

采用带注意机制的序列序列结构进行英印地语神经机器翻译
Seq2seq模型构成了机器翻译、图像和视频字幕、文本摘要、聊天机器人以及任何你可能想到的包括从一个数据序列到另一个数据序列转换的任务的基础。如果您曾使用过谷歌Translate,或与Siri、Alexa或谷歌Assistant进行过互动,那么你就是序列对序列(seq2seq)神经结构的受益者。
我们这里的重点是机器翻译,基本上就是把一个句子x从一种语言翻译成另一种语言的句子y。机器翻译是seq2seq模型的主要用例,注意机制对机器翻译进行了改进。关于这类主题的文章通常涉及用于实现的大代码段和来自多个库的大量API调用,对概念本身没有直观的理解。在这方面,我们既要讲求理论,也要讲求执行。除了实现之外,我们还将详细了解seq2seq体系结构和注意力的每个组件表示什么。本文中使用的代码可以在最后的资源列表中找到。
目标
在Tensorflow中实现、训练和测试一个英语到印地语机器翻译模型。
对编码器、解码器、注意机制的作用形成直观透彻的理解。
讨论如何进一步改进现有的模型。
读数据集
首先,导入所有需要的库。在这个实现中使用的英语到印地语语料库可以在Kaggle找到。一个名为“Hindi_English_Truncated_Corpus”的文件。将下载csv "。请确保在pd.read_csv()函数中放置了正确的文件路径,该路径对应于文件系统中的路径。
import numpy as np
import pandas as pd
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import tensorflow as tf
from sklearn.model_selection import train_test_split
import time
from matplotlib import pyplot as plt
import os
import re
data = pd.read_csv("./Hindi_English_Truncated_Corpus.csv")
english_sentences = data["english_sentence"]
hindi_sentences = data["hindi_sentence"]
让我们快速看看我们正在处理的数据集的类型。这是相当简单的。
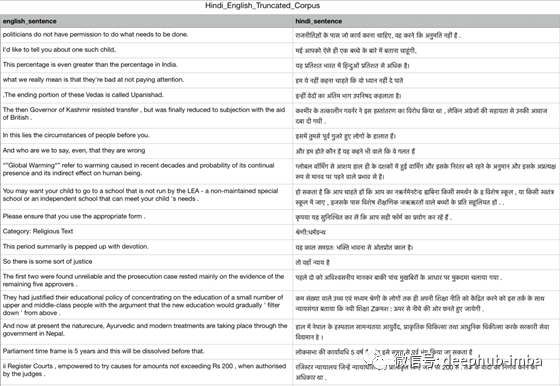
数据预处理
在我们继续我们的编码器,解码器和注意力实现之前,我们需要预处理我们的数据。请注意,预处理步骤也依赖于我们处理的数据类型。例如,在这里考虑的数据集中,也有带有空字符串的句子。我们需要相应地处理这类案例。如果使用其他数据集,也可能需要一些额外或更少的步骤。预处理步骤如下:
在单词和标点符号之间插入空格
如果手头上的句子是英语,我们就用空格替换除了(a-z, A-Z, “.”, “?”, “!”, “,”)
句子中去掉多余的空格,关键字“sentencestart”和“sentenceend”分别添加到句子的前面和后面,让我们的模型明确地知道句子开始和结束。
每个句子的以上三个任务都是使用preprocess_sentence()函数实现的。我们还在开始时初始化了所有的超参数和全局变量。请阅读下面的超参数和全局变量。我们将在需要时使用它们。
# Global variables and Hyperparameters
num_words = 10000
oov_token = '<UNK>'
english_vocab_size = num_words + 1
hindi_vocab_size = num_words + 1
MAX_WORDS_IN_A_SENTENCE = 16
test_ratio = 0.2
BATCH_SIZE = 512
embedding_dim = 64
hidden_units = 1024
learning_rate = 0.006
epochs = 100
def preprocess_sentence(sen, is_english):
if (type(sen) != str):
return ''
sen = sen.strip('.')
# insert space between words and punctuations
sen = re.sub(r"([?.!,¿;।])", r" \1 ", sen)
sen = re.sub(r'[" "]+', " ", sen)
# For english, replacing everything with space except (a-z, A-Z, ".", "?", "!", ",", "'")
if(is_english == True):
sen = re.sub(r"[^a-zA-Z?.!,¿']+", " ", sen)
sen = sen.lower()
sen = sen.strip()
sen = 'sentencestart ' + sen + ' sentenceend'
sen = ' '.join(sen.split())
return sen
对包含英语句子和印地语句子的每个数据点进行循环,确保不考虑带有空字符串的句子,并且句子中的最大单词数不大于MAX_WORDS_IN_A_SENTENCE的值。这一步是为了避免我们的矩阵是稀疏的。
下一步是对文本语料库进行向量化。具体来说,fit_on_texts()为每个单词分配一个唯一的索引。texts_to_sequences()将一个文本句子转换为一个数字列表或一个向量,其中数字对应于单词的唯一索引。pad_sequences()通过添加刚好足够数量的oov_token(从vocab token中提取)来确保所有这些向量最后都具有相同的长度,使每个向量具有相同的长度。tokenize_statements()封装了上面这些功能。
接下来,我们从完整的数据集中得到训练集,然后对训练集进行批处理。我们训练模型所用的句子对总数为51712。
# Loop through each datapoint having english and hindi sentence
processed_e_sentences = []
processed_h_sentences = []
for (e_sen, h_sen) in zip(english_sentences, hindi_sentences):
processed_e_sen = preprocess_sentence(e_sen, True)
processed_h_sen = preprocess_sentence(h_sen, False)
if(processed_e_sen == '' or processed_h_sen == '' or processed_e_sen.count(' ') > (MAX_WORDS_IN_A_SENTENCE-1) or processed_h_sen.count(' ') > (MAX_WORDS_IN_A_SENTENCE-1)):
continue
processed_e_sentences.append(processed_e_sen)
processed_h_sentences.append(processed_h_sen)
print("Sentence examples: ")
print(processed_e_sentences[0])
print(processed_h_sentences[0])
print("Length of English processed sentences: " + str(len(processed_e_sentences)))
print("Length of Hindi processed sentences: " + str(len(processed_h_sentences)))
def tokenize_sentences(processed_sentences, num_words, oov_token):
tokenizer = Tokenizer(num_words = num_words, oov_token = oov_token)
tokenizer.fit_on_texts(processed_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(processed_sentences)
sequences = pad_sequences(sequences, padding = 'post')
return word_index, sequences, tokenizer
english_word_index, english_sequences, english_tokenizer = tokenize_sentences(processed_e_sentences, num_words, oov_token)
hindi_word_index, hindi_sequences, hindi_tokenizer = tokenize_sentences(processed_h_sentences, num_words, oov_token)
# split into traning and validation set
english_train_sequences, english_val_sequences, hindi_train_sequences, hindi_val_sequences = train_test_split(english_sequences, hindi_sequences, test_size = test_ratio)
BUFFER_SIZE = len(english_train_sequences)
# Batching the training set
dataset = tf.data.Dataset.from_tensor_slices((english_train_sequences, hindi_train_sequences)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder = True)
print("No. of batches: " + str(len(list(dataset.as_numpy_iterator()))))
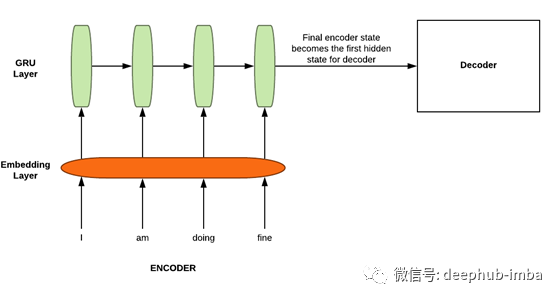
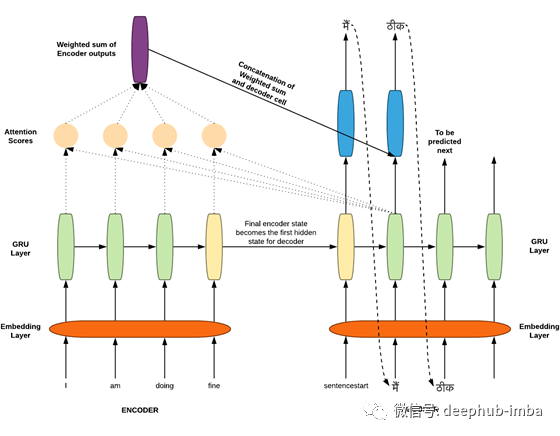
编码器Encoder
Seq2seq架构在原论文中涉及到两个长短期内存(LSTM)。一个用于编码器,另一个用于解码器。请注意,在编码器和解码器中,我们将使用GRU(门控周期性单元)来代替LSTM,因为GRU的计算能力更少,但结果与LSTM几乎相同。Encoder涉及的步骤:
输入句子中的每个单词都被嵌入并表示在具有embedding_dim(超参数)维数的不同空间中。换句话说,您可以说,在具有embedding_dim维数的空间中,词汇表中的单词的数量被投影到其中。这一步确保类似的单词(例如。boat & ship, man & boy, run & walk等)都位于这个空间附近。这意味着“男人”这个词和“男孩”这个词被预测的几率几乎一样(不是完全一样),而且这两个词的意思也差不多。
接下来,嵌入的句子被输入GRU。编码器GRU的最终隐藏状态成为解码器GRU的初始隐藏状态。编码器中最后的GRU隐藏状态包含源句的编码或信息。源句的编码也可以通过所有编码器隐藏状态的组合来提供[我们很快就会发现,这一事实对于注意力的概念的存在至关重要]。
class Encoder(tf.keras.Model):
def __init__(self, english_vocab_size, embedding_dim, hidden_units):
super(Encoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(english_vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(hidden_units, return_sequences = True, return_state = True)
def call(self, input_sequence):
x = self.embedding(input_sequence)
encoder_sequence_output, final_encoder_state = self.gru(x)
#Dimensions of encoder_sequence_output => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, hidden_units)
#Dimensions of final_encoder_state => (BATCH_SIZE, hidden_units)
return encoder_sequence_output, final_encoder_state
# initialize our encoder
encoder = Encoder(english_vocab_size, embedding_dim, hidden_units)
解码器Decoder ( 未使用注意力机制)
注意:在本节中,我们将了解解码器的情况下,不涉及注意力机制。这对于理解稍后与解码器一起使用的注意力的作用非常重要。
解码器GRU网络是生成目标句的语言模型。最终的编码器隐藏状态作为解码器GRU的初始隐藏状态。第一个给解码器GRU单元来预测下一个的单词是一个像“sentencestart”这样的开始标记。这个标记用于预测所有num_words数量的单词出现的概率。训练时使用预测的概率张量和实际单词的一热编码来计算损失。这种损失被反向传播以优化编码器和解码器的参数。同时,概率最大的单词成为下一个GRU单元的输入。重复上述步骤,直到出现像“sentenceend”这样的结束标记。
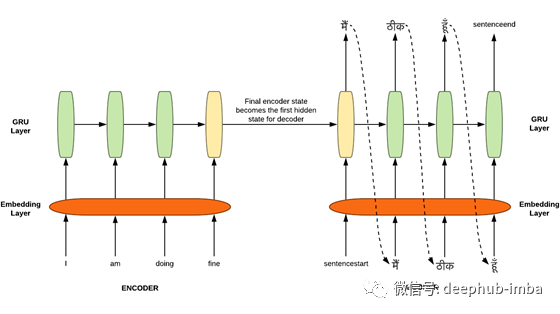
这种方法的问题是:
信息瓶颈:如上所述,编码器的最终隐藏状态成为解码器的初始隐藏状态。这就造成了信息瓶颈,因为源句的所有信息都需要压缩到最后的状态,这也可能会偏向于句子末尾的信息,而不是句子中很久以前看到的信息。
解决方案:我们解决了上述问题,不仅依靠编码器的最终状态来获取源句的信息,还使用了编码器所有输出的加权和。那么,哪个编码器的输出比另一个更重要?注意力机制就是为了解决这个问题。
添加注意力机制
注意力不仅为瓶颈问题提供了解决方案,还为句子中的每个单词赋予了权重(相当字面意义)。源序列在编码器输出中有它自己的的信息,在解码器中被预测的字在相应的解码器隐藏状态中有它自己的的信息。我们需要知道哪个编码器的输出拥有类似的信息,我们需要知道在解码器隐藏状态下,哪个编码器输出的信息与解码器隐藏状态下的相似。
因此,这些编码器输出和解码器的隐藏状态被用作一个数学函数的输入,从而得到一个注意力向量分数。当一个单词被预测时(在解码器中的每个GRU单元),这个注意力分数向量在每一步都被计算出来。该向量确定每个编码器输出的权重,以找到加权和。
注意力的一般定义:给定一组向量“值”和一个向量“查询”,注意力是一种计算基于查询的加权值和的技术。
在我们的seq2seq架构上下文中,每个解码器隐藏状态(查询)处理所有编码器输出(值),以获得依赖于解码器隐藏状态(查询)的编码器输出(值)的加权和。
加权和是值中包含的信息的选择性摘要,查询将确定关注哪些值。这个过程类似于将查询投射到值空间中,以便在值空间中查找查询(score)的上下文。较高的分数表示对应的值更类似于查询。
根据注意力机制的原始论文,解码器决定源句要注意的部分。通过让解码器有一个注意机制,我们将编码器从必须将源句中的所有信息编码为固定长度的向量的负担中解脱出来。使用这种新方法,信息可以分布在整个序列中,解码器可以相应地有选择地检索这些信息。
还记得我们刚才讨论的数学函数吗?有几种方法可以找到注意力得分(相似度)。主要有以下几点:
基本点积注意力(Dot Product Attention)
乘法注意力(multiplicative attention)
加性注意力(additive attention)
我们不会在这里逐一深入讲解。我们会在后续的文章中详细接好。现在我们将考虑基本的点积注意,因为它是最容易掌握。你已经猜到了这类注意力的作用。从名称判断,它是输入矩阵的点积。
注意,基本的点积注意有一个假设。它假设两个输入矩阵的维数在轴上要做点积的地方必须是相同的,这样才能做点积。在我们的实现中,这个维度是由超参数hidden_units给出的,对于编码器和解码器都是一样的。
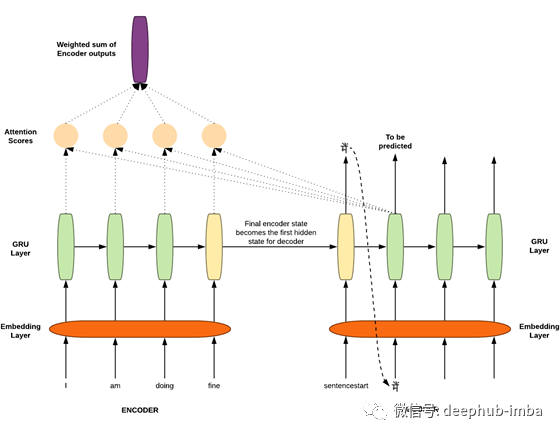
上面讲了太多的理论。现在让我们回到代码!我们将定义我们的Attention类。
将编码器输出张量与解码器隐藏状态进行点积,得到注意值。这是通过Tensorflow的matmul()函数实现的。我们取上一步得到的注意力分数的softmax。这样做是为了规范化分数并在区间[0,1]内获取值。编码器输出与相应的注意分数相乘,然后相加得到一个张量。这基本上是编码器输出的加权和,通过reduce_sum()函数实现。
class BasicDotProductAttention(tf.keras.layers.Layer):
def __init__(self):
super(BasicDotProductAttention, self).__init__()
def call(self, decoder_hidden_state, encoder_outputs):
#Dimensions of decoder_hidden_state => (BATCH_SIZE, hidden_units)
#Dimensions of encoder_outputs => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, hidden_units)
decoder_hidden_state_with_time_axis = tf.expand_dims(decoder_hidden_state, 2)
#Dimensions of decoder_hidden_state_with_time_axis => (BATCH_SIZE, hidden_units, 1)
attention_scores = tf.matmul(encoder_outputs, decoder_hidden_state_with_time_axis)
#Dimensions of attention_scores => (BATCH_SIZE, MAX_WORDS_IN_A_SENTENCE, 1)
attention_scores = tf.nn.softmax(attention_scores, axis = 1)
weighted_sum_of_encoder_outputs = tf.reduce_sum(encoder_outputs * attention_scores, axis = 1)
#Dimensions of weighted_sum_of_encoder_outputs => (BATCH_SIZE, hidden_units)
return weighted_sum_of_encoder_outputs, attention_scores
解码器Decoder ( 增加注意力机制)
代码在decoder类中增加了以下步骤。
就像编码器一样,我们在这里也有一个嵌入层用于目标语言中的序列。序列中的每一个单词都在具有相似意义的相似单词的嵌入空间中表示。
我们也得到的加权和编码器输出通过使用当前解码隐藏状态和编码器输出。这是通过调用我们的注意力层来实现的。
我们将以上两步得到的结果(嵌入空间序列的表示和编码器输出的加权和)串联起来。这个串联张量被发送到我们的解码器的GRU层。
这个GRU层的输出被发送到一个稠密层,这个稠密层给出所有hindi_vocab_size的单词出现的概率。具有高概率的单词意味着模型认为这个单词应该是下一个单词。
class Decoder(tf.keras.Model):
def __init__(self, hindi_vocab_size, embedding_dim, hidden_units):
super(Decoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(hindi_vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(hidden_units, return_state = True)
self.word_probability_layer = tf.keras.layers.Dense(hindi_vocab_size, activation = 'softmax')
self.attention_layer = BasicDotProductAttention()
def call(self, decoder_input, decoder_hidden, encoder_sequence_output):
x = self.embedding(decoder_input)
#Dimensions of x => (BATCH_SIZE, embedding_dim)
weighted_sum_of_encoder_outputs, attention_scores = self.attention_layer(decoder_hidden, encoder_sequence_output)
#Dimensions of weighted_sum_of_encoder_outputs => (BATCH_SIZE, hidden_units)
x = tf.concat([weighted_sum_of_encoder_outputs, x], axis = -1)
x = tf.expand_dims(x, 1)
#Dimensions of x => (BATCH_SIZE, 1, hidden_units + embedding_dim)
decoder_output, decoder_state = self.gru(x)
#Dimensions of decoder_output => (BATCH_SIZE, hidden_units)
word_probability = self.word_probability_layer(decoder_output)
#Dimensions of word_probability => (BATCH_SIZE, hindi_vocab_size)
return word_probability, decoder_state, attention_scores
# initialize our decoder
decoder = Decoder(hindi_vocab_size, embedding_dim, hidden_units)
训练
我们定义我们的损失函数和优化器。选择了稀疏分类交叉熵和Adam优化器。每个训练步骤如下:
- 从编码器对象获取编码器序列输出和编码器最终隐藏状态。编码器序列输出用于查找注意力分数,编码器最终隐藏状态将成为解码器的初始隐藏状态。
- 对于目标语言中预测的每个单词,我们将输入单词、前一个解码器隐藏状态和编码器序列输出作为解码器对象的参数。返回单词预测概率和当前解码器隐藏状态。
- 将概率最大的字作为下一个解码器GRU单元(解码器对象)的输入,当前解码器隐藏状态成为下一个解码器GRU单元的输入隐藏状态。
- 损失通过单词预测概率和目标句中的实际单词计算,并向后传播
在每个epoch中,每批调用上述训练步骤,最后存储并绘制每个epoch对应的损失。
附注:在第1步,为什么我们仍然使用编码器的最终隐藏状态作为我们的解码器的第一个隐藏状态?
这是因为,如果我们这样做,seq2seq模型将被优化为一个单一系统。反向传播是端到端进行的。我们不想分别优化编码器和解码器。并且,没有必要通过这个隐藏状态来获取源序列信息,因为我们已经有注意力机制了:)
optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate)
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')
def loss_function(actual_words, predicted_words_probability):
loss = loss_object(actual_words, predicted_words_probability)
mask = tf.where(actual_words > 0, 1.0, 0.0)
return tf.reduce_mean(mask * loss)
def train_step(english_sequences, hindi_sequences):
loss = 0
with tf.GradientTape() as tape:
encoder_sequence_output, encoder_hidden = encoder(english_sequences)
decoder_hidden = encoder_hidden
decoder_input = hindi_sequences[:, 0]
for i in range(1, hindi_sequences.shape[1]):
predicted_words_probability, decoder_hidden, _ = decoder(decoder_input, decoder_hidden, encoder_sequence_output)
actual_words = hindi_sequences[:, i]
# if all the sentences in batch are completed
if np.count_nonzero(actual_words) == 0:
break
loss += loss_function(actual_words, predicted_words_probability)
decoder_input = actual_words
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss.numpy()
all_epoch_losses = []
training_start_time = time.time()
for epoch in range(epochs):
epoch_loss = []
start_time = time.time()
for(batch, (english_sequences, hindi_sequences)) in enumerate(dataset):
batch_loss = train_step(english_sequences, hindi_sequences)
epoch_loss.append(batch_loss)
all_epoch_losses.append(sum(epoch_loss)/len(epoch_loss))
print("Epoch No.: " + str(epoch) + " Time: " + str(time.time()-start_time))
print("All Epoch Losses: " + str(all_epoch_losses))
print("Total time in training: " + str(time.time() - training_start_time))
plt.plot(all_epoch_losses)
plt.xlabel("Epochs")
plt.ylabel("Epoch Loss")
plt.show()
测试
为了测试我们的模型在经过训练后的执行情况,我们定义了一个函数,该函数接受一个英语句子,并按照模型的预测返回一个印地语句子。让我们实现这个函数,我们将在下一节中看到结果的好坏。
- 我们接受英语句子,对其进行预处理,并将其转换为长度为MAX_WORDS_IN_A_SENTENCE的序列或向量,如开头的“预处理数据”部分所述。
- 这个序列被输入到我们训练好的编码器,编码器返回编码器序列输出和编码器的最终隐藏状态。
- 编码器的最终隐藏状态是译码器的第一个隐藏状态,译码器的第一个输入字是一个开始标记“sentencestart”。
- 解码器返回预测的字概率。概率最大的单词成为我们预测的单词,并被附加到最后的印地语句子中。这个字作为输入进入下一个解码器层。
- 预测单词的循环将继续下去,直到解码器预测结束标记“sentenceend”或单词数量超过某个限制(我们将这个限制保持为MAX_WORDS_IN_A_SENTENCE的两倍)。
def get_sentence_from_sequences(sequences, tokenizer):
return tokenizer.sequences_to_texts(sequences)
# Testing
def translate_sentence(sentence):
sentence = preprocess_sentence(sentence, True)
sequence = english_tokenizer.texts_to_sequences([sentence])[0]
sequence = tf.keras.preprocessing.sequence.pad_sequences([sequence], maxlen = MAX_WORDS_IN_A_SENTENCE, padding = 'post')
encoder_input = tf.convert_to_tensor(sequence)
encoder_sequence_output, encoder_hidden = encoder(encoder_input)
decoder_input = tf.convert_to_tensor([hindi_word_index['sentencestart']])
decoder_hidden = encoder_hidden
sentence_end_word_id = hindi_word_index['sentenceend']
hindi_sequence = []
for i in range(MAX_WORDS_IN_A_SENTENCE*2):
predicted_words_probability, decoder_hidden, _ = decoder(decoder_input, decoder_hidden, encoder_sequence_output)
# taking the word with maximum probability
predicted_word_id = tf.argmax(predicted_words_probability[0]).numpy()
hindi_sequence.append(predicted_word_id)
# if the word 'sentenceend' is predicted, exit the loop
if predicted_word_id == sentence_end_word_id:
break
decoder_input = tf.convert_to_tensor([predicted_word_id])
print(sentence)
return get_sentence_from_sequences([hindi_sequence], hindi_tokenizer)
# print translated sentence
print(translate_sentence("Try multiple sentences here to check how good model is working!"))
结果
我们来看看结果。我运行的代码与NVidia K80 GPU Kaggle,在上面的代码。100个epoch,需要70分钟的训练。损失与epoch图如下所示。
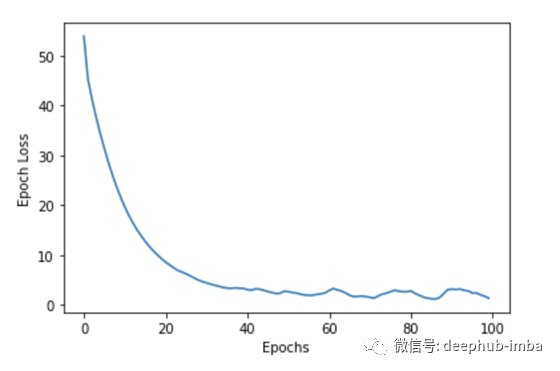
经过35个epoch的训练后,我尝试向我们的translate_sentence()函数中添加随机的英语句子,结果有些令人满意,但也有一定的问题。显然,可以对超参数进行更多的优化。
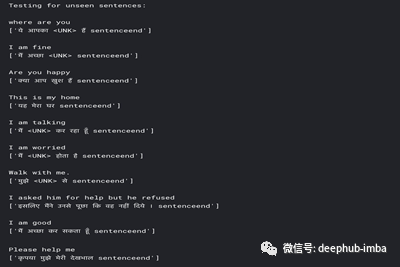
但是在这里,超参数并不是与实际翻译有一些偏差的唯一原因。让我们对更多可以实现以使我们的模型运行得更好的点进行小讨论。
可能的改进
在实现我们的模型时,我们已经对编码器、解码器和注意力机制有了非常基本的了解。根据可用的时间和计算能力,以下是一些点,可以尝试和测试,以知道如果他们工作时,实施良好:
使用堆叠GRU编码器和解码器
使用不同形式的注意力机制
使用不同的优化器
增加数据集的大小
采用Beam Search代替Greedy decoding
我们现在所使用的的解码器被称作贪婪解码(Greedy decoding)。我们假设概率最高的单词是最终预测的单词,并输入到下一个解码器状态。这种方法的问题是没有办法撤销这个动作。Beam Search解码从单词概率分布中考虑最高k个可能的单词,并检查所有的可能性,我们会在明天的文章中介绍Beam Search。
资源引用
- https://arxiv.org/abs/1409.3215 Original paper for Sequence to sequence Architecture without Attention
- https://arxiv.org/abs/1409.0473 Original paper for Sequence to sequence Architecture with Attention
- Dataset: https://www.kaggle.com/aiswaryaramachandran/hindienglish-corpora
- Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 8 — Translation, Seq2Seq, Attention
- https://www.tensorflow.org/tutorials/text/nmt_with_attention
作者:Ayush Jain
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********