
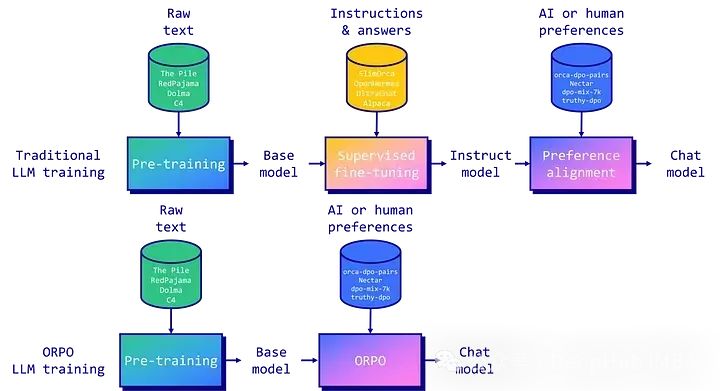
ORPO是一种新的微调技术,它将传统的监督微调和偏好对齐阶段结合到一个过程中。减少了训练所需的计算资源和时间。论文的实证结果表明,ORPO在各种模型大小和基准上都优于其他对齐方法,所以这次我们就来使用最新的Llama 3来测试下ORPO的效果。

我们将使用ORPO和TRL库对新的Llama 3 8b模型进行微调。
ORPO
指令调优和偏好对齐是使大型语言模型(llm)适应特定任务的基本技术。这涉及一个多阶段的过程:1、监督微调(SFT)指令,使模型适应目标领域;2、偏好校准,如人类反馈强化学习(RLHF)或直接偏好优化(DPO),增加产生首选响应的可能性。
虽然SFT有效地使模型适应所需的领域,但它无意中增加了生成不希望的答案和首选答案的概率。这就是为什么需要第二阶段的偏好校准,通过偏好校准,可以扩大偏好输出和拒绝输出的可能性之间的差距。
ORPO通过将指令调优和偏好对齐结合到一个单一的整体训练过程中,为该问题提供了一个优雅的解决方案。ORPO修改了标准语言建模目标,将负对数似然损失与比值比(OR)项结合起来。这种OR损失会对被拒绝的反应进行弱惩罚,而对偏好的反应进行强奖励,从而允许模型同时学习目标任务并与人类偏好保持一致。
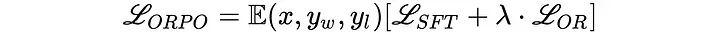
更具体的ORPO介绍,可以看我们前几天发布的文章:
目前ORPO已经在主要的微调库中实现,比如TRL、Axolotl和LLaMA-Factory,所以我们可以直接就拿来用
ORPO微调Llama 3
Llama 3已经发布了两种模型大小:700亿参数模型和较小的80亿参数模型。70B模型在MMLU基准测试中得分82分,在HumanEval基准测试中得分81.7分,可以说是相当不错的。
并且Llama 3模型还将上下文长度增加到8,192个令牌(Llama 2为4,096个),并可以使用RoPE扩展到32k。模型还使用了具有128k词表的,参数从7B到8B参数的增加,基本上就是词表数量的增加。
要使用ORPO需要一个偏好数据集,包括提示、选择的答案和拒绝的答案。
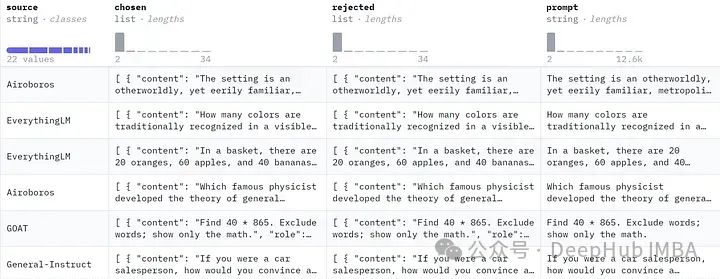
我们将使用mlabonne/orpo-dpo-mix-40k,因为他是以下高质量DPO数据集的组合:
argilla/distilabel-capybara-dpo-7k-binarized: highly scored chosen answers >=5 (2,882 samples)
argilla/distilabel-intel-orca-dpo-pairs: highly scored chosen answers >=9, not in GSM8K (2,299 samples)
argilla/ultrafeedback-binarized-preferences-cleaned: highly scored chosen answers >=5 (22,799 samples)
argilla/distilabel-math-preference-dpo: highly scored chosen answers >=9 (2,181 samples)
unalignment/toxic-dpo-v0.2 (541 samples)
M4-ai/prm_dpo_pairs_cleaned (7,958 samples)
jondurbin/truthy-dpo-v0.1 (1,016 samples)
首先我们安装依赖
pip install -U transformers datasets accelerate peft trl bitsandbytes wandb
安装完成后,我们可以导入必要的库并登录WB(可选):
import gc
import os
import torch
import wandb
from datasets import load_dataset
from google.colab import userdata
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
)
from trl import ORPOConfig, ORPOTrainer, setup_chat_format
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
如果你有一个最新的GPU,可以使用Flash Attention 库取代默认的eager注意力,因为它效率更高,所以我们直接使用下面代码来进行判断,支持的话就是用Flash Attention,不支持就用默认的。
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float16
然后我们使用bitsandbytes,以4位精度加载Llama 38 8B模型,使用QLoRA来作为 PEFT的方法。然后调用setup_chat_format()函数来修改模型和标记器让其支持ChatML。这个函数会自动应用聊天模板,添加特殊的标记,并调整模型嵌入层的大小以匹配新的词汇表大小。
# Model
base_model = "meta-llama/Meta-Llama-3-8B"
new_model = "OrpoLlama-3-8B"
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = prepare_model_for_kbit_training(model)
通过上面的设置,模型已经准备好进行训练了,加载mlabonne/orpo-dpo-mix-40k,并使用apply_chat_template()函数将“选中”和“拒绝”列转换为ChatML格式。为了方便演示只使用了1000个样本,而不是整个数据集,因为运行它需要很长时间。
dataset_name = "mlabonne/orpo-dpo-mix-40k"
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=42).select(range(10))
def format_chat_template(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= os.cpu_count(),
)
dataset = dataset.train_test_split(test_size=0.01)
最后我们设置超参数:
learning_rate:与传统的SFT甚至DPO相比,ORPO的学习率非常低。这个8e-6的值来源于原文,大致对应的SFT学习率为1e-5, DPO学习率为5e-6。但是可以试试将它增加到1e-6左右。
beta:它是本文中的\lambda参数,默认值为0.1。原始论文的附录显示了它是如何在消融研究中被选择的。
其他参数,如max_length和批处理大小被设置为使用尽可能多的VRAM(我们目前的配置中约为占用20 GB,如果你是4090,建议使用我们的配置)。
orpo_args = ORPOConfig(
learning_rate=8e-6,
beta=0.1,
lr_scheduler_type="linear",
max_length=1024,
max_prompt_length=512,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
report_to="wandb",
output_dir="./results/",
)
最后使用ORPOTrainer训练模型
trainer = ORPOTrainer(
model=model,
args=orpo_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(new_model)
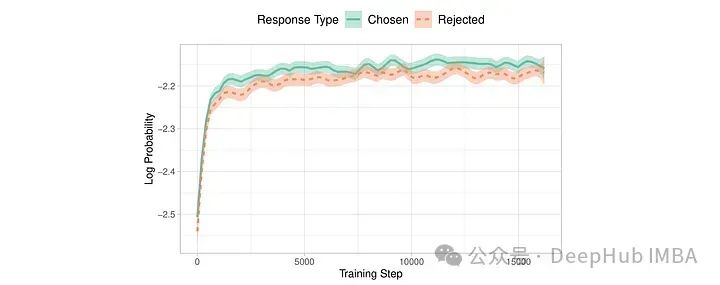
训练结果如下:
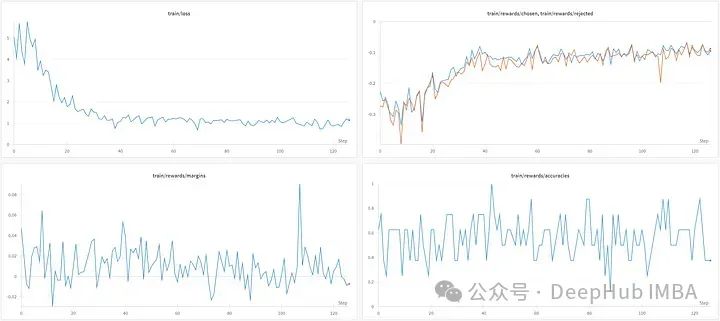
虽然损失有所下降,但被选中和被拒绝的答案之间的差异并不明显:平均差值和准确率分别略高于零和0.5。
在最初的论文中,作者在Anthropic/hh-rlhf数据集(161k样本)上训练了10个epoch,我们只训练了1个epoch,作者也尝试了lama 3,并分享了他们的日志(我们最后提供地址)。
作为训练的最后部分,还需要将QLoRA适配器与基本模型合并,
# Flush memory
del trainer, model
gc.collect()
torch.cuda.empty_cache()
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)
model, tokenizer = setup_chat_format(model, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(model, new_model)
model = model.merge_and_unload()
这样,我们就完成了Llama 3的快速微调,最后还我使用LLM AutoEval进行了一些评估。
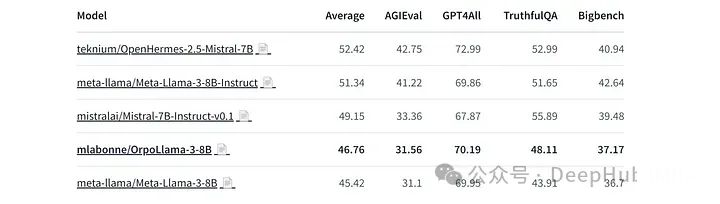
可以看到,虽然我们只是用了1000条数据,并且只运行了一个epoch,但是在每个基准测试中都提高了基本模型的性能。如果对整个40k个样本进行微调将应该能产生很好的结果。
总结
在本文中,我们介绍了ORPO算法然后使用TRL对自定义偏好数据集上的Llama 38b模型进行微调。最后的模型得到了不错的结果,这可以说明ORPO作为一种新的微调范式还是可以使用的。
本文代码:
https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi?usp=sharing
orpo作者微调Llama 3的log
https://huggingface.co/orpo-explorers/hf-llama3-8b-orpo-v0.0/tensorboard
作者:Maxime Labonne