
一、前言
在之前的文章中,我们了解到clickhouse作为一款列式存储数据库 ,查询性能非常高效,一方面与其自身的存储引擎设计有关,另一方面,在执行查询语句时,底层做了大量的语法规则的优化,本文将详细介绍clickhouse的常用优化策略。
二、环境准备
从官方下载两个测试数据文件,这两个文件中表的数据量接近千万,用于做实验的数据;

三、准备数据操作步骤
1、上传测试数据包到服务器目录
2、解压文件到clickhouse的数据目录
clickhouse的默认数据目录在 : /var/lib 下
sudo tar -xvf hits_v1.tar -C /var/lib/clickhouse
sudo tar -xvf visits_v1.tar -C /var/lib/clickhouse
解压完成后,可以在data目录下看到本次上传的数据文件

3、修改数据文件以及用户授权
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/data/datasets
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/metadata/datasets
4、重启clickhouse服务
sudo clickhouse start
5、登录clickhouse确认数据是否导入成功
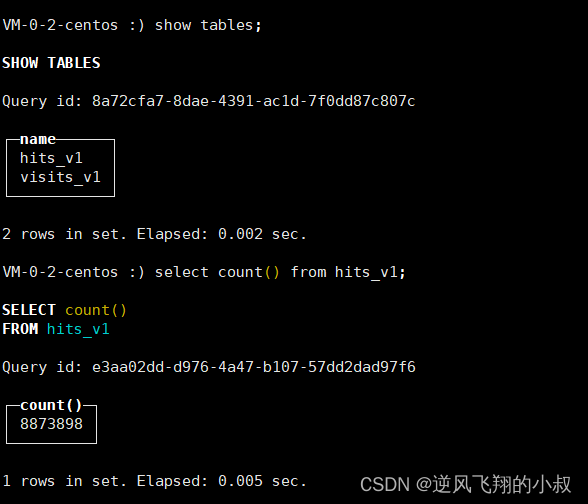
到这里,环境准备就完成了
四、语法规则优化之 —— count
count() 函数在mysql中大家经常使用的,在clickhouse中也提供了该函数,但是在使用时底层在执行上表现略有差异;
从下面的执行来看,count中带有具体的字段时,引擎会对表的数据进行扫描,而直接count的时候,则发现未作扫描;

接下来通过explain来看下引擎对两种sql语句的执行计划
count字段时执行计划分析
explain plan select count(UserID) from visits_v1;

count为空时执行计划分析

在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则
会直接使用 system.tables 的 total_rows
- 注意 Optimized trivial count ,这是对 count 的优化,在上图中explain的计划中展示了出来,即通过读取预加载的count文件(有点类似于缓存);
- 如果 count 具体的列字段,则不会使用此项优化,这时就要对表进行数据扫描了;
补充:
count(1)和count(*)效果等同于count(),引擎认为count的字段是无意义的字段,默认会转换为count()处理,所以效果一样;

五、语法规则优化之 —— 子查询重复字段查询
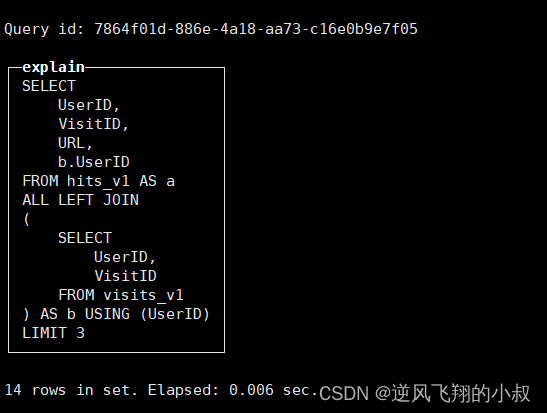
在使用clickhouse进行关联查询时,如果子查询语句中有重复的字段,引擎会自动进行重复字段的消除,如下查询语句:
SELECT
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM
hits_v1 AS a
LEFT JOIN (
SELECT
UserID,
UserID as copy,
VisitID
FROM visits_v1) AS b
USING (UserID)
limit 3;
可以看到,在子查询语句中,查询了两遍UserID,使用explain执行下发现引擎自动帮我们做了字段去重;
六、语法规则优化之 —— 谓词下推优化
当 group by 有 having 子句,但是没有 with cube、with rollup 或者 with totals 修饰的时
候,having 过滤会下推到 where 提前过滤,看下面的这个sql;
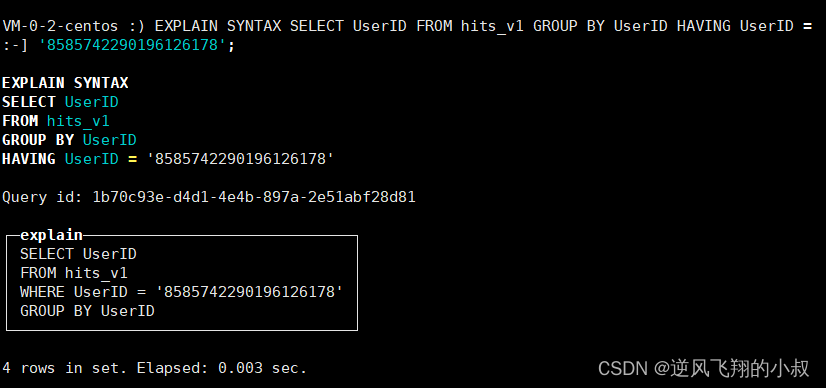
EXPLAIN SYNTAX SELECT UserID FROM hits_v1 GROUP BY UserID HAVING UserID =
'8585742290196126178';
通过explain执行计划发现引擎在执行的时候自动将having去掉了,即将userID的条件下推至where条件里面;
子查询谓词下推
看下面的这条sql
EXPLAIN SYNTAX
SELECT *
FROM
(
SELECT UserID
FROM visits_v1
)
WHERE UserID = '8585742290196126178'
//返回优化后的语句
SELECT UserID
FROM
(
SELECT UserID
FROM visits_v1
WHERE UserID = \'8585742290196126178\'
)
WHERE UserID = \'8585742290196126178\'

七、语法规则优化之 —— **聚合计算外推 **
聚合函数内的计算,会外推,请看下面的sql ,该语句即统计UserID字段的sum乘以2:
SELECT sum(UserID * 2) FROM visits_v1
实际上,使用explain之后优化后的sql如下,即把乘以2的操作挪到外面去了;

聚合函数消除
同样的道理,如果对聚合键,也就是 group by key 使用 min、max、any 聚合函数,则将函数消除,看下面的sql;
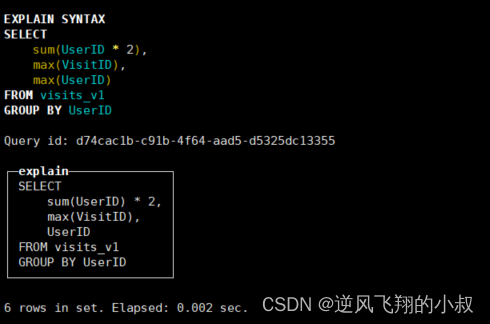
SELECT
sum(UserID * 2),
max(VisitID),
max(UserID)
FROM visits_v1
GROUP BY UserID
使用explain之后优化后的sql如下,这也很好理解,既然最后你都按照UserID进行分组了,再查询max(UserID)意义就不大了;
八、语法规则优化之 —— 删除重复的聚合字段
**删除重复的 **order by key
如下面的sql,重复的聚合键 id 字段会被去重
SELECT *
FROM visits_v1
ORDER BY
UserID ASC,
UserID ASC,
VisitID ASC,
VisitID ASC;
优化后的sql如下,可以看到重复的order by 字段自动被删除了

**删除重复的 ****limit by key **
如下面的语句,重复声明的 name 字段会被去重
SELECT *
FROM visits_v1
LIMIT 3 BY
VisitID,
VisitID
LIMIT 10

**删除重复的 **USING Key
例如下面的语句,重复的关联键 id 字段会被去重
SELECT
a.UserID,
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM hits_v1 AS a
LEFT JOIN visits_v1 AS b USING (UserID, UserID);
回优化后的语句:

九、语法规则优化之 —— 标量替换
如果子查询只返回一行数据,在被引用的时候则会用标量替换,如下面sql语句中的
total_disk_usage 字段:
WITH
(
SELECT sum(bytes)
FROM system.parts
WHERE active
) AS total_disk_usage
SELECT
(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10;
优化后sql如下:

**三元运算优化 **
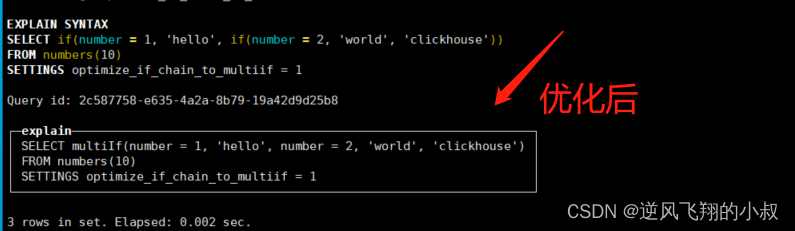
如果开启了 optimize_if_chain_to_multiif 参数,三元运算符会被替换成 multiIf 函数,如下面的sql语句,
未完待续,感谢观看!
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。