
背景
今年写了一个数据中心的项目,其中有相当一部分的数据查询,用的是ES来做的,涉及到dsl的查询语句,从最开始的简单查询,到后面的复杂的查询,逐步掌握了ES的常用写法,现在总结一下。
文章内的称呼,没有按照ES的官方称呼,例如sql那边的表叫type,sql那边的行叫documents,sql那边的列或者字段叫fields。为了方便起见,统一按照sql的叫法。
查询语句解释说明
示例一:
{"size":0,"query":{"bool":{"must":[{"bool":{"must":[{"term":{"depot_id":1}},{"range":{"order_time":{"gte":"2022-01-01 00:00:00","lte":"2099-01-01 00:00:00"}}}]}},{"bool":{"must_not":[{"match_phrase":{"user_remark":{"query":"换货单"}}}]}}]}},"aggregations":{"total_user_count":{"cardinality":{"field":"user_id","precision_threshold":50000000}},"total_order_money":{"sum":{"field":"pay_money"}}}}
在这个查询中,使用了条件过滤,以及查询之后,对结果进行聚合。
代码解释:
1.size:0
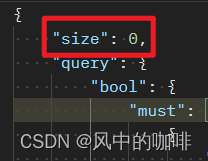
加上size:0之后,则不会返回查询到条件,对应的ES内存的原始数据。
用sql解释就是,没有size:0,则相当于“select * from 某个表”。这个和后面查询的聚合结果没有关系,就只是 是否返回原始数据,以及返回多少条原始数据。加不加size,都不会影响返回后面的聚合后的值。
2._source
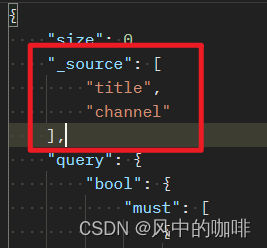
_source后面加上字段名,是用于返回原始数据的指定字段的。
例如sql中会写:
select id ,name,sex
from stu_info
limit100
在ES里面就会写
{"size":100,"_source":["id","name","sex"],"query":{"match_all":{}}}
如果只是排除个别的字段,可以写exclude
例如: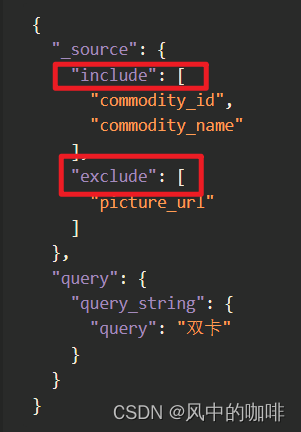
这里面的意思就是,只需要显示 commodity_id、commodity_name, 排除掉 picture_url。
3.“query”
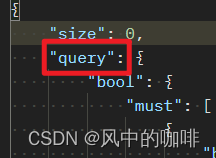
在query后面,会加上查询数据的条件,例如上面查询,我们用了
"query":{"match_all":{}}
它的意思就是,匹配所有的数据
而这个
"query":{"query_string":{"query":"双卡"}}
它的意思是,查询包含“双卡”的数据。
4.must,must_not,should
must 理解起来就是sql里面的 =,in ()
例如
select*from stu_info
where id =3or name in('张三','李四')
那么此处的这两个条件,都可以用must来写。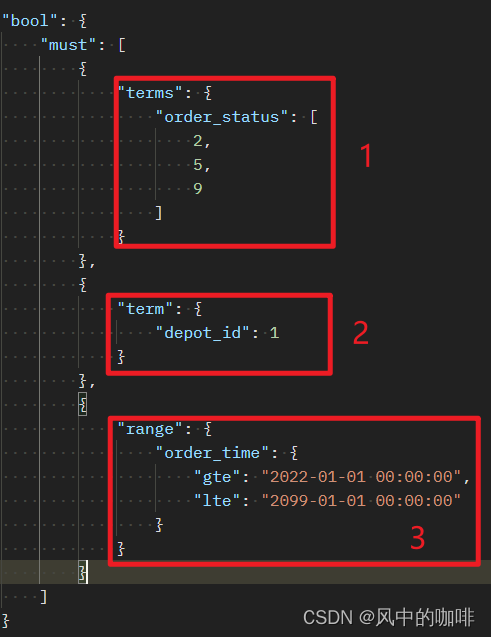
这个图中,must下面包含了三个条件,并且这三个条件的关系是and,必须同时满足,此处不做过多解释,下面是对应的sql写法
1.order_status in(2,5,9)2.depot_id =13.order_time between'2022-01-01 00:00:00'and'2099-01-01 00:00:00'
must_not 对应的就是 !=,<>, not in ()
should 对应的则是or, should中的两个条件至少满足一个就可以。
至于must,must_not,should的组合以及嵌套,可以参考:
解决es中must,must_not,should不能同时生效的问题
5 aggregations或aggs
这个是用于查询结果聚合的,类似于groupby,注意只是类似于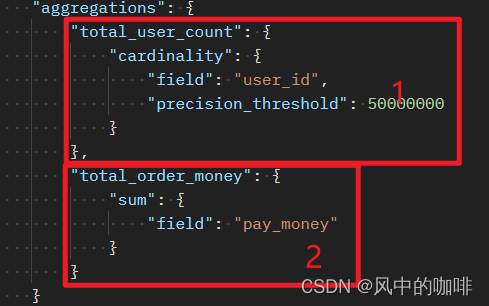
在这个代码里,实现了两个功能,
1.对user_id 进行去重数个数,相当于
count(distinct user_id)
这里的precision_threshold是修改精度,因为在数据量较大时,计数会产生稍微的误差
2.对pay_money进行求和,相当于
sum(order_money)
同样的,这这里可以进行求平均值,最大值等操作
结尾
这一部分就先写到这里,这只是我对于ES的自己的总结,难免会有不完整以及错误的地方,欢迎指正。
版权归原作者 风中的咖啡 所有, 如有侵权,请联系我们删除。