
文章目录
前言
跟着白哥学Java,今天就来分享一下Java如何上传文件到hdfs上面,
提示:以下是一点见解
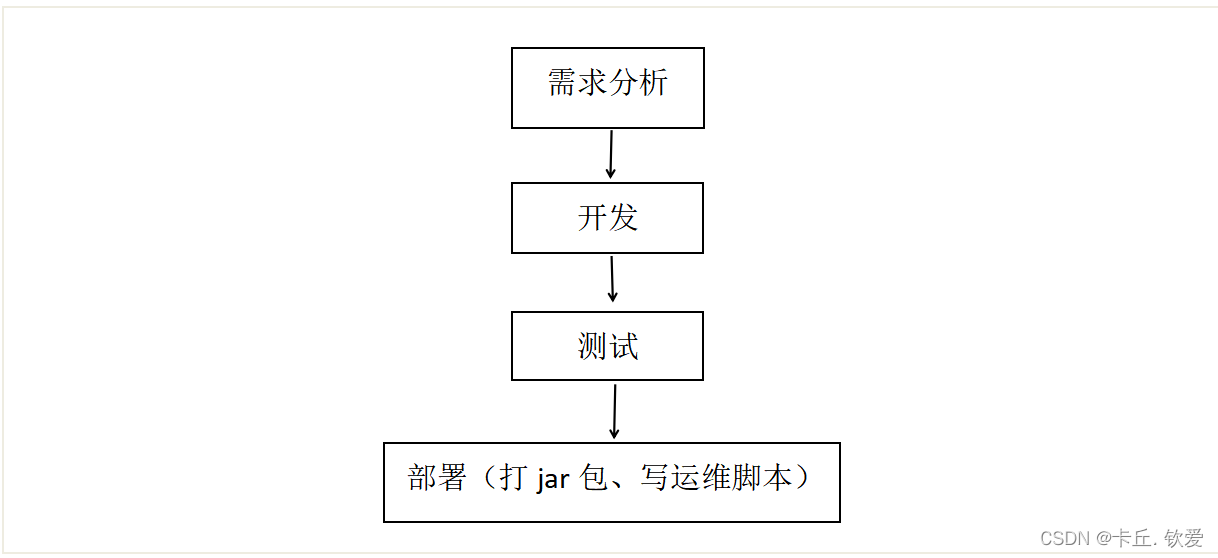
一、项目大体流程
我们想要上传到hdfs,首先就得知道hdfs是什么东西:
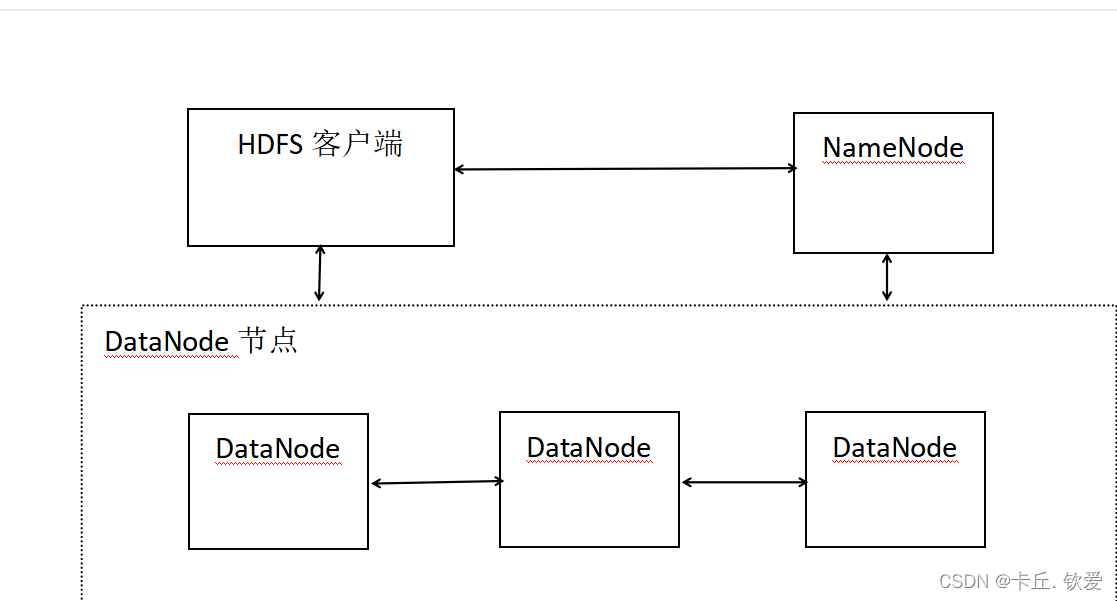
**本质:**HDFS的中文翻译是****Hadoop分布式文件系统****(Hadoop Distributed File System)。它本质还是程序,主要还是以****树状目录结构****来管理文件(和linux类似,/表示根路径),且可以运行在多个节点上(即分布式)。
**解决的问题:**存储海量离线数据(如TB、PB、ZB级别的数据),并且保证数据高可用,支持高并发访问。注:不适合将****大量的小文件****存到HDFS。(主要原因:HDFS的NameNode进程在内存中存储文件的元数据,故文件越多,消耗的内存就越大。大量的小文件,耗尽NameNode节点的内存,而实际存的文件总量却很小,HDFS存海量数据的优势没有发挥出来)
**架构:**HDFS的架构如下,其中在Linux端的详细部署就不一一赘述了
我们的项目构成如下:
二、详细步骤
1.在idea里面创建空项目(小白也能看懂)
图解(示例):
注意:一般idea会自带一个jdk是20以上的,如果版本不和心意,也可以点下载,选择合适的jdk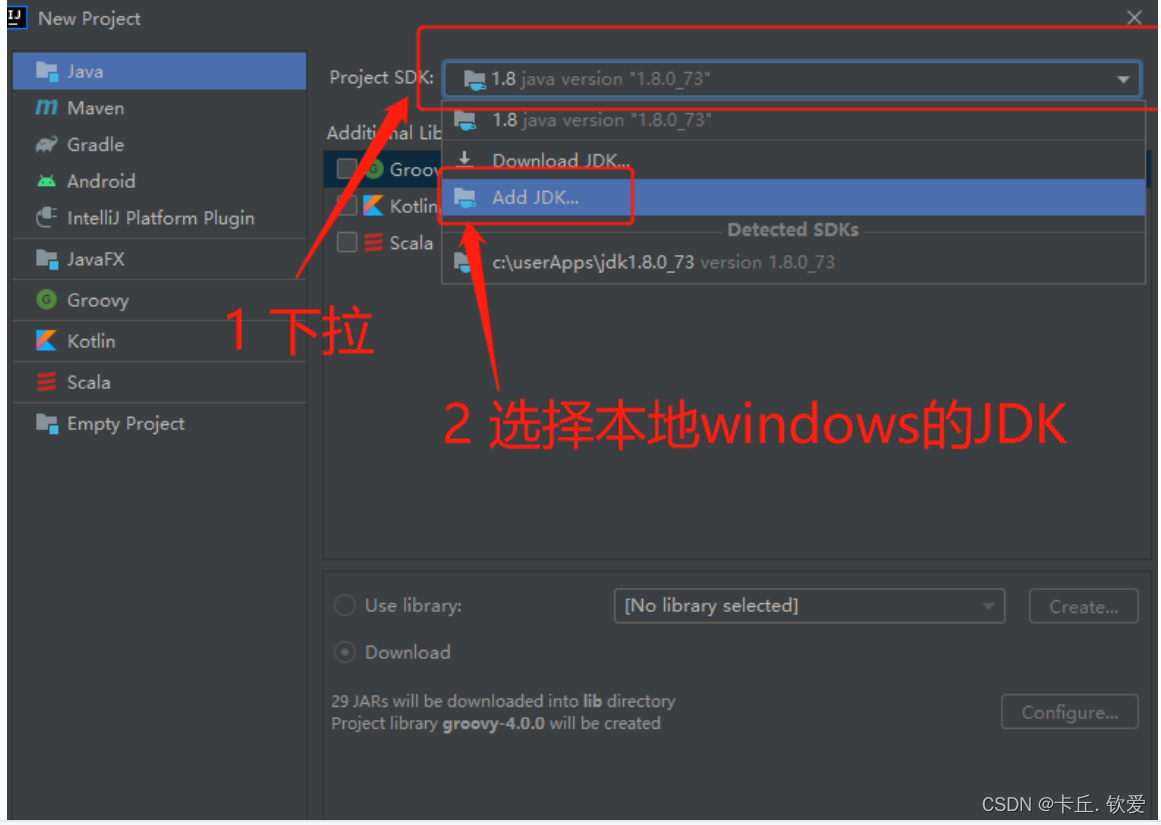
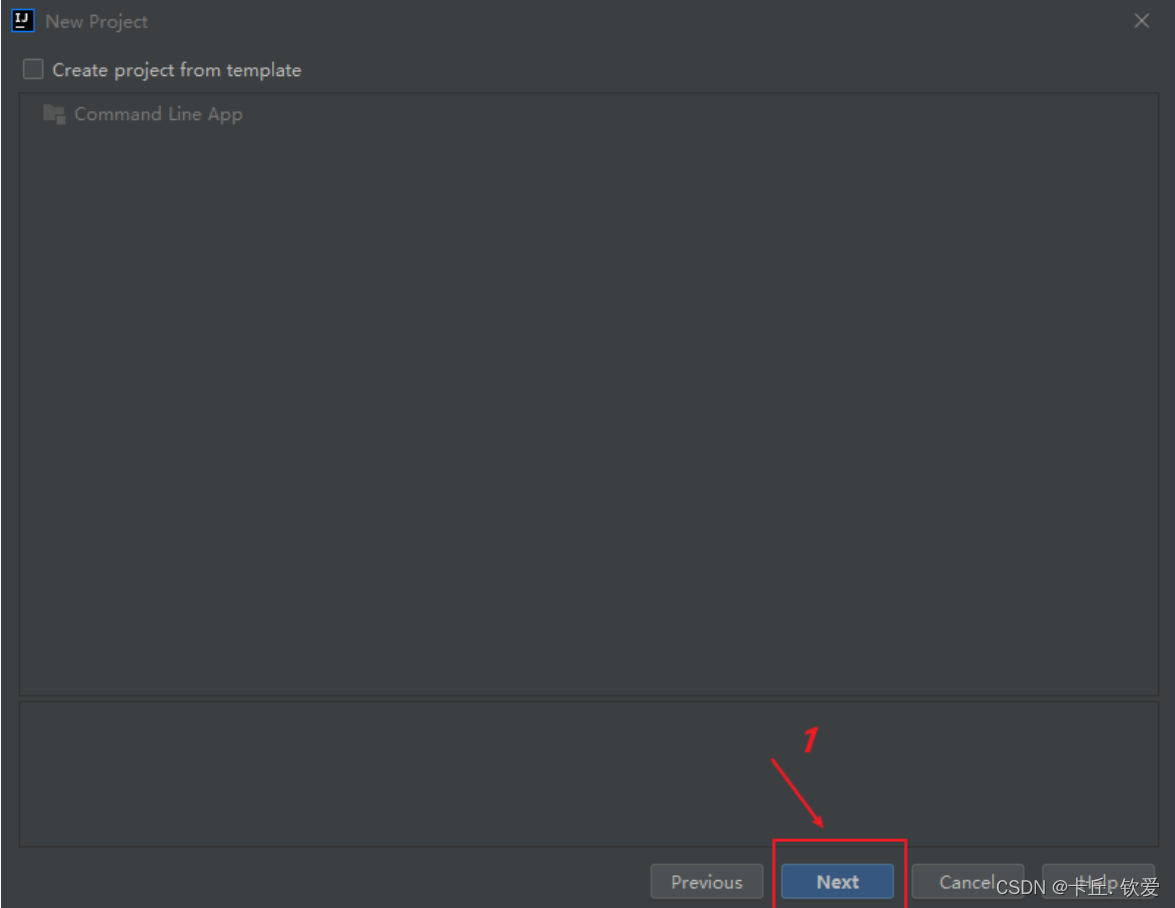
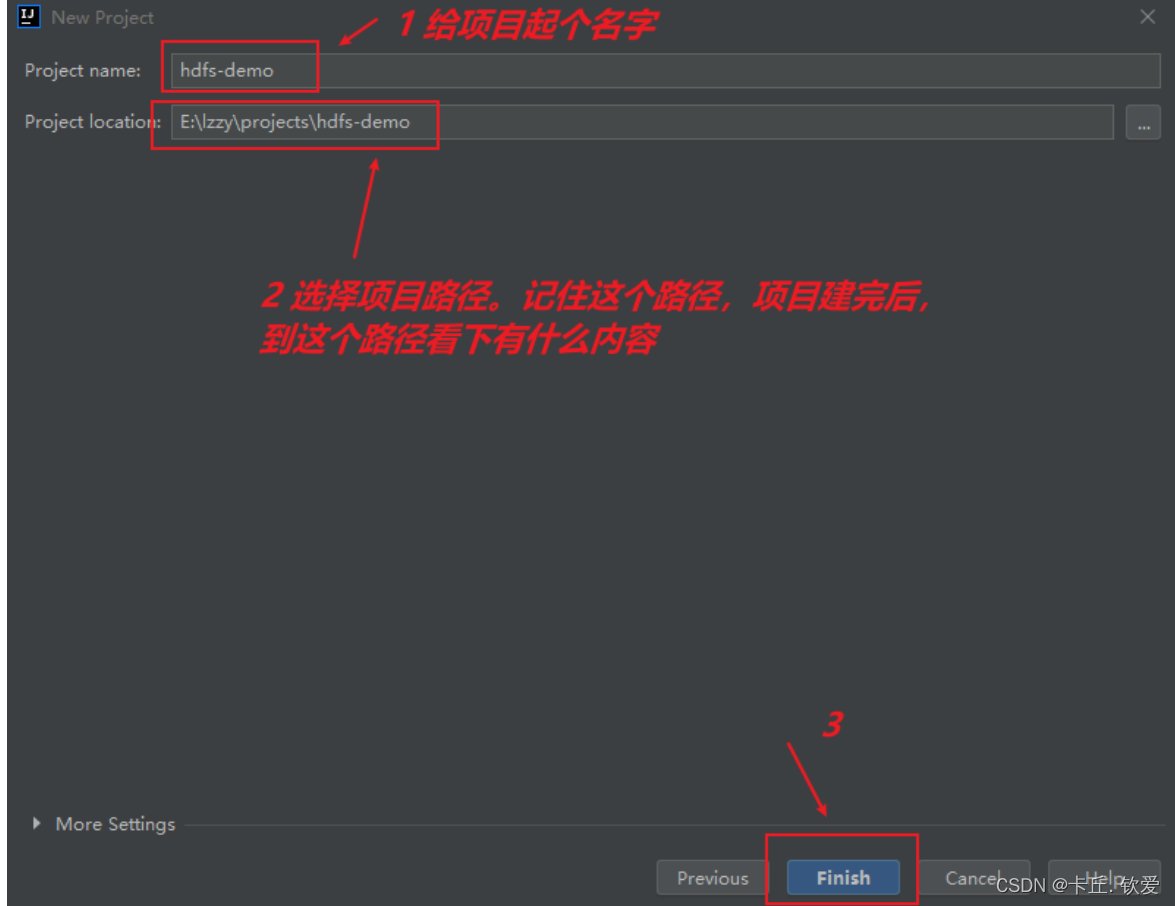
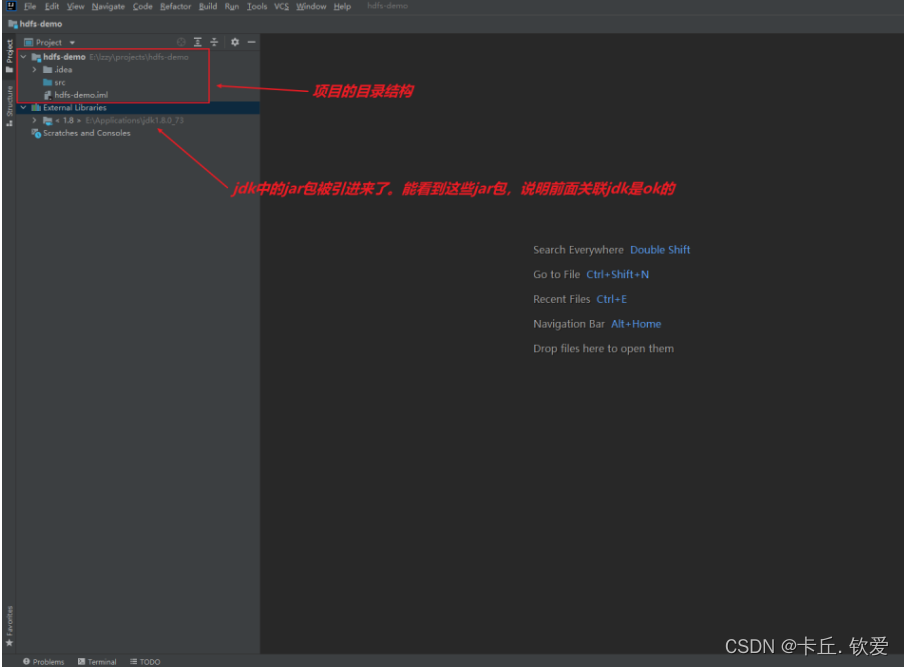

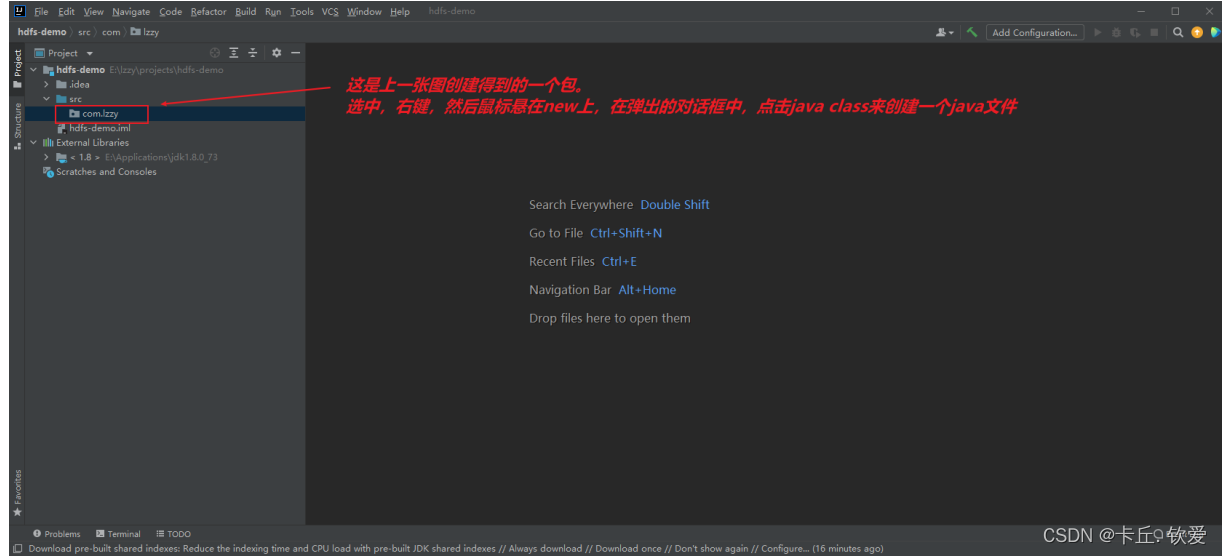
好的,这样子我们就得到一个空项目了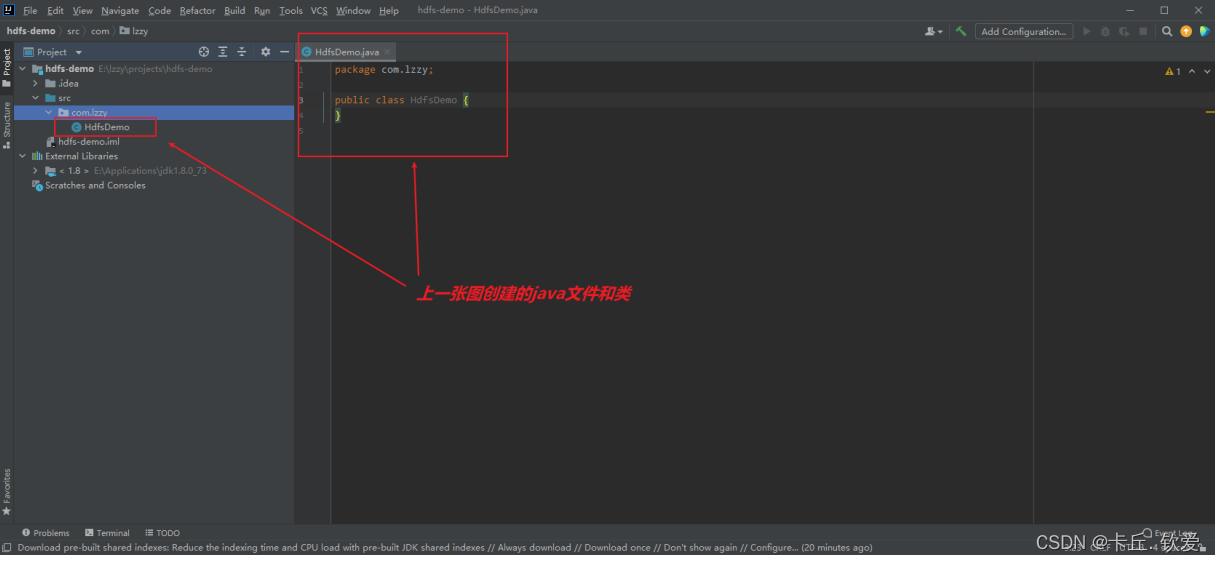
2.导入所需的jar包
新建一个项目后,将HDFS相关的jar包引入到项目中,目的是调用HDFS提供的相关的类、方法。我们现在将所需要的jar依赖导入进来,接下来要进行导包:

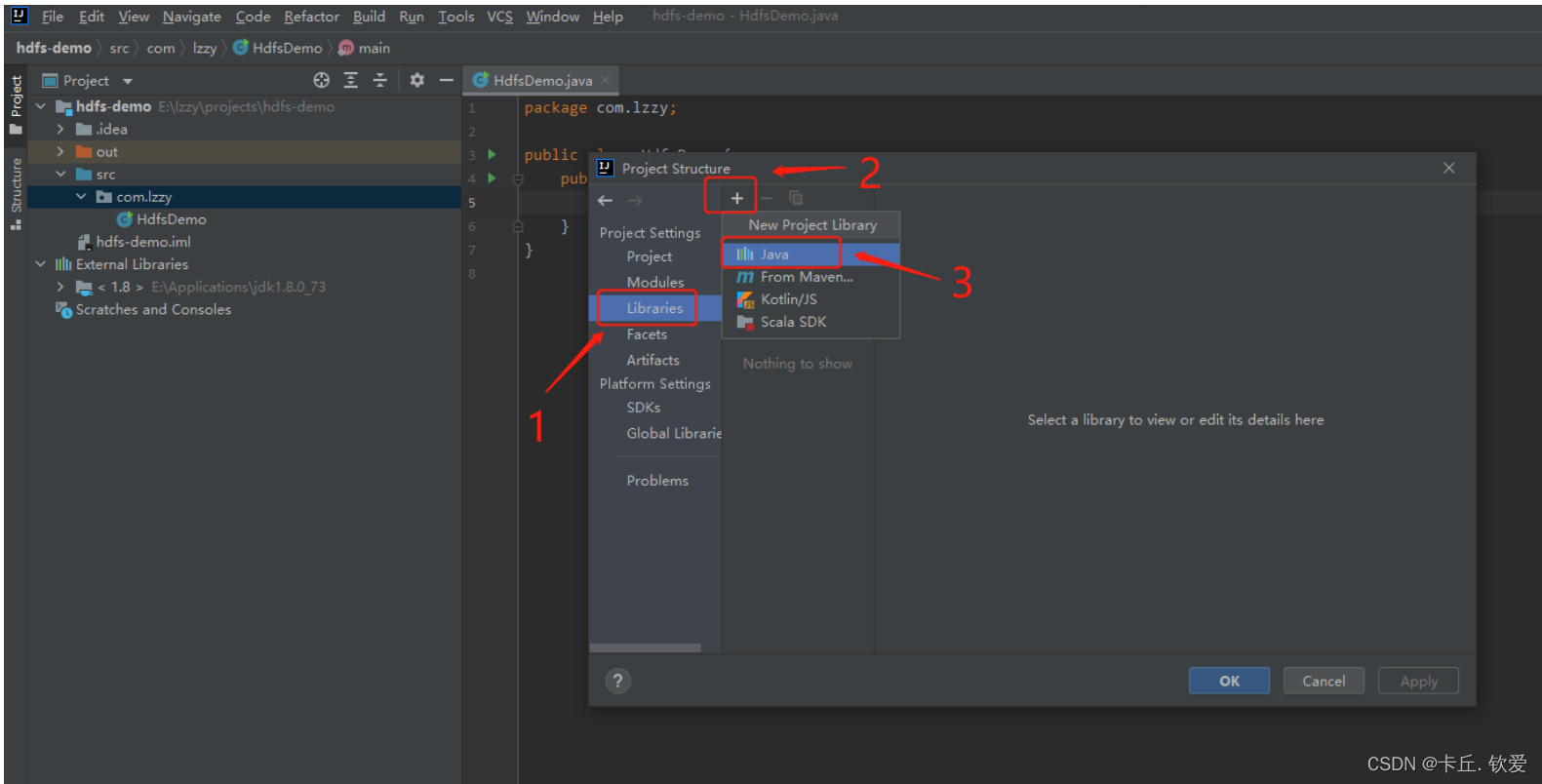
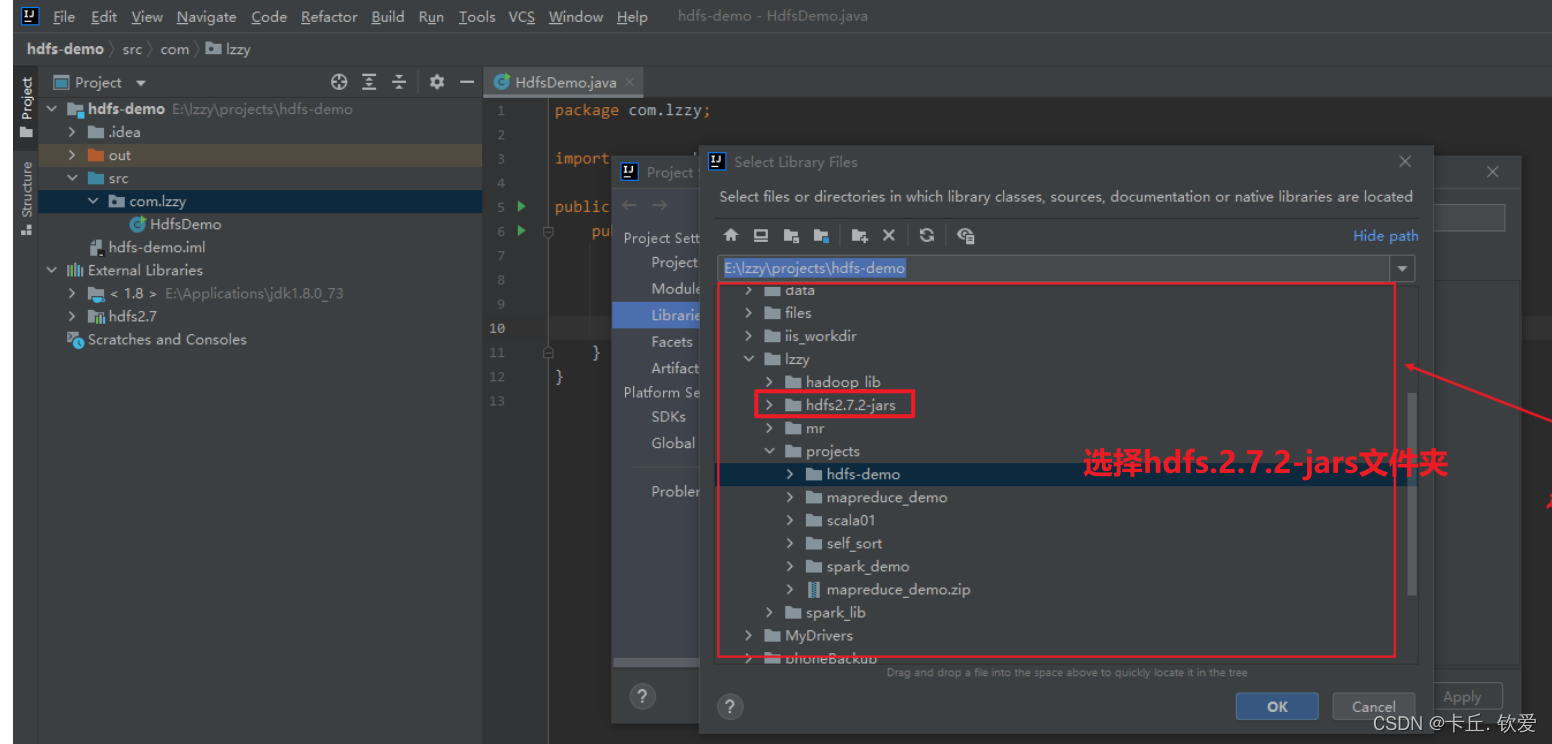
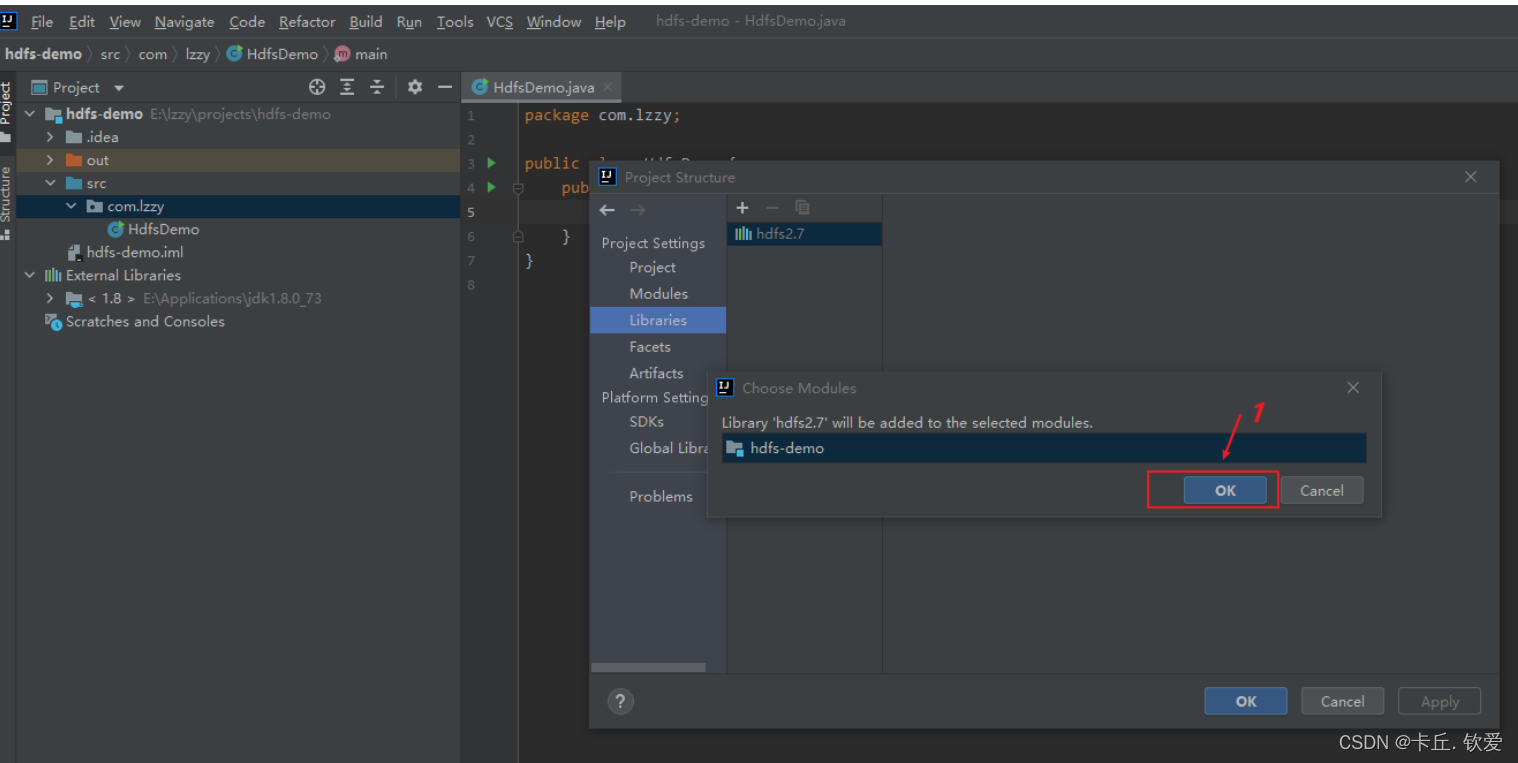
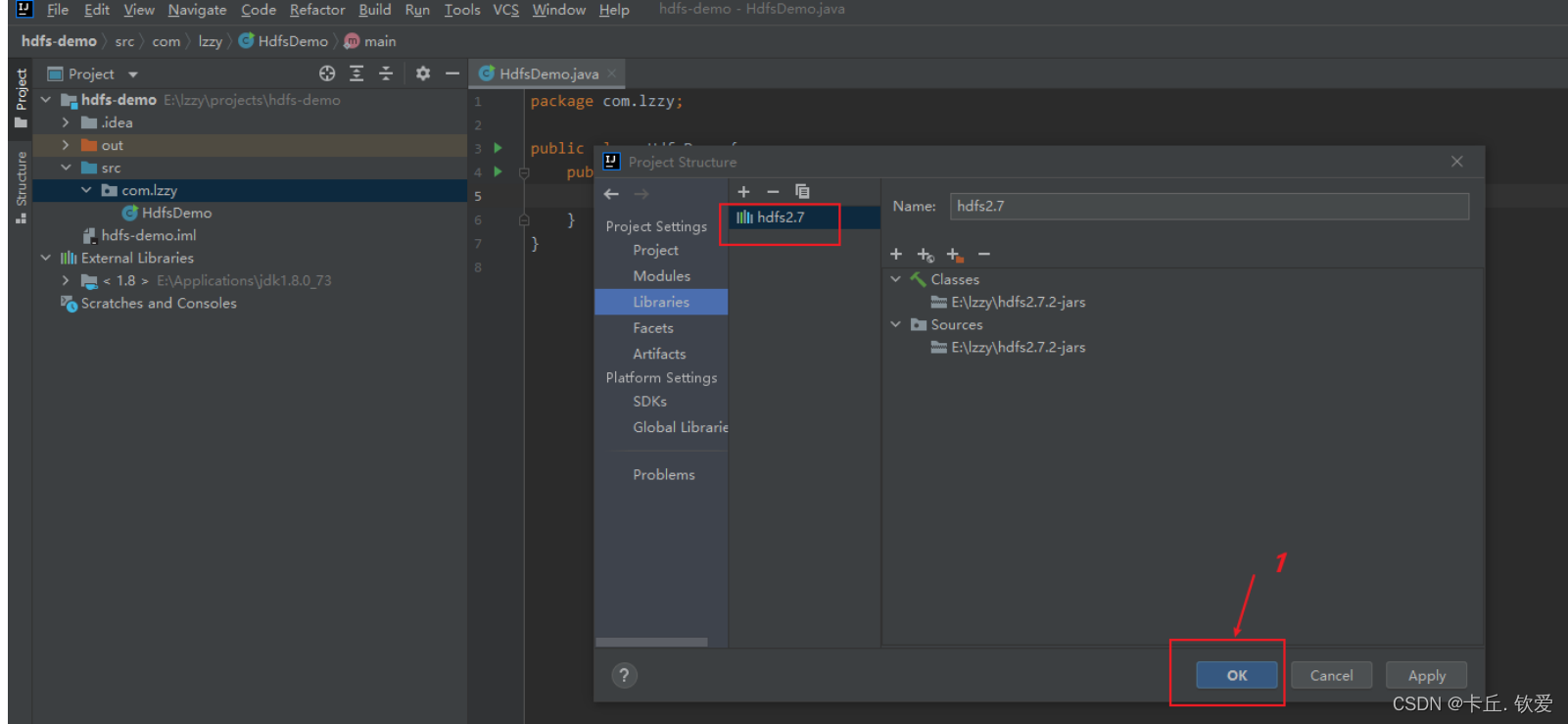
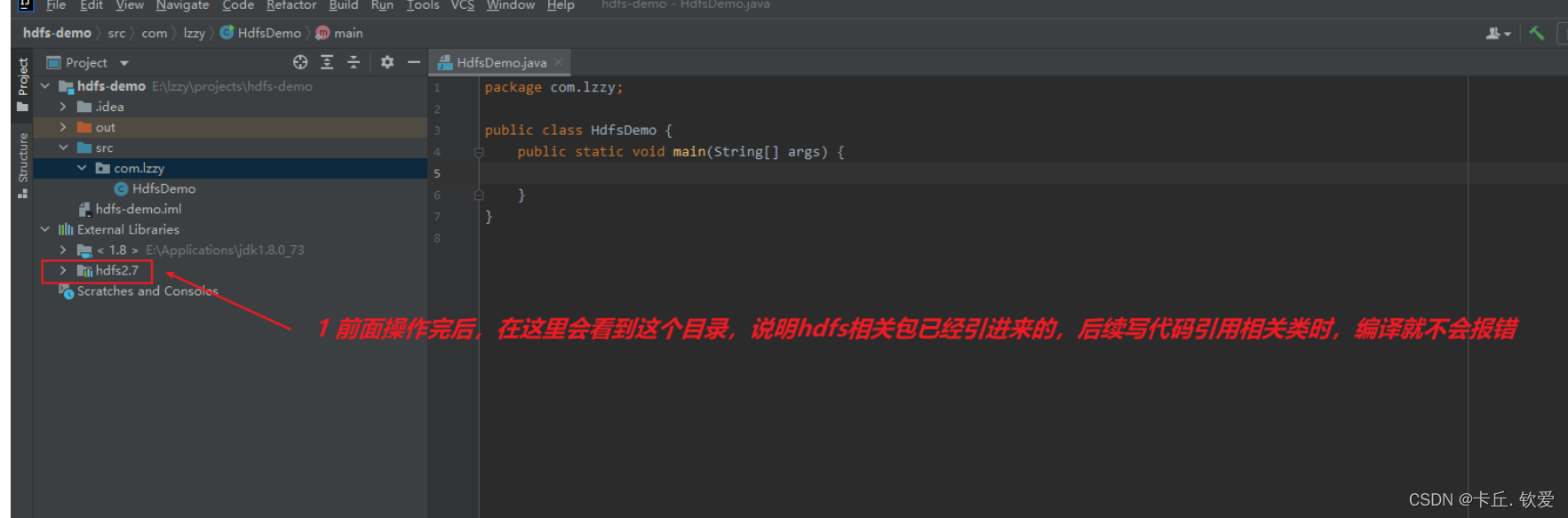
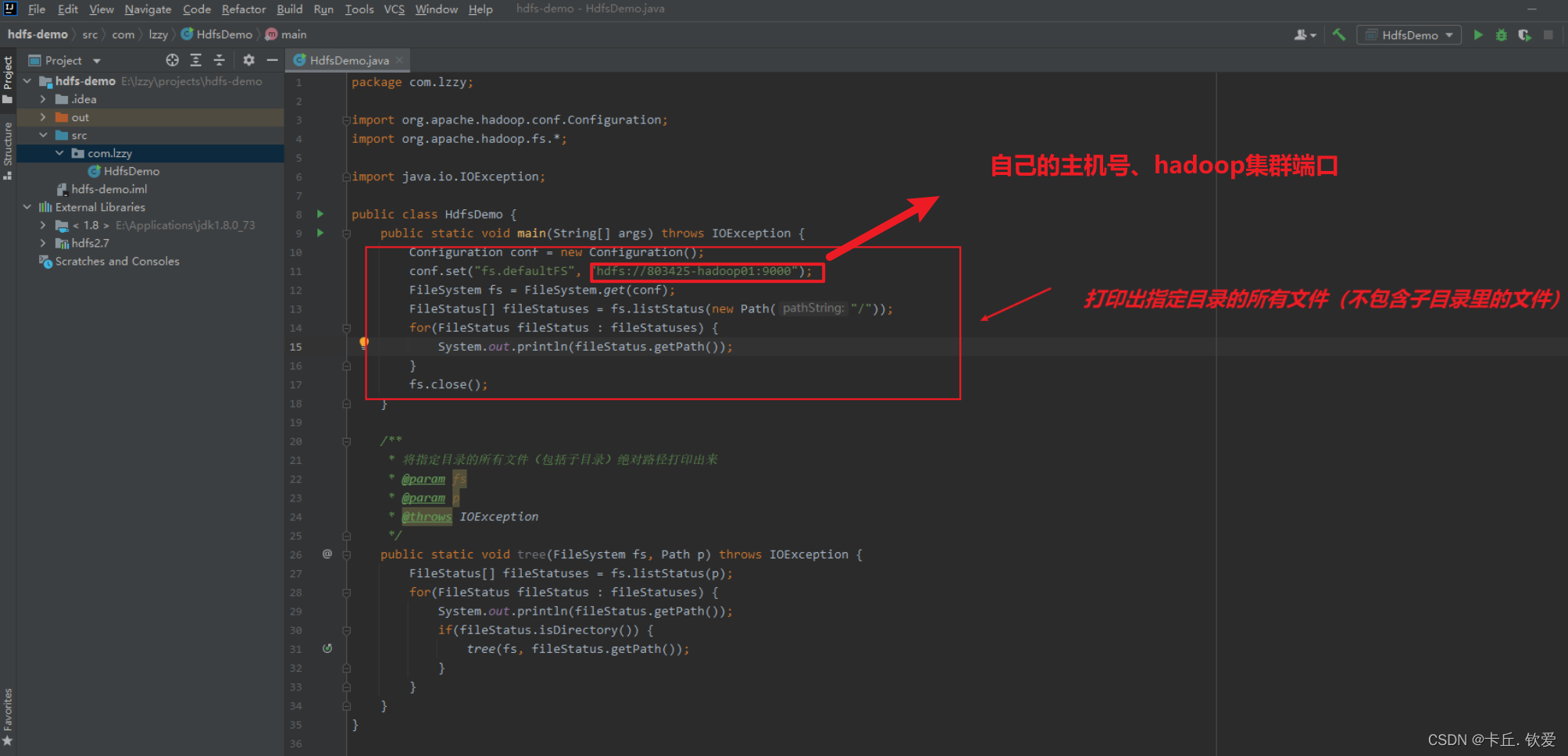
2.输入代码后就可以实现了
public static void main(String[] args) throws IOException {
if(args.length == 0){
System.out.println("创建失败,请传入一个路径参数指定要读取的文件");
return;
}
String feilePath = args[0];
System.out.println("传入的名字是:"+feilePath);
//1.创建词汇表Configuration类型的对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://20210322045-master:9000");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream fsDataInputStream = fs.open(new Path(feilePath));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
//读取文件第一行字符串,如果返回null,表明已经读取到文件的末尾
String nextLine = bufferedReader.readLine();
//如果没有读取到末尾,则继续读取
while (null != nextLine){
//将读取到的数据输出到控制台
System.out.println(nextLine);
nextLine = bufferedReader.readLine();
}
fs.close();
}
图解(示例):
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
本文转载自: https://blog.csdn.net/qq_51294997/article/details/131038660
版权归原作者 卡丘. 钦爱 所有, 如有侵权,请联系我们删除。
版权归原作者 卡丘. 钦爱 所有, 如有侵权,请联系我们删除。