
本文将介绍如何在HBase 2.3.7中配置snappy压缩。snappy是一种快速的数据压缩和解压缩算法,可以提高HBase的存储空间利用率和读写性能。本文将使用HBase 2.3.7版本,运行在三个Ubuntu系统的虚拟机中,分别作为master和slave节点。
主要步骤如下:
- 安装snappy,并检查是否成功。
- 配置Hadoop,添加snappy的相关配置。
- 配置HBase,添加snappy的相关配置。
- 重启Hadoop和HBase服务。
- 验证snappy压缩,使用CompressionTest工具和HBase Shell命令。
本文使用了HBase 2.3.7版本,运行在三个Ubuntu系统的虚拟机中,分别作为master和slave节点。也可以使用其他版本的HBase和其他操作系统,只要保证snappy的安装和配置正确
一、安装snappy
- 在每个节点上,下载snappy的源码包,并解压。例如:
wget https://github.com/google/snappy/releases/download/1.1.9/snappy-1.1.9.tar.gz
tar -zxvf snappy-1.1.9.tar.gz
- 进入解压后的目录,编译并安装snappy。例如:
cd snappy-1.1.9
./configure
make
sudo make install
- 检查是否安装成功,可以使用ldconfig命令查看是否有libsnappy.so的链接。例如:
sudo ldconfig -p | grep libsnappy.so
- 如果输出类似如下内容,说明安装成功:
libsnappy.so.1 (libc6,x86-64) => /usr/local/lib/libsnappy.so.1
libsnappy.so (libc6,x86-64) => /usr/local/lib/libsnappy.so
二、配置Hadoop
- 在每个节点上,编辑Hadoop的配置文件core-site.xml,添加以下内容:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.compression.codec.snappy.native</name>
<value>true</value>
</property>
- 这些配置指定了Hadoop支持的压缩编码器,并启用了snappy的本地库。
- 在每个节点上,编辑Hadoop的配置文件hadoop-env.sh,添加以下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
- 这个配置指定了Hadoop加载本地库的路径。
三、配置HBase
- 在每个节点上,编辑HBase的配置文件hbase-env.sh,添加以下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
- 这个配置指定了HBase加载本地库的路径。
四、重启Hadoop和HBase
- 在每个节点上,重启Hadoop和HBase服务。例如:
stop-dfs.sh
stop-yarn.sh
stop-hbase.sh
start-dfs.sh
start-yarn.sh
start-hbase.sh
五、验证snappy压缩
- 在任意一个节点上,进入HBase Shell,使用CompressionTest工具验证snappy支持是否启用,并且本地库是否可以加载。例如:
hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://host/path/to/hbase snappy
- 如果输出类似如下内容,说明验证成功:
2023-5-28 10:23:45,123 INFO [main] Configuration.deprecation: io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2023-5-28 10:23:45,124 INFO [main] hfile.CacheConfig: CacheConfig:disabled
2023-5-28 10:23:45,125 INFO [main] hfile.CacheConfig: CacheConfig:disabled
SUCCESS
- 在HBase Shell中,创建一个使用snappy压缩的表,并查看表的描述信息。例如:
create 't1', { NAME => 'cf1', COMPRESSION => 'SNAPPY' }
describe 't1'
- 如果输出类似如下内容,说明创建成功:
Table t1 is ENABLED
t1, {TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.hadoop.hbase.coprocessor.MultiRowMutationEndpoint|536870911|'}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s)
Took 0.0179 seconds
- 压缩测试
在HBase shell中将rawdata表转为压缩并整理,该表在创建时未设置压缩格式
alter 'rawdata', NAME => 'f1', COMPRESSION => 'snappy'
major_compact 'rawdata'
得到前后存储空间占用情况对比,效果显著,最上面有COMPRESSION压缩格式设置
前:
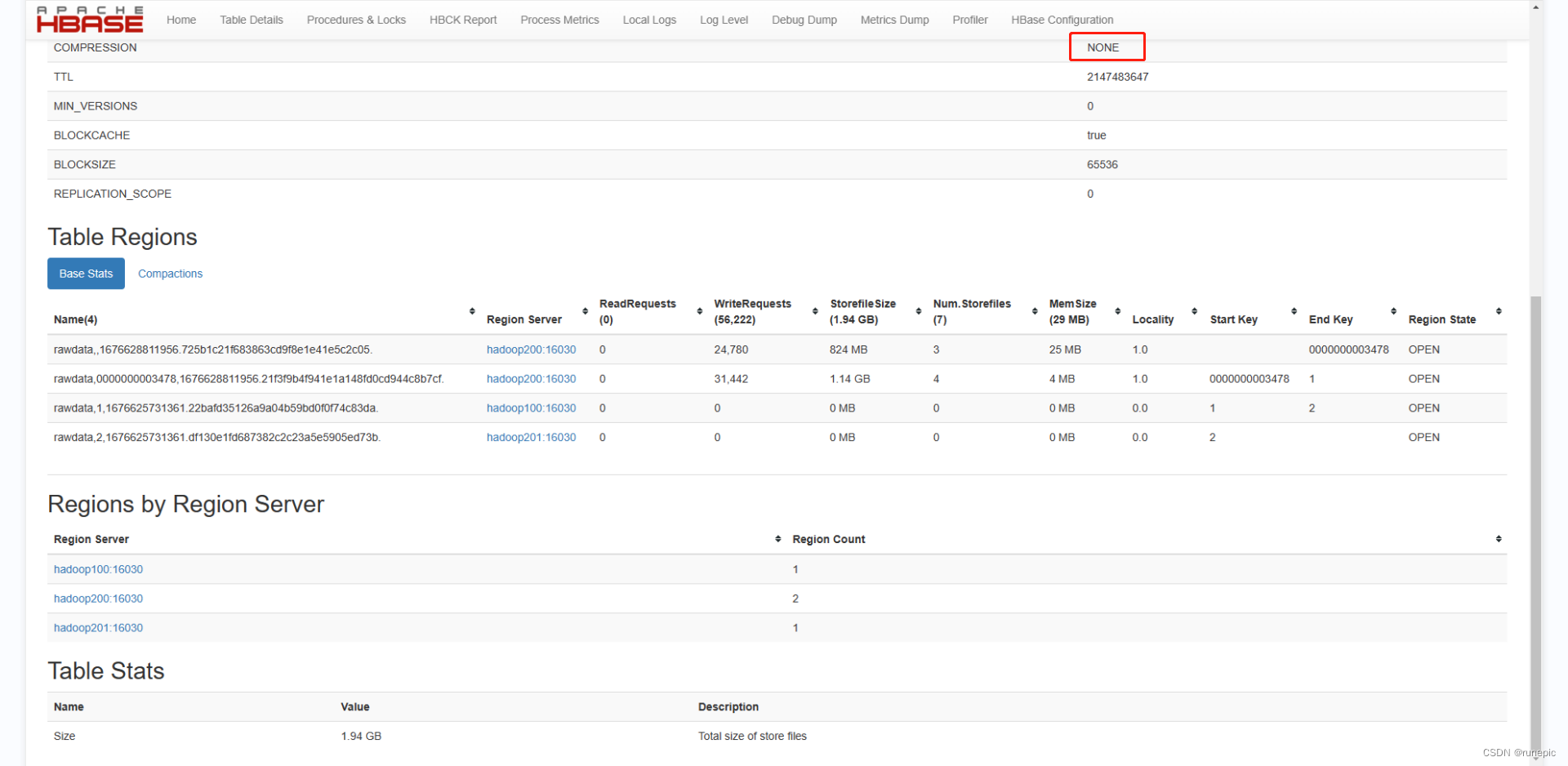
后:

本文转载自: https://blog.csdn.net/weixin_40694662/article/details/131243211
版权归原作者 runepic 所有, 如有侵权,请联系我们删除。
版权归原作者 runepic 所有, 如有侵权,请联系我们删除。