
Selenium 操作被检测屏蔽
selenium打开浏览器模仿人工操作是诸多爬虫小白最万能的网页数据获取方式,但是在做自动化爬虫时,经常被检测到是selenium驱动。前段时间selenium打开维普高级搜索时得到的页面是空白页。
Selenium为何会被检测
主要原因是selenium打开的浏览器指纹和人工操作打开的浏览器指纹是不同的,比如最熟知的
window.navigator.webdriver
关键字,在selenium打开的浏览器打印返回结果为true,而正常浏览器打印结果返回为
undefined
,我们可以在 网站比较各关键字。
Selenium防检测方法
1. 修改
window.navigator.webdriver
关键字返回结果
from selenium import webdriver
options = webdriver.ChromeOptions()
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
但是因为浏览器指纹很多,这种方法的局限性是显而易见的。
2. 使用stealth.min.js文件防止selenium被检测
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
driver = Chrome('./chromedriver', options=chrome_options)
with open('/Users/kingname/test_pyppeteer/stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
stealth.min.js
文件来源于puppeteer,有开发者给 puppeteer 写了一套插件,叫做
puppeteer-extra
。其中,就有一个插件叫做
puppeteer-extra-plugin-stealth
专门用来让 puppeteer 隐藏模拟浏览器的指纹特征。
python开发者就需要把其中的隐藏特征的脚本提取出来,做成一个 js 文件。然后让 Selenium 或者 Pyppeteer 在打开任意网页之前,先运行一下这个 js 文件里面的内容。
puppeteer-extra-plugin-stealth
的作者还写了另外一个工具,叫做
extract-stealth-evasions
。这个东西就是用来生成stealth.min.js文件的。
stealth.min.js资源:
链接:https://pan.baidu.com/s/1wiFnwOlHx3Wxe1UzW5gdrg
提取码:6hqf
3. undetected_chromedriver
undetected_chromedriver
使用方法
undetected_chromedriver 可以防止浏览器特征被识别,并且可以根据浏览器版本自动下载驱动。
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get('https://nowsecure.nl')
这是目前在用的一种方法,基本可以解决selenium被识别的问题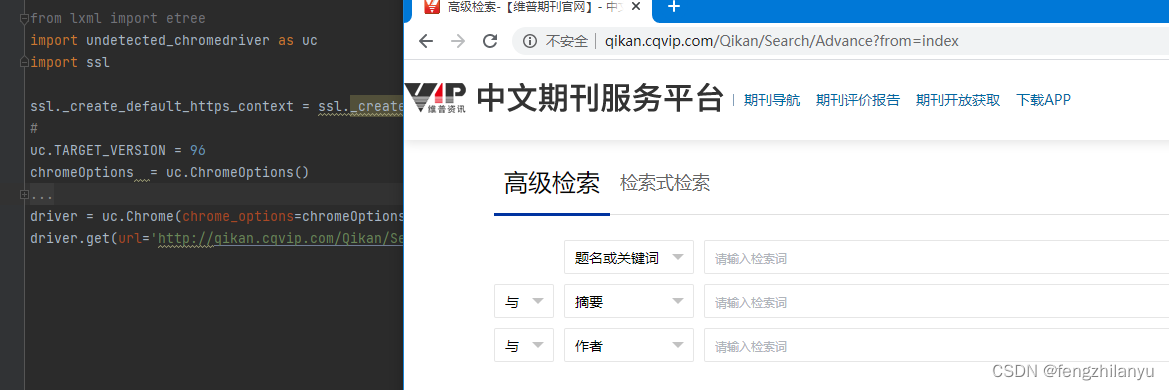
本文转载自: https://blog.csdn.net/fengzhilanyu/article/details/124745539
版权归原作者 fengzhilanyu 所有, 如有侵权,请联系我们删除。
版权归原作者 fengzhilanyu 所有, 如有侵权,请联系我们删除。