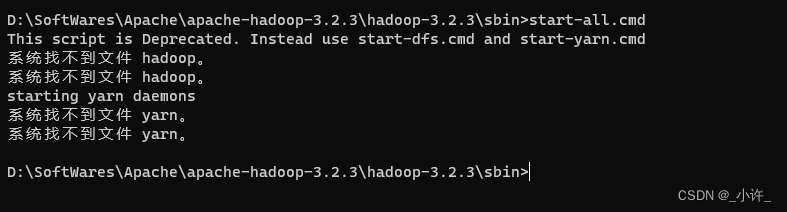
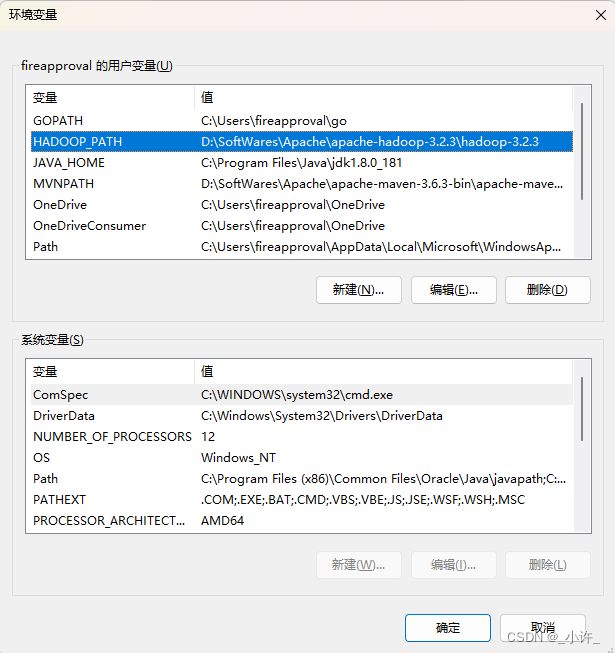

bin目录存在hadoop信息的启动命令,sbin存在hadoop集群启动命令,bin和sbin可以不配置,切换到相应目录再启动cmd即可。
修改配置文件
- 修改windows系统启动类
hadoop-env.cmd


将%JAVA_HOME%替换为java环境变量的路径。
将Program Files替换为PROGRA~1

- 修改配置文件(core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml)
- core-site.xml

<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
- hdfs-site.xml
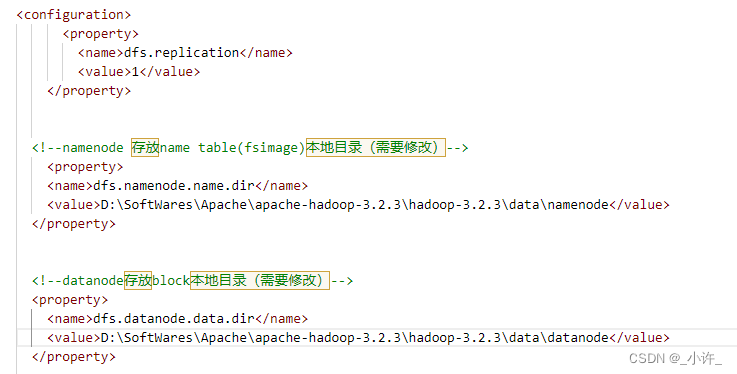
<property><name>dfs.replication</name><value>1</value></property><!--namenode 存放name table(fsimage)本地目录(需要修改)--><property><name>dfs.namenode.name.dir</name><value>D:\SoftWares\Apache\apache-hadoop-3.2.3\hadoop-3.2.3\data\namenode</value></property><!--datanode存放block本地目录(需要修改)--><property><name>dfs.datanode.data.dir</name><value>D:\SoftWares\Apache\apache-hadoop-3.2.3\hadoop-3.2.3\data\datanode</value></property>
- mapred-site.xml

<property><name>mapreduce.framework.name</name><value>yarn</value></property>
- yarn-site.xml
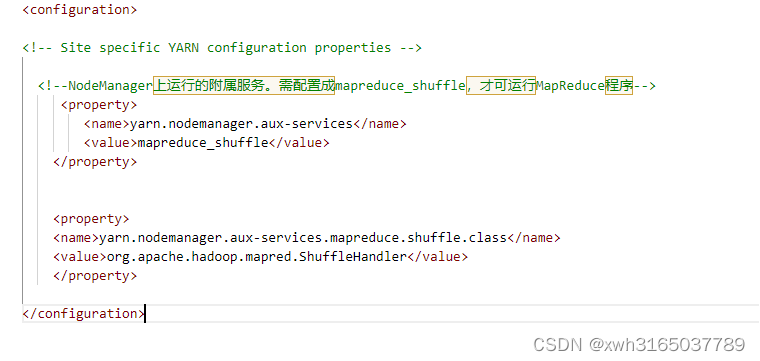
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
初始化与启动
注意如果配置了环境变量可以直接运行命令,如果没有配置环境变量,则切换到对于目录在启动cmd。路径为
~\hadoop-3.2.3\bin
。
输入
hadoop version
检查是否安装成功
输入
hadoop namenode -format
初始化hadoop
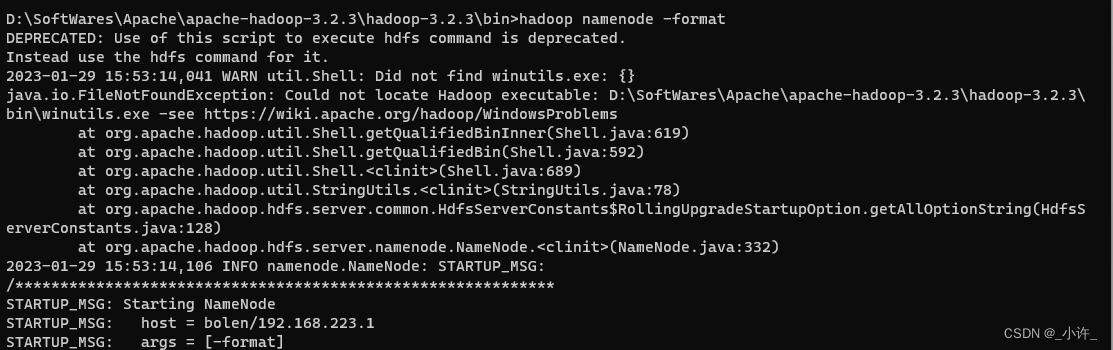

出现下面且
\data\namenode
有
current
目录·即为初始化成功。

data目录为自定义目录
在cmd中执行
start-all.cmd
命令,启动Hadoop,路径:
~\hadoop\hadoop-3.2.3\sbin
。
sbin没有配置环境变量需要切换到对应目录,也可以在为sbin配置环境变量。

输入
start-all.sh
启动:
运行成功后,会出现四个窗口,分别是:yarn-resourcemanager、yarn-nodemanager、hadoop-namenode、hadoop-datanode。
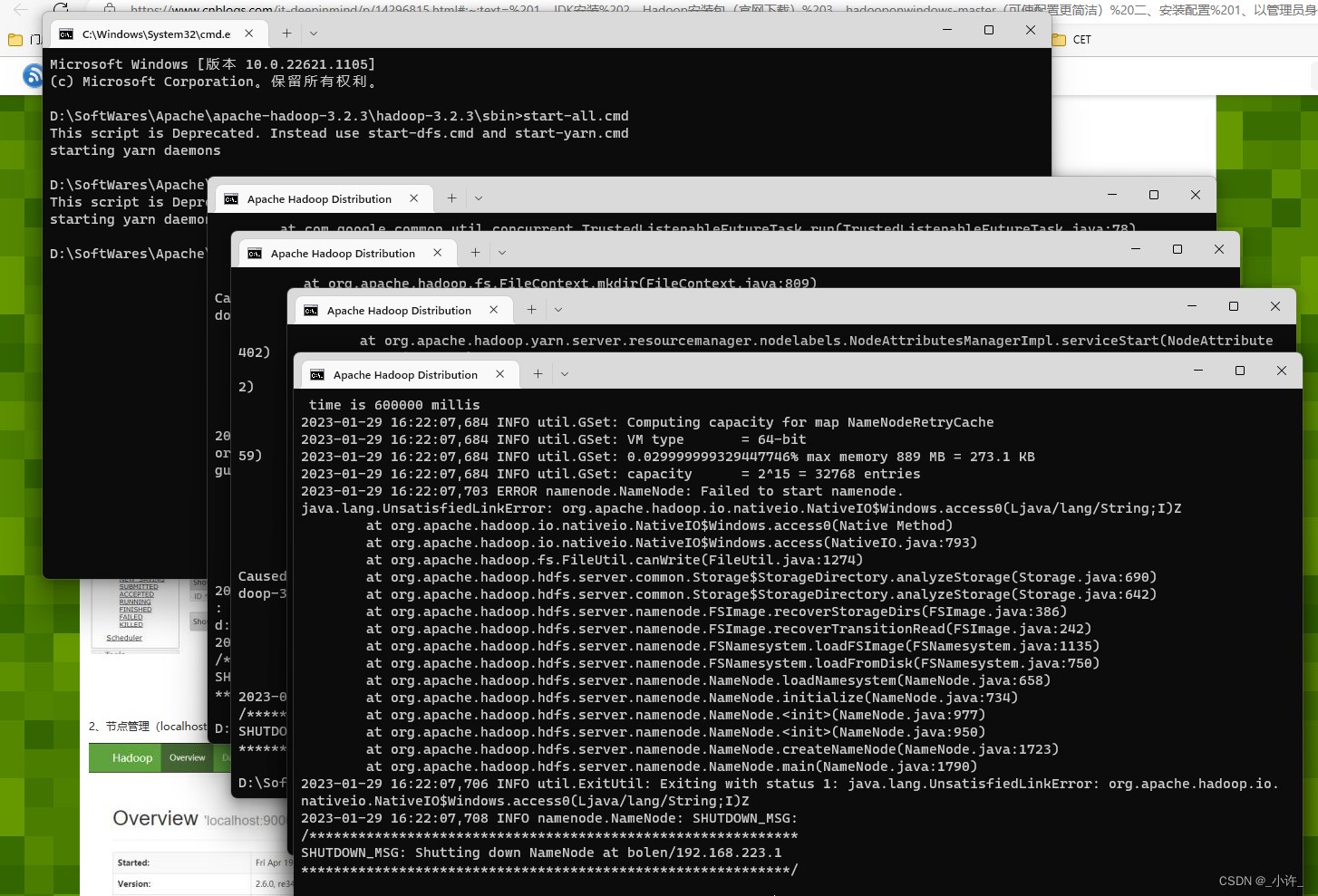
参考自:windows下安装Hadoop,就是这么简单
java.net.URISyntaxException: Illegal character in opaque part at index 2: D:\SoftWares\Apache\apache-hadoop-3.2.3\hadoop-3.2.3\data\namenode
信息: 没有运行的带有指定标准的任务。
如果出现上面两个错误则说明namenode的配置有问题。转到
hdfs-site.xml
/是linux系统的路径配置,
\是windows系统的路径配置,但要用
\\。
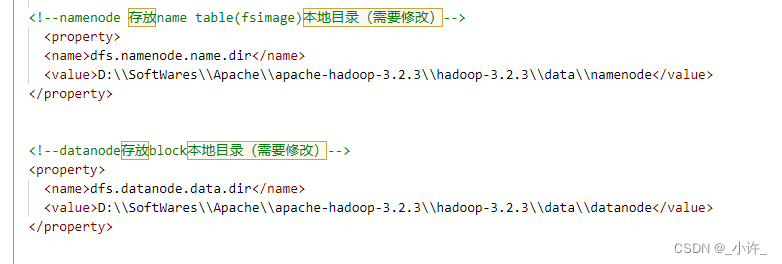
之后就可以正常启动了。
Could not locate Hadoop executable: D:\SoftWares\Apache\apache-hadoop-3.2.3\hadoop-3.2.3\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
在hadoop/bin目录下缺少了winutils.exe和hadoop.dll
下载地址
下载后复制到bin目录下即可:
这个两个文件虚拟机和window两方都要上传。
启动spark
windows上安装了hadoop但一般不用启动,需要使用计算计算框架MapReduce或者Spark是可以直接调用。
将目录切换到hadoop安装目录的bin目录下:
这些都是相关的命令,其中cmd后缀的是windows环境的,没有后缀名的默认是.sh为linux系统的命令。以spark为例,双击
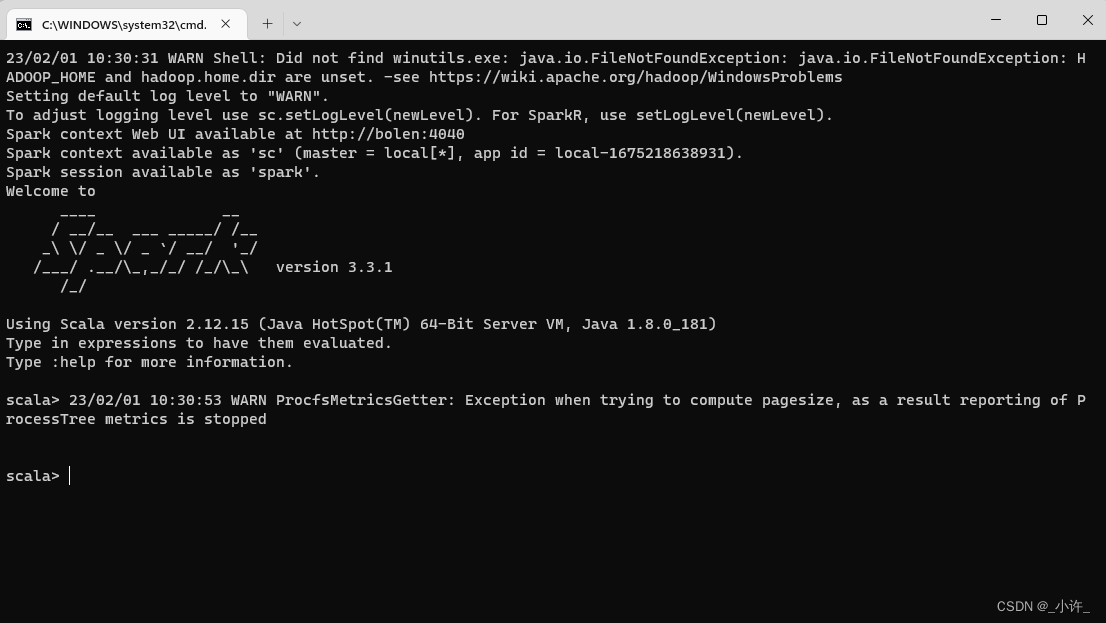
spark-shell.com
启动scala版的spark:
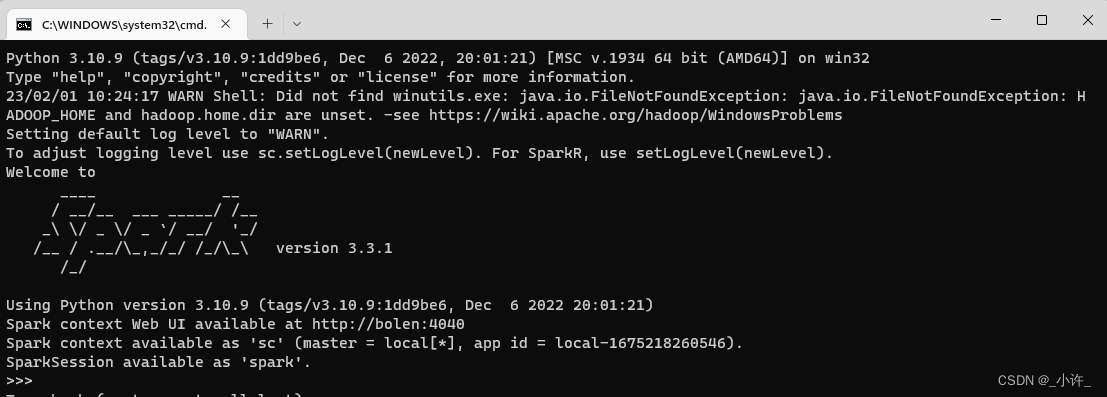
双击
pyspark.cmd
启动python版的spark:
可以正常启动的话就可以调用接口实现1相关1计算了。连续按两次Ctrl+C停止服务。
idea连接本地spark
配置好上面的环境后通过idea创建scala项目。可参考sbt编程语言scala的构建工具配置及项目构建(附带网盘下载)
- 创建scala项目
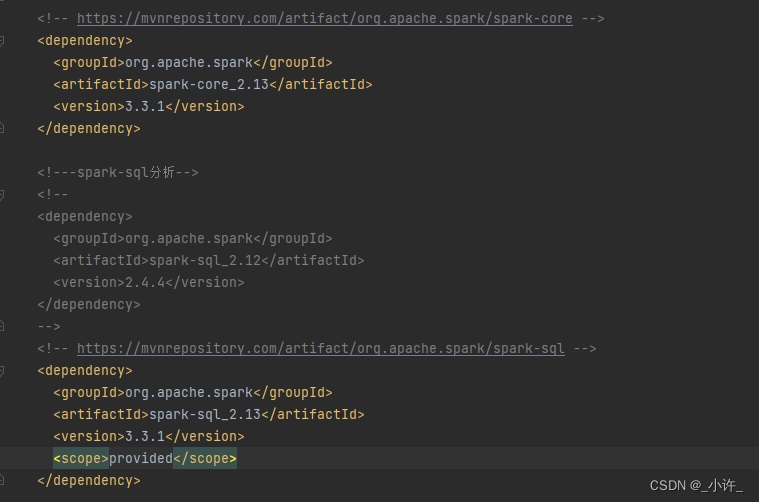
- pom导入spark依赖
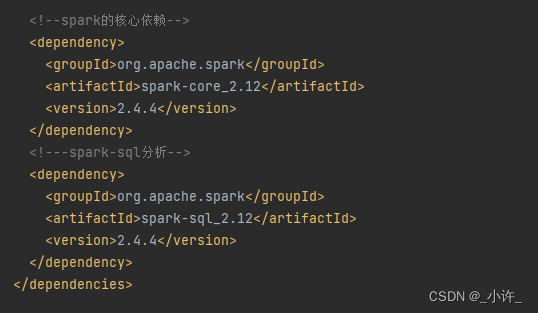
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>3.3.1</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>3.3.1</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.13</artifactId><version>3.3.1</version><scope>provided</scope></dependency>
依赖根据版本需要对应,不然会出现冲突。
Maven地址:https://mvnrepository.com/
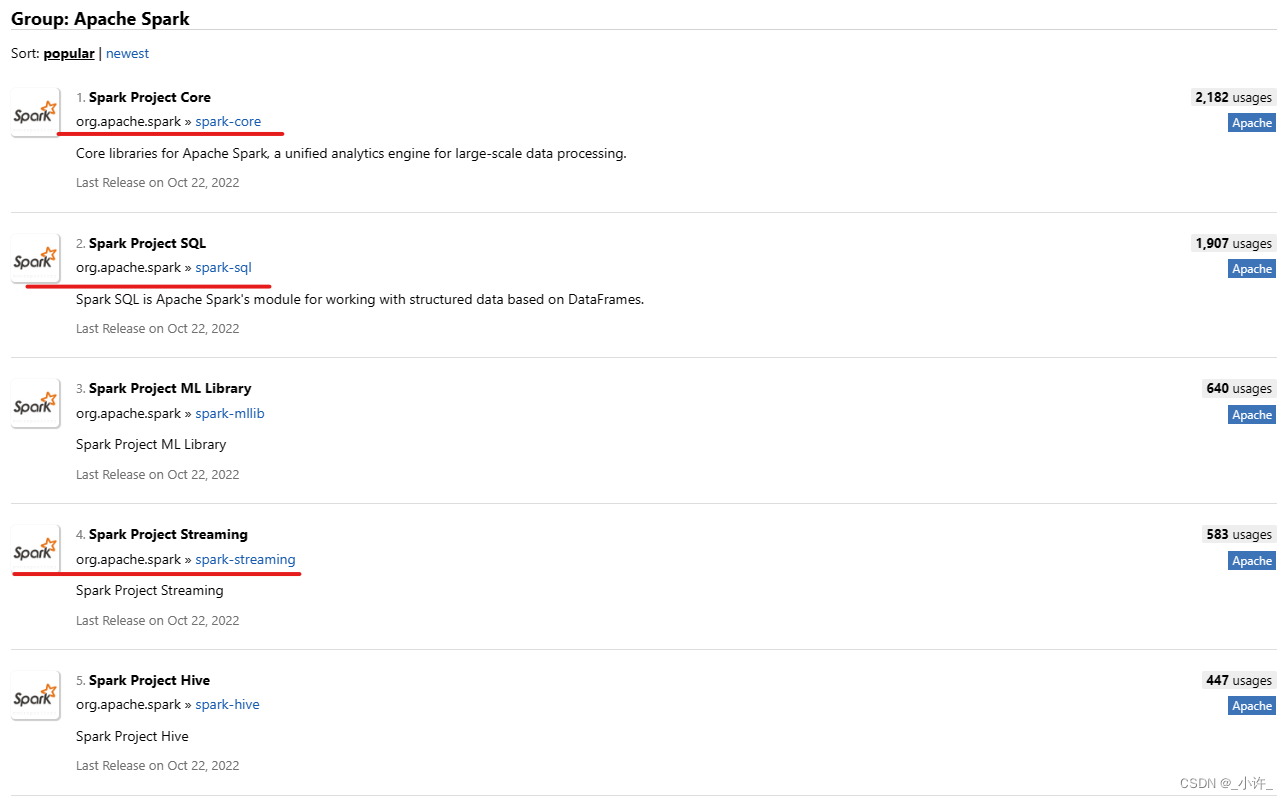
注意这里的spark要与虚拟机上的一致。
- 编写连接测试代码
sorry,小编也还处于学习阶段,这一部分还未成功,出现了部分问题还未解决,由于时间紧迫就临时换为Java语言的了,后续在跟新Scala语言。
maven版的scala和java的依赖一样的,接口也可公用。
class sparkConnect {sparkConnect(){//配置本地spark并命名JavaSparkContext sc =newJavaSparkContext("local","thisSpark");List<Integer> list =newArrayList<Integer>();
list.add(1); list.add(2); list.add(3);//内存中获取数据常见rddJavaRDD<Integer> rdd = sc.parallelize(list);//rdd计算JavaRDD<Integer> listPlus = rdd.map(y->y+5);//打印System.out.println("list is:"+ list);System.out.println("listPlus is:"+ listPlus);System.out.println("the relation is list plus five = listPlus");}publicstaticvoidmain(String[] args){
sparkConnect sparkConnect =newsparkConnect();}
Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
运行上述的测试代码会报错,未能加载
winutils.exe
文件,可是在之前的配置中已经添加了该引用,这是由于Windows环境变量默认识别cmd命令的,其他的无法执行,例如在redis中,光使用redis-server就是出现该系统不支持一个道理。
解决方案是为该exe单独配置环境变量

在此之前一定要确认环境变量无误
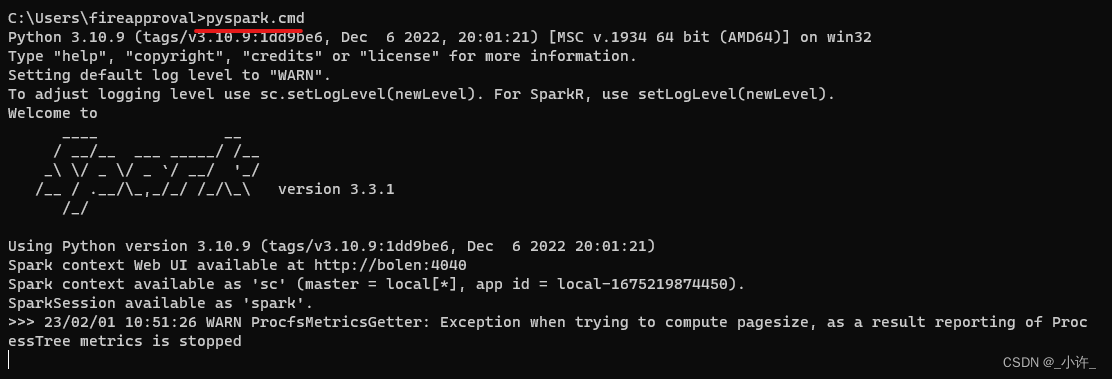
配置之后就可以运行测试项目了。可以是小编这里又遇到了一个问题,配置了
winutils.exe
还是无法找到。如下图:

在调试的过程中发现启动的spark版本是2.4.4也就是pom中加载的版本,而本地的spark版本是3.3.1的版本不一致,匹配不了。
修改pom的文件版本,注意与本地对应
修改后就可以成功启动了: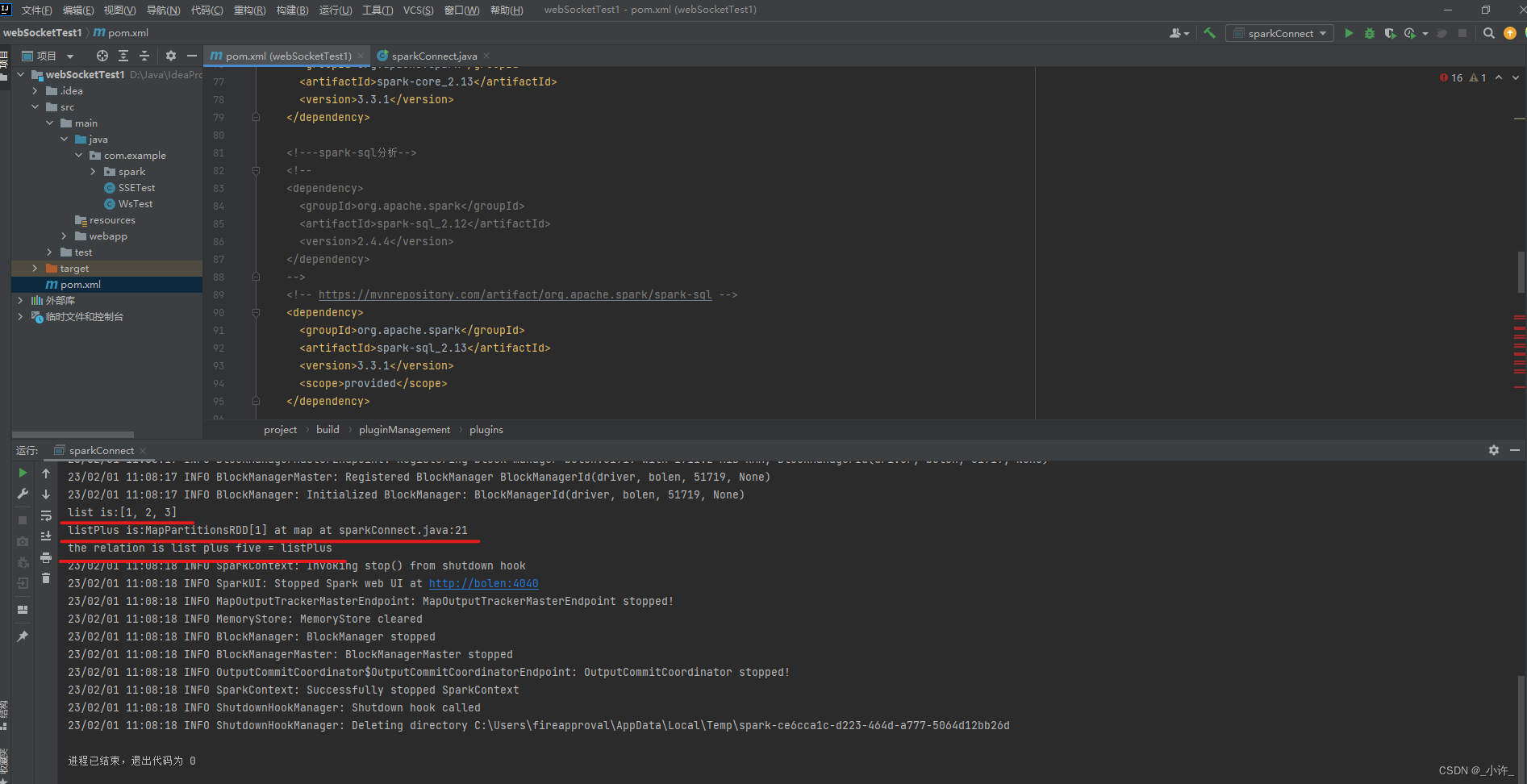
如上图已经实现了本地saprk的连接,就可以通过java独立引用程序调用spark。
class sparkConnect {sparkConnect(){JavaSparkContext sc =newJavaSparkContext("local","thisSpark");List<Integer> list =newArrayList<Integer>();
list.add(1); list.add(2); list.add(3);//内存中获取数据常见rddJavaRDD<Integer> rdd = sc.parallelize(list);//rdd计算JavaRDD<Integer> listPlus = rdd.map(y->y+5);System.out.println("list is:"+ list);System.out.println("listPlus is:"+ listPlus);System.out.println("the relation is list plus five = listPlus");}publicstaticvoidmain(String[] args){
sparkConnect sparkConnect =newsparkConnect();}}
回顾测试代码,这已经是调用spark实现简单计算最精简的步骤了。创建的
sc
对象可交互式的sc是等效的。如下:
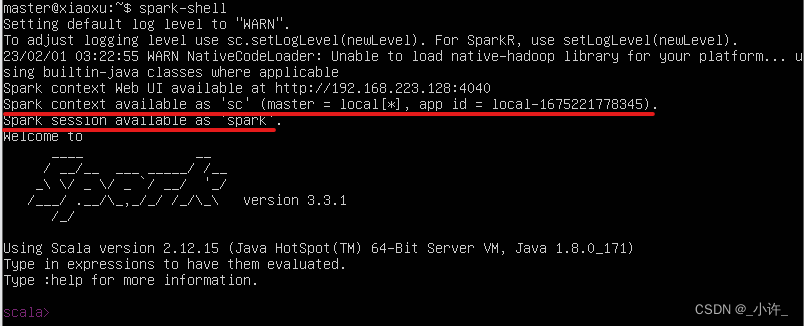
它们的区别在于一个是Java语言的调用对象,一个是Scala的调用对象。
idea远程连接spark
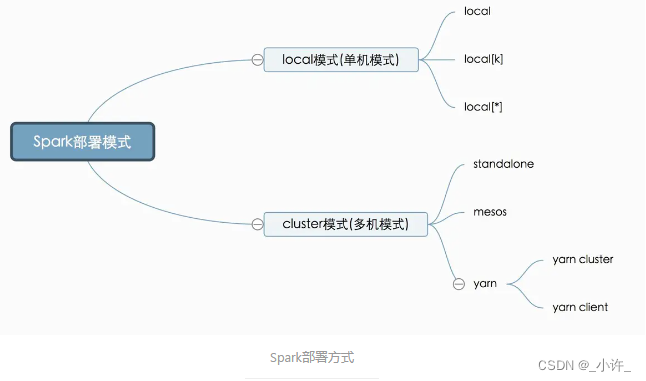
远程连接spark首先要了解spark的部署方式这边文章讲的很详细,感谢作者!
JavaSparkContext sc =newJavaSparkContext("local","thisSpark");
构造方法中第一个参数是主机,第二个参数是名称,关键就在于
local
参数,来看一段scala连接的代码:
def main(args: Array[String]):Unit={val spark = SparkSession
.builder
.appName("Spark Pi").master("spark://172.21.212.114:7077").config("spark.jars","E:\\work\\polaris\\polaris-spark\\spark-scala\\target\\spark-scala-1.0.0.jar").config("spark.executor.memory","2g").config("spark.cores.max","2").config("spark.driver.host","172.21.58.28").config("spark.driver.port","9089").getOrCreate()
注意设置master的参数。由于库公用,Java也可以尝试一下:
切换到spark的conf目录查看默认配置

查看运行节点在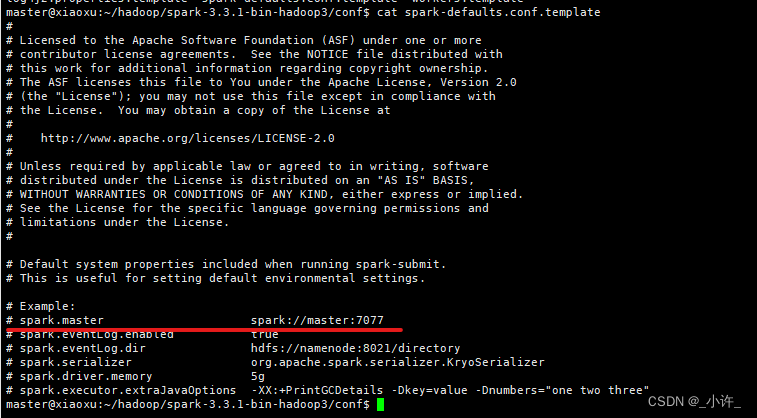
JavaSparkContext sc =newJavaSparkContext("spark://192.168.223.128:7077","thisSpark");
尝试了很多写法,http,只有ip的,spark开头的都没有成功。所以远程连接失败了,大佬了解需要怎末连接的。
版权归原作者 _小许_ 所有, 如有侵权,请联系我们删除。