
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
- 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。
- 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。
- 3、Flik Table API和SQL基础系列 本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。
- 4、Flik Table API和SQL提高与应用系列 本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。
- 5、Flink 监控系列 本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
本文介绍了Flink checkpoint中的配置、重启策略以及手动恢复的示例,其中包含详细的验证步骤与验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文依赖hadoop环境、kafka环境、flink集群环境好用。
本专题分为以下几篇文章:
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(2) -重启策略与手动恢复
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例 - 完整版
关于Flink checkpoint的更多介绍参考文章:
9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
一、Checkpoint配置
Flink 中的每个方法或算子都能够是有状态的。
状态化的方法在处理单个 元素/事件 的时候存储数据,让状态成为使各个类型的算子更加精细的重要部分。
为了让状态容错,Flink 需要为状态添加 checkpoint(检查点)。Checkpoint 使得 Flink 能够恢复状态和在流中的位置,从而向应用提供和无故障执行时一样的语义。
1、开启与配置 Checkpoint
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
Checkpoint 其他的属性包括:
- 精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中传入一个模式来选择使用两种保证等级中的哪一种。 对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。
- checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。
- checkpoints 之间的最小时间:该属性定义在 checkpoint 之间需要多久的时间,以确保流应用在 checkpoint 之间有足够的进展。如果值设置为了 5000, 无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。 注意这个值也意味着并发 checkpoint 的数目是1。
- 并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。 该选项不能和 “checkpoints 间的最小时间”同时使用。
- externalized checkpoints: 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。 这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。更多的细节请看 Externalized checkpoints 的部署文档。
- 在 checkpoint 出错时使 task 失败或者继续进行 task:他决定了在 task checkpoint 的过程中发生错误时,是否使 task 也失败,使失败是默认的行为。 或者禁用它时,这个任务将会简单的把 checkpoint 错误信息报告给 checkpoint coordinator 并继续运行。
- 优先从 checkpoint 恢复(prefer checkpoint for recovery):该属性确定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,这可以潜在地减少恢复时间(checkpoint 恢复比 savepoint 恢复更快)。
- 代码示例
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);// 高级选项:// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 开启实验性的 unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
2、选择 State Backend
Flink 的 checkpointing 机制 会将 timer 以及 stateful 的 operator 进行快照,然后存储下来, 包括连接器(connectors),窗口(windows)以及任何用户自定义的状态。 Checkpoint 存储在哪里取决于所配置的 State Backend(比如 JobManager memory、 file system、 database)。
默认情况下,状态是保持在 TaskManagers 的内存中,checkpoint 保存在 JobManager 的内存中。为了合适地持久化大体量状态, Flink 支持各种各样的途径去存储 checkpoint 状态到其他的 state backends 上。通过 StreamExecutionEnvironment.setStateBackend(…) 来配置所选的 state backends。
State Backend分为三类,即FsStateBackend、MemoryStateBackend和RocksDBStateBackend。
- MemoryStateBackend,构造方法是设置最大的StateSize,选择是否做异步快照。 推荐使用的场景为本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。
- FsStateBackend是在文件系统上,需要传一个文件路径和是否异步快照。 推荐使用的场景为常规使用状态的作业,例如分钟级窗口聚合或 join、需要开启HA的作业。
- RocksDBStateBackend,RocksDB 是先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。 推荐使用的场景为超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
RocksDBStateBackend在编码时需要额外引入maven依赖。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
3、迭代作业中的状态和 checkpoint
Flink 现在为没有迭代(iterations)的作业提供一致性的处理保证。在迭代作业上开启 checkpoint 会导致异常。
为了在迭代程序中强制进行 checkpoint,用户需要在开启 checkpoint 时设置一个特殊的标志:
env.enableCheckpointing(interval,CheckpointingMode.EXACTLY_ONCE, force =true);
4、Task 故障恢复
当 Task 发生故障时,Flink 需要重启出错的 Task 以及其他受到影响的 Task ,以使得作业恢复到正常执行状态。
Flink 通过重启策略和故障恢复策略来控制 Task 重启,重启策略决定是否可以重启以及重启的间隔;故障恢复策略决定哪些 Task 需要重启。
1)、重启策略Restart Strategies
Flink 支持不同的重启策略,来控制 job 万一故障时该如何重启。
Flink 作业如果没有定义重启策略,则会遵循集群启动时加载的默认重启策略。 如果提交作业时设置了重启策略,该策略将覆盖掉集群的默认策略。
通过 Flink 的配置文件 flink-conf.yaml 来设置默认的重启策略。配置参数 restart-strategy 定义了采取何种策略。 如果没有启用 checkpoint,就采用“不重启”策略。如果启用了 checkpoint 且没有配置重启策略,那么就采用固定延时重启策略, 此时最大尝试重启次数由 Integer.MAX_VALUE 参数设置。下表列出了可用的重启策略和与其对应的配置值。
每个重启策略都有自己的一组配置参数来控制其行为。 这些参数也在配置文件中设置。 后文的描述中会详细介绍每种重启策略的配置项。
除了定义默认的重启策略以外,还可以为每个 Flink 作业单独定义重启策略。 这个重启策略通过在程序中的 ExecutionEnvironment 对象上调用 setRestartStrategy 方法来设置。 当然,对于 StreamExecutionEnvironment 也同样适用。
下例展示了如何给我们的作业设置固定延时重启策略。 如果发生故障,系统会重启作业 3 次,每两次连续的重启尝试之间等待 10 秒钟。
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,// 尝试重启的次数Time.of(10,TimeUnit.SECONDS)// 延时));
1、Fixed Delay Restart Strategy
固定延时重启策略按照给定的次数尝试重启作业。 如果尝试超过了给定的最大次数,作业将最终失败。 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间。
通过在 flink-conf.yaml 中设置如下配置参数,默认启用此策略。
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts:3restart-strategy.fixed-delay.delay: 10 s
固定延迟重启策略也可以在程序中设置:
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,// 尝试重启的次数Time.of(10,TimeUnit.SECONDS)// 延时));
2、Failure Rate Restart Strategy
故障率重启策略在故障发生之后重启作业,但是当故障率(每个时间间隔发生故障的次数)超过设定的限制时,作业会最终失败。 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间。
通过在 flink-conf.yaml 中设置如下配置参数,默认启用此策略。
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval:3restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
故障率重启策略也可以在程序中设置:
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,// 每个时间间隔的最大故障次数Time.of(5,TimeUnit.MINUTES),// 测量故障率的时间间隔Time.of(10,TimeUnit.SECONDS)// 延时));
3、No Restart Strategy
作业直接失败,不尝试重启。
通过在 flink-conf.yaml 中设置如下配置参数
restart-strategy: none
在程序中设置
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
4、Fallback Restart Strategy
使用群集定义的重启策略。 这对于启用了 checkpoint 的流处理程序很有帮助。 如果没有定义其他重启策略,默认选择固定延时重启策略。
2)、Failover Strategies
Flink 支持多种不同的故障恢复策略,该策略需要通过 Flink 配置文件 flink-conf.yaml 中的 jobmanager.execution.failover-strategy 配置项进行配置。
1、Restart All Failover Strategy
在全图重启故障恢复策略下,Task 发生故障时会重启作业中的所有 Task 进行故障恢复。
2、Restart Pipelined Region Failover Strategy
该策略会将作业中的所有 Task 划分为数个 Region。当有 Task 发生故障时,它会尝试找出进行故障恢复需要重启的最小 Region 集合。 相比于全局重启故障恢复策略,这种策略在一些场景下的故障恢复需要重启的 Task 会更少。
5、checkpoint的配置方式
一般而言有2种配置方式,即全局配置(配置在flink-conf.yaml文件中)和应用程序配置。其示例在上述的介绍中都有对应的说明。一般而言,推荐在应用程序中配置,除非flink集群是为某一个共性的应用创建的,此时配置文件可能更方便。
二、示例:程序中设置Checkpoint
本示例实现统计地铁站出站口人数,同时在程序中设置chenckpoint,将state存在hdfs中。
同时,本示例是将数据sink到kafka中,因flink在kafka的实现过程中出现不同的版本,故本示例给出了2个不同的版本实现。
1、maven依赖
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency>
2、java bean
packageorg.datastreamapi.checkpoint.bean;importlombok.AllArgsConstructor;importlombok.Data;importlombok.NoArgsConstructor;/**
* @author alanchan
*
*/@Data@AllArgsConstructor@NoArgsConstructorpublicclassSubway{privateString sNo;privateInteger userCount;privateLong enterTime;publicSubway(String sNo,Integer userCount){this.sNo = sNo;this.userCount = userCount;}}
3、自定义数据源
自动生成数据
importjava.util.Random;importorg.apache.commons.lang3.time.FastDateFormat;importorg.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;importorg.datastreamapi.checkpoint.bean.Subway;/**
* @author alanchan
*
*/publicclassSubwaySourceextendsRichParallelSourceFunction<Subway>{privateboolean flag =true;FastDateFormat df =FastDateFormat.getInstance("HH:mm:ss");@Overridepublicvoidrun(SourceContext<Subway> ctx)throwsException{Random random =newRandom();while(flag){String sNo ="No"+ random.nextInt(3);int userCount = random.nextInt(100);long eventTime =System.currentTimeMillis();Subway subway =newSubway(sNo, userCount, eventTime);System.err.println(subway +" ,格式化后时间 "+ df.format(subway.getEnterTime()));
ctx.collect(subway);Thread.sleep(1000);}}@Overridepublicvoidcancel(){
flag =false;}}
4、实现(Flink 1.13.6版本)
1)、序列化
- 示例string序列化,实际上已经系统实现了。
importorg.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;importorg.apache.kafka.clients.producer.ProducerRecord;/**
* @author alanchan
*
*/publicclassAlanKafkaSerializationSchema_StringimplementsKafkaSerializationSchema<String>{String topic;publicAlanKafkaSerializationSchema_String(String topic){this.topic = topic;}@OverridepublicProducerRecord<byte[],byte[]>serialize(String element,Long timestamp){returnnewProducerRecord(topic, element.getBytes());}}
- pojo 序列化
importorg.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.datastreamapi.checkpoint.bean.Subway;/**
* @author alanchan
* kafka序列化---传递对象
*/publicclassAlanKafkaSerializationSchema_PojoimplementsKafkaSerializationSchema<Subway>{String topic;publicAlanKafkaSerializationSchema_Pojo(String topic){this.topic = topic;}@OverridepublicProducerRecord<byte[],byte[]>serialize(Subway element,Long timestamp){returnnewProducerRecord(topic, element.toString().getBytes());}}
2)、实现
sink到kafka并state存储到hdfs上,以便能恢复数据。
maven可以用上述的内容,只是已经过期了。
packageorg.datastreamapi.checkpoint;importjava.util.Properties;importorg.apache.flink.api.common.RuntimeExecutionMode;importorg.apache.flink.runtime.state.filesystem.FsStateBackend;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.CheckpointConfig;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;importorg.datastreamapi.checkpoint.bean.Subway;importorg.datastreamapi.checkpoint.serialization.AlanKafkaSerializationSchema_Pojo;/**
* @author alanchan
*
*/publicclassTestCheckpointByKafkaSourceDemo{/**
* @param args
* @throws Exception
*/publicstaticvoidmain(String[] args)throwsException{System.setProperty("HADOOP_USER_NAME","alanchan");// envStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// Checkpoint参数设置// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(newFsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));// 设置两个Checkpoint 之间最少等待时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);// 默认是0// 当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// sourceDataStreamSource<Subway> subwayDS = env.addSource(newSubwaySource());// transformationDataStream<Subway> maxByResult = subwayDS.keyBy(subway -> subway.getSNo()).maxBy("userCount");// sinkString topic ="t_kafkasink";Properties props =newProperties();
props.setProperty("bootstrap.servers","server1:9092");// 使用EXACTLY_ONCE必须设置自动提交时间
props.setProperty("transaction.timeout.ms",1000*5+"");// FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), props);// 实现kafka传递的subway对象,需要自己实现序列化FlinkKafkaProducer<Subway> kafkaSink =newFlinkKafkaProducer<>(topic,newAlanKafkaSerializationSchema_Pojo(topic), props,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
maxByResult.addSink(kafkaSink);
maxByResult.print("maxBy");// execute
env.execute();}}
5、实现(Flink 1.17.0版本实现)
本示例实现需要的java bean和自定义数据源参考Flink 1.13.6版本中相应内容。
本处实现的不同的地方即是序列化和sink方法,验证方式一样,不再赘述。
1)、序列化
importorg.apache.flink.api.common.serialization.SerializationSchema;importorg.datastreamapi.checkpoint.bean.Subway;/**
* @author alanchan
*
*/publicclassKafkaValueSerializationSchema_PojoimplementsSerializationSchema<Subway>{@Overridepublicbyte[]serialize(Subway element){return element.toString().getBytes();}}
2)、实现
packageorg.datastreamapi.checkpoint;importorg.apache.flink.api.common.RuntimeExecutionMode;importorg.apache.flink.connector.base.DeliveryGuarantee;importorg.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;importorg.apache.flink.connector.kafka.sink.KafkaSink;importorg.apache.flink.runtime.state.filesystem.FsStateBackend;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.CheckpointConfig;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.datastreamapi.checkpoint.bean.Subway;importorg.datastreamapi.checkpoint.serialization.KafkaValueSerializationSchema_Pojo;importorg.apache.flink.streaming.util.serialization.SimpleStringSchema;/**
* @author alanchan
*
*/publicclassTestCheckpointByKafkaSourceDemo2{/**
* @param args
*/publicstaticvoidmain(String[] args)throwsException{System.setProperty("HADOOP_USER_NAME","alanchan");// envStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// Checkpoint参数设置// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(newFsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));// 设置两个Checkpoint 之间最少等待时间
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);// 默认是0// 当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// sourceDataStreamSource<Subway> subwayDS = env.addSource(newSubwaySource());// transformationDataStream<Subway> maxByResult = subwayDS.keyBy(subway -> subway.getSNo()).maxBy("userCount");// sinkString topic ="t_kafkasink";KafkaSink<Subway> kafkaSink =KafkaSink.<Subway>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(newKafkaValueSerializationSchema_Pojo()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();
maxByResult.print("maxBy");
maxByResult.sinkTo(kafkaSink);// execute
env.execute();}}
6、验证
此处验证分为三个部分,即应用程序控制台输出、kafka输出和hdfs上的checkpoint。
虽然实现有两种版本的不同,但结果一样,故只列出一种实现结果的验证。
- 应用程序控制台输出
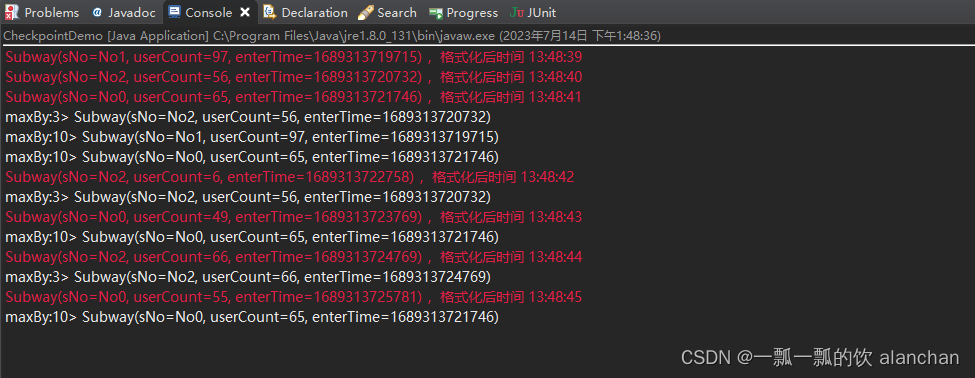
- kafka输出
[root@server1~]# kafka-console-consumer.sh --bootstrap-server server1:9092--topic t_kafkasink --from-beginning
Subway(sNo=No1, userCount=97, enterTime=1689313719715)Subway(sNo=No2, userCount=66, enterTime=1689313724769)Subway(sNo=No1, userCount=97, enterTime=1689313719715)Subway(sNo=No2, userCount=66, enterTime=1689313724769)Subway(sNo=No0, userCount=83, enterTime=1689313731841)Subway(sNo=No0, userCount=83, enterTime=1689313731841)
- hdfs上的checkpoint
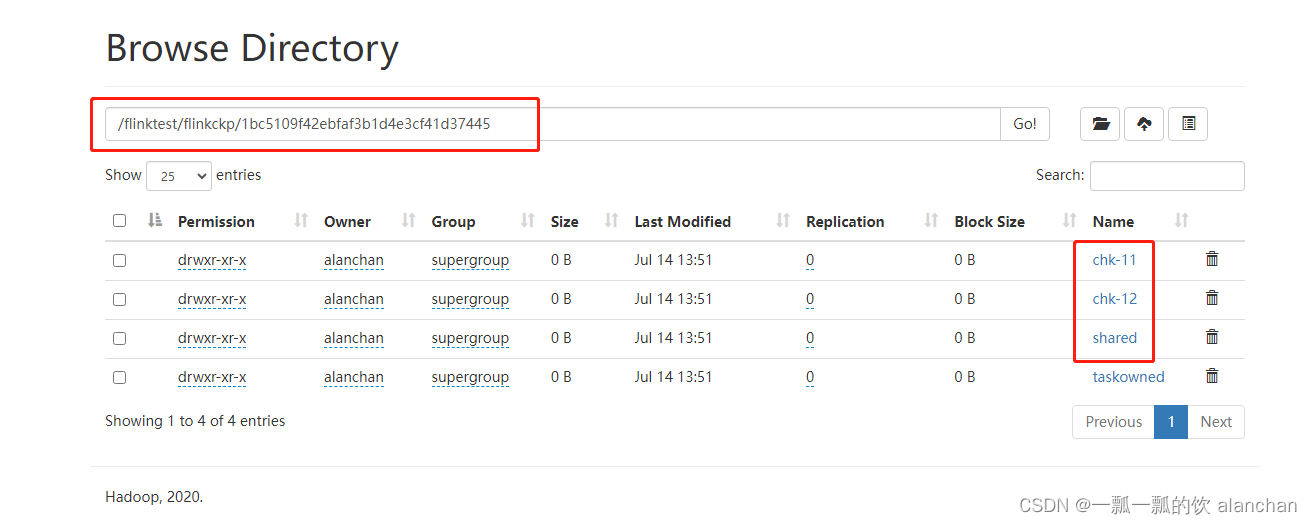
三、示例:程序中设置重启策略
本示例是将数据sink到kafka中,因flink在kafka的实现过程中出现不同的版本,故本示例给出了2个不同的版本实现。
1、演示代码
该代码包含四种重启策略,根据自己的情况进行验证即可。
本示例着重验证了固定次数重启策略。
2、maven依赖
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency>
3、实现(Flink 1.13.6版本)
1)、序列化
packageorg.datastreamapi.checkpoint.serialization;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;importorg.apache.kafka.clients.producer.ProducerRecord;/**
* @author alanchan
*
*//**
* kafka sink tuple的序列化实现
*
* @author alanchan
*
*/publicclassAlanKafkaSerializationSchema_TupleimplementsKafkaSerializationSchema<Tuple2<String,Integer>>{String topic;publicAlanKafkaSerializationSchema_Tuple(String topic){this.topic = topic;}@OverridepublicProducerRecord<byte[],byte[]>serialize(Tuple2<String,Integer> element,Long timestamp){returnnewProducerRecord(topic,(element.f0 +":"+ element.f1).getBytes());}}
2)、实现
packageorg.datastreamapi.checkpoint;importjava.util.Properties;importjava.util.concurrent.TimeUnit;importorg.apache.flink.api.common.RuntimeExecutionMode;importorg.apache.flink.api.common.functions.FlatMapFunction;importorg.apache.flink.api.common.restartstrategy.RestartStrategies;importorg.apache.flink.api.common.time.Time;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.runtime.state.filesystem.FsStateBackend;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.CheckpointConfig;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;importorg.apache.flink.util.Collector;importorg.datastreamapi.checkpoint.serialization.AlanKafkaSerializationSchema_Tuple;/**
* @author alanchan
*
*/publicclassTestCheckpointRestartStrategyDemo{publicstaticvoidmain(String[] args)throwsException{System.setProperty("HADOOP_USER_NAME","alanchan");StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(newFsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 配置重启策略:// 1、配置了Checkpoint的情况下,默认是Integer.MAX_VALUE次重启并自动恢复// 2、单独配置无重启策略RestartStrategies.noRestart()// 3、固定延迟重启RestartStrategies.fixedDelayRestart
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,// 最多重启3次数Time.of(5,TimeUnit.SECONDS)// 重启时间间隔));// 4、失败率重启策略RestartStrategies.failureRateRestart// 如果2分钟内job失败不超过3三次,,自动重启,, 每次间隔10s (如果2分钟内程序失败超过(含)3次,则程序退出)// env.setRestartStrategy(RestartStrategies.failureRateRestart(3, // 每个测量时间间隔最大失败次数// Time.of(2, TimeUnit.MINUTES), // 失败率测量的时间间隔// Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔// ));// SourceDataStream<String> linesDS = env.socketTextStream("192.168.10.42",9999);// TransformationDataStream<Tuple2<String,Integer>> wordTuple = linesDS.flatMap(newFlatMapFunction<String,Tuple2<String,Integer>>(){@OverridepublicvoidflatMap(String value,Collector<Tuple2<String,Integer>> out)throwsException{String[] words = value.split(",");for(String word : words){// vx:alanchanchnif(word.equals("vx:alanchanchn")){System.out.println("出现了敏感词。。。。。。。。。。不能出现微信号:alanchanchn。");thrownewException("出现了敏感词。。。。。。。。。。。不能出现微信号:alanchanchn。");}
out.collect(Tuple2.of(word,1));}}});DataStream<Tuple2<String,Integer>> sumResult = wordTuple.keyBy(t -> t.f0).sum(1);// sink
sumResult.print();Properties props =newProperties();
props.setProperty("bootstrap.servers","server1:9092");
props.setProperty("transaction.timeout.ms","3000");String topic ="t_kafkasink";// FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), props);FlinkKafkaProducer<Tuple2<String,Integer>> kafkaSink =newFlinkKafkaProducer<>(topic,newAlanKafkaSerializationSchema_Tuple(topic), props,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
sumResult.addSink(kafkaSink);// 5.execute
env.execute();}}
3)、验证
验证实际上分为3部分,即应用程序控制台、kafka输出和hdfs上的checkpoint。
由于本示例仅仅是为了演示重启策略,故其他的两个部分不再赘述。
5>(alanchan,1)5>(alanchanchn,1)5>(alanchan,2)13>(alan,1)5>(chan,1)11>(chn,1)
出现了敏感词。。。。。。。。。。不能出现微信号。
11>(chn,2)5>(alanchan,3)5>(alanchanchn,2)11>(chn,2)10>(vx:alanchanchn,1)5>(alanchan,3)5>(alanchanchn,2)
出现了敏感词。。。。。。。。。。不能出现微信号。
11>(chn,3)5>(alanchan,4)5>(alanchanchn,3)
出现了敏感词。。。。。。。。。。不能出现微信号。
出现了敏感词。。。。。。。。。。不能出现微信号。
5>(alanchan,4)11>(chn,3)5>(alanchanchn,3)
Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
# 应用程序出现了异常并退出
4、实现(Flink 1.17.0版本)
1)、序列化
packageorg.datastreamapi.checkpoint.serialization;importorg.apache.flink.api.common.serialization.SerializationSchema;importorg.apache.flink.api.java.tuple.Tuple2;/**
* @author alanchan
*
*/publicclassKafkaValueSerializationSchema_TupleimplementsSerializationSchema<Tuple2<String,Integer>>{@Overridepublicbyte[]serialize(Tuple2<String,Integer> element){return(element.f0 +":"+ element.f1).getBytes();}}
2)、实现
packageorg.datastreamapi.checkpoint;importjava.util.Properties;importjava.util.concurrent.TimeUnit;importorg.apache.flink.api.common.RuntimeExecutionMode;importorg.apache.flink.api.common.functions.FlatMapFunction;importorg.apache.flink.api.common.restartstrategy.RestartStrategies;importorg.apache.flink.api.common.time.Time;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.connector.base.DeliveryGuarantee;importorg.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;importorg.apache.flink.connector.kafka.sink.KafkaSink;importorg.apache.flink.runtime.state.filesystem.FsStateBackend;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.CheckpointConfig;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;importorg.apache.flink.util.Collector;importorg.datastreamapi.checkpoint.serialization.AlanKafkaSerializationSchema_Tuple;importorg.datastreamapi.checkpoint.serialization.KafkaValueSerializationSchema_Tuple;/**
* @author alanchan
*
*/publicclassTestCheckpointRestartStrategyDemo2{/**
* @param args
* @throws Exception
*/publicstaticvoidmain(String[] args)throwsException{System.setProperty("HADOOP_USER_NAME","alanchan");StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(newFsStateBackend("hdfs://server1:8020//flinktest/flinkckp"));
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,// 最多重启3次数Time.of(5,TimeUnit.SECONDS)// 重启时间间隔));// SourceDataStream<String> linesDS = env.socketTextStream("192.168.10.42",9999);// TransformationDataStream<Tuple2<String,Integer>> wordTuple = linesDS.flatMap(newFlatMapFunction<String,Tuple2<String,Integer>>(){@OverridepublicvoidflatMap(String value,Collector<Tuple2<String,Integer>> out)throwsException{String[] words = value.split(",");for(String word : words){// vx:alanchanchnif(word.equals("vx:alanchanchn")){System.out.println("出现了敏感词。。。。。。。。。。不能出现微信号:alanchanchn。");thrownewException("出现了敏感词。。。。。。。。。。。不能出现微信号:alanchanchn。");}
out.collect(Tuple2.of(word,1));}}});DataStream<Tuple2<String,Integer>> sumResult = wordTuple.keyBy(t -> t.f0).sum(1);// sink
sumResult.print();String topic ="t_kafkasink";KafkaSink<Tuple2<String,Integer>> kafkaSink =KafkaSink.<Tuple2<String,Integer>>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic(topic).setValueSerializationSchema(newKafkaValueSerializationSchema_Tuple()).build()).setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();
sumResult.sinkTo(kafkaSink);// 5.execute
env.execute();}}
3)、验证
略。参考Flink 1.13.6版本验证内容。
四、示例:手动重启-检验checkpoint
使用【三、示例:程序中设置重启策略】的例子,将该应用程序打包并上传至flink集群。
关于maven打包以及Flink集群提交任务参考该专栏的文章。1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
1、maven打包
mvn package-Dmaven.test.skip=true
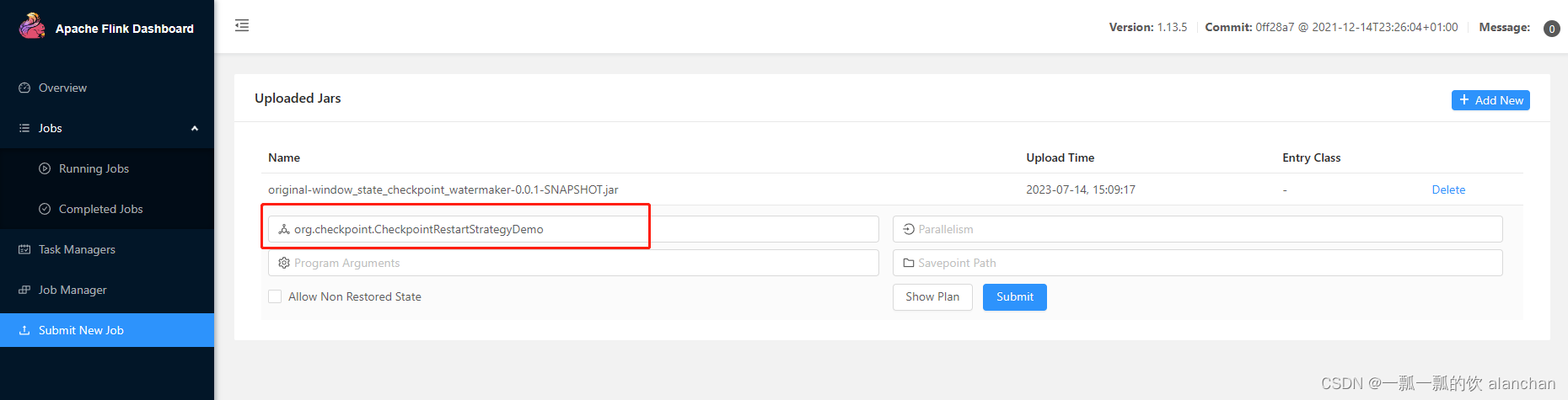
2、上传打包后的jar
上传成功后的界面,并设置运行主类,即main函数所在的类
上传成功后,任务处于运行状态

3、验证程序功能
验证方式与上面在开发工具中验证一致,即在nc中输入数据,观察kafka中的输出。
验证关键点:是否自动重启了
- 输入数据
[root@server2~]# nc -lk 9999
aa,
bb,aa
cc,bb,aa,a
dd
aa
cc
- kafka控制台输出
aa:1
bb:1
aa:2
dd:1
aa:3
cc:1
aa:4
bb:2
4、手工恢复
在恢复点填入checkpoint对应的文件进行恢复。
本示例的地址为:hdfs://server2:8020/flinktest/flinkckp/0f93e35e25c3fb87ee8ce3d6393d6344/chk-129

填写完毕后提交任务,成功后进入如下页面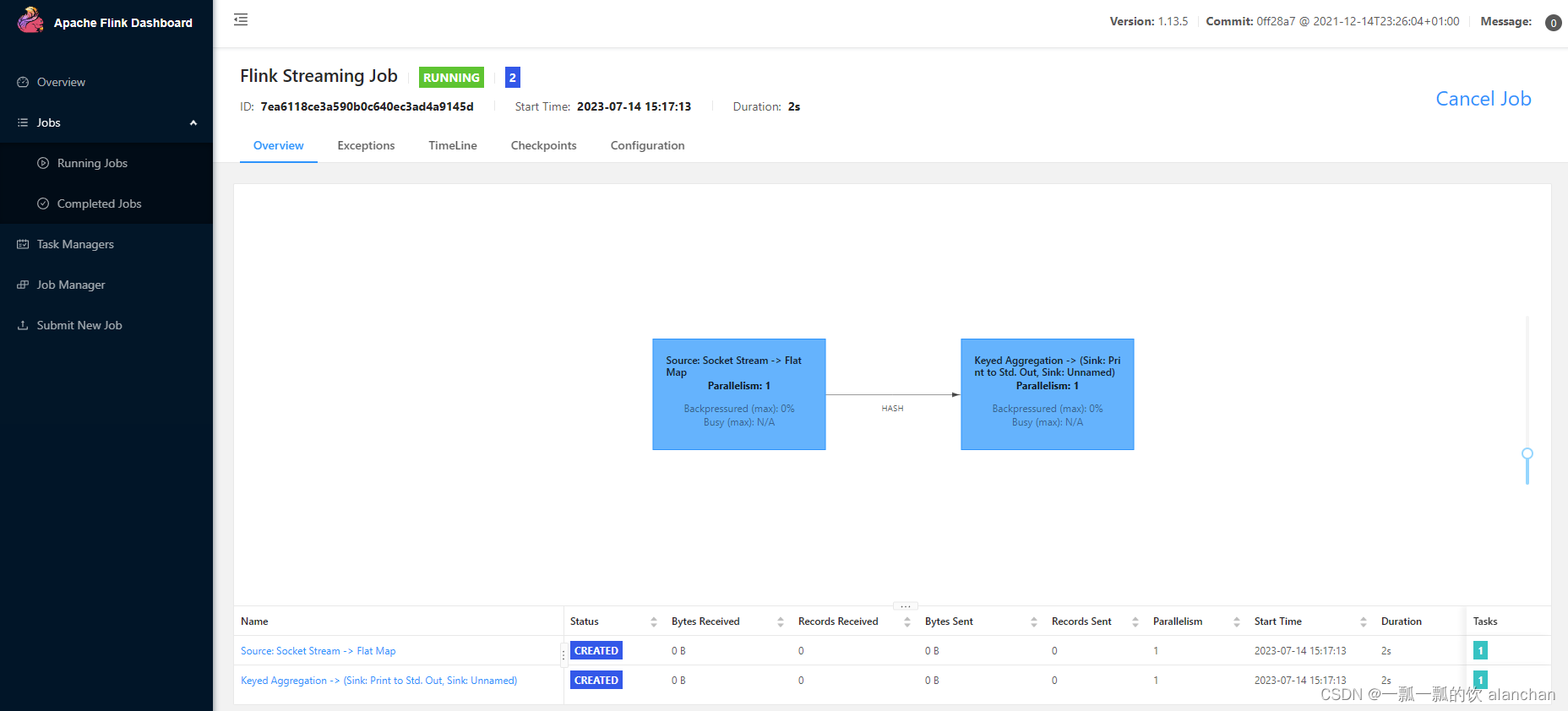
5、验证
再次验证,即关键之前计算的结果是否存在以及输入相同的键值,是否在原来的基础上累加。
- nc输入
[root@server2~]# nc -lk 9999
dd
bb
aa
a
- kafka控制台输出
dd:2
aa:4
bb:3
cc:2
以上完成了checkpoint的手工启动验证,实际生产中可能是系统自动完成的,不需要人工启动。如因非程序原因需要自动启动的话,比如系统重启等外界因素,一般使用手工的启动,人为的设置savepoint。
下面一节将介绍savepoint部分。
五、示例:通过savepoint手动恢复
在实际生产中,如要对集群进行停机维护/扩容…那么这时候需要执行一次Savepoint也就是执行一次手动的Checkpoint(也就是手动的发一个barrier栅栏),程序的所有状态都会被执行快照并保存,当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复。
本示例以flink提交任务的session模式进行演示
# 启动yarn session
/usr/local/flink-1.13.5/bin/yarn-session.sh -n2-tm1024-s1-d# 运行job-会自动执行Checkpoint
/usr/local/flink-1.13.5/bin/flink run --class org.checkpoint.CheckpointRestartStrategyDemo /usr/local/bigdata/testdata/original-window_state_checkpoint_watermaker-0.0.1-SNAPSHOT.jar
# 手动创建savepoint--相当于手动做了一次Checkpoint# 225125bc4ddf3f69190ebcb8e82e428f是当前任务的id
/usr/local/flink-1.13.5/bin/flink savepoint 225125bc4ddf3f69190ebcb8e82e428f hdfs://server1:8020//flinktest/flinkckp
# 停止job
/usr/local/flink-1.13.5/bin/flink cancel 225125bc4ddf3f69190ebcb8e82e428f
# 重新启动job,手动加载savepoint数据# savepoint-702b87-0a11b997fa70 是创建savepoint时系统自动生成的checkpoint文件名称
/usr/local/flink-1.13.5/bin/flink run -s hdfs://server1:8020/flinktest/savepoint/savepoint-702b87-0a11b997fa70 --class org.checkpoint.CheckpointRestartStrategyDemo /usr/local/bigdata/testdata/original-window_state_checkpoint_watermaker-0.0.1-SNAPSHOT.jar
# 停止yarn session# 关闭方式很多,比如kill或界面上中止等
以上,本文介绍了Flink checkpoint中的配置、重启策略以及手动恢复的示例,其中包含详细的验证步骤与验证结果。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(1) - checkpoint配置及实现
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例(2) -重启策略与手动恢复
【flink番外篇】8、flink的Checkpoint容错机制(配置、重启策略、手动恢复)介绍及示例 - 完整版
版权归原作者 一瓢一瓢的饮 alanchanchn 所有, 如有侵权,请联系我们删除。