
linux 内核接口atomic_long_try_cmpxchg_acquire详解
1 atomic_long_try_cmpxchg_acquire/release
1.1 atomic_long_try_cmpxchg_acquire
static __always_inline bool
atomic_long_try_cmpxchg_acquire(atomic_long_t *v,long*old,longnew){returnatomic64_try_cmpxchg_acquire(v,(s64 *)old,new);}
1.2 atomic_long_try_cmpxchg_release
static __always_inline bool
atomic_long_try_cmpxchg_release(atomic_long_t *v,long*old,longnew){returnatomic64_try_cmpxchg_release(v,(s64 *)old,new);}
2 arch_atomic64_cmpxchg_acquire/release
2.1 arch_atomic64_cmpxchg_acquire/release定义
#define arch_atomic64_cmpxchg_acquire atomic64_cmpxchg_acquire
#define arch_atomic64_cmpxchg_release atomic64_cmpxchg_release
2.2 atomic64_cmpxchg_acquire/release
#ifdefined(arch_atomic64_cmpxchg_acquire)static __always_inline s64
atomic64_cmpxchg_acquire(atomic64_t *v, s64 old, s64 new){instrument_atomic_read_write(v,sizeof(*v));returnarch_atomic64_cmpxchg_acquire(v, old,new);}
#define atomic64_cmpxchg_acquire atomic64_cmpxchg_acquire
#endif
#ifdefined(arch_atomic64_cmpxchg_release)static __always_inline s64
atomic64_cmpxchg_release(atomic64_t *v, s64 old, s64 new){instrument_atomic_read_write(v,sizeof(*v));returnarch_atomic64_cmpxchg_release(v, old,new);}
#define atomic64_cmpxchg_release atomic64_cmpxchg_release
#endif
2.3 instrument_atomic_read_write
原子读写访问
/**
* instrument_atomic_read_write - instrument atomic read-write access
*
* Instrument an atomic read-write access. The instrumentation should be
* inserted before the actual write happens.
*
* @ptr address of access
* @size size of access
*/static __always_inline voidinstrument_atomic_read_write(constvolatilevoid*v, size_t size){kasan_check_write(v, size);kcsan_check_atomic_read_write(v, size);}
2.4 arch_atomic64_cmpxchg_acquire/release
#define arch_atomic64_cmpxchg_acquire arch_atomic_cmpxchg_acquire
#define arch_atomic64_cmpxchg_release arch_atomic_cmpxchg_release
2.5 arch_atomic_cmpxchg_acquire/release
#define arch_atomic_cmpxchg_acquire(v, old,new) \
arch_cmpxchg_acquire(&((v)->counter),(old),(new))
#define arch_atomic_cmpxchg_release(v, old,new) \
arch_cmpxchg_release(&((v)->counter),(old),(new))
2.6 arch_cmpxchg_acquire/release
#define arch_cmpxchg_acquire(...)__cmpxchg_wrapper(_acq, __VA_ARGS__)
#define arch_cmpxchg_release(...)__cmpxchg_wrapper(_rel, __VA_ARGS__)
2.7 __cmpxchg_wrapper
- 对于
arch_cmpxchg_acquire来说,sfx指代的是_acq - 对于
arch_cmpxchg_release来说,sfx指代的是_rel sizeof(*(ptr))表示要访问地址对应的数据宽度
#define __cmpxchg_wrapper(sfx, ptr, o, n) \
({ \
__typeof__(*(ptr)) __ret; \
__ret =(__typeof__(*(ptr))) \
__cmpxchg##sfx((ptr),(unsigned long)(o), \
(unsigned long)(n),sizeof(*(ptr))); \
__ret; \
})
2.8 __cmpxchg##sfx
__CMPXCHG_GEN()表示为__cmpxchg__CMPXCHG_GEN(_acq)表示为__cmpxchg_acq__CMPXCHG_GEN(_rel)表示为__cmpxchg_rel__CMPXCHG_GEN(_mb)表示为__cmpxchg_mb
#define __CMPXCHG_GEN(sfx) \
static __always_inline unsigned long __cmpxchg##sfx(volatilevoid*ptr, \
unsigned long old, \
unsigned longnew, \
int size) \
{ \
switch(size){ \
case1: \
return __cmpxchg_case##sfx##_8(ptr, old,new); \
case2: \
return __cmpxchg_case##sfx##_16(ptr, old,new); \
case4: \
return __cmpxchg_case##sfx##_32(ptr, old,new); \
case8: \
return __cmpxchg_case##sfx##_64(ptr, old,new); \
default: \
BUILD_BUG(); \
} \
\
unreachable(); \
}__CMPXCHG_GEN()__CMPXCHG_GEN(_acq)__CMPXCHG_GEN(_rel)__CMPXCHG_GEN(_mb)
2.9 _xchg_case##name##sz
__XCHG_CASE(w, b, , 8, , , , , , )对应着__xchg_case_8,其所对应的ld" #acq "xr" #sfx "\t%" #w "0, %2为ldxrb "\t%" #w "0, %2;所对应的st" #rel "xr" #sfx "\t%w1, %" #w "3, %2为stxrb "\t%w1, %" #w "3, %2;相对应的arm64汇编指令为ldxrb和stxrb__XCHG_CASE(w, b, acq_, 8, , , a, a, , "memory")对应着__xchg_case_acq_8,其所对应的ld" #acq "xr" #sfx "\t%" #w "0, %2为ldaxrb "\t%" #w "0, %2;所对应的st" #rel "xr" #sfx "\t%w1, %" #w "3, %2为stxrb "\t%w1, %" #w "3, %2;相对应的arm64汇编指令为ldaxrb和stxrb
/*
* We need separate acquire parameters for ll/sc and lse, since the full
* barrier case is generated as release+dmb for the former and
* acquire+release for the latter.
*/
#define __XCHG_CASE(w, sfx, name, sz, mb, nop_lse, acq, acq_lse, rel, cl) \
static inline u##sz __xchg_case_##name##sz(u##sz x,volatilevoid*ptr) \
{ \
u##sz ret; \
unsigned long tmp; \
\
asm volatile(ARM64_LSE_ATOMIC_INSN( \
/* LL/SC */ \
" prfm pstl1strm, %2\n" \
"1: ld" #acq "xr" #sfx "\t%" #w "0, %2\n" \
" st" #rel "xr" #sfx "\t%w1, %" #w "3, %2\n" \
" cbnz %w1, 1b\n" \
" " #mb, \
/* LSE atomics */ \
" swp" #acq_lse #rel #sfx "\t%" #w "3, %" #w "0, %2\n" \
__nops(3) \
" " #nop_lse) \
:"=&r"(ret),"=&r"(tmp),"+Q"(*(u##sz *)ptr) \
:"r"(x) \
: cl); \
\
return ret; \
}__XCHG_CASE(w, b,,8,,,,,,)__XCHG_CASE(w, h,,16,,,,,,)__XCHG_CASE(w,,,32,,,,,,)__XCHG_CASE(,,,64,,,,,,)__XCHG_CASE(w, b, acq_,8,,, a, a,,"memory")__XCHG_CASE(w, h, acq_,16,,, a, a,,"memory")__XCHG_CASE(w,, acq_,32,,, a, a,,"memory")__XCHG_CASE(,, acq_,64,,, a, a,,"memory")__XCHG_CASE(w, b, rel_,8,,,,, l,"memory")__XCHG_CASE(w, h, rel_,16,,,,, l,"memory")__XCHG_CASE(w,, rel_,32,,,,, l,"memory")__XCHG_CASE(,, rel_,64,,,,, l,"memory")__XCHG_CASE(w, b, mb_,8, dmb ish, nop,, a, l,"memory")__XCHG_CASE(w, h, mb_,16, dmb ish, nop,, a, l,"memory")__XCHG_CASE(w,, mb_,32, dmb ish, nop,, a, l,"memory")__XCHG_CASE(,, mb_,64, dmb ish, nop,, a, l,"memory")
2.10 ldxr
2.10.1 ldxr
加载排他寄存器从基本寄存器值获取地址,从内存中加载32位字或64位双字,并将其写入寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由独占存储指令检查的。
2.10.2 ldxrb
加载排他寄存器字节从一个基本寄存器值派生一个地址,从内存加载一个字节,零扩展它,并将其写入一个寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由独占存储指令检查的。
2.10.3 LDXRH
加载排他寄存器半字从基本寄存器值获得地址,从内存加载半字,零扩展它并将其写入寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由独占存储指令检查的。
2.11 ldaxr
2.11.1 ldaxr
加载-获取独占寄存器从基本寄存器值获取地址,从内存中加载32位字或64位双字,并将其写入寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由独占存储指令检查的。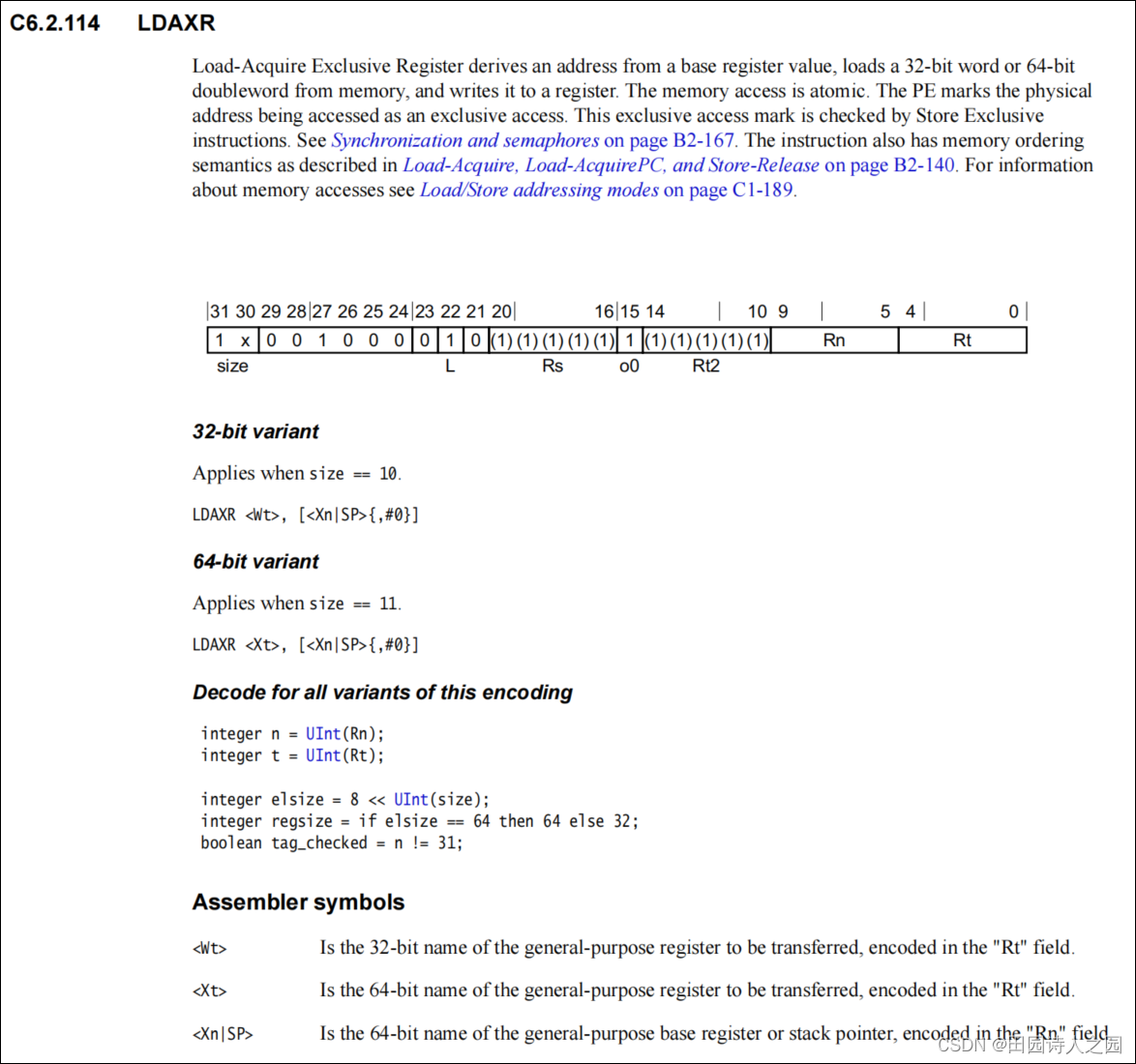
2.11.2 ldaxb
加载-获取独占寄存器字节从一个基本寄存器值派生一个地址,从内存加载一个字节,零扩展它,并将其写入一个寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由存储独占指令检查的。
2.11.3 LDAXRH
加载获取独占寄存器半字从基本寄存器值获得地址,从内存加载半字,零扩展它并将其写入寄存器。内存访问是原子式的。PE将被访问的物理地址标记为独家访问。此独家访问标记是由存储独占指令检查的。
2.12 stxr
2.12.1 STXR
如果PE对内存地址具有独占访问权限,则独家存储器从寄存器存储32位字或64位双字,如果存储成功,返回状态值为0,如果没有执行存储,则返回状态值为1。

2.12.2 STXRB
存储独占寄存器字节如果PE只访问内存地址,则存储从寄存器到内存的字节,如果存储成功,则返回状态值为0,如果没有执行存储,则返回状态值为1。内存访问是原子式的。
2.12.3 stxrh
如果PE对内存地址有独占访问,则存储寄存器存储到内存,如果存储成功,返回状态值为0,如果没有执行存储,返回状态值为1。内存访问是原子式的。
版权归原作者 田园诗人之园 所有, 如有侵权,请联系我们删除。