
文章目录
1. 引言
官方部署介绍:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/overview/
Flink任务支持许多不同场景的部署,如部署作业任务至Standalone独立集群、Yarn或者K8S,部署流程如下:
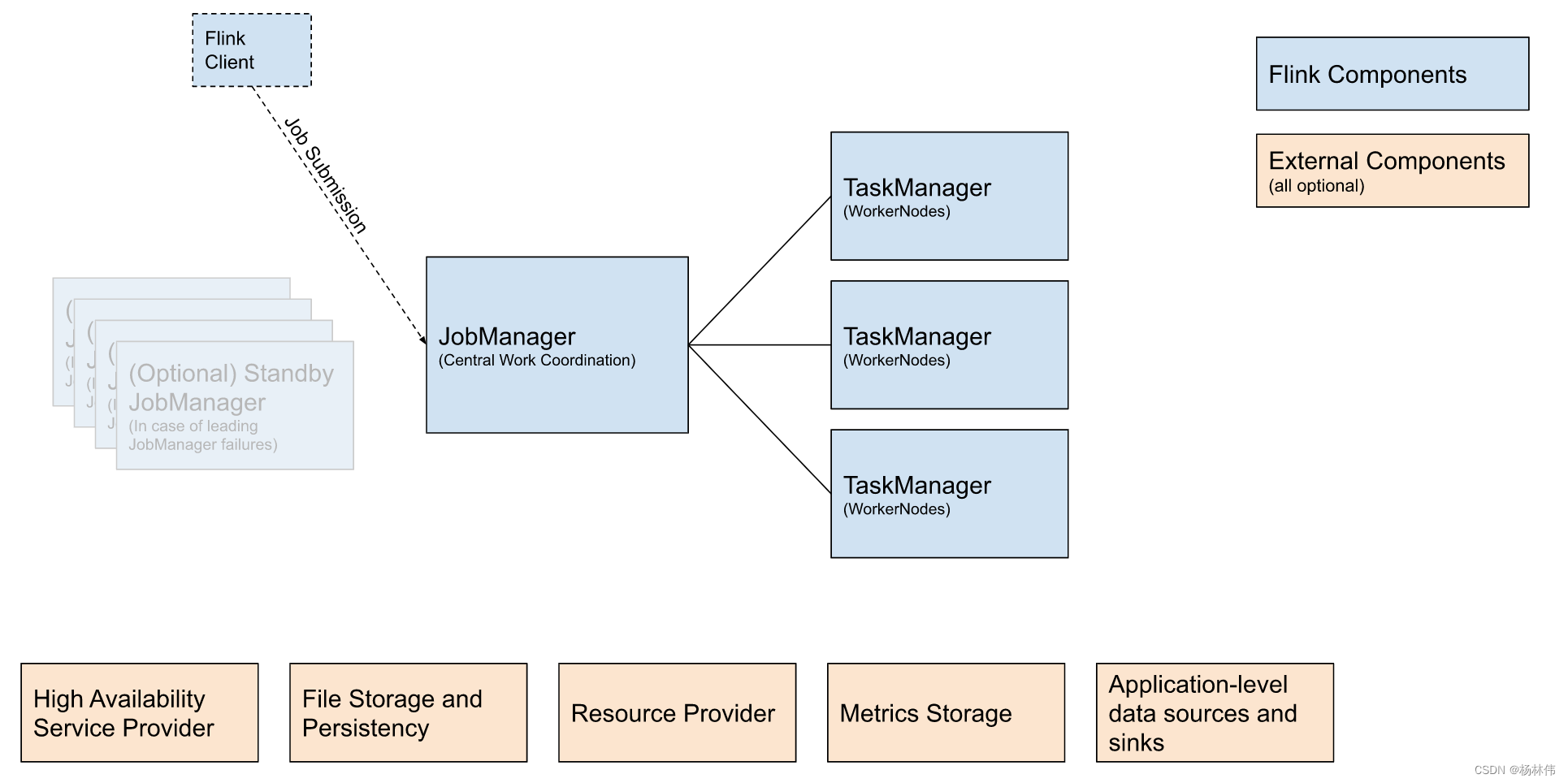
根据部署流程图,可以知道有如下组件:Flink Client、JobManager、TaskManager等。
其流程简要描述:
- 使用Flink Client客户端提交任务至JobManager(提交方式有很多种,如CMD、REST、SQL Client等);
- JobManager是Flink的工作中心,主要分配工作给TaskManager(JobManager的提交方式有多种,如Application、Per-Job、Session);
- TaskManager是Flink任务的执行者;
- 其余组件都是可选的,如HA ServiceProvider主要做JobManager的故障转移、Resource Provider 即资源提供框架进行部署Kubernetes或YARN等。
2. Flink Client (任务提交客户端)
**Flink Client:**是Flink作业任务提交客户端,它主要将批处理或流处理应用程序编译为数据流图(JobGraph),然后提交给JobManager。
提交方式分为如下几种(点击即可查看详情):
- 命令行(Command Line Interface)
- REST接口(REST Endpoint)
- SQL客户端(SQL Client)
- Python脚本
- Scala脚本
3. JobManager (任务协调者)
JobManager:是Flink的中心工作协调组件。它根据作业提交模式,并针对不同的资源管理程序(
Resource Provider
),实现不同的高可用性、资源分配行为。
JobManager 作业任务提交模式有如下:
- Application Mode
- Per-Job Mode
- Session Mode
3.1 Application Mode
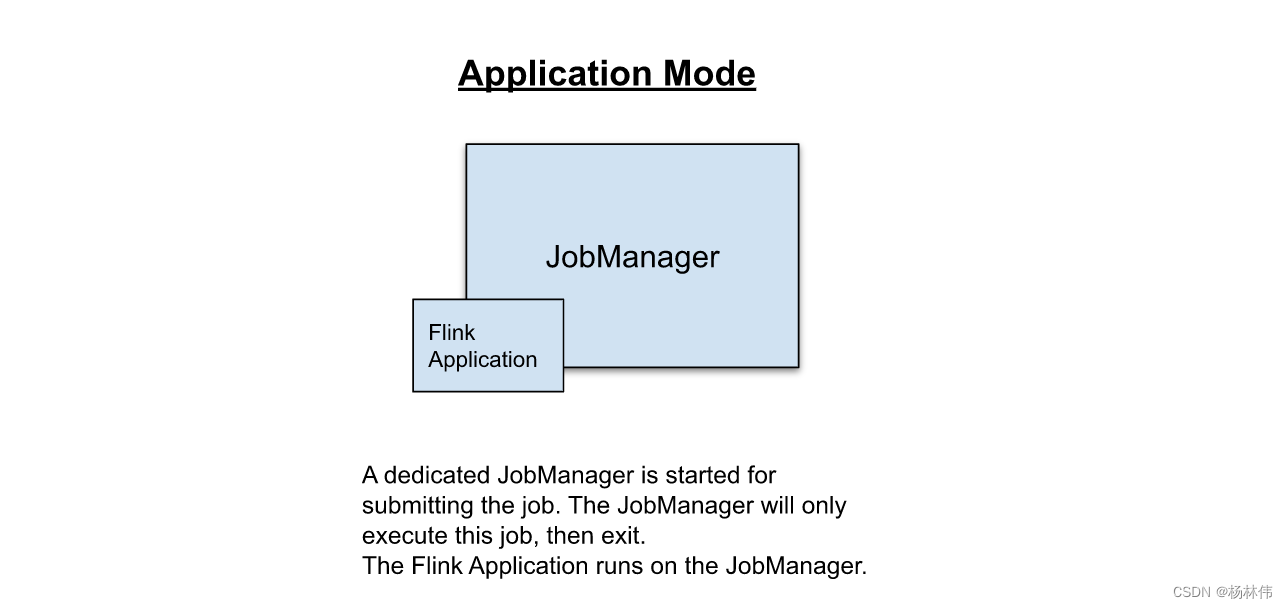
Application Mode为每个提交的应用程序创建一个集群,注意应用程序的main()方法在JobManager上执行,这个过程包括本地下载应用程序的依赖项,执行main()来提取Flink运行时可以理解的应用程序的表示(即JobGraph),并将依赖项和JobGraph发送到集群。
3.2 Per-Job Mode
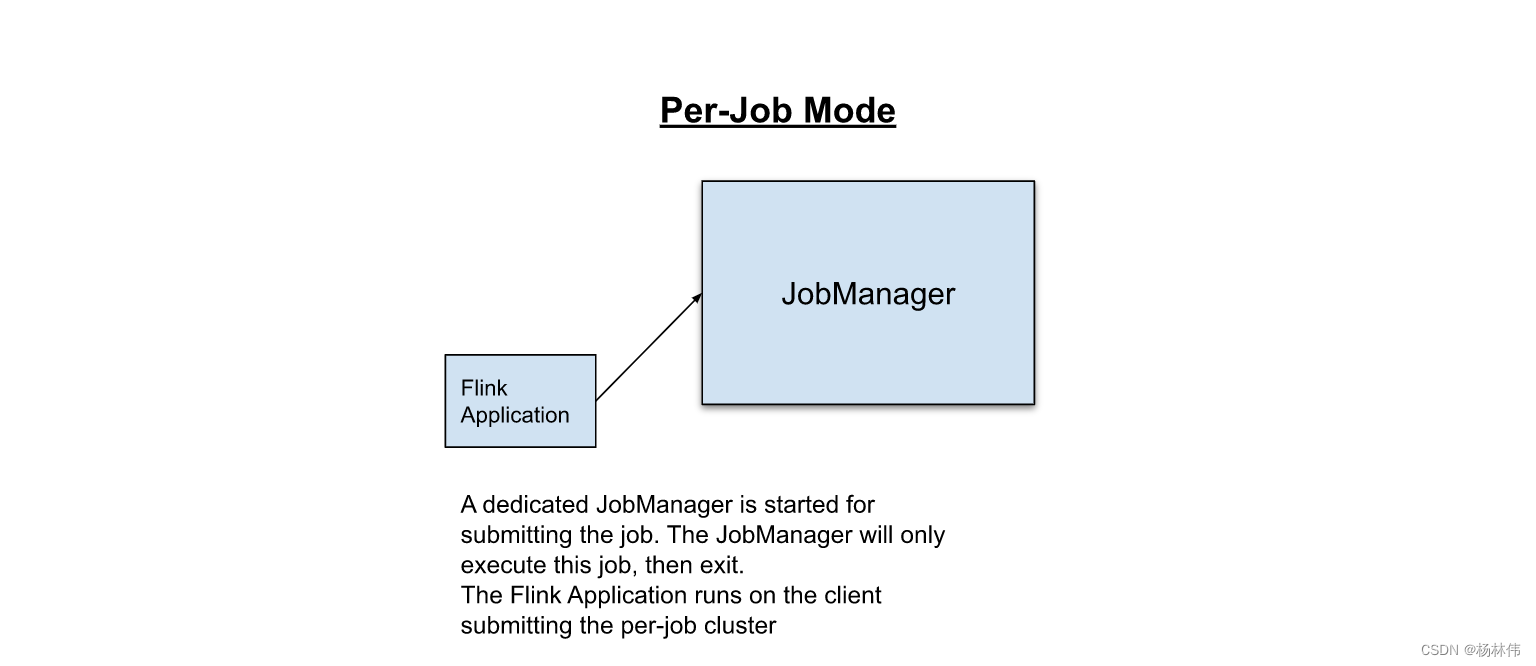
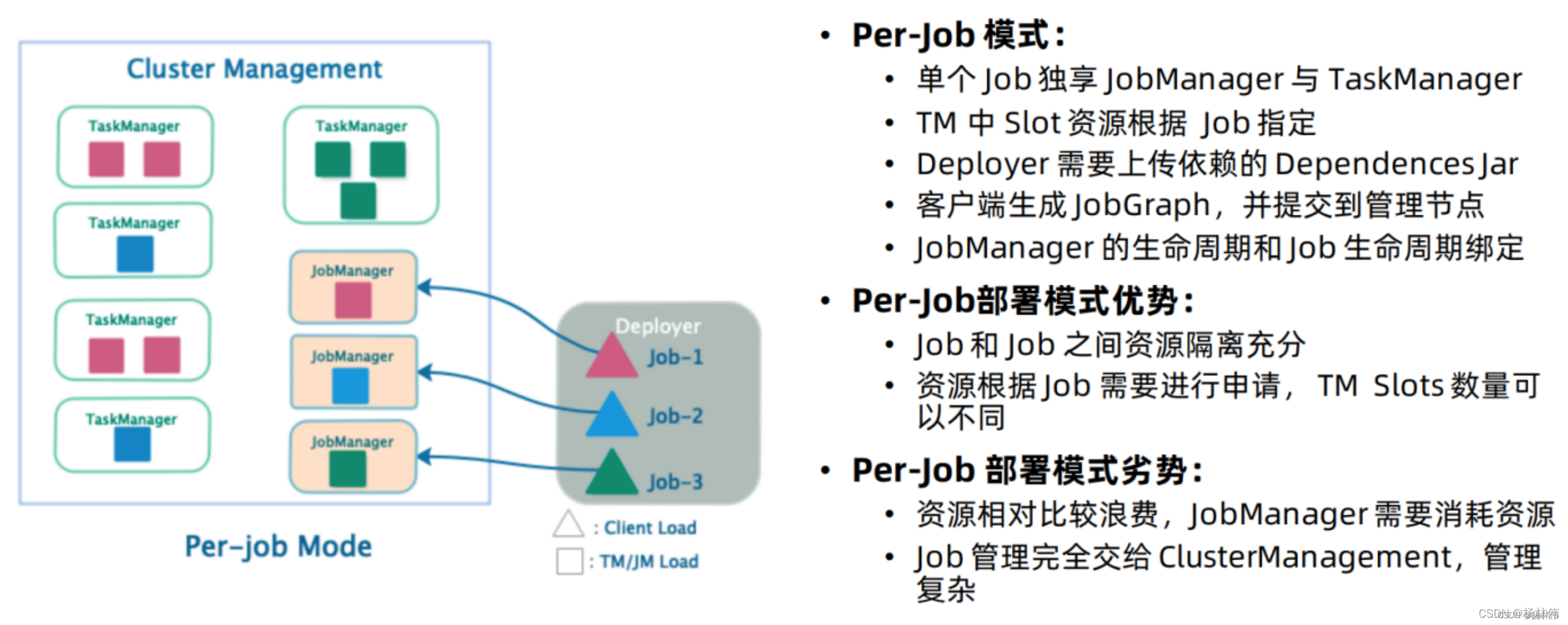
在Per-Job模式下,集群管理器框架(例如YARN或Kubernetes)用于为每个提交的Job启动一个 Flink 集群。
Job完成后,集群将关闭,所有残留的资源(例如文件)也将被清除。此模式可以更好地隔离资源,因为行为异常的Job不会影响任何其他Job。另外,由于每个应用程序都有其自己的JobManager,因此它将记录的负载分散到多个实体中。
- 特点:每次递交作业都需要申请一次资源
- 优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
- 缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
- 应用场景:适合作业比较少的场景、大作业的场景
3.3 Session Mode
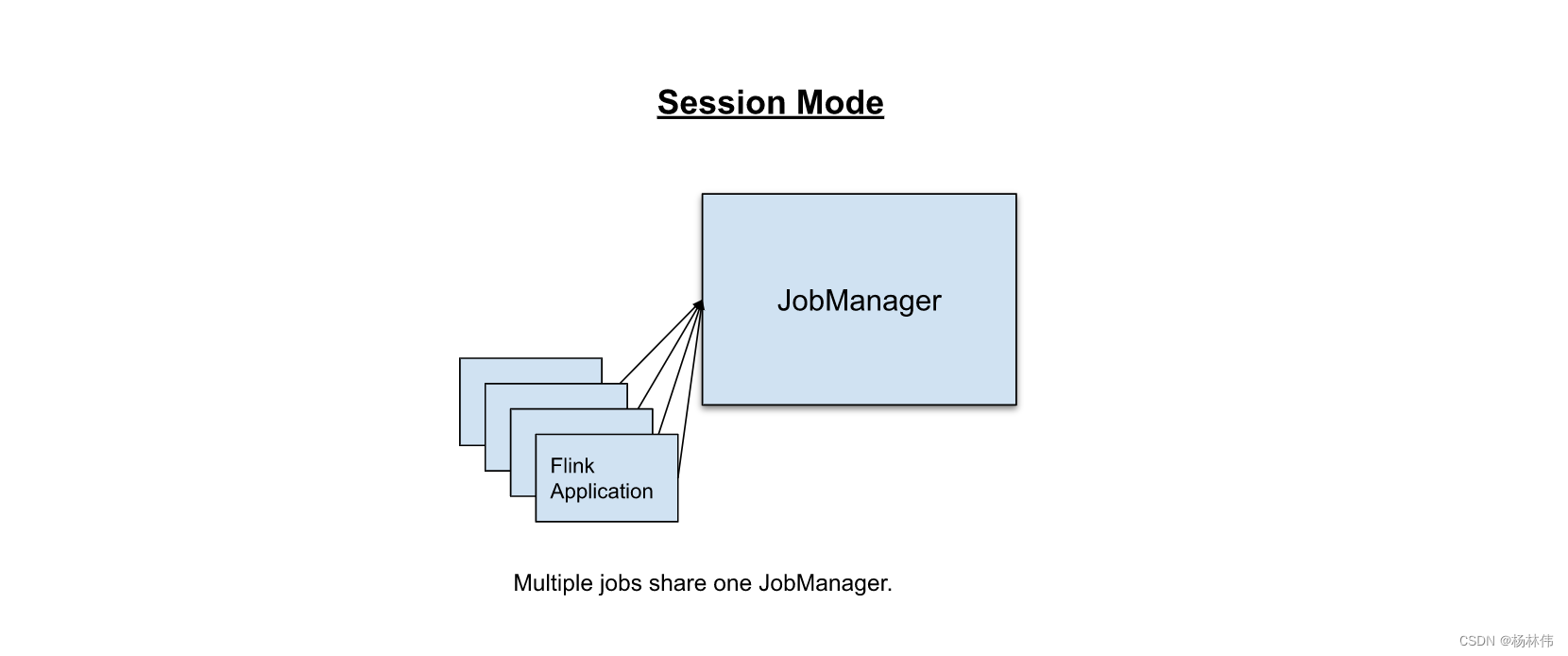
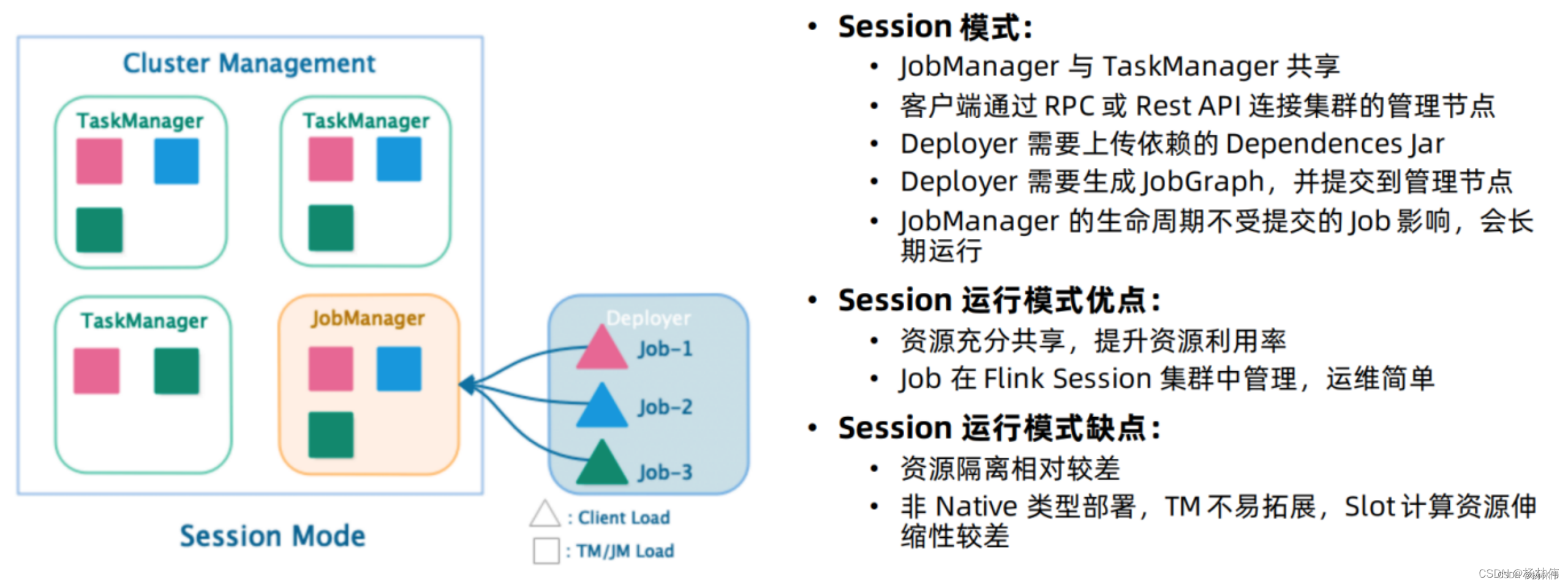
Session 模式假定已经存在一个集群,并任何的提交的应用都在该集群里执行。
因此会导致资源的竞争,该模式的优势是你无需为每一个提交的任务花费精力去分解集群。但是,如果Job异常或是TaskManager 宕掉,那么该TaskManager运行的其他Job都会失败。除了影响到任务,也意味着潜在需要更多的恢复操作,重启所有的Job,会并发访问文件系统,会导致该文件系统对其他服务不可用。此外,单集群运行多个Job,意味着JobManager更大的负载。这种模式适合启动延迟非常重要的短期作业。
- 特点:需要事先申请资源,启动JobManager和TaskManger
- 优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
- 缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源 应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
3.4 小结
以下是根据个人理解的三种模式:
- Application 模式:提交的应用程序已经包含了Flink的环境(即Flink集群环境),应用程序的main方法在JobManager上执行,过程包括本地下载应用程序的依赖项,main来提取Flink运行时可以理解的应用程序的表示(即JobGraph),并将依赖项和JobGraph发送到集群。
- Per-Job模式:需要为每个提交的作业先创建好集群,它提供了更好的隔离保证,因为资源不会在作业之间共享,在这种情况下,集群的生命周期绑定到作业的生命周期。
- Session模式:先创建好集群,集群的生命周期独立于集群上运行的任何作业的生命周期,所有作业共享统一集群资源。
4. TaskManager(任务执行者)
TaskManager 是实际执行
Flink
作业的服务,本文不再详述。
5. Resource Provider(资源管理者)
前面讲到JobManager根据作业提交的情况,并根据不同的资源管理者来实现高可用性和资源分配。
资源管理程序有:
- Standalone
- Kubernetes
- YARN
5.1 Standalone(独立集群)
5.2 Kubernetes(k8s集群)
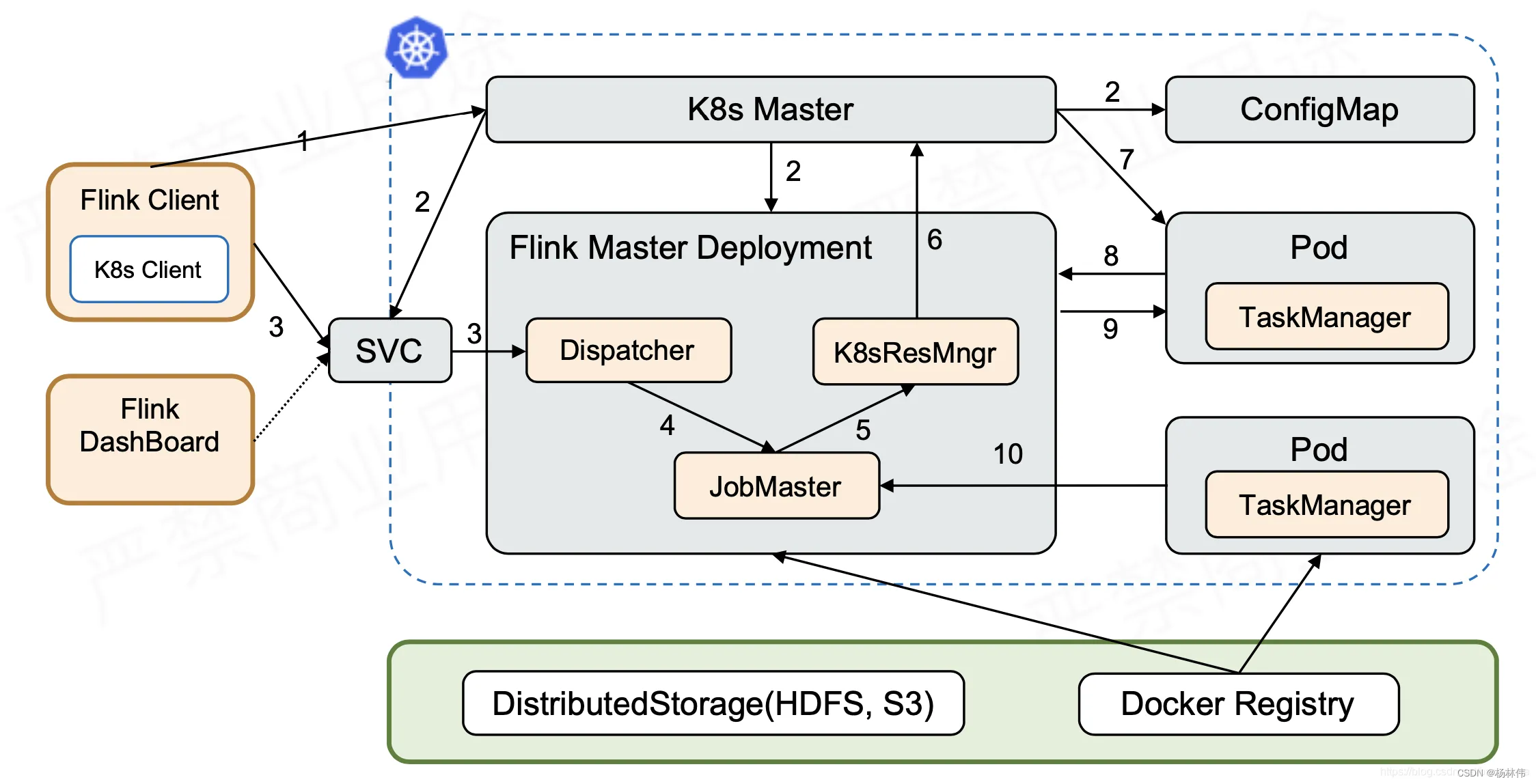
工作原理如下:
- 使用 Kubectl 或者 K8s 的 Dashboard 提交请求到 K8s Master;
- K8s Master 将创建 Flink Master Deployment、TaskManager Deployment、ConfigMap、SVC 的请求分发给 Slave 去创建这四个角色,创建完成后 Flink Master、TaskManager 启动;
- TaskManager 注册到 JobManager。在非 HA 的情况下,是通过内部 Service 注册到 JobManager,至此,Flink 的 Sesion Cluster 已经创建起来。此时就可以提交任务了;
- 在 Flink Cluster 上提交 Flink run 的命令,通过指定 Flink Master 的地址,将相应任务提交上来,用户的 Jar 和 JobGrapth 会在 Flink Client 生成,通过 SVC 传给 Dispatcher;
- Dispatcher 会发现有一个新的 Job 提交上来,这时会起一个新的 JobMaster,去运行这个 Job;
- JobMaster 会向 ResourceManager 申请资源,因为 Standalone 方式并不具备主动申请资源的能力,所以这个时候会直接返回,而且我们已经提前把 TaskManager 起好,并且已经注册回来;
- 这时 JobMaster 会把 Task 部署到相应的 TaskManager 上,整个任务运行的过程就完成。
5.3 YARN(yarn集群)
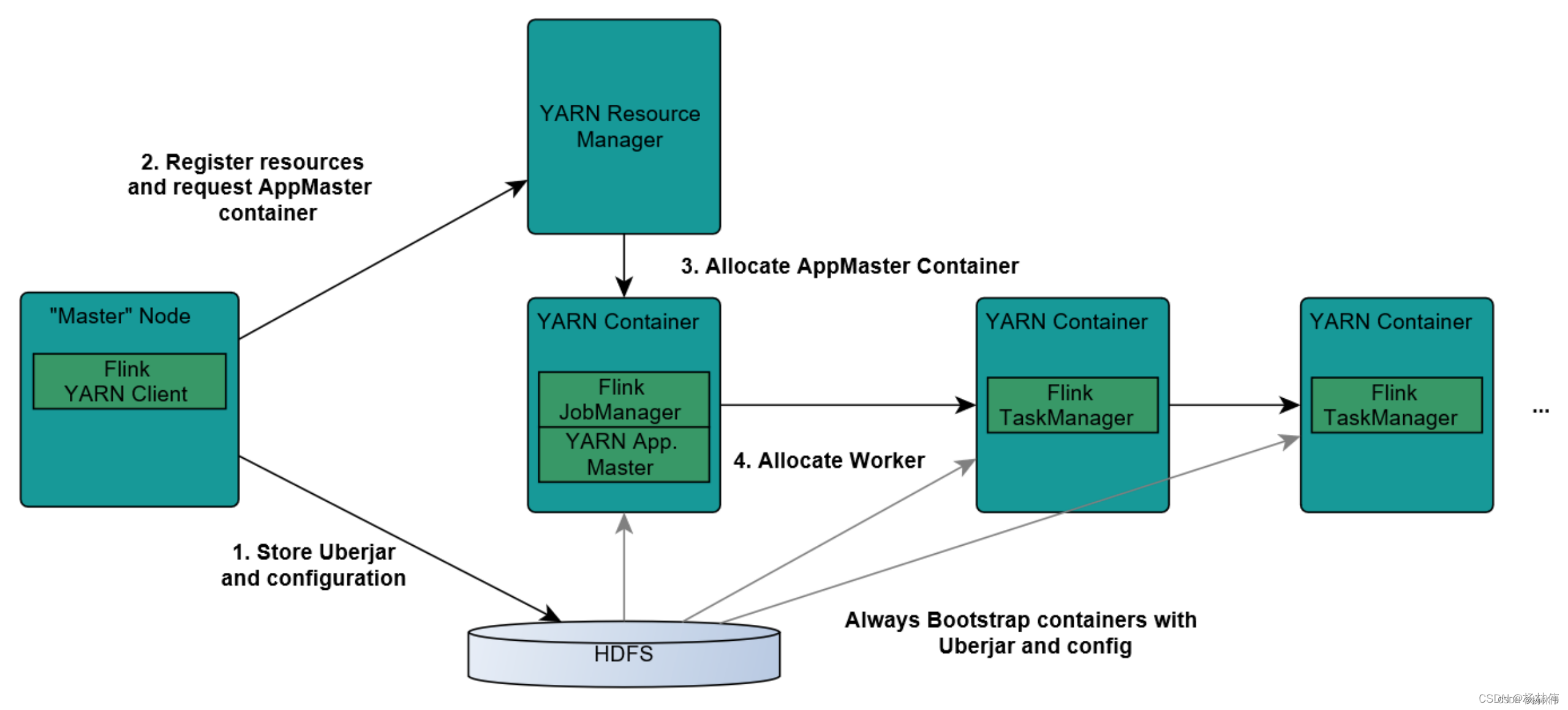
工作原理如下:
- Client上传jar包和配置文件到HDFS集群上;
- Client向Yarn ResourceManager提交任务并申请资源;
- ResourceManager分配Container资源并启动AppMaster;
- 然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager,JobManager和ApplicationMaster运行在同一个container上。
- 一旦它们被成功启动,AppMaster就知道JobManager的地址(AppMaster它自己所在的机器),它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager),这个配置文件也被上传到HDFS上;
- 此外,AppMaster容器也提供了Flink的web服务接口,YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink;
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager;
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
6. 文末总结
从本文我们知道了Flink作业任务部署有几种模式,分别为:
- Application 模式
- Per-Job 模式
- Session模式
无论何种模式,都是提交到JobManager的,JobManager会把作业分发到不同的TaskManager,TaskManager为实际的工作者。
对于JobManager及TaskManager,又可以部署到不同的资源管理器中,如:
- Standlone 独立集群
- Yarn 资源管理器
- K8S 集群(本质也是资源管理器)
好了,本文就讲到这里,希望能帮助到大家,谢谢大家的阅读,本文完!
版权归原作者 杨林伟 所有, 如有侵权,请联系我们删除。