
一、grep基本介绍
全拼:Global search REgular expression and Print out the line.
从grep的全称中可以了解到,grep是一个可以利用”正则表达式”进行”全局搜索”的工具,grep会在文本文件中按照指定的正则进行全局搜索,并将搜索出的行打印出来。
当然,不使用正则表达式时也可以使用grep,但是当grep与正则表达式结合在一起时,威力更强大。
使用grep命令在文本中查找指定的字符串,就像你在windows中打开txt文件,使用快捷键 “Ctrl+F” 在文本中查找某个字符串一样,说白了,可以把grep理解成字符查找工具。
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行.
模式:由正则表达式的元字符及文本字符所编写出的过滤条件﹔
grep的语法格式:
grep -option(参数) ‘word’(关键词) file(文本文件);
grep参数:
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
二、正则表达式grep实践
首先先看一下这个测试文件的内容吧:
test.txt
I aaam teacher
I aaaaaam student
I like Linux
I like JAVA
Hello World
世界,你好!
12312434
324828
fdjsoifjidosa
joijofids.
joijiodsf.
#jidfjisoaf
#fjidsfoijsdaifo
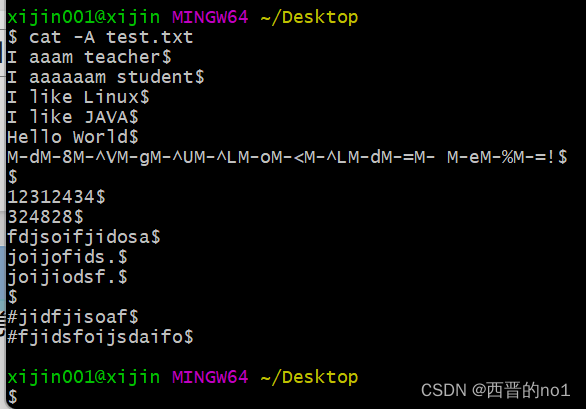
- 注意在Linux平台下, 所有文件的结尾都有一个$符
- 可以利用cat -A 查看文件
cat -A test.txt
注意:如果要在windows下验证本文内容,需要做下述两个准备
1.Windows 系统下使用grep 命令: Windows 系统下使用grep 命令_西晋的no1的博客-CSDN博客
2.测试文件参考链接中转换方式1进行处理:
shell脚本报错:“syntax error: unexpected end of file“ 原因和解决_西晋的no1的博客-CSDN博客
2.1、从test.txt文本文件中搜索包含”L”字符的行,则可以使用如下命令
grep "L" test.txt
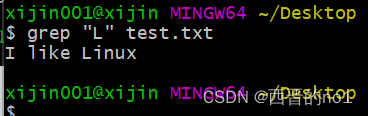
上图中的命令表示使用grep命令,在test.txt文件中搜索包含”L”字符的行,并将包含L字符的行打印出来。
默认情况下,grep是区分大小写的,所以,文件中包含小写”l”的行没有被打印出来。
2.2、输出以 I 开头的行(不区分大小写)
grep "^i" test.txt -i -n -o

注: -i代表不区分大小写, -n代表显示匹配行和行号,-o可以只显示被匹配到的关键字, 而不是将整行的内容都输出,注意,”-o”选项会把每个匹配到的关键字都单独显示在一行中进行输出,什么意思呢?看如下示例即可明白
grep "L" test.txt -i -n -o
grep "L" test.txt -i -n --color
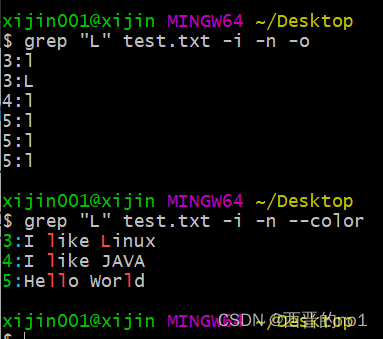
如上图所示,当没有使用”-o”选项时,包含"L"字符的行都会被打印出来,当同一行中包含多个"L"时,所在行会被打印出来,对应的关键字也会高亮显示,当使用了”-o”选项时,每个被匹配到的关键字都会被单独打印在一行中,如上图所示,第1个"L"与第2个"L"都属于第3行的文本,但是它们仍然各自独占一行的输出了。
2.3、grep的参数--color
使用grep在文本中搜索出的行虽然会被打印了出来,但是在打印这些行时,被匹配到的关键字没有高亮显示,如果我们想要高亮显示行中的关键字,该怎么办呢?我们可以使用”--color”选项,高亮显示行中的关键字,示例如下
grep "L" test.txt -i -n --color
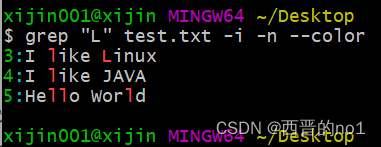
注:”--color选项”是长选项,使用”--color”与使用”--color=auto”的效果相同,都表示高亮显示关键字。
2.4、grep的参数-Bn
"-B”选项,显示符合条件的行之前的行,"B"有before之意,示例如下
grep "L" test.txt -i -n --color -B2
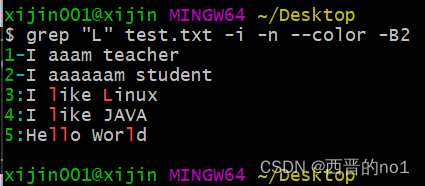
如上图所示,包含字符”L″的行被高亮输出了,同时,符合条件的行”之前的2行”也被打印了出来。
没错,上例中的”-B2″选项表示显示符合条件的行的同时还显示之前的2行,举一反三,"B5"代表同时显示之前的5行,"-B3"代表同时显示之前的3行,”-B”选项的后面必须有数字,否则会报错。
2.5、grep的参数-An
与"-B"选项对应的选项是"-A"选项,"-B"有Before之意,"-A"有After之意,"-A"代表显示符合条件的行的同时,还要显示之后的行,"-A3"表示同时显示符合条件的行之后的3行。
grep "L" test.txt -i -n --color -A2
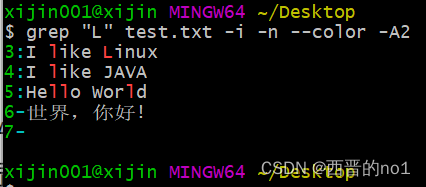
2.6、grep的参数-Cn
说了"-A",说了"-B",现在说说"-C","-C"选项可以理解为"-A"与"-B"的结合,"-C"选项表示在显示符合条件的行的同时,也会显示其前后的行,如"-C1","-C1"表示打印符合条件的行的同时,也打印出之前的一行与之后的一行,"-C"有Context之意(上下文之意),示例如下。
grep "L" test.txt -i -n --color -C2
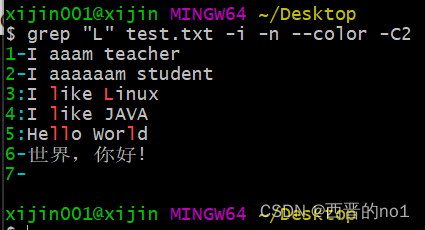
2.7、grep的参数-q
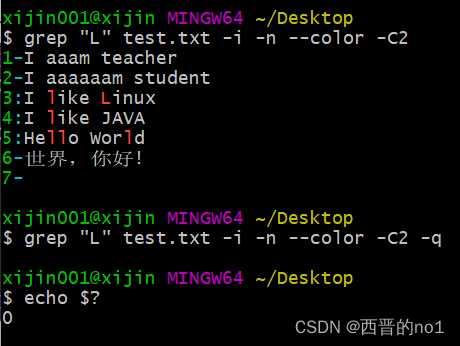
在写脚本时,你可能只是想要利用grep判断文本中是否存在某个字符串,你只关心有没有匹配到,而不关心匹配到的内容,你只关心有,或者没有,这时,我们可以使用grep的静默模式,示例如下
grep "L" test.txt -i -n --color -C2
grep "L" test.txt -i -n --color -C2 -q
echo $?
grep "LLL" test.txt -i -n --color -C2
grep "LLL" test.txt -i -n --color -C2 -q
echo $?
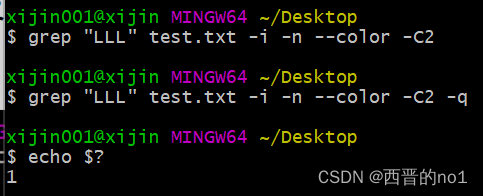
当使用"-q"选项时,表示grep使用静默模式,静默模式下grep不会输入任何信息,无论是否匹配到指定的字符串,都不会输出任何信息,所以,我们需要配合"echo $?"命令,查看命令的执行状态,如果返回值为0,证明上一条grep命令匹配到了指定的字符串,如果返回值为1,则证明上一条grep命令没有匹配到指定的字符串,就像上图示例中显示的那样,静默模式下,grep没有输出任何信息,当我们在test.txt文本中查找"L"字符串时,可以匹配到结果,当在文本中查找"LLL"字符串的时候,没有匹配到结果,所以,我们只关心有没有匹配到指定字符时,可以使用"-q"选项,但是需要配合"echo $?"命令查看执行状态。
2.8、grep的参数-c
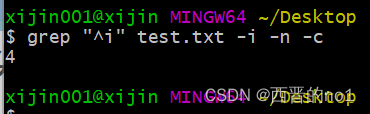
使用”-c”选项即可只统计符合条件的总行数,而不会打印出行。
显示出文章中有多少行有a或b或c
grep "^i" test.txt -i -n -o -c
2.9、输出以.结尾的行
grep "\.$" test.txt -n -o

注: 因为.在这里有着特殊含义, 所以要用\转义一下, 如果不加转义字符的话, grep就会把它当做正则表达式来处理(.代表的含义是匹配任意一个字符)
2.10、grep的参数-c
不打印以.结尾的行
grep "\.$" test.txt -n -v

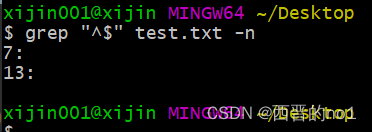
2.11、^$(代表空行的意思)组合符
找出文件的空行, 以及行号
grep "^$" test.txt -n
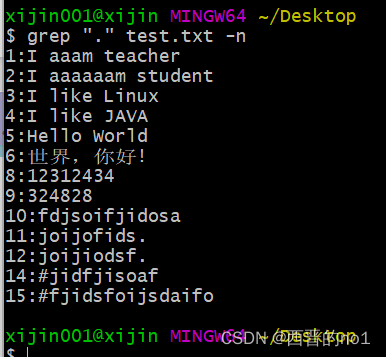
2.12、.点符号
"."点表示任意一个字符, 有且只有一个, 不包含空行
grep "." test.txt -n
2.13、*符号
"*"表示找出前一个字符0次或一次以上
找出文件中i出现0次或多次的行和行号
grep "i*" test.txt -n
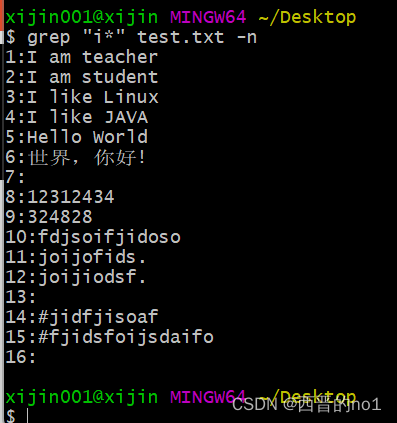
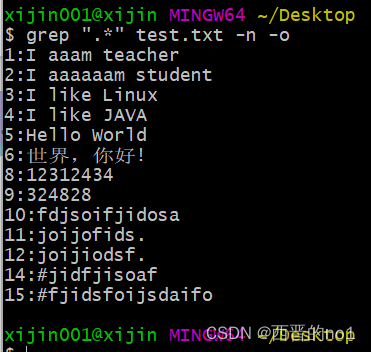
2.14、.*组合符
".*"表示所有内容, 包括空行
grep ".*" test.txt -n -o
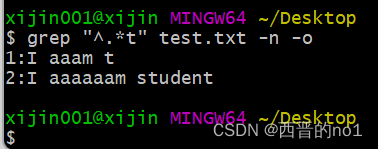
2.15、^.*t符 (含义: 以任意内容开头, 直到t结束)
grep "^.*t" test.txt -n -o
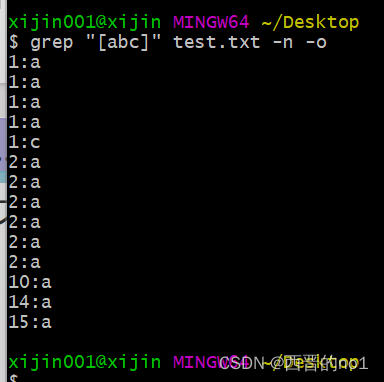
2.16、[abc]中括号
中括号表达式,[abc]表示匹配中括号中任意一个字符, a或b或c,常见的形式如下;
- [a-z]匹配所有小写单个字母[A-Z]匹配所有单个大写字母
- [a-zA-Z]匹配所有的单个大小写字母
- [0-9]匹配所有单个数字
- [a-zA-ZO-9]匹配所有数字和字母
匹配abc字符中的任意一个,得到它的行数和行号
grep "[abc]" test.txt -n -o
2.17、[^abc]中括号中去反
[^abc]或[^a-c]这样的命令, "^"符号在中括号中第一位表示排除, 就是排除字符a,b,c
注: 出现再中括号里的尖角号表示取反
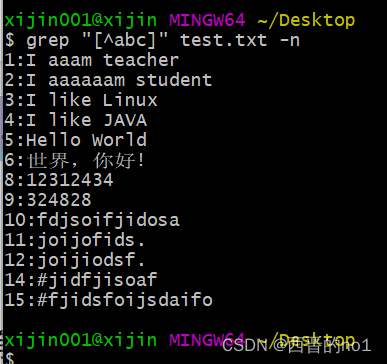
grep "[^abc]" test.txt -n
三、扩展正则表达式grep实践
在使用”-E”选项时,grep才支持”扩展正则表达式”,不使用”-E”选项时,grep默认只支持”基本正则表达式”。
此处使用grep -E进行实践扩展正则, egrep官网已经弃用了
不同的开发语言中,正则表达式的规则可能略有不同,我们在使用grep时,可以使用”-P”选项,指明使用perl兼容的正则表达式。
3.1、+号
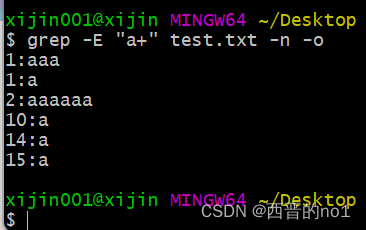
+号表示匹配前一个字符1一次或多次,必须使用grep-E扩展正则
grep -E "a+" test.txt -n -o
3.2、?符
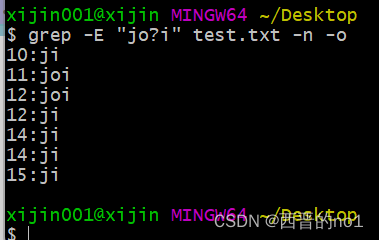
匹配前一个字符0次或1次
找出文件中包含ji或者joi的行
grep -E "jo?i" test.txt -n -o
3.3、|符
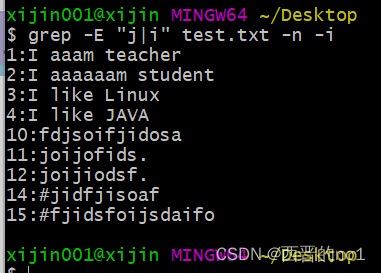
竖线|在正则中是或者的意思
找出文件中包含j或者i的行, 不区分大小写(-i)
grep -E "j|i" test.txt -n -i
3.4、()小括号
将一个或多个字符捆绑在一起, 当作一个整体进行处理
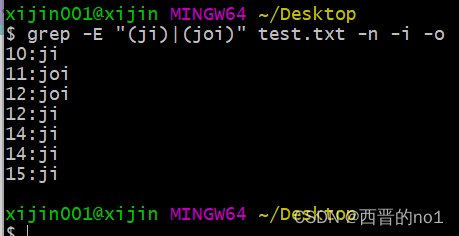
grep -E "(ji)|(joi)" test.txt -n -i -o
3.5、{n,m}匹配次数
{n,m}:匹配前一个字符至少n次, 最多m次
{n,}: 匹配前一个字符至少n次, 没有上限
{,m}: 匹配前一个字符最多m次,可以没有
重复前一个字符各种次数, 可以通过-o参数显示明确的匹配过程
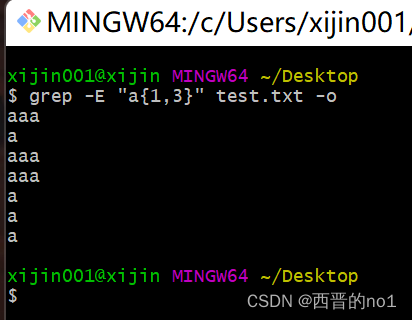
grep -E "a{1,3}" test.txt -o
四、总结
为了方便以后回顾,将grep的常用选项总结如下
–color=auto 或者 –color:表示对匹配到的文本着色显示
-i:在搜索的时候忽略大小写
-n:显示结果所在行号
-c:统计匹配到的行数,注意,是匹配到的总行数,不是匹配到的次数
-o:只显示符合条件的字符串,但是不整行显示,每个符合条件的字符串单独显示一行
-v:输出不带关键字的行(反向查询,反向匹配)
-w:匹配整个单词,如果是字符串中包含这个单词,则不作匹配
-Ax:在输出的时候包含结果所在行之后的指定行数,这里指之后的x行,A:after
-Bx:在输出的时候包含结果所在行之前的指定行数,这里指之前的x行,B:before
-Cx:在输出的时候包含结果所在行之前和之后的指定行数,这里指之前和之后的x行,C:context
-e:实现多个选项的匹配,逻辑or关系
-q:静默模式,不输出任何信息,当我们只关心有没有匹配到,却不关心匹配到什么内容时,我们可以使用此命令,然后,使用”echo $?”查看是否匹配到,0表示匹配到,1表示没有匹配到。
-P:表示使用兼容perl的正则引擎。
-E:使用扩展正则表达式,而不是基本正则表达式,在使用”-E”选项时,相当于使用egrep。
版权归原作者 西晋的no1 所有, 如有侵权,请联系我们删除。