
目录
数组与链表
数组
在学习Java的初期,我们认识了一种能够存储多个数据的数据结构——数组,其中数据在空间中是连续的,因其具有索引值的原因,它在根据索引值查询数据时拥有着很大的优势,但是在对内容进行增、删操作的时候却是很复杂的。
我们简单创建一个长度为5的数组:

删除索引值为2元素时,数组的变化过程。
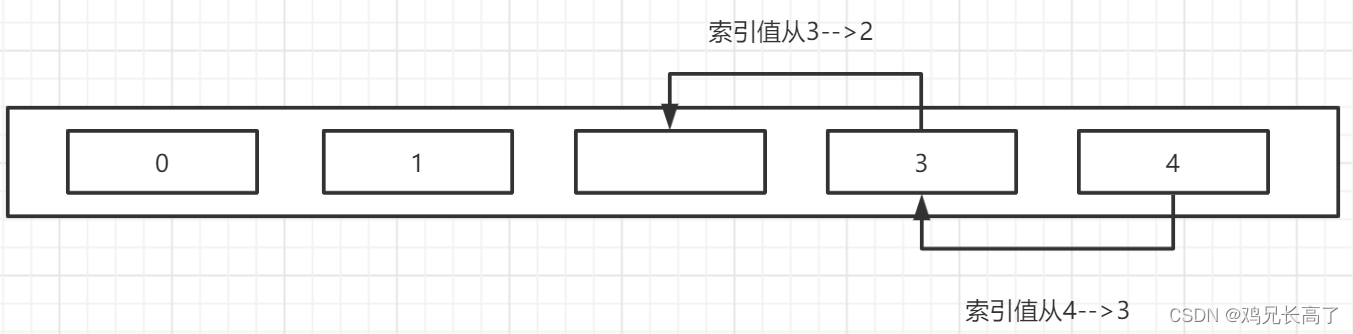
数组新增过程与删除过程类似,比如要在索引值为2的位置新增元素,索引值>=2的所有元素都要后移一个,十分复杂,效率低。
链表
而链表是每个值的空间可以不连续的一种数据结构。

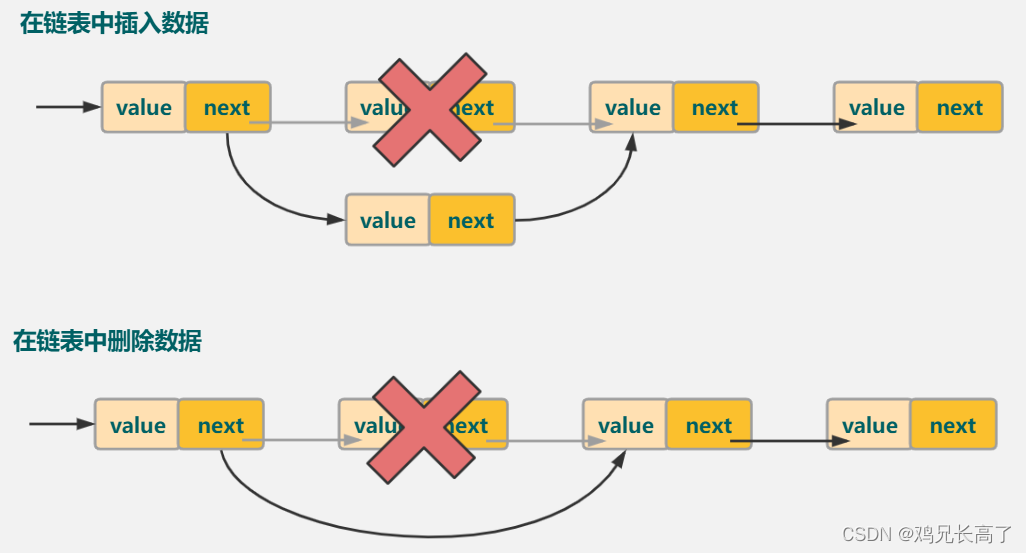
链表有着增删快的特点。
增加元素时:①更改上一个元素的指向地址值(更改为新增元素的地址值)
②更改增加元素的指向地址值(更改为上一个元素原本指向的地址值)
删除同理。
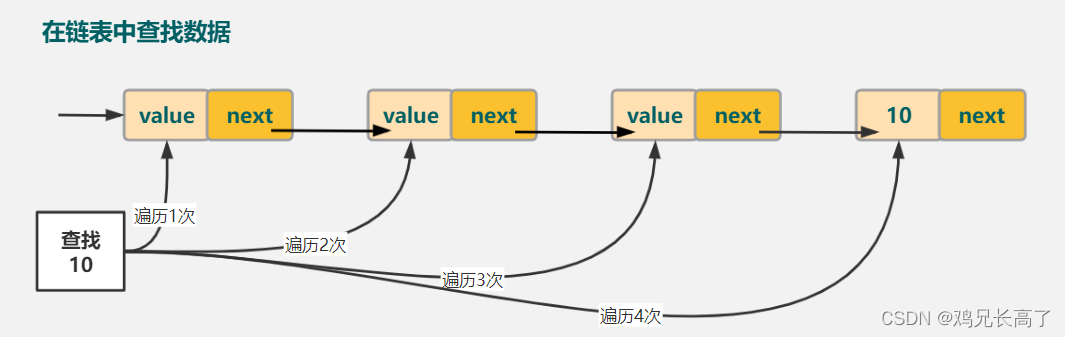
但是链表在查询数据时没有优势,只能通过逐个遍历的方式来进行查询。
为提高效率有双向链表的存在,指从两个方向来遍历查找元素,但是速度不会比数组快。
哈希表
现在我们引入这样一个数据结构,它是由数组和链表/红黑树结构组合而成的。
当我们学习到集合时,会学到Set接口的一个实现类:HashSet,它的底层就是使用了哈希表(HashMap)的数据结构,它的特点是:无索引值,元素不重复。
哈希表的新增过程
public static void main(String[] args) {
HashSet<Integer> list = new HashSet<>();
list.add(10);
list.add(10);
list.add(20);
list.add(30);
System.out.println(list); //输出结果为:[20, 10, 30]
}
我们来创建一个HashSet类型的集合,根据关键性原码来简述一下元素的新增过程。
//此时进行增加操作,e为我们新增的元素值,E为元素的泛型:Integer
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//此时add相当于进行了HashMap中的put方法,key为我们新增的元素值
public V put(K key, ...) {
return putVal(hash(key), ...);
}
//此时key为我们新增的元素值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
①hash方法对新增的值进行了一定的操作,我们新增的元素不为null,则通过(h = key.hashCode()) ^ (h >>> 16)计算元素的哈希值,返回给put方法。
final V putVal(int hash, ...) {}
计算完hash值将结果传入 putVal方法。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; //OldCap为0
int oldThr = threshold; //oldThr为0
int newCap, newThr = 0;
if (oldCap > 0) {
...
}
else if (oldThr > 0)
...
else { //执行此代码块中操作
newCap = DEFAULT_INITIAL_CAPACITY; //数组的初始长度为16
}
...
}
②添加第一个值时数组还未创建,则第一次添加后,将数组长度初始化为16,数组类型为java.util.HashMap$Node。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
Node类型中有个成员变量next,并且类型也是Node,可知这是一个单向链表结构,next表示指向的下一个元素。
final V putVal(int hash, ...) {
if ((p = tab[i = (n - 1) & hash]) == null)
//通过某操作计算出元素索引值i(伪索引)
...
}
③数组已经创建,数组长度为16。上述计算出元素伪索引的操作课简单描述为hash%数组长度。因此可得出0~15之间的某一个值。
final V putVal(int hash,...) {
...
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
...
}
因为是添加的第一个元素,索引值位置的值一定为null,此时会new一个Node类型的对象。
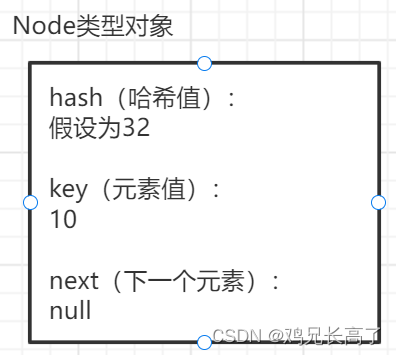
进行操作后得出索引值位置:
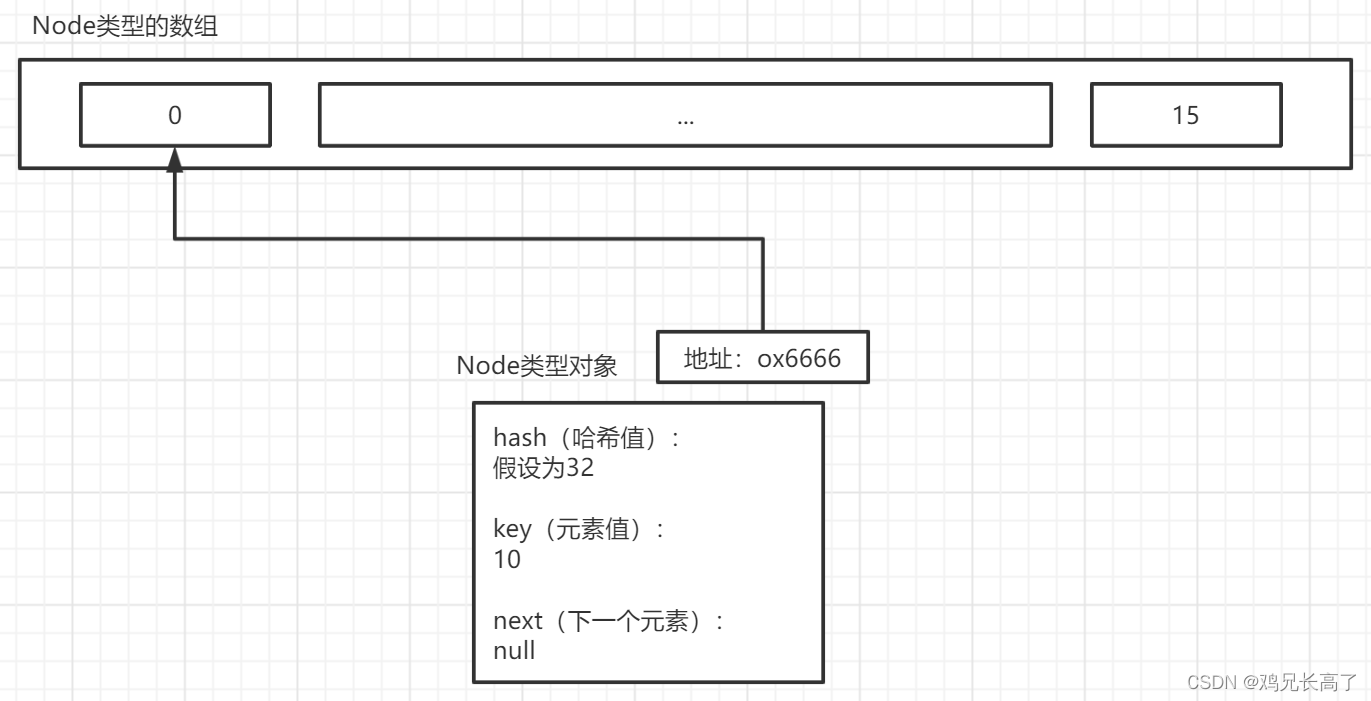
④如果新增的位置为null,则直接新增。
final V putVal(int hash, ...) {
...
else {
...
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
...
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//p为此索引值下已存在的值
//k为新增的值
break;
p = e;
...
}
...
}
⑤如果新增位置不为null时,因为Set接口中规定元素是不能重复的,则通过p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))进行元素是否重复的判断。
因为Node中存的都是引用数据类型,因此==比较的是地址值。
简单来说就是将(哈希值相同 &&(地址值相同 || equals值相同)) 值作为判定条件。
我们认为两个值地址相同或者值相同,如String中,两个对象的地址值不同,但是当他们是指向同一个字符串常量池的位置时,通过equals比较时值相同,我们便可以说这两个值是相等的。
因此,如果我们自定义一个类,将他作为HashSet的泛型时,如果想达到存入的值是不重复的效果,需在类中重写HashCode()和 equals()方法。
- 当元素不重复时。将元素新增在该索引值位置链表的最后面。
- 当元素重复时,放弃新增。
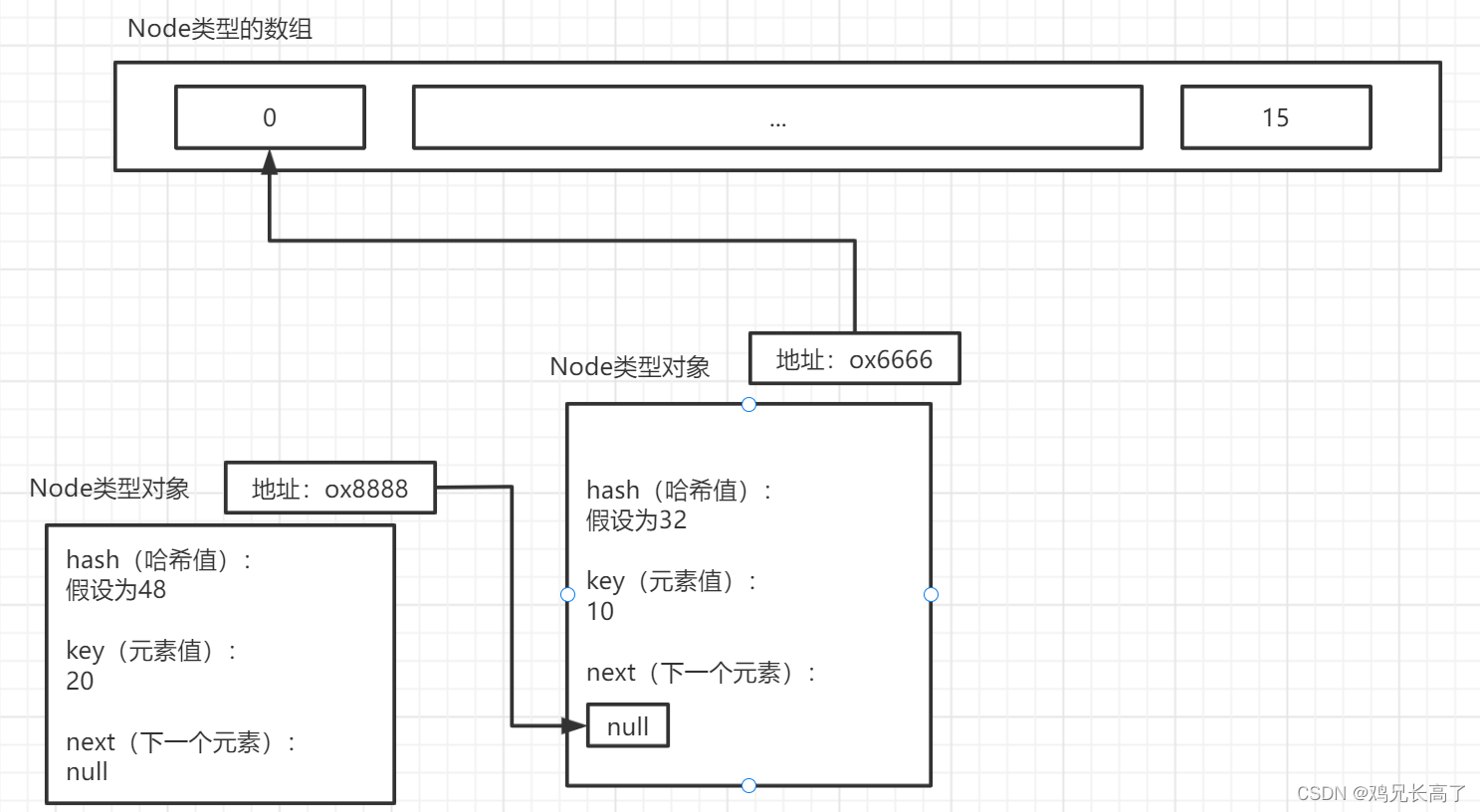
可以看出当索引值位置有值时会添加到该索引值位置链表的最后面。(即next为null的地方)
我们也可以看出来链表在空间上的位置时不连续的。
总结新增过程:
1.计算元素的哈希值
2.当数组已创建,通过哈希值%数组长度确定元素索引值位置。
3.当该索引值位置为null时,直接新增。
4.当该索引值位置不为null时,判定元素是否重复
判断是否重复的方法:比较两个对象的哈希值 && (地址值相同 || equals相同)
- 重复,则新增到该索引值位置链表的最后面
- 重复,则不新增
哈希表是如何进行扩容的(简述)
什么时候扩容:
①当同一索引值下元素个数>8,且数组长度<64(未达到树化条件)
新容量 = 旧容量 << 1(新容量是旧容量的2倍)②当同一索引值下元素个数>8,且数组长度>=64(未达到树化条件)
将链表结构转换为红黑树③当索引值的占用率超过75%进行扩容。
- 如果同一索引值下的元素个数过多,则会增加查询的时间,扩容后元素排列会有变化
- 如0索引值下元素超过8个,进行第一次扩容,扩容后会将本来放在0索引下的元素逐一分配给0索引和16索引
- 当进行第二次扩容,0索引值的元素分配给0和32,16索引值的元素分配给16和48
- 索引值占用率的默认值为0.75(如数组长度为16,13个索引值有元素就扩容),此为加载因子,也可以通过有参构造设置加载因子
- 我们也可以指定容量(哈希表数组长度),但实际创建的数组长度为最近此值的2次方值(如指定100会实际创建长度为128的数组)
构造方法参数含义public HashSet() public HashSet(int capacity)capacity为容量public HashSet(int capacity, float loadFactor)loadFactor为加载因子
关于哈希表的一些其他问题
1.为什么HashSet是无序的
因为先新增的元素可能算出的索引值靠后,后新增的元素值算出来可能在前,而获取元素的值是从前向后的(先获取索引值为0的)。
从我们举的例子可以看出来,存入的顺序为10,20,30。而输出(获取)的结果为:[20, 10, 30]。
2.为什么哈希表没有索引值
我们在上面说的都是伪索引,是Node类型数组的索引值,哈希表底层是Node类型的数组,而Node是链表结构,每个索引值下面可能会有多个元素,因此获取哈希表中的元素不能像数组一样通过下标获取。
本文转载自: https://blog.csdn.net/weixin_46005032/article/details/126335437
版权归原作者 鸡兄长高了 所有, 如有侵权,请联系我们删除。
版权归原作者 鸡兄长高了 所有, 如有侵权,请联系我们删除。