
原书很长,有19.3w字,本文尝试浓缩一下其中的精华。
知识点
GPT相关
谷歌发布LaMDA、BERT和PaLM-E,PaLM 2
Facebook的母公司Meta推出LLaMA,并在博客上免费公开LLM:OPT-175B。
在GPT中,P代表经过预训练(pre-trained),T代表Transformer,G代表生成性的(generative)。
基于大模型提供法律咨询服务的Casetext,利用私域文本嵌入和摘要技术来应对GPT的错误信息风险。
ChatPDF:基于大模型的文档工具,解析PDF,识别内容,理解用户意图和需求,提供文本对话、知识问答等服务。
ShareGPT:浏览器插件产品,用户可以通过ShareGPT保存并分享自己跟ChatGPT的对话记录。
Character.ai:神经语言模型聊天机器人网络应用程序。
ELIZA:1960s年代在麻省理工学院开发的聊天机器人,支持好几种对话脚本,可以模拟人本主义的心理治疗师,跟用户文本交流。
GPT系列模型用过的数据集:
- 维基百科
- 古登堡计划(Project Gutenberg),致力于将文化作品数字化和归档,数字图书馆
- ThePile数据集中的Books3数据
- 自助出版平台Smashwords,维护着Toronto BookCorpus与BookCorpus数据集
- ArXiv论文库
- 美国国家卫生研究院(The National Institutes of Health)数据集
- GitHub
- Reddit:社交媒体平台
- Common Crawl:互联网爬虫
- C4,公共网页数据集,包括各种文章、博客、新闻、论坛等
- Stack Exchange,高质量的问答网站,涵盖从计算机到化学等各种领域的问题和答案
- 斯坦福问答数据集,The Stanford Question Answering Dataset,简称SQuAD。
- 谷歌的自然问答数据集
- TruthfulQA:一个非常容易产生幻觉的数据集,专门用来对幻觉进行测试
临界点:《大语言模型的涌现能力》(Emergent Abilities of Large Language Models)论文说,许多新的能力在中小模型上线性放大规模都得不到线性的增长,模型规模必须要指数级增长超过某个临界点,新技能才会突飞猛进。量变引发质变。
大模型强调规模定律(Scaling Law),要指数级地加大模型来获得性能突增和能力涌现
Hallucination:幻觉,指的是生成式AI的胡诌,杜撰,Confabulation。封闭域幻觉是指人类用户要求大模型仅使用给定背景中提供的信息,但大模型却创造背景中没有的额外信息。开放域幻觉是指大模型在没有参考任何特定输入背景的情况下,提供关于世界的错误信息。
未来人类学习的知识,会有很大一部分源于生成式大模型;大模型生成的内容,存在胡诌和虚假,会对传统人类知识造成污染。OpenAI曾考虑对人工智能生成内容进行水印标记,但并未找到可行的实施方法。因此,这个关于信任的挑战必须由人类自己来面对。
英伟达公司推出针对大模型推理的H100 NVL GPU和DGX CLOUD计算集群。
Anyscale:开发Ray并为OpenAI公司提供框架支持的创业公司,提供SkyPilot,基于多个云服务商的模型训练推理计算资源的代理。给定一项计算任务及资源需求(CPU、GPU或TPU),SkyPilot会自动找出哪些位置(区域和云服务商)具有合适的计算能力,然后将其发送到成本最低的位置执行。
TPU,Tensor Processing Unit,张量处理单元,张量处理器,Google开发的专用集成电路,专门用于加速机器学习。
NPU:神经网络处理器,Neural Network Processing Unit,用电路模拟人类的神经元和突触结构。典型代表有国内的寒武纪芯片和IBM的TrueNorth。
PUGC:Professional User Generated Content
PUGM:Professional User Generated Model
其他
BIG-bench,谷歌的一个研究项目,包括有207个测试任务,涵盖语言学、数学、常识推理、生物学、物理学、软件开发等领域。
卢德运动:英格兰中部莱斯特市,织布学徒工内德·卢德(Ned Ludham)在被雇主责骂后失控,拿起锤子砸毁一台纺织机。此后,他被追随者们称作“卢德王”或“卢德将军”,卢德运动由此得名。
恩格斯式停顿:Engels’ pause,技术进步初期,收益分配不均;虽然全社会的生产率在不断上升,但许多人的生活水平仍然停滞不前,甚至不断恶化。
自动驾驶里的分级标准,涉及生命安全,对驾驶动作的容错性极低,分级也非常细致:
- L1级,辅助驾驶,指车辆可以在一个维度(横向或纵向)完成部分驾驶任务,例如自适应巡航、车道保持等,但需要人类司机时刻监控和干预。
- L2级,部分自动驾驶,指车辆可以同时在多个维度(加减速和转向)完成部分驾驶任务,例如特斯拉的自动辅助驾驶(Autopilot)等,但仍然需要人类司机时刻监控和干预。
- L3级,有条件自动驾驶,指车辆可以在特定环境中(如高速公路)实现完全自动化的加减速和转向,无需人类司机干预,但当遇到复杂或异常情况时(如交通拥堵、事故等),需要人类司机接管控制权。
- L4级,高度自动驾驶,指车辆可以在限定条件下(如地理区域、天气状况、速度范围等)实现完全自动化的行驶,在这些条件下无须人类司机接管或监控。
- L5级,完全自动化或无人化,在任何条件、任何场景下都能够实现完全自动化的行驶,在任何情况下都不需要人类司机接管或监控。
智能客服领域,可以简化为3级:
- L1级,辅助客服,大模型可以在服务过程中的部分环节(如查询信息、回答常规问题)提供响应,但仍然需要人工客服时刻监控和干预。类似于自动驾驶中的辅助驾驶或部分自动驾驶。
- L3级,有条件自动客服,大模型在标准的场景中(如普通等级投诉、标准产品销售)实现完全自动化的服务,无须人工客服干预,但当遇到复杂或异常情况时(如高等级投诉、申请特殊折扣),需要人工客服接管服务。类似于自动驾驶中的有条件自动驾驶或高度自动驾驶。
- L5级,无人化客服,在任何条件、任何场景下都能够实现完全自动化的客服,在任何情况下都不需要人工客服接管或监控。类似于自动驾驶中的无人化自动驾驶。
数字游民通常是指那些通过互联网和移动设备追寻自由、独立和灵活的新型职业人群,他们可以在任何地点和时间进行自己的工作。
个人IP则是指个人在社交媒体等平台上,通过内容输出和品牌塑造来建立自己的个人品牌。
Hugging Face:在线模型库和社区平台。用户分为两大类,即模型托管者和模型使用者。托管者通常是模型的研究开发方,可以在平台上托管并共享预训练模型和数据集;模型使用者可以通过平台选择合适的模型,在社区中进行协作和模型评价,然后将选定的模型投入生产应用,而训练和推理均可在平台上完成。
Hugging Face是人工智能领域的GitHub。国内类似的有阿里的ModelScope魔搭社区。
DeepMind:2010年创业公司,2014年被Google收购。发布的AlphaGo Zero,不采用任何人类棋谱作为训练数据,仅通过自我对弈完成强化学习,且比之前的所有版本都要强大。DeepMind和Google自家的Brain合并为Google DeepMind。
Watson Health:IBM投资医疗领域的产物。
Alphabet:谷歌母公司,Waymo也隶属于Alphabet下,研发自动驾驶汽车。
MaaS:Model as a Service,模型即服务。
聚焦生成式预训练大模型领域,主要需要关注大模型在以下几个方面的表现:
- 生成文本的质量:模型生成的文本是否流畅、连贯,是否与输入强相关、符合人类的预期,是否存在偏见或错误信息,可以通过人工评估来衡量。
- 零次迁移的学习能力:模型在没有接受特定任务训练的情况下处理相关问题的能力。这反映了模型的泛化能力和灵活性。
- 生成样本的多样性:模型生成的文本是否具有多样性,能否在相同输入的情况下给出多种合理的回应。这可以通过检查生成样本的不同程度来评估。
- 输入的容错性和鲁棒性:一个好的模型应当能够处理输入中的错误(如拼写错误、语法错误等),并且在面对攻击或敌对样本时保持稳定表现。
- 计算资源需求:模型在训练和推理阶段对计算资源(如GPU、内存等)的需求。较小的计算资源需求意味着更高的可扩展性和商业可行性。
- 可解释性和可审计性:这些特性有助于理解模型的工作原理,以及如何改进模型以减少偏见和错误。
技术
GPT
Transformer核心是基于注意力机制的技术,可以建立起输入和输出数据的不同组成部分之间的依赖关系,具有质量更优、更强的并行性和训练时间显著减少的优势。
Transformer的基本特征:
- 由编码组件(encoder)和解码组件(decoder)两个部分组成;
- 采用神经网络处理序列数据,神经网络被用来将一种类型的数据转换为另一种类型的数据,在训练期间,神经网络的隐藏层(位于输入和输出之间的层)以最能代表输入数据类型特征的方式调整其参数,并将其映射到输出;
- 拥有的训练数据和参数越多,它就越有能力在较长文本序列中保持连贯性和一致性;
- 标记和嵌入——输入文本必须经过处理并转换为统一格式,然后才能输入到Transformer;
- 实现并行处理整个序列,从而可以将顺序深度学习模型的速度和容量扩展到前所未有的速度;
- 引入注意机制,可以在正向和反向的非常长的文本序列中跟踪单词之间的关系,包括自注意力机制(self-attention)和多头注意力机制(multi-head attention),其中的多头注意力机制中有多个自注意力机制,可以捕获单词之间多种维度上的相关系数注意力评分(attention score),摒弃递归和卷积;
- 训练和反馈——在训练期间,Transformer提供非常大的配对示例语料库(例如,英语句子及其相应的法语翻译),编码器模块接收并处理完整的输入字符串,尝试建立编码的注意向量和预期结果之间的映射。
在Transformer之前,有RNN,Recurrent Neural Network,循环神经网络,或CNN,Convolutional Neural Networks,卷积神经网络。
大模型的训练包括三个阶段:
- 自监督预训练(Self-supervised pre-training)
- 监督微调(Supervised Fine Tuning)
- 人类反馈强化学习(RLHF)
RLHF:Reinforcement Learning from Human Feedback,
监督学习:一种经典的机器学习方法,其目标是使用有标签数据集来训练一个模型,以使其能够对新的未标记数据进行预测。训练数据的标签是已知的,模型的目标是最小化预测输出与真实标签之间的差异,以学习如何进行准确的预测。
微调(Fine-Tuning)的起源可以追溯到早期计算机视觉领域,当时在大型图像数据集上训练的CNN被证明能够捕捉图像中的高级特征,这些特征在许多视觉任务中都是有用的。
SFT,Supervised Fine-Tuning,监督微调是一种特定的迁移学习方法,不同于传统从零开始训练的监督学习。基于一个通用的预训练模型,使用少量有标签的数据集对模型进行微调,以适应特定任务的要求。微调方法通常需要更少的标签数据来实现良好的性能,因为预先训练的模型已经学习一些通用的语言表示,可以更好地适应新的任务。微调需要的训练时间和算力也更少,在微调过程中,预训练模型的一部分可能会被固定,以避免过度调整和过拟合,只会改变模型的一小部分层。
自回归(auto-regressive),在生成每个token时,都会考虑前面已经生成的token,可以保证生成文本的连贯性和语义一致性。
束搜索(beam search),计算多个概率较高的token候选集,生成多个候选响应,并选择其中概率最高的响应作为最终的输出。
使用温度(temperature)参数来引入一定程度的随机性,以使生成的响应更加丰富多样。较大的temperature值会有更多机会选择非最高概率token,可产生更多样的响应,但也可能会导致生成的响应过于随机和不合理;较小的temperature值可以产生更保守和合理的响应,但也可能会导致生成的响应缺乏多样性。
大模型标注样本数据的获取主要有以下4种手段:
- 通过专业人员进行数据标注。Scale AI公司是OpenAI公司的专业数据标注服务商,支持标注的数据类型包括文本、图像、音频、视频、3D传感、地图等。标注业务的商业模式有两种:按条数收费和按项目收费。
- 搜集用户使用过程中的反馈
- 获取公域或三方数据
- 接入企业私域数据
RDMA远程直接内存访问(Remote Direct Memory Access),跟传统以太网和TCP/IP协议相比,RDMA将数据直接从一个GPU节点的内存快速转移到另一个节点的内存中,绕开双方操作系统内核和CPU的处理,实现高吞吐、低时延和低资源占用率。
RDMA有两种典型的技术方案:无限宽带技术(IB)、基于融合以太网的RDMA(RoCE)。IB方案的链路层流控技术可以获得更高的带宽利用率,因此能支撑更大规模的训练集群;但IB方案无法兼容现有以太网,需要更换IB网卡和交换机,部署和运维成本不菲。RoCE,将IB的报文封装成以太网包进行收发,相比IB在性能上有一些损失。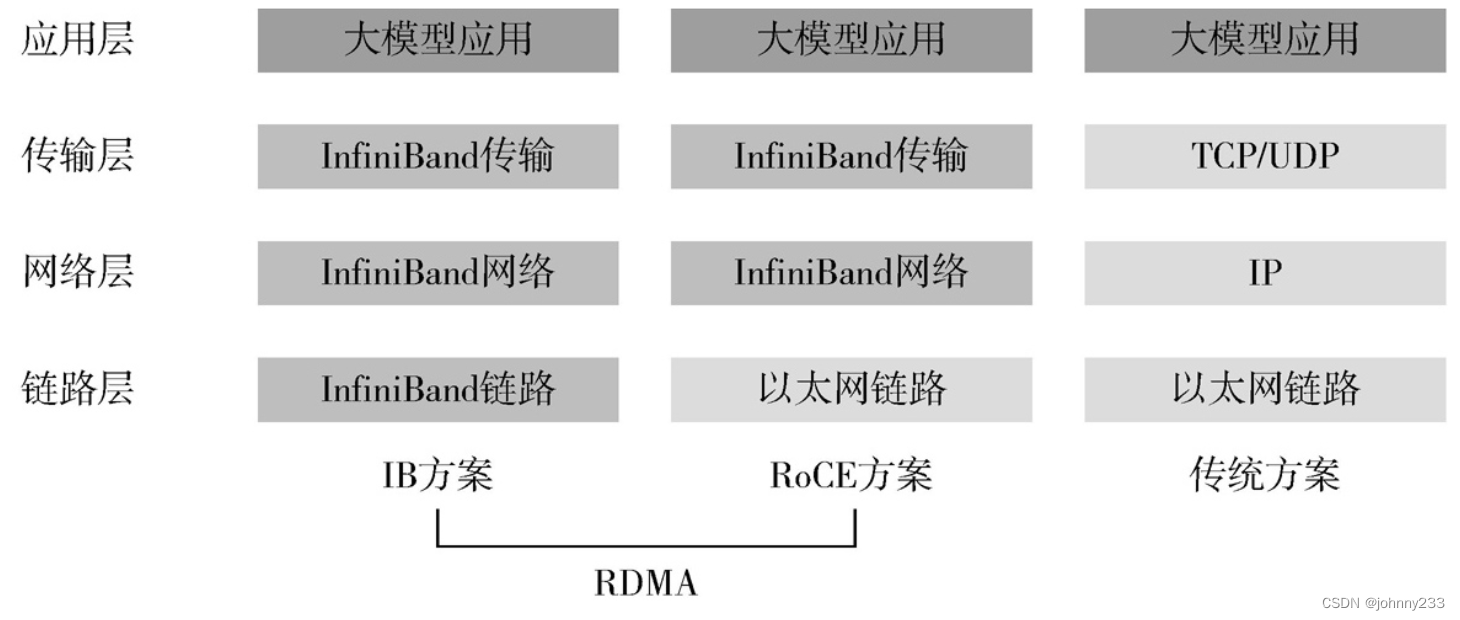
分布式的深度学习框架便成为大模型最重要的软件基础设施,需要重点解决以下问题:
- 大规模计算:大型语言模型通常包含数十亿甚至数百亿的参数,这需要大量的计算资源才能进行训练和推理。分布式深度学习框架可以在多个计算节点和多个GPU或其他加速器上并行执行任务,从而实现大规模计算。
- 数据、模型和流水线并行:数据并行将允许多个计算设备同时处理不同的数据分片,提高训练速度。模型并行将模型分布在不同的计算设备上,使得训练更大的模型成为可能。流水线并行将模型的计算过程划分为多个阶段,在不同的计算设备上并行执行,减少通信开销,提高计算设备的利用率。以上几种并行策略对于加速大型语言模型的训练过程至关重要。
- 高效的资源利用:通过任务调度、负载均衡和资源管理等机制,确保计算资源得到高效利用。这有助于降低大型语言模型训练和推理的时间和成本。
- 容错和恢复:大型语言模型的训练时间较长,在训练过程中出现计算节点和设备故障,无须从头开始,只需要容错和恢复机制,就可以确保训练可以继续进行。
如果大模型的需求超过<GPU每年性能提升一倍>(英伟达黄仁勋提出),只能靠更大的分布式计算集群来实现,有两个瓶颈或突破口:
- 云服务商数据中心的核心网带宽,要从老的以太网升级到新的标准;
- 软件方面,深度学习框架要配合。
分布式深度学习框架能力的实现方式有两种:
- 叠加式:在已有的深度学习框架之上提供分布式能力,如OpenAI在ChatGPT中使用Ray on PyTorch。Ray主要解决分布式计算、任务调度和资源管理等方面,而PyTorch则侧重于模型的构建、训练和优化。英伟达的Nemo Framework、微软的DeepSpeed等,提供模型并行、数据并行和流水线并行等技术。 - 模型设计和开发:使用PyTorch构建神经网络模型,定义损失函数、优化器等训练所需组件。这个阶段主要依赖于PyTorch的功能。- 分布式训练:使用Ray提供的分布式API,将PyTorch模型在多个节点和多个GPU上进行训练。Ray负责任务调度、资源管理和容错,而PyTorch则负责模型参数的更新和优化。- 数据和模型并行:结合Ray的分布式特性,在PyTorch上实现数据并行(多个设备同时处理不同数据分片)和模型并行(将模型分散到不同的计算设备上)。- 部署和推理:使用Ray Serve部署PyTorch模型,并提供高性能的在线推理服务。Ray Serve负责模型的扩展和负载均衡,确保推理过程的高效和稳定。
- 全栈式:专为大模型解决横向扩展问题的、原生支持分布式并行训练的深度学习框架,如国人开源框架OneFlow。 - OneFlow以软硬协同设计为指导思想,从芯片设计领域借鉴了大量思路,在纯软件层面解决大模型训练的横向扩展难题。- 将自动编排并行模式、静态调度、流式执行等技术相融合,构建一套原生支持数据并行、模型并行及流水并行等多种模式的分布式深度学习框架,无需定制化开发,兼容多种底层GPU硬件,降低大模型分布式训练门槛。- 降低计算集群内部的通信和调度消耗,提高硬件使用率,缩减训练成本和时间。
BERT
变体:BioBERT、RoBERTa和ALBERT
GPT vs BERT
不同:
- GPT是单向编码,BERT是双向编码。GPT基于Transformer解码器构建,BERT基于Transformer编码器构建。这意味着GPT只能利用左侧的上文信息,而BERT可以同时利用左右两侧的上下文信息,可以捕捉更长距离的依赖关系,并且更适合处理一词多义的情况。
- GPT使用传统的语言模型作为预训练任务,即根据前面的词预测下一个词。而BERT使用两个预训练任务:掩码语言模型(MLM),即在输入中随机遮盖一些词,然后根据上下文来还原这些词;下一句预测(NSP),即给定两个句子,判断它们是否有连贯的关系。这两个任务可以提高BERT对语言结构和语义的理解能力。
- GPT可以应用于自然语言理解(NLU)和自然语言生成(NLG)两大任务,原生的BERT只能完成NLU任务,无法直接应用在文本生成上面。因为GPT采用左到右的解码器,可以在未完整输入时预测接下来的词汇。而BERT没有解码器,只能对输入进行编码和预测掩码位置的词汇。
其他
传统的分析型AI是通过训练数据来学习预测新数据的标签或值;生成式AI则是通过学习数据的概率分布来生成新的数据。生成式AI的技术:GPT,生成式对抗网络(GAN)。
GAN,基本思想是同时训练两个神经网络:一个生成器网络和一个判别器网络。生成器网络用于生成假数据,判别器网络用于区分真实数据和生成的假数据。两个网络不断交替训练,直到生成器网络生成的假数据无法被判别器网络区分真假为止。已被广泛应用于图像、音频、视频生成等领域,如图像生成应用Midjourney就采用GAN技术。
提示(Prompt)工程有3个主要作用:
- 激发模型的潜在知识和能力。
- 使模型理解输入的问题或任务,提供相关的回答。
- 改进模型的生成输出,提高可读性、连贯性和准确性。
在<算力、数据、算法>的人工智能三要素当中,大模型产业通过硬件基础设施层加上分布式框架,重点解决算力要素的问题。
LLaMA,一种基于开放数据集进行自监督预训练的大模型。主打两个特色:
- 开放,即可以在非商业许可下提供给政府、开发社区和学术界的研究人员,让更多机构和个人能参与大模型的研究和探索,实现大模型的民主化;
- 性价比,可以在大数据集的基础上缩小模型规模,找到模型性能和推理部署成本的最佳平衡。
观点
21世纪以来,摩尔定律面临新的生态:功耗、内存、开关功耗极限,以及算力瓶颈等技术节点。摩尔定律逼近物理极限,无法回避量子力学的限制。在摩尔定律之困下,只有三项选择:延缓摩尔,扩展摩尔,超越摩尔。
凯文·凯利1994年所著的《失控:机器、社会与经济的新生物学》,提出群集系统理论:群集系统存在明显的冗余问题,且效率相对较低,有不可预测、不可知、不可控的缺点;但也有可适应、可进化、无限性和新颖性的优势。如蚁群,粒子群,神经网络等系统,个体随机混乱但是彼此关联协同形成一个有迹可循的整体。个体的进化,推动整体能力的涌现。
达特茅斯学院的人工智能会议引申出人工智能的三个基本派别:
- 符号学派(Symbolism),又称逻辑主义、心理学派或计算机学派。该学派主张通过计算机符号操作来模拟人的认知过程和大脑抽象逻辑思维,实现人工智能。符号学派主要集中在人类推理、规划、知识表示等高级智能领域。
- 联结学派(Connectionism),又称仿生学派或生理学派。联结学派强调对人类大脑的直接模拟,认为神经网络和神经网络间的连接机制和学习算法能够产生智能。学习和训练是需要有内容的,数据就是机器学习、训练的内容。联结学派的技术性突破包括感知器、人工神经网络和深度学习。
- 行为学派(Actionism),该学派的思想来源是进化论和控制论。其原理为控制论以及感知—动作型控制系统。该学派认为行为是个体用于适应环境变化的各种身体反应的组合,其理论目标在于预见和控制行为。
罗伯特·赖克(Robert Reich)于1991年出版的《国家的工作》(The Work of Nations)一书中,把这个时代的工作分成三类:
- 符号分析师:包括经理人、工程师、金融分析师、律师、科学家、记者、咨询师等知识工作者。
- 逐渐被计算机接管的常规工作
- 需要人际交流的面对面服务工作
根据布鲁姆教育目标分类法(Bloom’s taxonomy of educational objectives),人类对知识的处理(Knowledge Processing)有六个层次:记忆、理解、应用、分析、评价和创造。
《创造力手册》,法国数学家庞加莱(Poincaré)指出:创造的一种形式,是对有用的关联元素进行新组合。
《ChatGPT预示着一场智力革命》,大模型将重新定义人类的知识:
- 人类知识的边界有机会更快速地扩展
- 人类知识处理的范式将发生转换
- 人类知识处理还将面对范式转换带来的严峻挑战
搜商:借助于搜索引擎在互联网上快速精确搜索想要的信息及获取知识的能力。
搜索语言:利用双引号、加号、减号、文件类型、站点范围等各种限定符,对搜索结果进行更精准的筛选。
阿尔伯特·爱因斯坦说:提出一个问题往往比解决一个问题更重要。
提问题的问题,即所谓问商。在大模型时代,问商更凸显其价值。
根据人类与大模型之间协作的过程,把问商分为两部分:
- 初始阶段,3R任务授权法,Ask AI for help。
- 跟进阶段,苏格拉底提问法,Question AI for better result。
3R:
- Role,即角色设定和目的
- Result,即期望的结果
- Recipe,即思考如何才能拿到预期的结果,并给出方法和指导
史蒂芬·R.柯维(Stephen R.Covey)在《高效能人士的七个习惯》一书中,提出任务授权的两种类型——指令型授权和责任型授权,重点描述和推荐责任型授权的方法。这种授权类型要求双方就以下五个方面达成清晰、坦诚的共识,并做出承诺:
- 预期成果。要以“结果”,而不是以“方法”为中心
- 指导方针。确认适用的评估标准,避免成为指令型授权,但是一定要有明确的限制性规定
- 可用资源
- 责任归属
- 明确奖惩
理查德·保罗(Richard Paul)在《像苏格拉底一样提问》(The art of Socratic questioning)一书中给苏格拉底提问法下的定义:提出问题并引导出答案的方法,有如下的一个或多个目的:
- 检验理论或观点是否正确。
- 循循善诱,让潜藏于脑海中尚未成形的想法成形。
- 引导回答者得出符合逻辑或合理的结论,无论发问者是否已预知该结论。
- 引导对方承认其观点或结论需要进一步验证是真是假。
苏格拉底式的问题,可以分为4大类:证据类、视角类、理由类、影响类: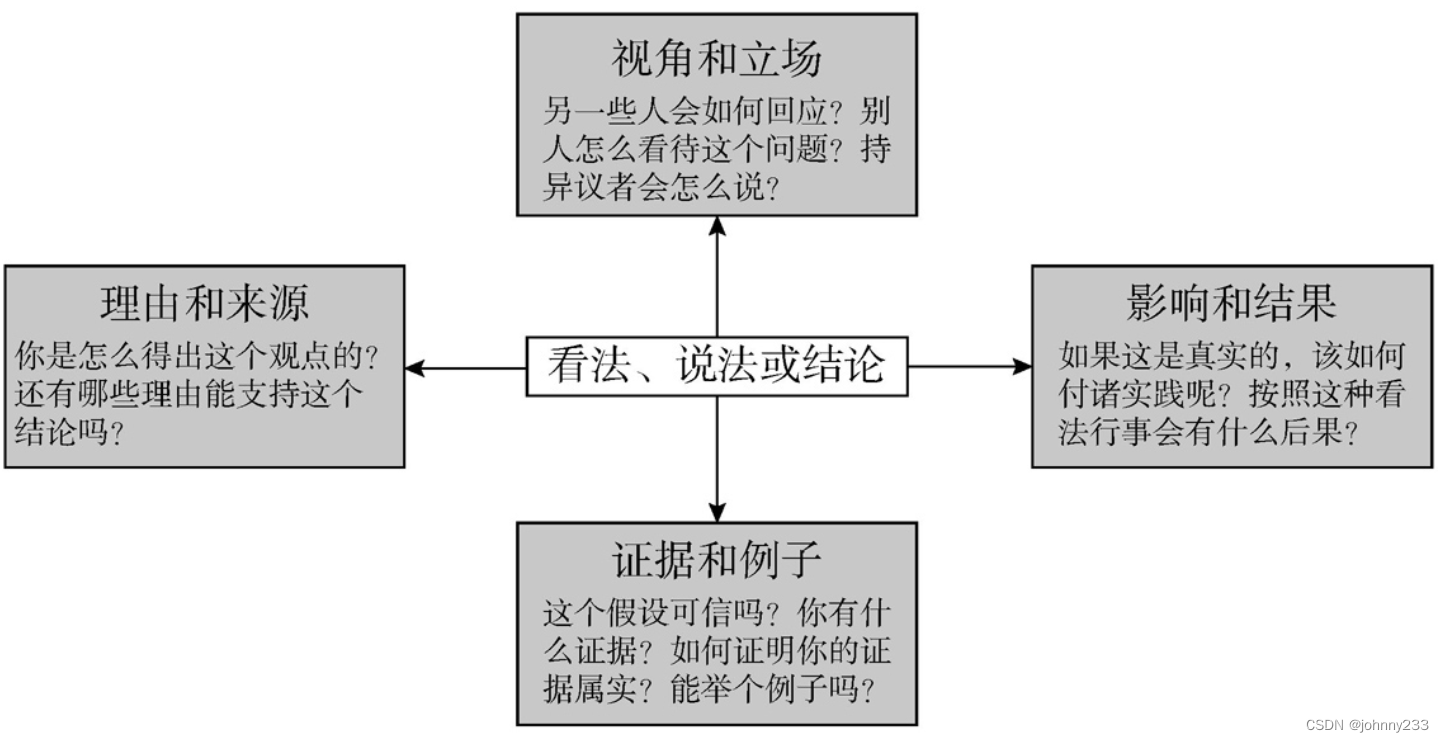
GPT大模型满足通用技术的三个核心标准:随着时间推移,技术不断改进,贯穿整个经济体系,能够催生互补性的创新。
创新者窘境,即成功的公司往往会被自己现有的市场和客户束缚,而忽视新兴的技术和市场的需求,从而导致被更具创新力和灵活性的新进入者所颠覆。如谷歌在大模型方面落后于OpenAI。
版权归原作者 johnny233 所有, 如有侵权,请联系我们删除。