
- 文章封面为个人AI绘图训练结果

- 项目传送门:传送门 (谷歌警告)
- 该项目为免费使用的AI绘图项目,并且可以在本地搭建部署环境。
- AI绘图对于人脸处理仍处于较为实现困难的阶段,因此该项目更适合用于各类场景、风格的绘制,尤其以宏观场景以及油画、厚涂风格为佳。目前对于像素画风格绘制并不是很理想。
- 本篇博客主要讲述网络直接使用以及本地环境搭建两种方式方法。
- 网络直接使用方法中使用的为Google Colab提供的托管机器,显卡有两种,大概率可以分配到Telsa显卡,训练速度为4.0/it约等于3070显卡的速度。但Google Colab会有闲置检测,长时间未点击页面会自动离线,需要购买其Pro+会员(大几百),而本地环境搭建不存在此问题。
- 2022/6/18补充:如有其他疑问可以直接去答疑博客:传送门,查找对应问题解决方案,或者直接进行体温
- 个人博客网址:AI绘图-Disco Diffusion使用指南 - Sugar的博客,如文章转载中出现例如传送门失效等纰漏,建议直接访问原博客网址。
- 如有不对之处,欢迎指正。
网络直接使用
- 首先点击传送门进入到项目内,该项目基于Google Colab发布,因此要求使用者必须持有谷歌账号,或选择本地环境搭建运行。
- 进入到网站后,点击复制到云盘按钮,然后可以自拟一个项目名称。

- 项目左侧的项目大纲中有详细的项目步骤,分别是:Tutorial、Set Up、Diffusion and CLIP model settings、Settings、Diffuse。
Tutorial
- 该部分主要详细讲述了项目的主要参数。主要控制训练过程,以及提供在base图片上二次训练绘制功能等。感兴趣可自行研究。
Set Up
- 首先,点击左上角的链接按钮,链接到Google Colab提供的虚拟环境当中。
- 然后,点击运行1.1 Check GPU Status代码,检查GPU运行情况。
- 忽略1.2-1.6部分,该部分主要为项目依赖包检测提供以及训练模型依赖检查与提供。
Diffusion and CLIP model settings
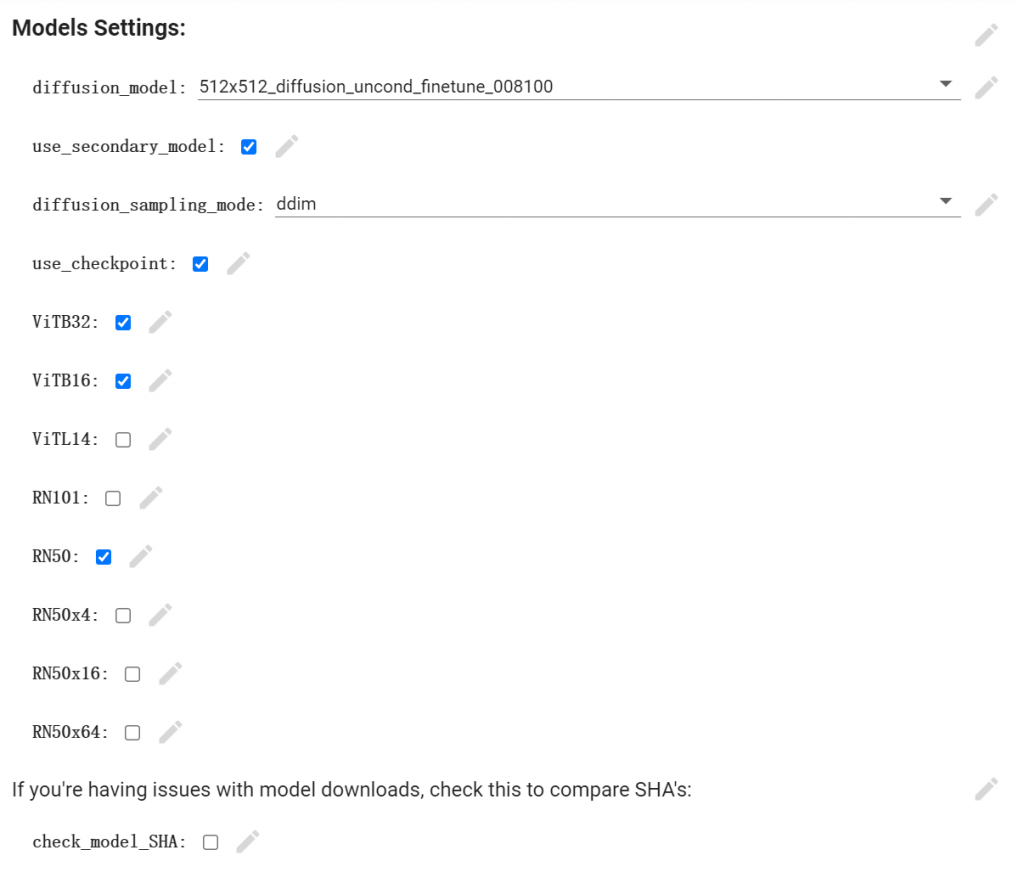
- 参数解释:(可以保持默认配置)diffusion_model:训练使用模型,有512×512以及256×256两种。512×512训练模型精度更高。use_secondary_model:是否使用第二模型diffusion_sampling_mode:有ddim以及plms两种训练集 后续ViT以及RN代表CLIP所用模型,用于分析自然语言和图片对比,勾选越多语言描述识别越精细,但会花费更长的时间。如果没有买PRO+会员那么最好保持原状,都勾选了会爆显卡RAM。
Settings

- 参数解释-Basic Settings:*batch_name:此次绘制图片导出文件夹名称,建议更改为自己需要的名称。*steps:训练步数,可以理解为绘制一张图片经历的模型训练次数,一般值推荐为200,最高可设置1000。轮数越高效果越好(决定性因素仍未给出的语言描述,训练步数为次要影响因素)width_height:图片尺寸,应为64的倍数,过大的图片尺寸可能导致超长时间渲染或者预期外的错误。clip_guidance_scale:可以理解为细节精细程度,推荐默认数值5000,追求更高精细度可调整到10000。 之后几个参数主要为图片细节调整,包括平滑度、RGB等,在Tutorial中有解释
- 参数解释-Init Settings:*init_image:在原有图片基础上进行二次绘制,默认为None。如果想使用此功能,请先上传图片到Google Colab上,然后把文件路径填入到该项目内。*init_scale:控制生成图片效果,推荐值为1000.skip_steps:跳过初始训练步数,即steps-skip_step为你实际的训练步数,如果你有依赖图片,那么至少请保证skip_steps占总step的50%以上。
Animation Settings(跳过)
Extra Settings
- 打开该片段折叠页
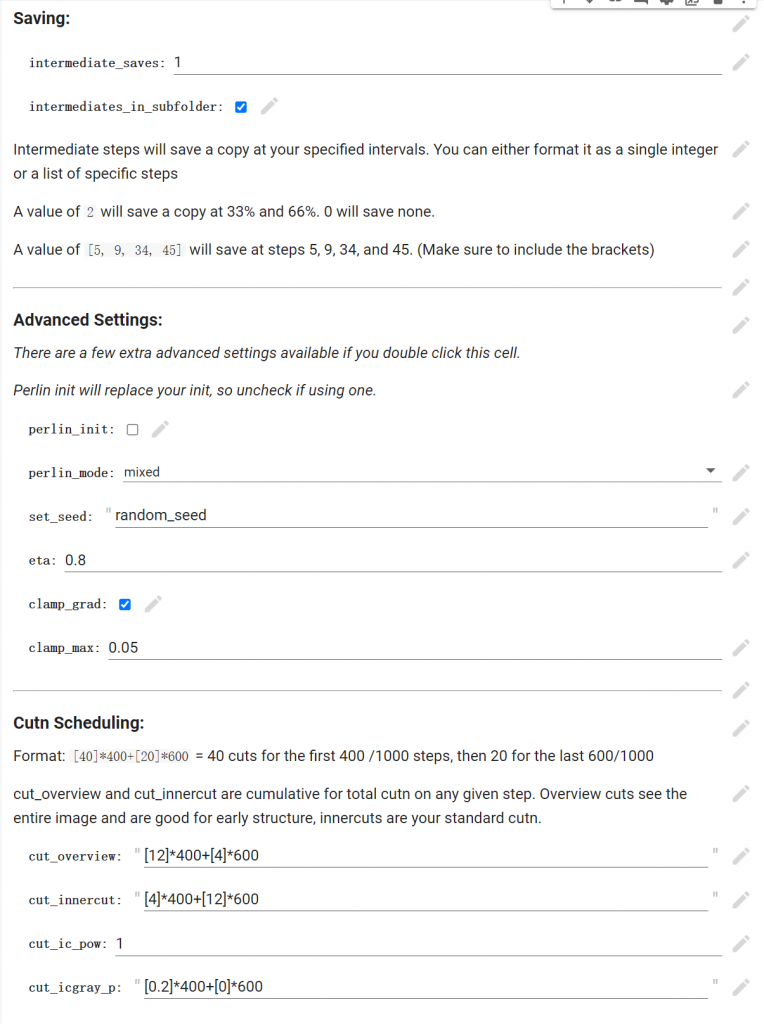
- 参数解释:intermediate_saves:保存图片数量,0为只保存最终1张图片,1为保存50%进度图片以及成片,2为33%1张66%1张成片一张以此类推。此参数不影响训练速度。intermediates_in_subfolder:对上一条的中间图片过程是否用子文件夹单独存放。Advanced Settings:该类别不要随便修改,主要为柏林噪声等内容。Cutn Scheduling:图片训练切割等内容。同理,不了解的话不要乱动。
Prompts

- 这里刚开始的默认语句为: “A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.”, “yellow color scheme” 填入内容可以用多个引号逗号区分。
- 该部分为AI训练最关键部分,主要填写为0:[]中内容,内容可以分为五个方向 画种描述:A beautiful painting of; 内容描述:a singular lighthouse, shining its light across a tumultuous sea of blood; 画家描述:by greg rutkowski and thomas kinkade; 参考渲染方式:Trending on artstation(全球性质CG艺术家社区); 颜色描述:yellow color scheme。
- 该部分内容可以优先参考网络上分享的语言表述,然后再自行创作。
Diffuse!
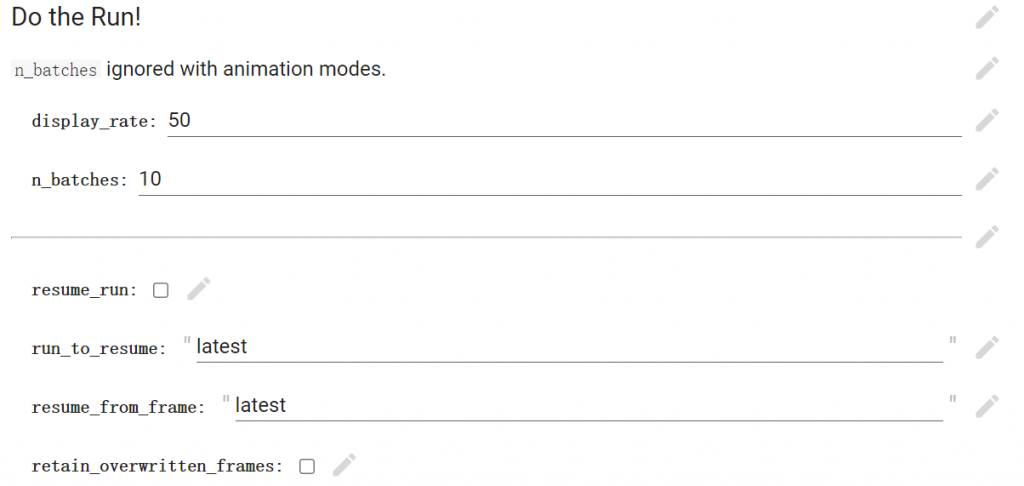
- 该部分为AI绘图训练的实际运行部分,在实际训练运行时,会在该代码片段下方展示出正在训练的图片。
- 参数解释:display_rate:展示率。即每隔多少个Step展示一次训练图形结果。推荐设置为5。n_batches:训练次数。即产出多少张最终图片。每一张图片都经理一次完整的step。
正式使用
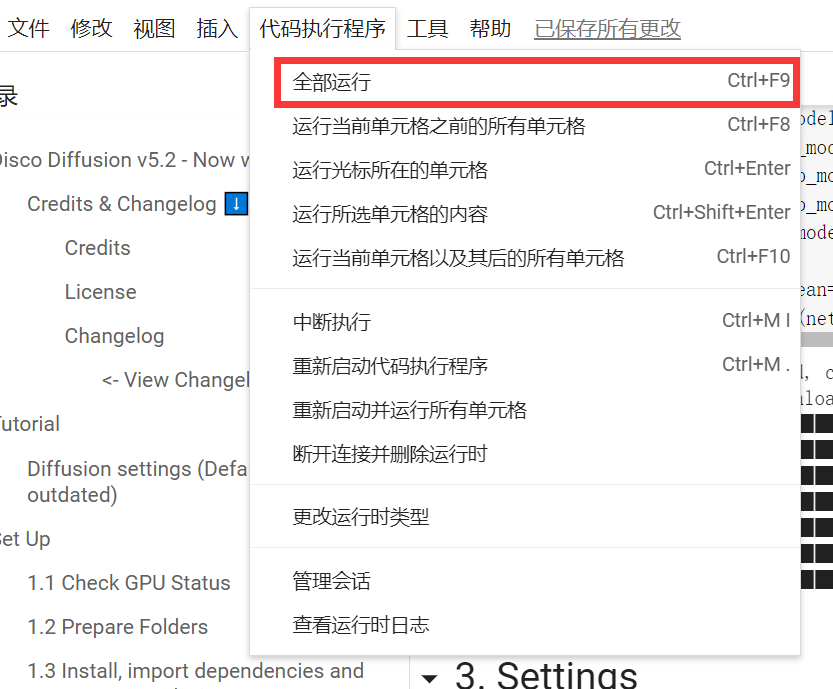
- 在点击链接之后,点击代码执行程序中的全部运行按钮,然后等待程序运行即可。
本地环境搭建(保姆级教程)For win
TIP:如果不是英伟达显卡,为A卡等其他卡就可以不要考虑本地环境搭建了。
前置软件/工程文件安装导入
- 首先你需要你个Git:传送门,点击download for Windows下载并完成安装。
- 其次打开项目Github官网:传送门,然后在你想创建项目的位置(务必在固态硬盘中创建)右键,点击Git Bash Here。等待其初始化完成之后输入如下代码:
1
git clone https://github.com/alembics/disco-diffusion.git
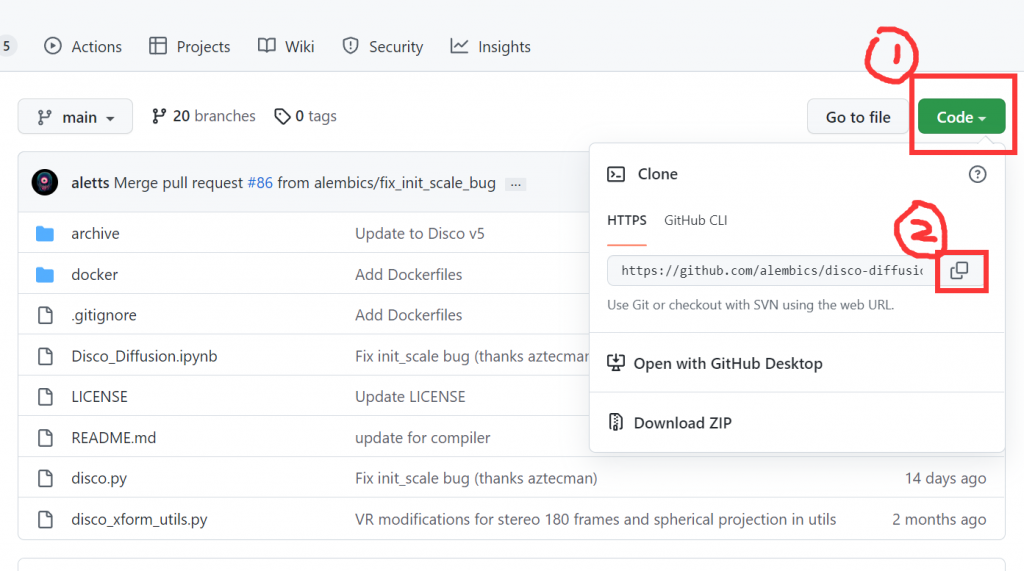
项目下载Https通过进入Github然后互点击Code再点击复制按钮即可
- 第三,你需要一个查看代码的IDE,这里推荐VScode:传送门,同理点击Download for Windows进行下载。
- 第四,你需要一个Python环境,这里推荐Anaconda:传送门

- 安装好Anaconda之后,在左下角Windows菜单中找到Anaconda Navigator点击并鼠标拖拽图标到桌面建立快捷方式,方便之后使用。
- 打开Vscode,选择左上角文件->打开文件夹之后找到下载好的文件夹并导入到项目中。
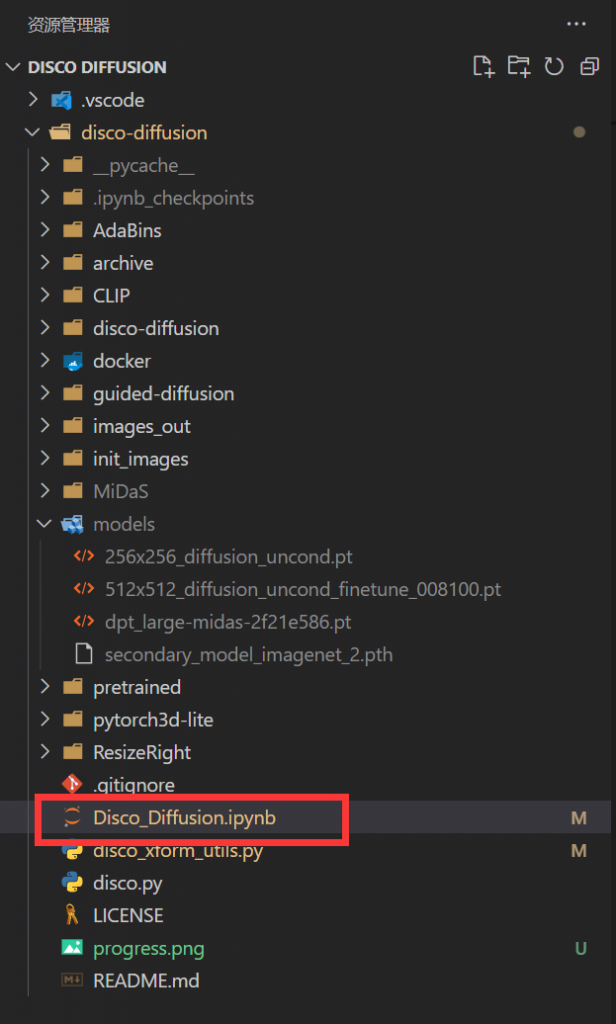
- 之后在项目中找到Disco_Diffusion.ipynb并双击打开,之后请阅读本文网络直接使用部分,了解程序的具体步骤以及参数。
环境/依赖包安装
运行时报错查看:在点击运行的时候,VS CODE下方弹出的红色字体就是报错内容信息。

- 首先找到Set Up代码片段,点击左边按钮运行程序,你可以得到你的GUP具体参数。如果出现Decode或者其他Error报错情况,把该段代码直接删除即可。
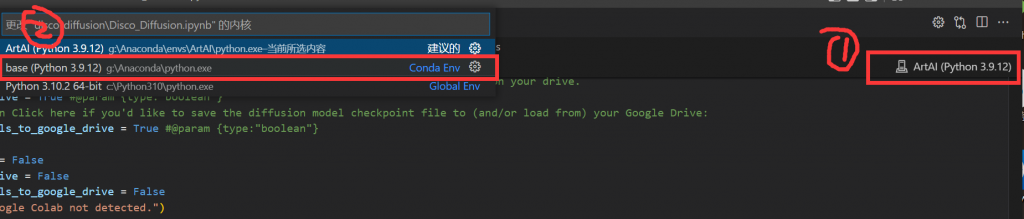
运行时或者代码导入时可能会提示你安装Python插件,请务必点击Install安装。在运行代码时首先点击右上角的按钮进行环境选择,然后选择下拉菜单中的base环境选项。
然后依次点击1.2,1.3代码片段。在1.3代码部分会出现报错,提示缺少Module。如果运行1.3代码时间过长可以中断程序跳过运行1.3此步骤。

- 此时打开Anaconda,点击Environment选项,选中base环境,点击base右侧按钮,选择Open terminal。(弄完之后不要关闭)
- (额外非必要)可以百度Anaconda换源,按照教程更换Anaconda下载镜像网址。
- 然后输入如下代码:每行依次输入,等待安装完成后再进行下一个代码输入
1
2
3
4
pip install opencv-python
pip install numpy
pip install lpips
pip install midas
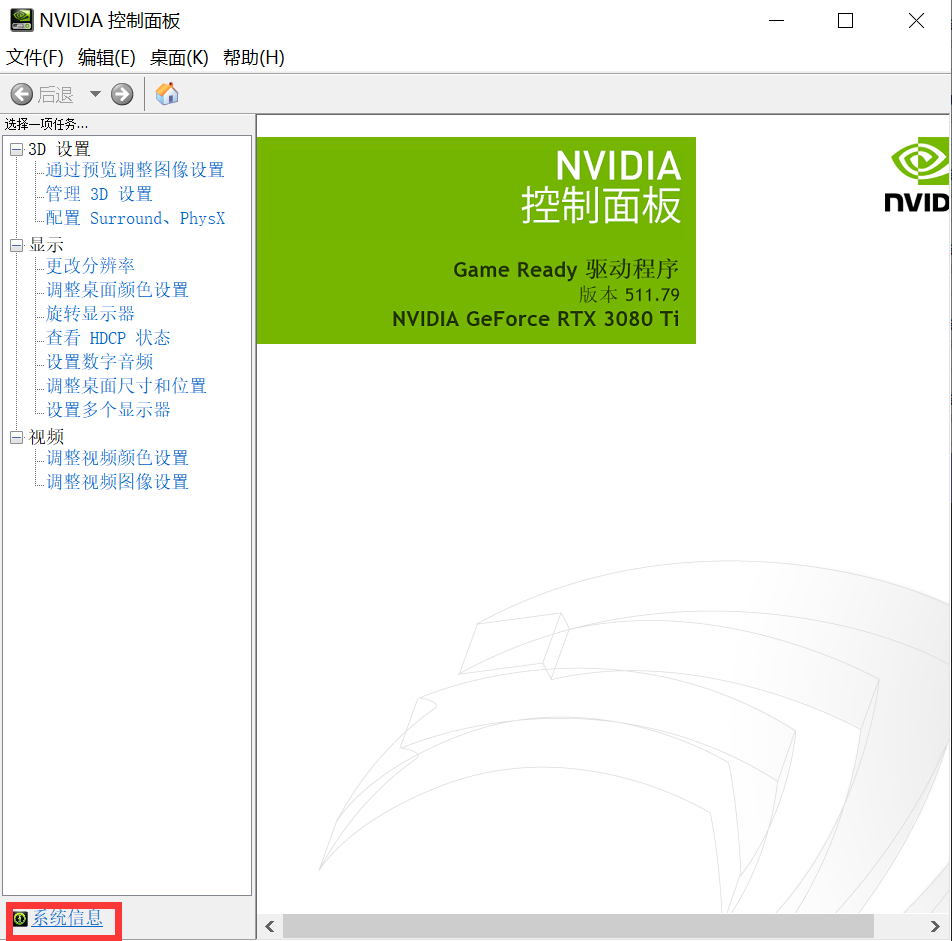
- 之后,在桌面空白处点击鼠标右键,NVIDIA控制面板,选择左下角系统信息按钮
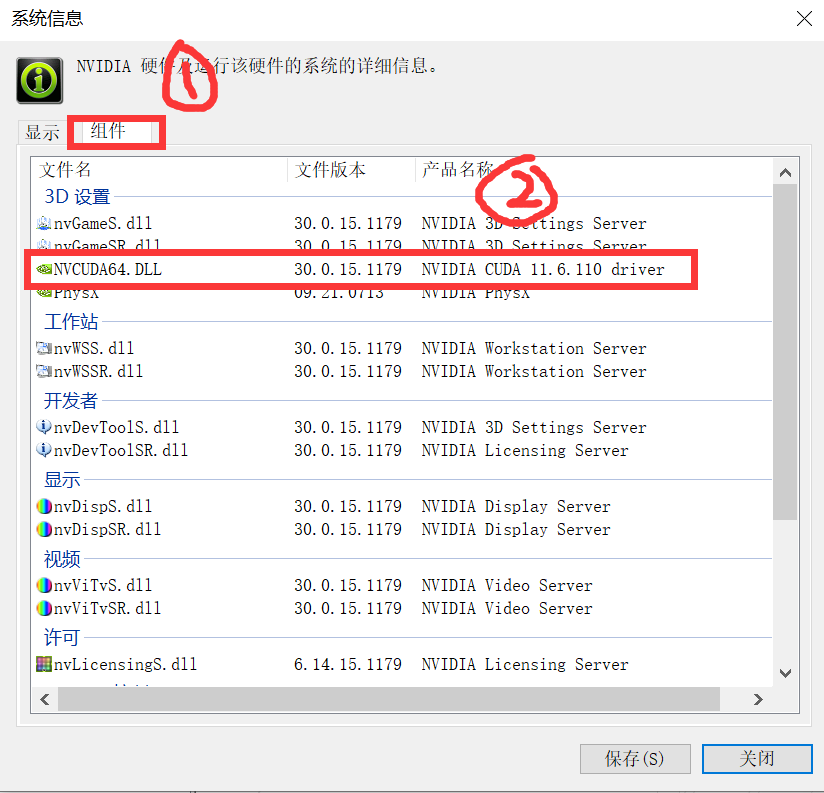
- 点击组件选项卡,查看NVCUDA的系统信息。后面显示的NVIDIA CUDA 11.6.110即为你能够安装的CUDA的最高的版本号。这里我的为11.6版本。

- 打开Pytorch官网:传送门,下拉找到如上图所示部分的下载安装选项,如果你的显卡支持11.3及其以上的版本则选择如上图所示的选项,如果支持10.2以上版本的CUDA那么就选择10.2版本,否则请及时更新你的显卡驱动(方法,下载360搜索栏里面搜索驱动,找到驱动安装,然后更新显卡驱动)
- 复制Run this Command中的命令,然后打开Anaconda的面板,输入复制到的代码:(下方为笔者的版本代码,如果安装时有卡顿现象,需要挂在美国节点或者香港节点的梯子)
1
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
1.3代码片段各类报错解决方案
- 之后再次回到VS code中点击运行代码。
- 出现xxx module missing或者not found等字样,则按照提示输入pip install xxxx,xxxx为该module名称。
- 出现Torch not compiled with CUDA enabled,那么则需要下载CUDA额外组件,去CUDA官网:传送门查找对应版本(如果出现下载速度过慢等情况推荐复制下载网址到迅雷内下载)。如果你能够支持11.3及其以上的CUDA,那么点击进入CUDA Toolkit 11.3.0,否则下载10.2版本CUDA。选择C盘默认安装即可,不要选择精简安装。 之后下载对应版本CUDNN:传送门,需要注册账号才能下载。下载时根据版本选择11.x或者10版本。 之后吧该CUDNN文件解压,打开里面的文件并复制剪切,之后找到你的CUDA安装文件默认路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3(最后一个为你的版本号不要乱复制粘贴)
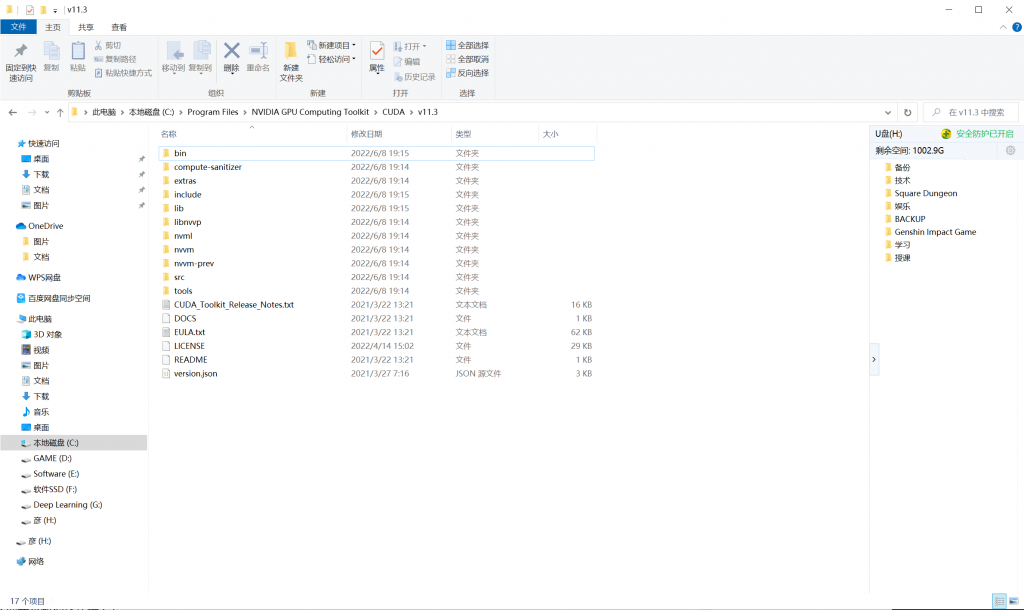
- 打开之后应当如上图所示,然后把CUDNN中的文件夹内容(不要直接复制外部大的文件夹,要把文件夹里面的三个文件和一个licence剪切复制)复制到该文件夹当中。 只有打开系统环境变量,可以在左下角的搜索栏中直接搜索环境变量
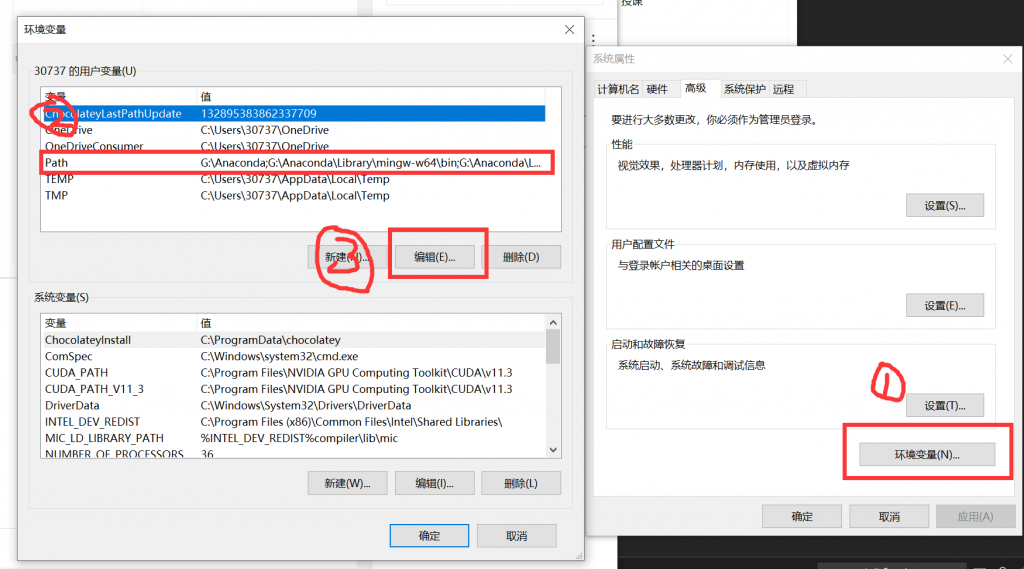
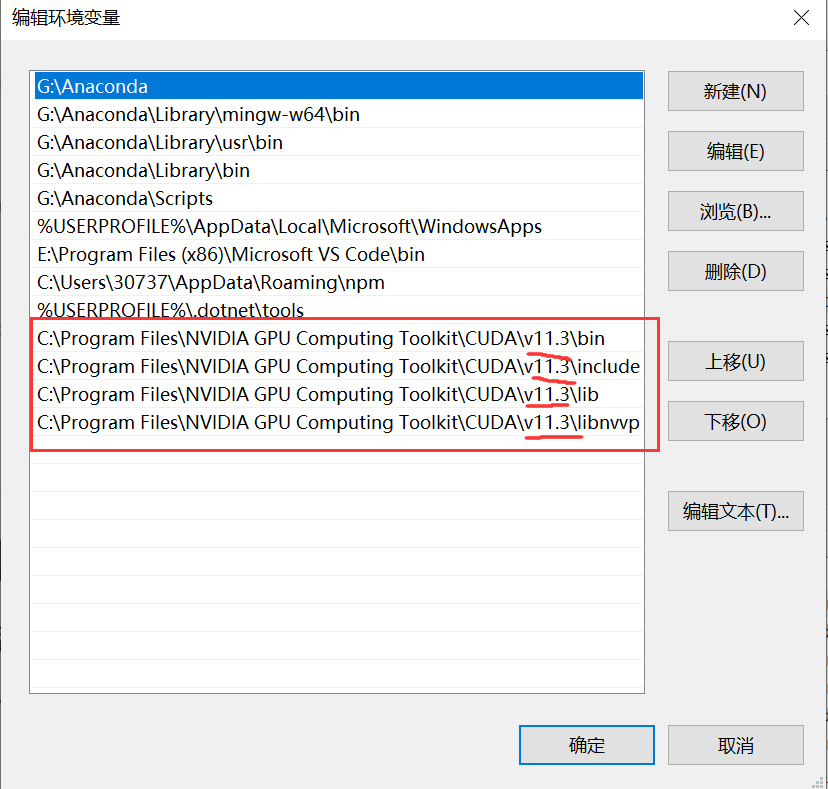
- 然后按照如上图所示步骤选择环境变量按钮,在选中Path一栏,之后点击编辑按钮添加如图所示四个路径,注意不要照抄,每个人的版本号都不一样,该路径就是你CUDA文件夹中的路径,直接复制自己的即可。
- 出现Missing/Not Found尤其是MiDaS/Infer等字样时,在代码左侧有一些数字,这些数字代码出错的代码行号,有midas/Infer出现的行数然后点击数字快速跳转到该行。 如果出现的是小写的midas,或者在midas文件夹内出现的报错(代码里面有import midas类似字样,例如No module named ‘midas.dpt_depth’),例如midas.dpt_depth,则改为MiDaS.midas.dpt_depth,所有的代码都一致。 如果出现是Infer,则加上AdaBins前缀,例如AdaBins.Infer(注意有’.’字符连接)
- 出现UnicodeDecodeError包含midas等内容所在时,找到报错内容最后几行,with open或者open或者opencv等字样,点击对应数字行号打开该文件代码,添加with open(xxx, ‘r’, encoding=‘utf-8’)字样,即原本括号内代码为xxxx,然后添加, ‘r’, encoding=‘utf-8’字样(注意都要为英文)
训练集下载
- 训练集下载链接:/s/1rE-3amZQ8gBEXIQcetawCQ 密码:gmi1
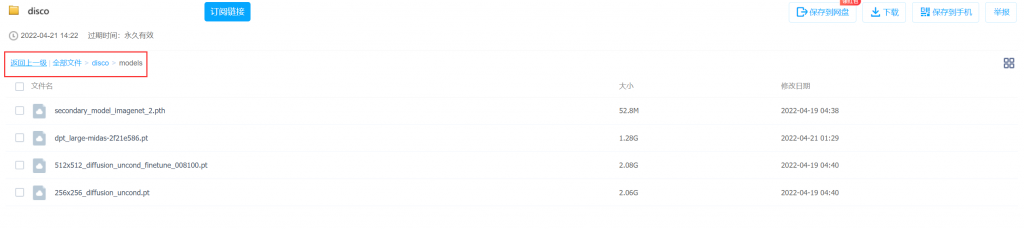
- 找到百度云盘中的models文件夹,并把文件夹中所有内容都下载下来,然后将里面内容放到你的disco-diffusion\models文件夹中。
- 之后一次从头开始顺序点击按钮直到4.Diffuse!代码块前
最终运行
- 之后根据网络直接使用中的内容,找到对应名称代码调整参数

- 在VScode中找到全部运行按钮点击运行即可,同理,图片会显示在4.Diffuse!代码块下方。
- ---## Linux(什么?你都用Linux还要我来教你搭环境?)
标签:
ai
本文转载自: https://blog.csdn.net/sugarsama/article/details/125620702
版权归原作者 sugarsama 所有, 如有侵权,请联系我们删除。
版权归原作者 sugarsama 所有, 如有侵权,请联系我们删除。