

文章目录
1.存储结构
要想学会使用 ES,完成对 ES 的增删改查,必须先了解一下 ES 的存储结构。
大家对 MySQL 的存储结构应该是很清楚的,所以咱们在学习 ES 存储结构时,同时类比 MySQL,这样理解起来会更透彻。MySQL 的数据模型由数据库、表、字段、字段类型组成,自然 ES 也有自己的一套存储结构。
ES 与 MySQL 存储结构的对应关系。
ES存储结构MySQL存储结构Index数据库Type(7.x已废弃)表Document行Field表字段Mapping表结构定义DSLSQL乐观锁(version)事物
1.1 index
索引(index)类似 MySQL 的表,是文档(document)的集合。文档是 ES 中存储的一条数据,下面会详细介绍。
1.2 type
type 为文档类型,不过在 ES 7.0 以后的版本 已经废弃文档类型了,一个 index 中只有一个默认的 type,即 _doc。在 ES 老版本中文档类型代表一类文档的集合,index 类似 MySQL 的数据库,文档类型类似 MySQL 的表。既然 ES 新版本文档类型没什么作用了,那么 index(索引)就类似 MySQL 表的概念,ES 没有数据库的概念了。
1.3 document
ES 是面向文档的数据库,文档是 ES 存储的最基本的存储单元,文档类似 MySQL 表中的一行数据。在 ES 中,文档使用 JSON 格式存储,因此存储上要比 MySQL 灵活很多,因为 ES 支持任意格式的 JSON 数据。
{"_index":"order","_type":"_doc","_id":"1","_version":2,"_seq_no":1,"_primary_term":1,"found":true,"_source":{"id":10000,"status":0,"total_price":10000,"create_time":"2020-09-06 17:30:22","user":{"id":10000,"username":"asong2020","phone":"888888888","address":"深圳人才区"}}}
其中 _source 为记录的具体内容,其他字段为文档的元数据,是插入 JSON 记录时 ES 自动生成的系统字段,二者共同组成一个 document。
常用的元数据有:
- _index:代表当前文档所属索引
- _type:代表当前文档所属类型(ES 7.0 以后废弃了 type 用法,但是元数据还是可以看到的)
- _id:文档唯一 ID,如果没有为文档指定 ID 则自动生成。
- _source:文档的原始 JSON 数据
- _version:文档的版本号,每修改一次文档,字段就会加 1,这个字段新版 ES 也给取消了
- _seq_no:文档编号,每修改一次文档,字段就会加 1,替代老的 version。注意 seq_no 递增属于整个 index,而不是单个文档
- _primary_term:文档所在主分区,这个可以跟 seq_no 搭配实现乐观锁并发控制,以防止旧版本的文档覆盖较新的文档
1.4 field
文档由多个 JSON 字段组成,字段跟 MySQL 中表的字段类似,常用字段类型有:
- binary:编码为Base64字符串的二进制值
- boolean:布尔类型
- Keywords:关键词族,不支持全文搜索。具体包括 keyword, constant_keyword 和 wildcard
- Numbers:数值类型,包括 long、integer、short、byte、double、float、half_float、scaled_float、unsigned_long
- Dates:日期类型,包括 date 和 date_nanos
- text 文本类型,支持全文搜索
- alias:为现有字段的别名
关于字符串常用的有两种类型 text 和 keyword。
关于 text:
- 索引全文值的字段,例如电子邮件正文或产品描述。
- 纯 text 字段默认无法进行排序或聚合。
- 使用text字段一定要使用合理的分词器。
- 如果您需要索引结构化内容,例如电子邮件地址、主机名、状态代码或标签,您可能应该使用 keyword 字段。
- 出于不同目的,我们期望以不同方式索引同一字段,这就是 multi-fields 。
例如,可以将 string 字段映射为用于全文搜索的 text 字段,并映射为用于排序或聚合的 keyword 字段:
PUT my_index
{"mappings":{"properties":{"name":{"type":"text",
"fields":{"raw":{"type":"keyword"}}}}}}
关于 keyword:
- 用于索引结构化内容的字段,例如 ID、电子邮件地址、主机名、状态代码、邮政编码或标签。如果您需要索引全文内容,例如电子邮件正文或产品描述,你应该使用 text 字段。
- 它们通常用于过滤(查找所有发布状态的博客文章)、排序和聚合。 keyword 字段只能精确匹配。
关于数组类型:
这里也特别说明一下。在 ElasticSearch 中,没有专门的数组类型。默认情况下,任意一个字段都可以包含 0 或多个值,这意味着每个字段都可以变成数组。数组类型的各个元素类型必须相同。在 ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
更多类型请查阅 Elasticsearch Guide [8.0] » Mapping » Field data types。
1.5 mapping
mapping 类似于 MySQL 的表结构体定义,每个索引都有一个映射的规则,我们可以通过定义索引的映射规则,提前定义好文档的 JSON 结构和字段类型。如果没有定义索引的 mapping,ES 会在写入数据的时候,根据我们写入的数据字段推测出对应的字段类型,相当于自动定义索引的 mapping 。
limit
定义字段索引过多会导致爆炸的映射,这可能会导致内存不足错误和难以恢复的情况, mapping 提供了一些配置对 field 进行限制,下面列举几个可能会比较常见的:
- index.mapping.total_fields.limit
限制field的最大数量,默认值是1000(field和object内的所有字段,都会加入计数)。
- index.mapping.depth.limit
限制object的最大深度,默认值是20。
- index.mapping.field_name_length.limit
限制中字段名的长度,默认是没有限制。
dynamic
mapping 有一个很重要的属性 dynamic,控制是否动态添加新字段,并接受以下参数:
参数说明trueNew fields are added to the mapping (default).runtimeNew fields are added to the mapping as runtime fields. These fields are not indexed, and are loaded from _source at query time.falseNew fields are ignored. These fields will not be indexed or searchable, but will still appear in the _source field of returned hits. These fields will not be added to the mapping, and new fields must be added explicitly.strictIf new fields are detected, an exception is thrown and the document is rejected. New fields must be explicitly added to the mapping.
- dynamic 为 true 表示动态映射(dynamic mapping)。
true 为缺省值。添加的文档中如果有新增的字段,则 ES 会自动把新的字段添加到映射中。新增的字段可以被索引,也就是这个字段可以被搜索,mapping 同时也被更新。
- dynamic 为 false 表示静态(显式)映射(explicit mapping)。
当 ES 察觉到有新增字段时,会写入新字段,但不会索引新字段,即无法通过新字段进行查询。在有些情况下,静态映射依然不够,所以还需要更严谨的策略来进一步做限制。
- dynamic 为 strict 表示精确(严格)映射(strict mapping)。
表示字段需要严格匹配,新增字段写入将会报错。
一般静态映射用的较多。就像 HTML 的 img 标签一样,src 为自带的属性,你可以在需要的时候添加 id 或者 class 属性。当然,如果你非常了解你的数据,并且未来很长一段时间不会改变,strict 不失为一个好选择。
注意: 动态映射很方便,但是实际业务中,对于关键字段类型,通常预先定义好,这样可以避免 ES 自动生成不是你想要的字段类型。
2.其他重要概念
除了数据结构的相关概念,因 ES 是一个分布式支持水平扩展的数据库系统,必然少不了分布式相关的概念,这个最好也需要了解一下。
2.1 cluster
一个集群由一个或多个节点组成,它们共同持有数据,一起提供存储搜索功能。
集群由一个唯一的名字进行区分,默认为"elasticsearch",集群中的节点通过整个唯一的名字加入集群。
2.2 node
节点是 ES 集群的一部分,只要多个节点在同个网络中,节点就可以通过指定集群的名称加入其中,与集群中的其他节点相互感知。
和集群类似,一个节点也是由一个名字来标识的。节点的名称默认为一个随机的通用唯一标识符(UUID),在启动时分配给该节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于 ES 集群中的哪些节点。
一个集群由一个或多个 node 组成。在测试的环境中,我可以把多个 node 运行在一个 server 上。在实际的部署中,大多数情况还是需要一个 server 上运行一个 node。
根据 node 的作用,可以分为如下几种:
- master-eligible:可以作为主 node。一旦成为主 node,它可以管理整个 cluster 的设置及变化:创建,更新,删除 index;添加或删除 node;为 node 分配 shard
- data:数据 node
- ingest: 数据接入(比如 pipepline)
- machine learning (Gold/Platinum License)
- Coordinating node:严格来说,这个不是一个种类的节点。它甚至可以是上面的任何一种节点。这种节点通常是接受客户端的 HTTP 请求的。针对大的集群而言,通常的部署时使用一些专用的节点来接受客户端的请求。这样的节点可以不配置上面的任何角色,也就是它既不是 master,也不是 data,也不是 ingest,也不是 machine learning。
一般来说,一个 node 可以具有上面的一种或几种功能。我们可以在命令行或者 Elasticsearch 的配置文件(Elasticsearch.yml)来定义:
Node类型配置参数默认值master-eligiblenode.mastertruedatanode.datatrueingestnode.ingesttruemachinelearningnode.ml
你也可以让一个 node 做专有的功能及角色。如果上面 node 配置参数没有任何配置,那么我们可以认为这个 node 是作为一个 coordination node。在这种情况下,它可以接受外部的请求,并转发到相应的节点来处理。针对 master node,有时我们需要设置 cluster.remote.connect: false,这样它不可以作为跨集群搜索 (CCS:Cross-cluster search) 和跨集群复制 (CCR:Cross-cluster replication) 用途。
在实际的使用中,我们可以把请求发送给 data 节点,而不能发送给 master 节点。
我们可以通过对 config/elasticsearch.yml 文件中配置来定义一个 node 在集群中的角色:
在有些情况中,我们可以通过设置 node.voting_only 为 true 从而使得一个 node 在 node.master 为真的情况下,只作为参加 voting 的功能,而不当选为 master node。这种情况为了避免脑裂情况发生。它通常可以使用一个 CPU 性能较低的 node 来担当。
GET /_cluster/state?filter_path=metadata.cluster_coordination.last_committed_config
你可能获得类似如下列表的结果:
{"metadata":{"cluster_coordination":{"last_committed_config":["nm8Qd9HyQt2QF6ZxaAv1DA"]}}}
在整个 Elastic 的架构中,Data Node 和 Cluster 的关系表述如下: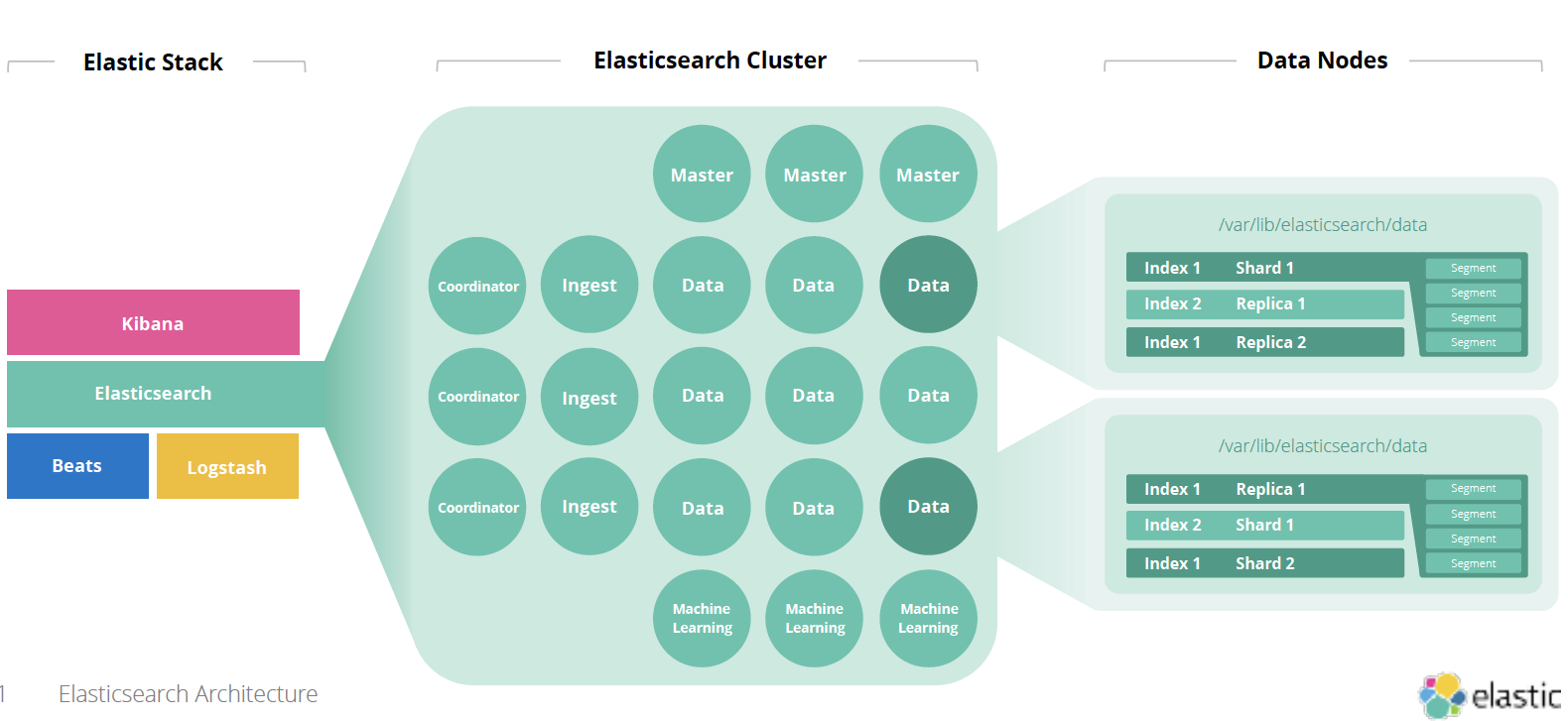
上面的定义适用于 Elastic Stack 7.9 发布版以前。在 Elastic Stack 7.9 之后,有了新的改进。请详细阅读文章 “Elasticsearch:Node roles 介绍 - 7.9 之后版本”。
2.3 shard
索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。为了解决这一问题,ES 提供细分索引的能力,即分片(shard)。
一个 shard 对应一个 Lucene 实例。ES 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,完全由 ES 管理,对于作为用户来说,这些都是透明的。
2.4 replica
在一个网络环境里,节点故障随时都可能发生,在某个分片/节点出现故障时,有一个备份机制是非常有用的。为此 ES 允许你为分片创建一份或多份拷贝,这些拷贝叫做副本(replica)。
副本之所以重要,主要有两方面的原因:一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高查询效率,ES 会自动对搜索请求进行负载均衡。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片和副分片(主分片的拷贝)。分片和复本的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变副本数量,但是不能改变分片的数量。
默认情况下,ES 中的每个索引被分为 5 个主分片和 1 份拷贝。如果你的集群中至少有两个节点,你的索引将会有 5 个主分片和另外 5 个副分片,这样的话每个索引总共就有 10 个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以分散存放在多台主机上,这取决于你的集群机器数量。主分片和副分片的具体位置是由 ES 内在的策略所决定的。有一点可以确定是,同一个节点上面,副本和主分片是一定不会在同一个节点上的。
注意: 从 7.x 版本开始,不设置 index 的 shard 数,缺省主分片由 5 改为了 1 个。
以上相关概念的逻辑关系如下图: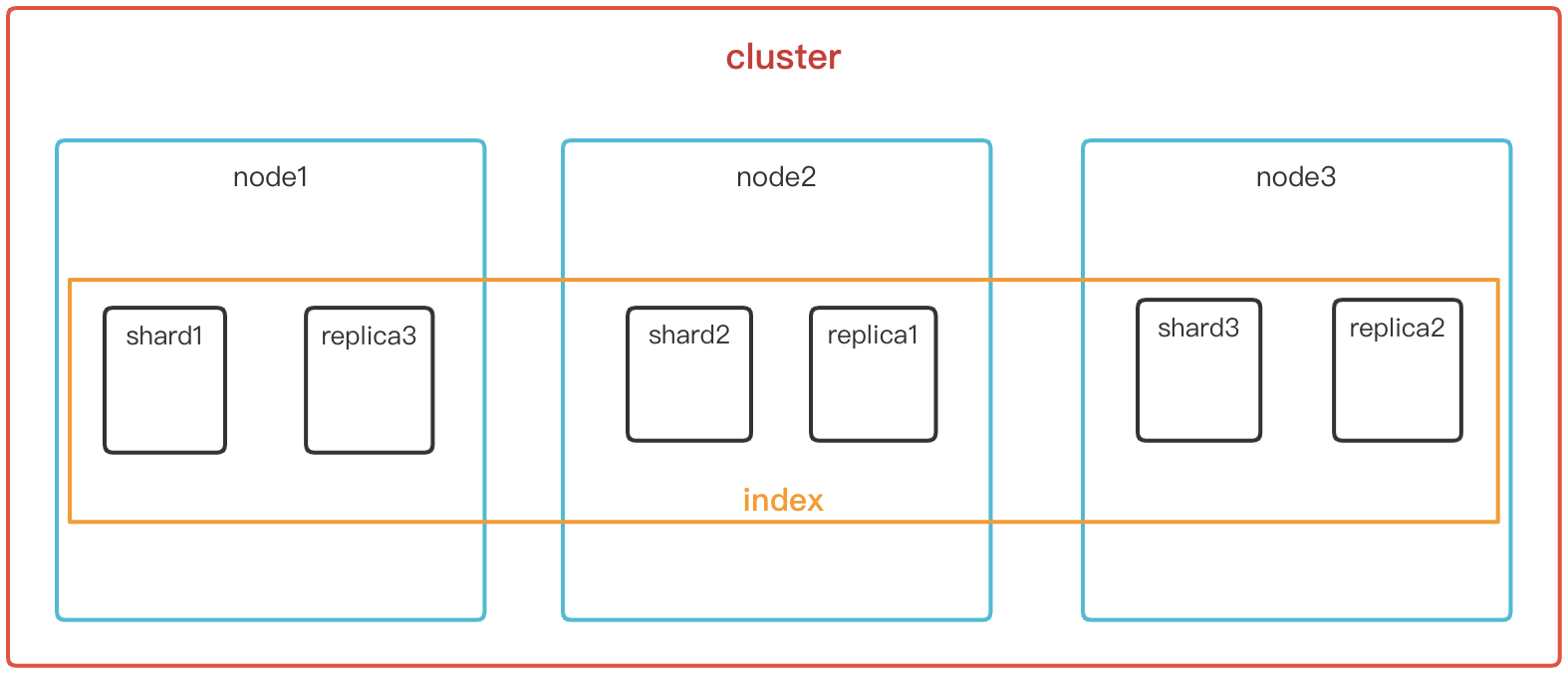
3.查看版本信息
有时候,随着 ES 的版本迭代,会加入一些新的特性。当我们使用一个特性时,可能需要了解下自己当前使用的 ES 的是否支持。此时我们需要查看 ES 的版本信息,很简单,对应的 RESTful API 为:
GET /
{"name":"kk-es-sh-test-es-data-1",
"cluster_name":"kk-es-sh-test",
"cluster_uuid":"6N8dPOE_RNSjyVqsid_uFA",
"version":{"number":"7.7.0",
"build_flavor":"default",
"build_type":"docker",
"build_hash":"81a1e9eda8e6183f5237786246f6dced26a10eaf",
"build_date":"2020-05-12T02:01:37.602180Z",
"build_snapshot": false,
"lucene_version":"8.5.1",
"minimum_wire_compatibility_version":"6.8.0",
"minimum_index_compatibility_version":"6.0.0-beta1"},
"tagline":"You Know, for Search"}
可见我使用的 ES 版本为 “7.7.0”,底层 Lucene 的版本为 “8.5.1”。
4.小结
ES 作为一款数据库,其数据存储结构的相关概念可与传统关系型数据库一一对应,类比学习能够更好地帮助我们理解 ES。
此外,ES 作为一款分布式数据库,又有着与分布式相关的概念,如集群(cluster)、节点(node)、分片(shard)和副本(replica)。对这些概念也要有清晰的认知。
参考文献
Elasticsearch 官网
Elasticsearch Guide [8.1] » Mapping » Mapping parameters » dynamic
Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica
go-ElasticSearch入门看这一篇就够了(一)
版权归原作者 恋喵大鲤鱼 所有, 如有侵权,请联系我们删除。