
前言

接上一篇内容......
中断线程~
中断线程就是让线程结束~(让内核里面的CPU被销毁)
让线程结束的关键,就是让线程对应的入口方法,执行完毕.
入口方法:
1.继承Thread重写的run方法
2.实现Runnable重写run方法
3.lambda
这些都算是它的入口方法,只要入口方法执行完了,线程就随机结束了
像这种情况:
//Thread是 Java 标准库中描述一个关于线程的类 //常用的方法就是自己定义一个类继承 Thread //重写 Thread 中的 run 方法. run方法就是表示线程要执行的具体任务(代码). class MyThread extends Thread{ @Override public void run() { System.out.println("hello,Thread"); } } public class Test { public static void main(String[] args) { Thread thread = new MyThread(); //stat 方法,就会在操作系统中真的创建一个线程出来,(内核中搞个PCB,加入到双链表中) //这个新的线程,就会执行 run中所描述的代码 thread.start(); //thread.run() } } 像这种情况
像这种情况,只要run执行完,线程就随之结束了
更多情况下,线程不一定这么快就能执行完run方法:
public class TestDome1 { public static void main(String[] args) { Thread t = new Thread(new Runnable() { @Override public void run() { while (true){ //打印当前线程的名字 //Thread.currentThread()这个静态方法,获取到当前线程实例 //哪个线程调用这个方法,就能获取到当前线程实例 System.out.println(Thread.currentThread().getName()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } },"myThread"); t.start(); //在这里也打印一下这个线程的属性 System.out.println("id: " + t.getId() ); System.out.println("name: " + t.getName()); System.out.println("state: " + t.getState()); System.out.println("priority: " + t.getPriority()); System.out.println("isDaemon" + t.isDaemon()); System.out.println("isInterrupted: "+t.isInterrupted()); System.out.println("isAlive " + t.isAlive()); } }
如果run里面带的是一个死循环,此时这个线程就会一直持续运行,直到整个进程结束.
实际开发中,并不希望线程run就是一个死循环,更希望能够控制这个线程,按照咱们的需要随时结束.
为了实现这样的效果,就有一些办法:
1.简单粗暴的办法,就是使用一个boolean变量来作为循环结束标记
public class TestDome { private static boolean flag = true; public static void main(String[] args) throws InterruptedException { Thread t = new Thread(){ @Override public void run() { while (flag){ System.out.println("线程运行中....."); try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("线程结束!"); } }; t.start(); //主循环中也等待个三秒 Thread.sleep(3000); //三秒之后,就把flag 改成 false flag = false; } }2.刚才是使用程序猿自己定义的变量作为循环标记,还可以使用标准库里内置的标记
获取线程内置的标记位:线程的isinterupted()(打断的意思)判定当前线程是不是应该结束循环
修改线程的内置标记位:Thread.interrupt()来修改这个标记位
public class TestDome2 { public static void main(String[] args) { Thread t = new Thread(){ @Override public void run() { //默认情况下isInterrupted(打断的意思)这个方法的值为false(默认是一个未被打断的状态,所以说要取反) while (!Thread.currentThread().isInterrupted()){ System.out.println("线程运行中..."); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); //在这里再加个break 就可以保证循环能结束了 break; } } } }; t.start(); //在主线程中,通过t.interrupt()方法来设置这个标记位 try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } //这个操作就是把Thread.currentThread().isInterrupted()给设置成true t.interrupt(); } }打印结果:
当我们三秒之后,insterrupt方法貌似并没有修改这个标记位......循环看起来再继续
同时这里还有个异常:
就是这个异常:
interrupt方法并没有修改这个标记位,而是直接抛了个异常
这里的interrupt方法可能有两种行为:
1.如果当前线程正在运行,此时就会修改Thread.currentThread().isInterrupted()标记位为true
2.如果当前线程正在sleep/wait/等待锁.......此时就会触发interruptedException
在这里加上break就可以保证循环结束了
isInterrupted()这个是Thread的实例方法
和这个方法还有一个类似的
interrupted()这个也是Thread的类方法(static)
都能去判断当前的标记位是不是被设置上了
使用两者的区别:
使用这个静态方法,会自动清楚标记位
例如:调用interrupt()方法,把标记位设为true,就应该结束循环
当调用静态的interrupted()来判定标记位的时候,就会返回true,同时会把标记位再改回false,下次再调用interrupted()就返回false
如果是调用非静态的isinterrupted()来判定标记位,也会返回true.同时不会对标记位进行修改.后面再调用isInterrupted()的时候就仍然返回true






线程等待 ~
线程和线程之间,调度顺序是完全不确定的(取决于操作系统调度器自身的实现)
但是有的时候,希望这里的顺序是可控的
此时,线程等待就是一种办法.
这里的线程等待,主要就是控制线程结束的先后顺序~
一种常见的逻辑:有一个t1线程,创建t2,t3,t4.让这三个新的线程分别执行一些任务,然后t1线程最后在这里汇总结果~~
这样的场景我们就需要t1结束时机必须比t2,t3,t4都迟
比如现在有一个线程实例:
Thread t = new Thread()
当我们调用 t.join() 的时候,执行到这个代码,此时调用这个代码的线程就会阻塞等待,代码就不继续往下走了.具体说就是操作系统短时间内不会把这个线程调度到CPU上了
以往的代码,只要代码一写好跑起来,此时就会快速的按照顺序执行...
但是join就会触发阻塞等待
当我们执行start()方法的时候,就会立刻创建出一个新的线程来.
同时main这个线程也立刻往下执行,就执行到t.join
执行到t.join的时候就发现,当前t线程还是在运行中的.....
只要t在运行中,join方法就会一直阻塞等待,一直等到t线程执行结束(run方法执行完了)
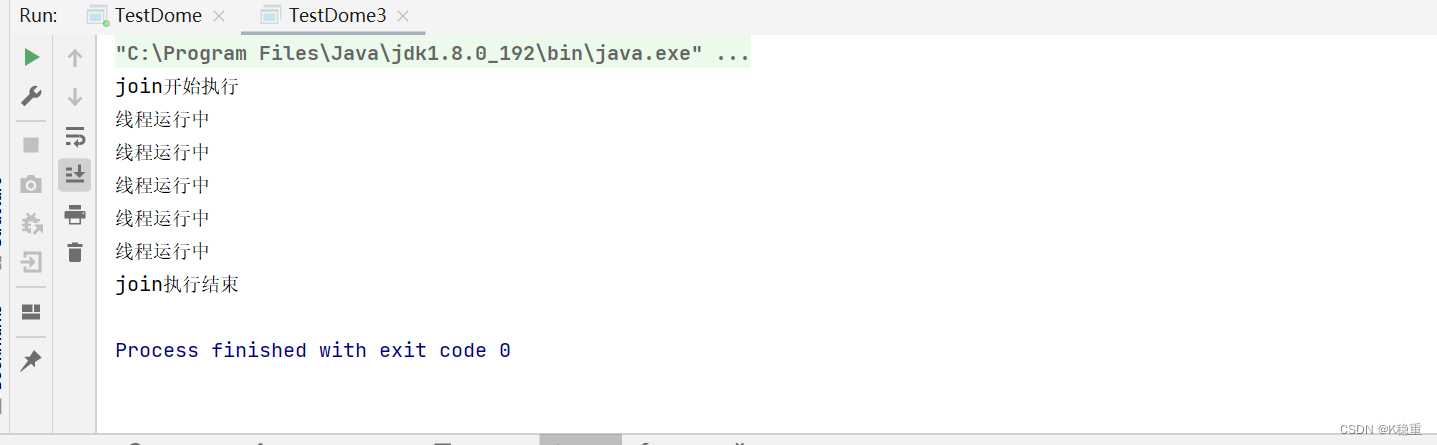
public class TestDome3 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(){ @Override public void run() { int count = 0; while (count < 5){ count++; System.out.println("线程运行中"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }; t.start(); //此处的join就会阻塞等待 System.out.println("join开始执行"); t.join(); System.out.println("join执行结束"); } }查看结果:
假设调用join的时候,t线程已经结束了,会咋样?
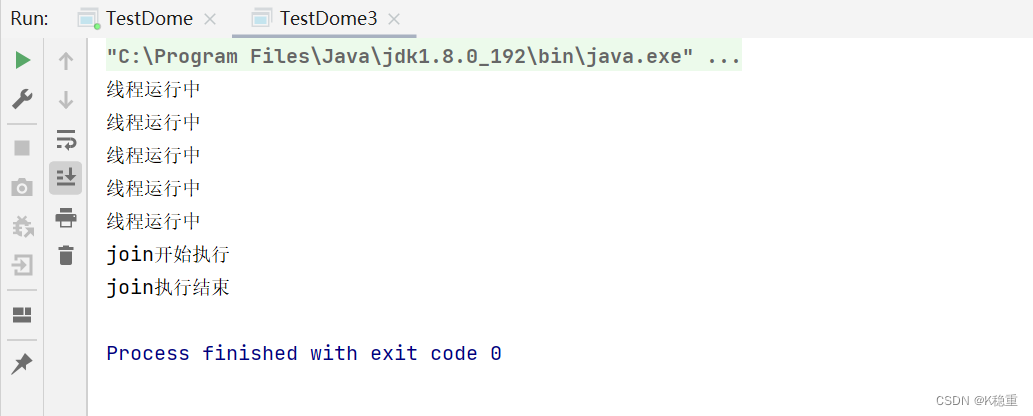
public class TestDome3 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(){ @Override public void run() { int count = 0; while (count < 5){ count++; System.out.println("线程运行中"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }; t.start(); Thread.sleep(7000); //此处的join就会阻塞等待 System.out.println("join开始执行"); t.join(); System.out.println("join执行结束"); } }打印结果:
join方法:
join无参数版本:相当于死等.
join有参数版本,参数就是最大等待时间.
在实际开发中,使用死等操作,往往是比较危险的
典型的就是网络编程中
发了一个请求,希望得到一个回应~~
由于种种原因,回应没有到达.....
此时我们的程序就不应该一直死等


获取当前线程引用
getCurrentThread() 能够获取到当前线程对应的Thread实例的引用
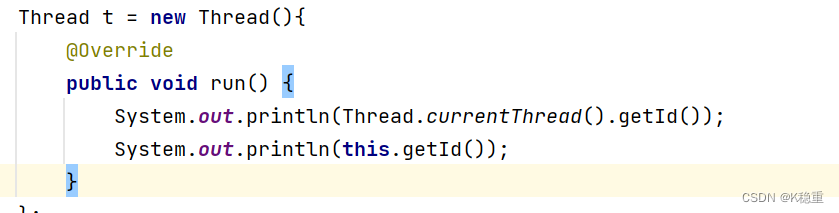
public class TestDome4 { public static void main(String[] args) { Thread t = new Thread(){ @Override public void run() { System.out.println(Thread.currentThread().getId()); System.out.println(this.getId()); } }; //在这个代码中,Thread.currentThread()得到的就是t这个引用,也就相当于是在run中直接使用this t.start(); } }打印结果:
在这个代码中看起来就好像是this 和 Tread.currentThread没啥区别
但是实际上,没区别的前提,是使用这种继承Thread,重写run的方式创建线程,才是没区别
如果当前是通过Runnable或者lambda的方式,就不行了
这个代码中this指向的是Runnable实例,而不是Thread实例了.此时也就没有getId这样的方法了


休眠当前线程
sleep这个方法,本质上是把线程PCB给从就绪队列,移动到了阻塞队列~
操作系统管理线程
1.描述:PCB
2.组织:双向链表(其实不仅仅是一个)

线程的状态
用于辅助系统对于线程进行调度这样的属性
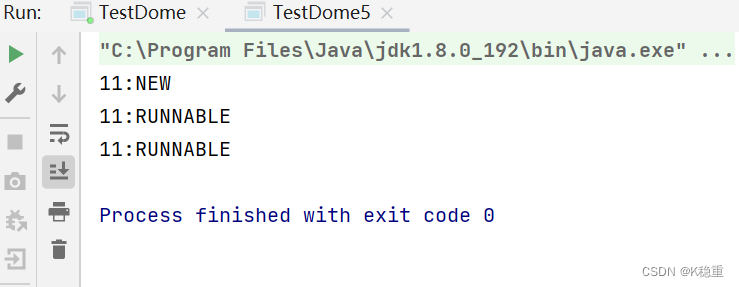
public class TestDome5 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(){ @Override public void run() { while (!Thread.currentThread().isInterrupted()){ } } }; System.out.println(t.getId() + ":" + t.getState()); t.start(); System.out.println(t.getId() + ":" + t.getState()); Thread.sleep(1000); t.interrupt(); System.out.println(t.getId() + ":" + t.getState()); } }打印结果:
**NEW:**当前已经把Thread对象创建出来了,但是内核里面的PCB还没创建出来(意思是当前只是把任务给它创建出来,但是没有任务去具体执行
**RUNNABLE:**当前的PCB也创建出来了,同时这个PCB随时待命(就绪)这个线程可能是正在CPU上运行,也可能是在就绪队列中排队...
public class TestDome5 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(){ @Override public void run() { while (!Thread.currentThread().isInterrupted()){ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); break; } } } }; System.out.println(t.getId() + ":" + t.getState()); t.start(); Thread.sleep(1000); System.out.println(t.getId() + ":" + t.getState()); Thread.sleep(1000); t.interrupt(); Thread.sleep(1000); System.out.println(t.getId() + ":" + t.getState()); } }打印结果:
**TIME_WAITING:**表示当前的PCB在阻塞队列中等待~
这样的一个等待是一个"带有结束时间"的等待
这个操作就会触发这个状态~~
**TERMINATED:**这个状态就表示当前PCB已经结束了.Thread对象还在,此时调用获取状态,得到的就是这个状态
**WAITING:**线程中如果调用了wait方法,也会阻塞等待.此时处在WAITING状态.(死等)除非是其他线程唤醒了该线程
**BLOCKED:**线程中尝试进行加锁,结果发现加锁已经被其他线程占用了.此时该线程也会阻塞等待.这个等待就会在其他线程释放锁之后,被唤醒
yield();这个方法并不会经常用到.效果是让线程主动让出CPU,但是不改变线程状态
这个操作咱们在Java很少会使用
当前这个几个状态,都是Java的Thread类的状态和操作系统内部PCB里面的状态的值并不完全一致的


线程安全
代码举例:
预期让count变量能够自增十万次
public class TestDome6 { static class Counter{ public int count = 0; public void increase(){ count ++; } } static Counter counter = new Counter(); public static void main(String[] args) { //此处创建两个线程,分别针对 count 自增5w次 Thread t1 = new Thread(){ @Override public void run() { for (int i = 0; i < 50000; i++) { counter.increase(); } } }; t1.start(); Thread t2 = new Thread(){ @Override public void run() { for (int i = 0; i <50000 ; i++) { counter.increase(); } } }; t2.start(); try { t1.join(); t2.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(counter.count); } }多次打印结果:
预期能够自增10w次
但实际上自增的次数,无法确定,每次运行结果都不一样
写代码最害怕的就是"不确定'
显然,这个代码我们视为一个"bug"
为啥会产生这个情况
大概率是和并发执行相关
由于多线程并发执行,导致代码中出现了BUG,这样的情况就称为"线程不安全"
分析程序执行的过程~
count++的详细过程;分成三个步骤~~
2.执行++操作(就是在CPU里面把0给它变成1)
3.把CPU的值写回到内存中~
此时我们这1次++就完成了
如果是两个线程并发的执行count++,就容易出现问题~~
我们来看一下两个线程并发执行的一个情况
我们给前面三个步骤分别起名为A,B,C
假设两个线程分别在不同的CPU上执行~~
产生线程不安全的原因:
1.线程之间是抢占式执行的(根本原因,线程不安全的万恶之源)
抢占式执行,导致两个线程的里面操作的先后顺序无法确定
这样的随机性,就是导致线程安全问题的根本存在
我们无力改变,这是操作系统内核实现的
2.多个线程修改同一个变量(和代码的写法密切相关)
一个线程修改同一个变量,没有线程问题!!不涉及并发,结果就是确定的
多个线程读取同一个变量,也没有线程安全问题!!读只是单纯的把数据从内存放到CPU中~,不管怎么读,内存的数据始终不变~~
多个线程修改不同的变量,也没有线程安全问题!!其实就认为就类似于第一个情况,一个线程修改一个变量
所以为了规避线程安全问题,就可以尝试变换代码的组织形式,达到一个线程只改变一个变量.....
有的场景下能这样变换,但是有的场景下不能这样变换
3.原子性~
像++这样的操作,本质上是三个步骤,是一个"非原子"的操作
像 = (赋值)操作,本质上就是一个步骤,认为是一个"原子"的操作
像当前,咱们的++操作本身不是原子的,可以通过加锁的方式,把这个操作编程原子的~~
4.内存可见性~
和原子性有点类似
例如:
线程1,读取变量
线程2,对变量自增
这样读,线程1就读到的是修改之前的值
这样读,线程1读到的就是修改之后值
像上面的两种情况都是OK的
1
3
4
如果我们的线程2更复杂了是循环的进行自增
比如说是按照这样一个方式来执行
线程2循环执行很多次自增
很多次自增就会涉及到很多次A和C
CPU执行B操作的速度比执行A和C要快1w倍~
这个时候线程2为了能够算的更快,于是就偷懒了~~
线程2这里面就不会每次自增都去A和C了
而是变成这个样子:
为了提高程序的整体效率,于是线程2就会把中间的一些A和C操作省略掉
这个省略操作是编译器(javac)和JVM(java)总和配合达成的效果~~
如果只是单线程下,这样的优化,没有任何副作用和
如果是多线程下,另外一个线程也尝试读取/修改这个数据
此时就出大事了
按照刚才的画法:
预期线程1读到的数据应该是1
但是实际上由于这样的优化可能导致线程1读到的是0了
如果把中间的A和C操作都省略掉,之后最后有一个C操作
这个时候A读到的其实还是内存中原来的值
这里的三次B操作都是在CPU内部来完成的,并没有把这样的结果写回到内存中
于是线程1再来去读内存就发现读到是旧的结果
1
至于这样的问题如何解决?
volatile关键字,就是用来解决这个问题的
我们下一篇继续.......













版权归原作者 K稳重 所有, 如有侵权,请联系我们删除。