
一、炸裂函数
针对一行数据,输出多行数据,主要用于map,array这种的
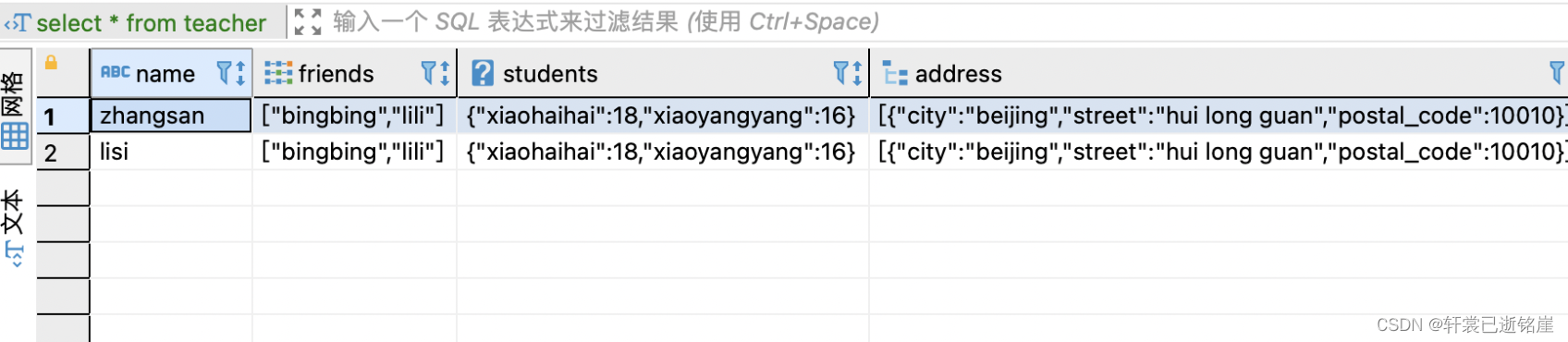
根据一个例子来看:
- friends 是一个array数组
- students 是一个map
- address是一个struct
1)explode函数
explode函数以array类型数据输入,然后对数组中的数据进行迭代,返回多行结果,一行一个数组元素值。
作用于array:
- arrayCol :array字段的名称
- colName1 :array字段的别名,随便起
-- 语法是这样select explode(arrayCol)as colName1 from tablename
举例:
select explode(friends)from teacher

作用于map:
- mapcol :map字段名称
- key1:key的别名 随便起
- value1:value的别名 随便起
select explode(mapcol)as(key1,value1)from tablename;
举例:
select explode(students)from teacher

2)posexplode函数
相对于 返回多行结果,一行一个数组元素值。会返回元素在集合中的位置
区别:
- posexplode只能用于array,而explode可以用于array,map
- posexplode还会返回元素在集合中的位置
select posexplode(friends)from teacher

3)Lateral View
通常与UDTF配合使用,Lateral View可以将UDTF应用到源表的每行数据,将每行数据转换为一行或者多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
那么,解决的问题到底是什么?
也不用Lateral View ,返回的字段也只能是炸裂的字段,不能进行其他任何操作
sql语法:
- ⚠️lateral view 一定要在udtf函数的前面
- ⚠️虚拟表别名一定要加,不然会报错
select[col1,col2,col3……]from 表名
lateral view udtf(expression) 虚拟表别名
举例:
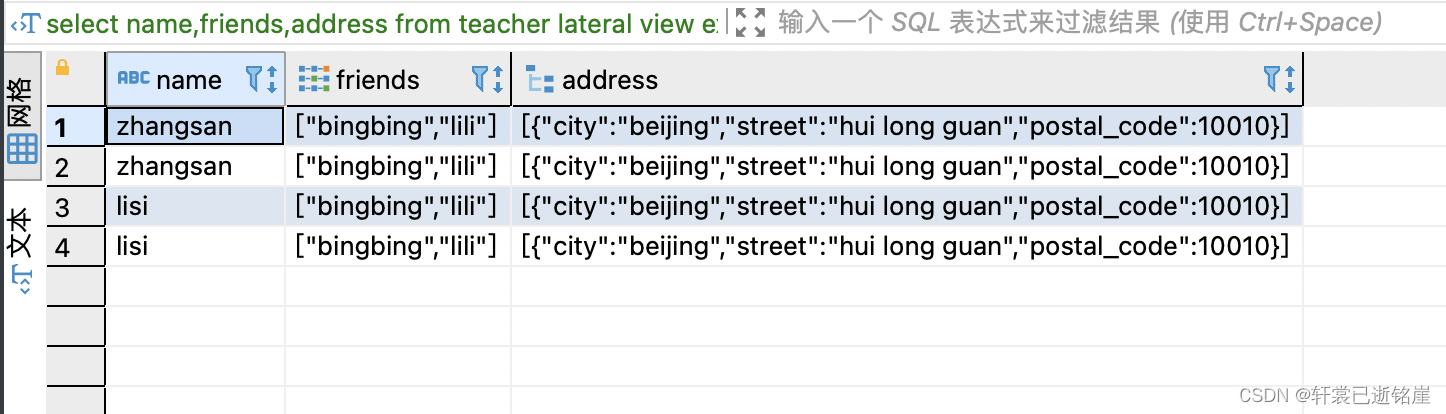
select name,friends,address from teacher lateral view explode(friends) p1
4)udtf+lateral view的举例:
createtable movie_info(
movie string,--电影名称
category string --电影分类)row format delimited fieldsterminatedby"\t";insert overwrite table movie_info
values("《疑犯追踪》","悬疑,动作,科幻,剧情"),("《Lie to me》","悬疑,警匪,动作,心理,剧情"),("《战狼2》","战争,动作,灾难");
先看原来的数据:
需求是: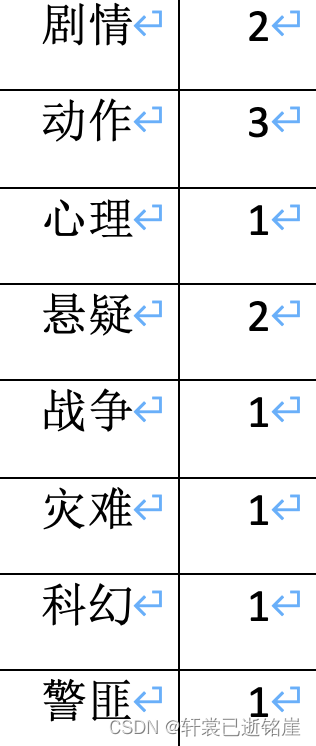
select cate,count(*)from(select movie, cate from(select movie,split(category,',') cates from movie_info)
t1 lateral view explode(cates) tmp as cate
)t2
groupby cate;
二、窗口函数
每行数据都能作为一个窗口,每个窗口都会进行范围的计算操作,并将计算结果返回当前行的一个新的字段。
可以是聚合(sum max min)等等操作,也可以是其他函数操作。
⭐️常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
举例:定义窗口函数基于行,使用聚合函数(sum)的,窗口的规则是字段A 负无穷到当前行。计算过程是怎么样的?首先对字段A从小到大进行排序。
1.按照排序后的一行一行作为窗口,从第一行开始,第一行的字段A最小,发现自己是最小的,那就当前行做为第一个窗口,计算结果只有本身,结果返回给第一行。
2.从第二行开始继续寻找,负无穷到当前行的,第二个窗口包含第一行、第二行数据,做范围内运算,sum=第一行的字段A+第二行的字段A,结果返回给第二行。
第三个窗口,包含第一行、第二行、第三行数据,那么计算sum=第一行字段A+第二行字段A+第三行字段A。
以此类推。。。。
最后一行的返回的计算结果一定是所有行字段A的总和
那这跟直接sql写sum()+group by 有什么区别吗?
⭐️区别在于,每行数据都会参与到计算中来,同时得到窗口计算的结果,我们直接写sql语句调用sum()只会返回最终结果,相当于只有最后一个窗口的值。

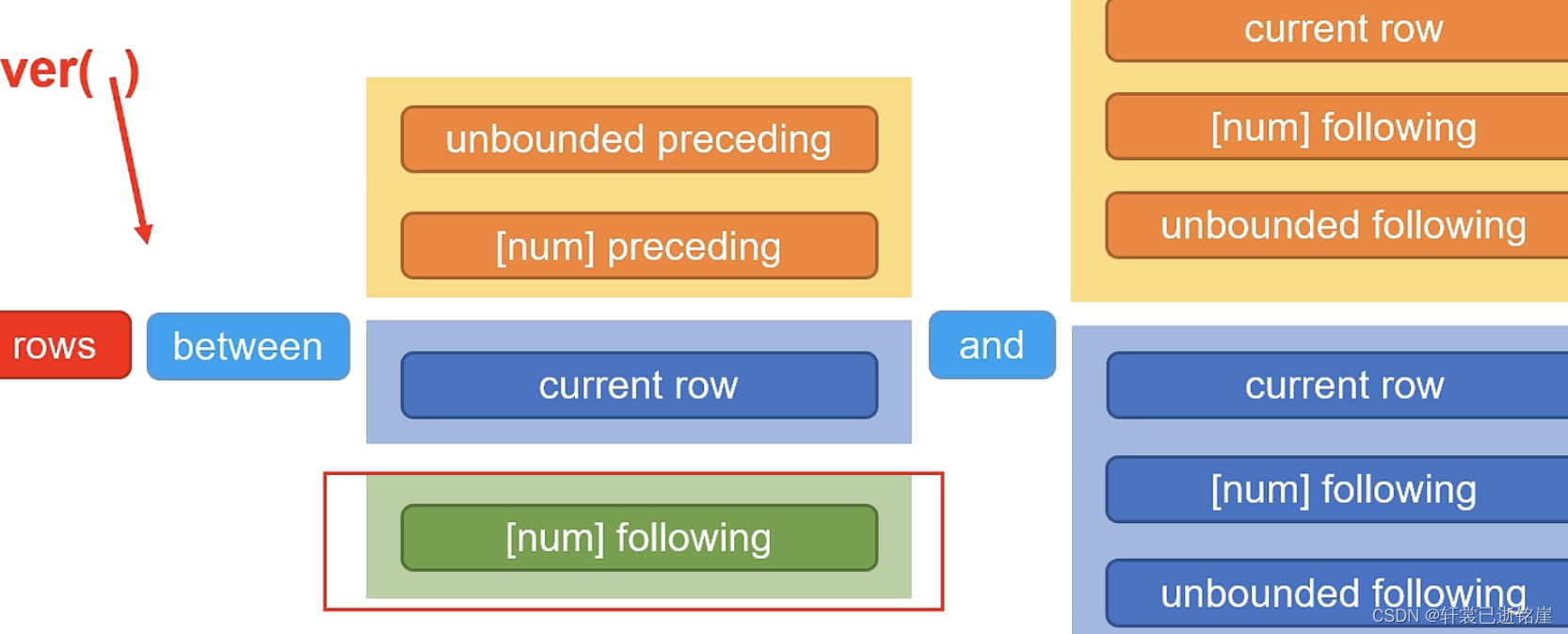
⭐️1)窗口规则 between and:
between相当重要的原因是按照什么样的规则定义窗口。
- unbounded preceding 表示负无穷
- current row 基于行的方式表示当前行,基于值的方式表示当前值
- unbounded following 表示正无穷
- [num] preceding 基于行的方式 表示当前行的前几行,基于值的方式 表示当前值减去num
- [num] following 基于值的方式 表示当前行的后几行,基于值的方式表示当前值加上num
⚠️ and 前后要注意sql的写法
- 如果前面写,current row,后面不允许写[num] preceding
- 如果使用基于值的方式,使用 preceding[num]或者[num] following,一定要保证划分窗口的字段属于数字类型
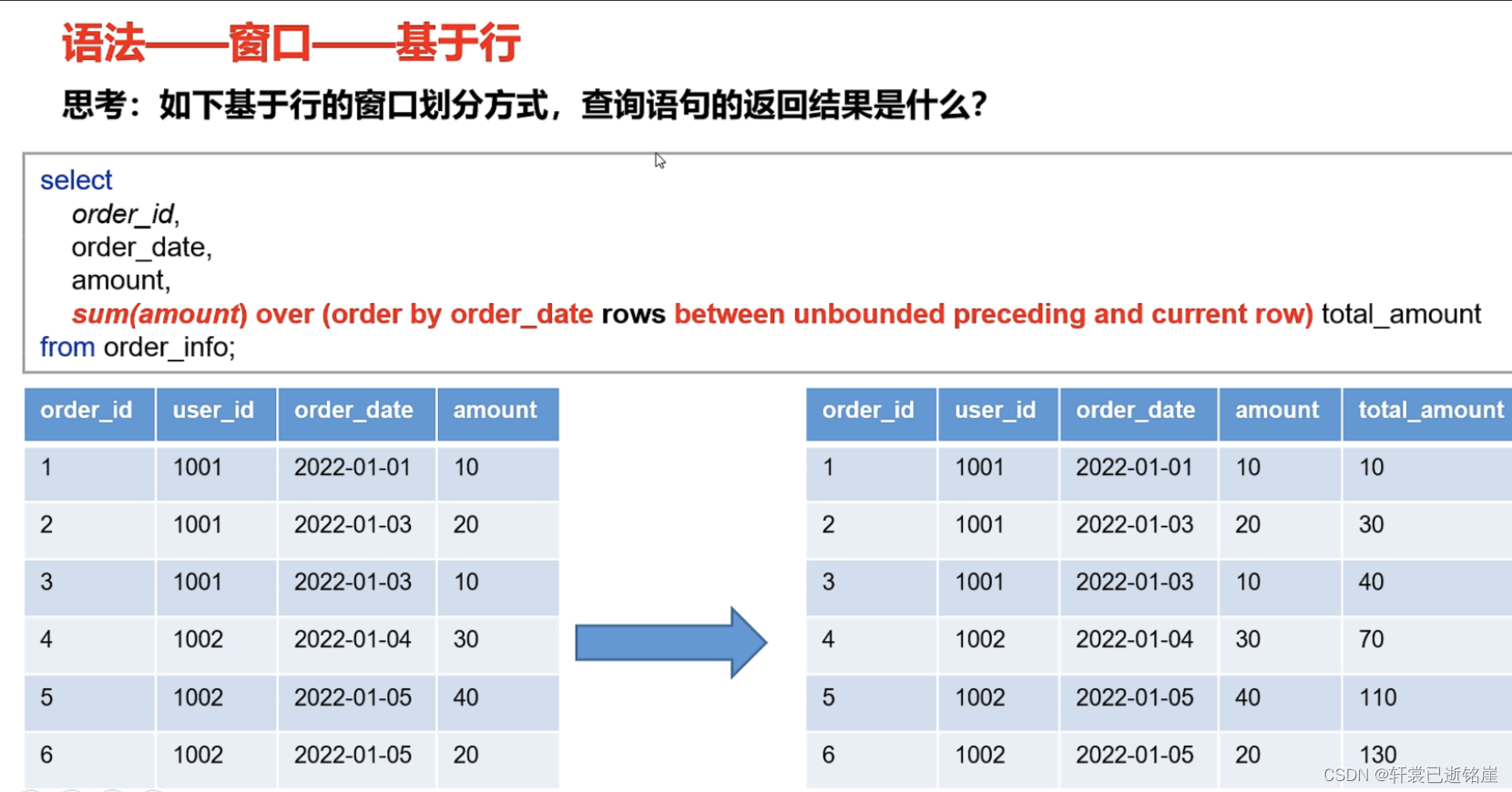
2)基于行
举例:
- between unbounded preceding and cureent now 表示负无穷到当前行 做为一个窗口
- order_id为1的发现order_date 小于自己的没有,只有自己,所以第一个窗口只包含当前行
- ordr_id为2的先查找,order_date小于等于当前行的,发现order_id为1的算一个,所以第二个窗口包含两行,是order_id为1的以及order_id为2的。 做窗口内的范围内运算(由于是sum,则相加)=20+10
- ordr_id为3=10+20+10
- 以此类推。。。
3)基于值
跟基于行最大的区别是什么?
between规则应用的不一样
同样都是between unbounded preceding and cureent now
基于行的含义是负无穷到当前行,而基于值的含义是负无穷到当前值
也就说基于行 会以自己的行 为终点,但是基于值 会 查找某个字段 小于等于自己的,自己的行不一定是终点。
如下图所示:
order_id为1的查找order_date小于等于自己的,只有本身,total_amount为自己
order_id为2的查找order_date小于等于自己的,有order_id为1,order_id为2,order_id为3,total_amount为10+20+10
order_id为3的查找order_date小于等于自己的,有order_id为1,order_id为2,order_id为3,total_amount为10+20+10

4)分区:
如果不开分区,那么窗口的计数从整个数据的开始到结尾
如果开了分区,那么一个分区内窗口计数从分区头到分区尾
说白了,第二个分区的实际数据即使在表的中间,也有可能属于第一个窗口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QPCIFxTX-1671867534186)(image-20221223183034924.png)]](https://img-blog.csdnimg.cn/fda7145e93ae4838bcdc167a13bf8969.png)
5)基本语法:
基于行的语法:
- 字段1,字段2 不用说了,就是显示的字段
- ⭐️ sum(字段3) 是基于窗口做什么操作,这个表示是基于每个窗口对 sum3字段做求和操作
- ⭐️ over()表示是什么样的窗口字段2:针对字段2进行划分窗口rows:表示基于行between unbounded preceding and current row:表示负无穷到最后一行
select 字段1,字段2,...,sum(字段3)over(字段2rowsbetweenunboundedprecedingandcurrentrow)as 新字段1
基于值的语法:
- range:表示基于值
- unbounded preceding and unbounded following: 表示负无穷到正无穷
select 字段1,字段2,...,sum(字段3)over(字段2 range betweenunboundedprecedingandunboundedfollowing)as 新字段1
加分区:
跟基于行 基于值没有关系
- partition by 字段1 表示针对字段1做分区
select 字段1,字段2,...,sum(字段3)over(partitionby 字段1 字段2 range betweenunboundedprecedingandcurrentrow)as 新字段1
6)缺省下情况:
- 就什么都不加,over(字段)相当于 基于行做窗口,范围是负无穷到正无穷,相当于所有字段作为一个窗口
- over(order by 字段) 排序后基于值做窗口,范围是负无穷到当前行
- ⭐️无论基于行还是基于值, 不加order by,没有任何意义(因为你都不知道上一行和下一行的值有没有关联),做范围内计算也是白瞎

7)聚合函数
支持以下几种,不再多阐述
max
min
sum
avg
count
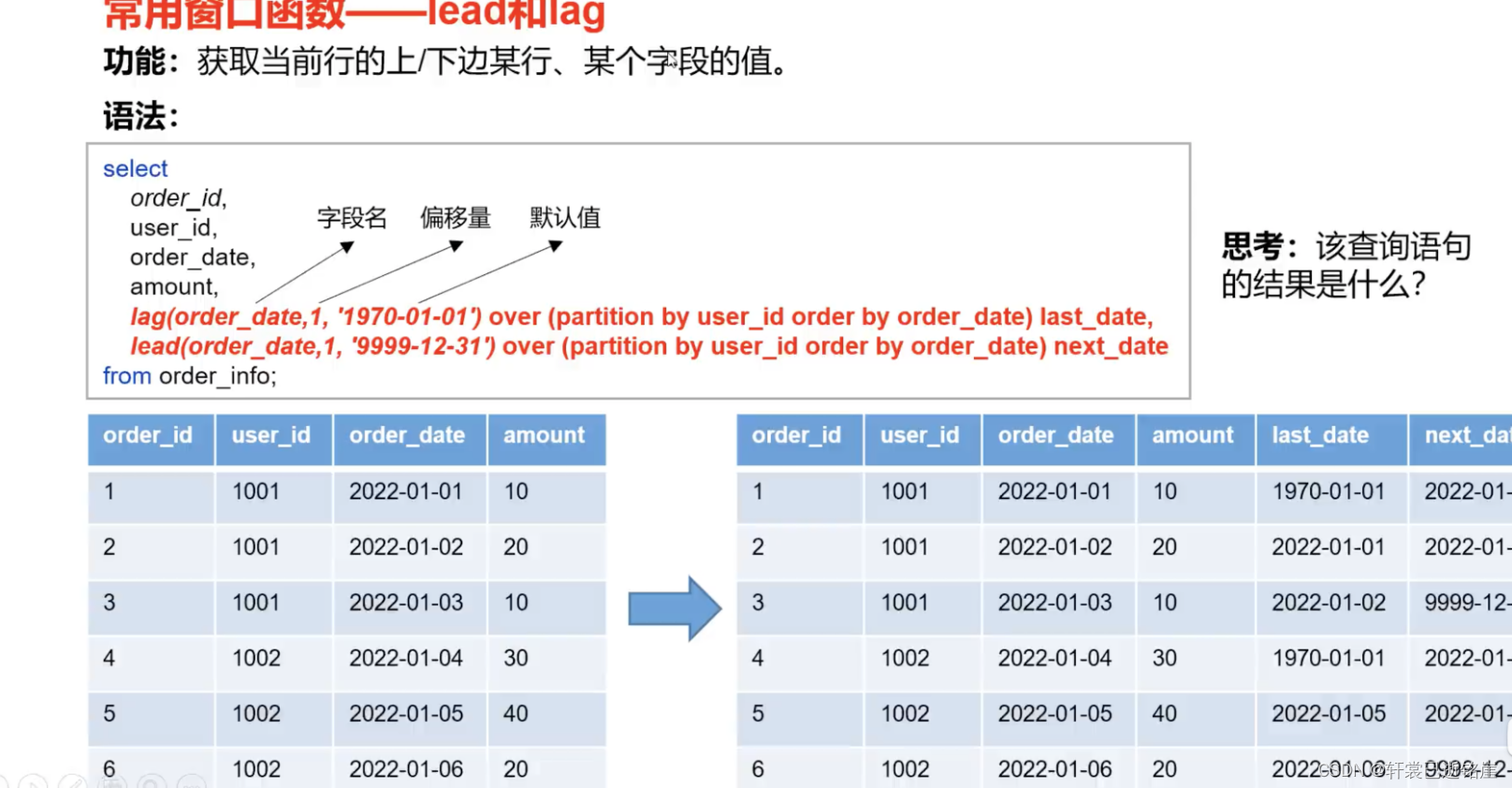
8)跨行取值函数
分别包括:
lag和lead(不支持自定义窗口):
- lag(): 按照 所在行的偏移量 取 前面的第几行
- lead(): 按照 所在行的偏移量 取 后面的第几行
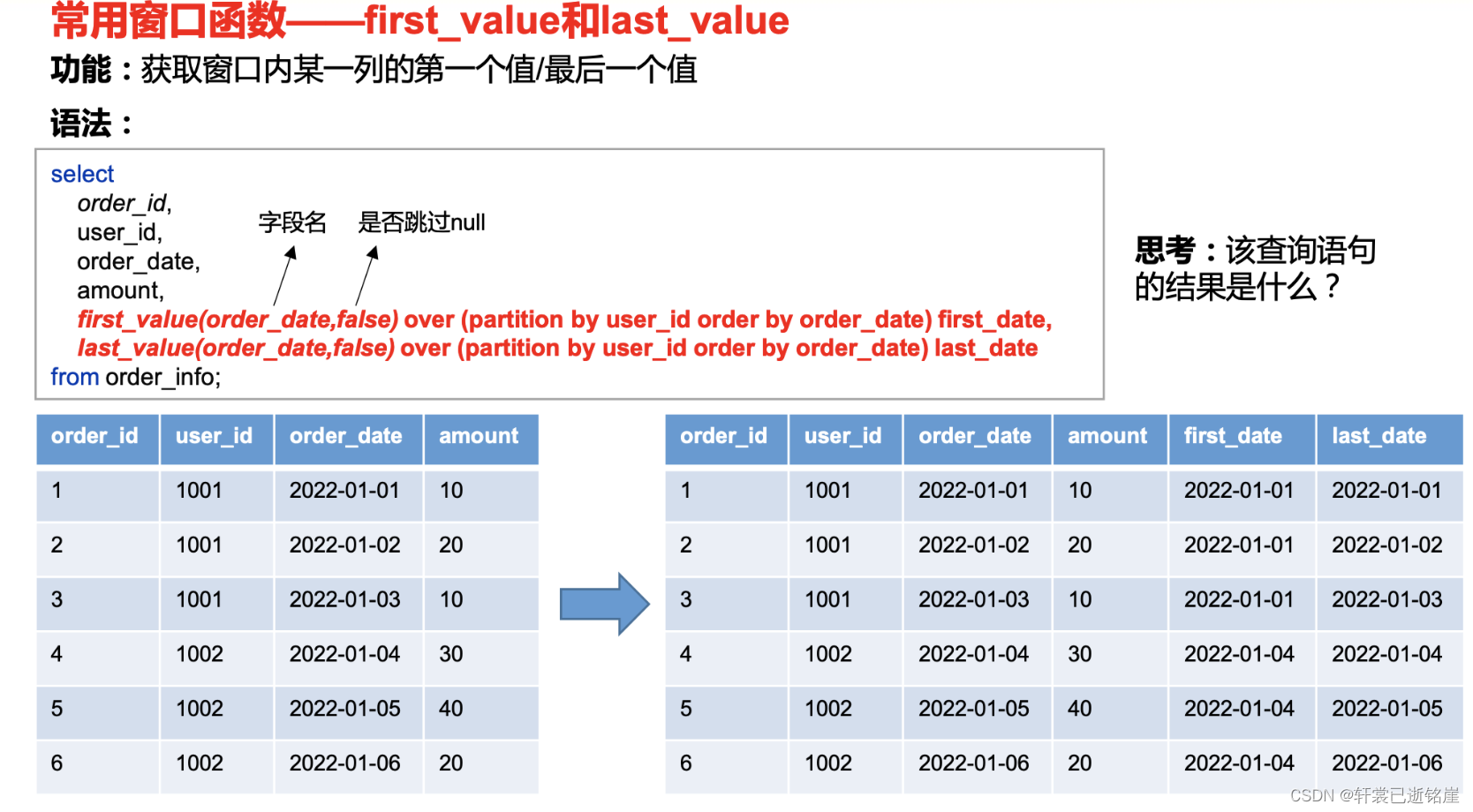
first_value和last_value(支持自定义窗口):
- first_value():当前窗口内所有行数据中的最小值
- last_value(): 当前窗口内所有行数据中的最大值
⚠️要注意,lag和lead不能使用自定义窗口,因为已经规定好了具体某一行与当前行作为一个窗口,不能再定义是负无穷到正无穷这样自定义的规则。
lag和lead:
语法:
- lag() :- 字段3:结果字段- 1: 取当前行前面的前1行- ‘1970-01-01’:当前所在行数取不够前面的行,取默认行(比如取前5行,但是当前行数是第四行,就取值为(‘1970-01-01’)的所在行
- lead :同上
语法如下:
select 字段1,字段2,字段3
lag(字段3,向前的具体行数,'默认值')over(.....) 别名1,
lead(字段3,向后的具体行数,'默认值')over(.....) 别名2,fromtable
举例:
- 现在要获取当前订单的上一个订单的时间跟下一个订单的时间(统计一下时间间隔)
- 可以看到,lag根据order_date做一个跨行,先按照时间排序(over order by )后取前面的一行,跟后面的一行,分别做为last_date 和 next_date 字段
first_value和last_value:
语法:
- first_value(字段3,FALSE) 字段3表示具体取哪个字段的值,false表示允许null的值作为结果,如果窗口内某一行是null值,结果就是null
select 字段1,字段2,字段3
first_value(字段3,FALSE)over(orderby 字段3) last_date,
last_value(字段3,FALSE)over(orderby 字段3) next_date
from table_name
举例:
- 获取每个用户订单的最早的下单时间(first_date) 那么就可以先以用户id分区,如下的user_id的就包含三个窗口,每个窗口最小值就是2022-01-01,所以得出user_id所有的订单中最早的日期是2022-01-01
9)排名函数
rank() 对某个值做个排名
dense_rank() 如果相同的值,给一样的名次
row_number() 如果相同的值,按照插入表的顺序分名次

三、综合案例
1.数据准备
1)表结构
order_iduser_iduser_nameorder_dateorder_amount11001小元2022-01-011021002小海2022-01-021531001小元2022-02-032341002小海2022-01-042951001小元2022-01-0546
2)建表语句
createtable order_info
(
order_id string,--订单id
user_id string,-- 用户id
user_name string,-- 用户姓名
order_date string,-- 下单日期
order_amount int-- 订单金额);insert overwrite table order_info
values('1','1001','小元','2022-01-01','10'),('2','1002','小海','2022-01-02','15'),('3','1001','小元','2022-02-03','23'),('4','1002','小海','2022-01-04','29'),('5','1001','小元','2022-01-05','46'),('6','1001','小元','2022-04-06','42'),('7','1002','小海','2022-01-07','50'),('8','1001','小元','2022-01-08','50'),('9','1003','小辉','2022-04-08','62'),('10','1003','小辉','2022-04-09','62'),('11','1004','小猛','2022-05-10','12'),('12','1003','小辉','2022-04-11','75'),('13','1004','小猛','2022-06-12','80'),('14','1003','小辉','2022-04-13','94');
**2.**需求
1)统计每个用户截至每次下单的累积下单总额
期望结果:
order_iduser_iduser_nameorder_dateorder_amountsum_so_far11001小元2022-01-01101051001小元2022-01-05465681001小元2022-01-085010631001小元2022-02-032312961001小元2022-04-064217121002小海2022-01-02151541002小海2022-01-04294471002小海2022-01-07509491003小辉2022-04-086262101003小辉2022-04-0962124121003小辉2022-04-1175199141003小辉2022-04-1394293111004小猛2022-05-101212131004小猛2022-06-128092
(2)需求实现
select order_id,user_id, user_name,order_date,order_amount,sum(order_amount)over(partitionby user_id orderby order_date
rowsbetweenunboundedprecedingandcurrentrow) sum_so_far
from order_info;
2)统计每个用户截至每次下单的当月累积下单总额
(1)期望结果
order_iduser_iduser_nameorder_dateorder_amountsum_so_far11001小元2022-01-01101051001小元2022-01-05465681001小元2022-01-085010631001小元2022-02-03232361001小元2022-04-06424221002小海2022-01-02151541002小海2022-01-04294471002小海2022-01-07509491003小辉2022-04-086262101003小辉2022-04-0962124121003小辉2022-04-1175199141003小辉2022-04-1394293111004小猛2022-05-101212131004小猛2022-06-128080
(2)需求实现
select
order_id,
user_id,
user_name,
order_date,
order_amount,sum(order_amount)over(partitionby user_id,substring(order_date,1,7)orderby order_date rowsbetweenunboundedprecedingandcurrentrow) sum_so_far
from order_info;
3)统计每个用户每次下单距离上次下单相隔的天数(首次下单按0天算)
(1)期望结果
order_iduser_iduser_nameorder_dateorder_amountdiff11001小元2022-01-0110051001小元2022-01-0546481001小元2022-01-0850331001小元2022-02-03232661001小元2022-04-06426221002小海2022-01-0215041002小海2022-01-0429271002小海2022-01-0750391003小辉2022-04-08620101003小辉2022-04-09621121003小辉2022-04-11752141003小辉2022-04-13942111004小猛2022-05-10120131004小猛2022-06-128033
(2)需求实现
select order_id,user_id,user_name,order_date,order_amount,
nvl(datediff(order_date,last_order_date),0) diff
from(select order_id,user_id, user_name,order_date, order_amount,
lag(order_date,1,null)over(partitionby user_id orderby order_date) last_order_date
from order_info
)t1
4)查询所有下单记录以及每个用户的每个下单记录所在月份的首末次下单日期
(1)期望结果
order_iduser_iduser_nameorder_dateorder_amountfirst_datelast_date11001小元2022-01-01102022-01-012022-01-0851001小元2022-01-05462022-01-012022-01-0881001小元2022-01-08502022-01-012022-01-0831001小元2022-02-03232022-02-032022-02-0361001小元2022-04-06422022-04-062022-04-0621002小海2022-01-02152022-01-022022-01-0741002小海2022-01-04292022-01-022022-01-0771002小海2022-01-07502022-01-022022-01-0791003小辉2022-04-08622022-04-082022-04-13101003小辉2022-04-09622022-04-082022-04-13121003小辉2022-04-11752022-04-082022-04-13141003小辉2022-04-13942022-04-082022-04-13111004小猛2022-05-10122022-05-102022-05-10131004小猛2022-06-12802022-06-122022-06-12
(2)需求实现
select order_id,user_id,user_name,order_date,order_amount,
first_value(order_date)over(partitionby user_id,substring(order_date,1,7)orderby order_date) first_date,
last_value(order_date)over(partitionby user_id,substring(order_date,1,7)orderby order_date rowsbetweenunboundedprecedingandunboundedfollowing) last_date
from order_info;
5)为每个用户的所有下单记录按照订单金额进行排名
(1)期望结果
order_iduser_iduser_nameorder_dateorder_amountrkdrkrn81001小元2022-01-085011151001小元2022-01-054622261001小元2022-04-064233331001小元2022-02-032344411001小元2022-01-011055571002小海2022-01-075011141002小海2022-01-042922221002小海2022-01-0215333141003小辉2022-04-1394111121003小辉2022-04-117522291003小辉2022-04-0862333101003小辉2022-04-0962334131004小猛2022-06-1280111111004小猛2022-05-1012222
(2)需求实现
select order_id,user_id,user_name,order_date,order_amount,
rank()over(partitionby user_id orderby order_amount desc) rk,
dense_rank()over(partitionby user_id orderby order_amount desc) drk,
row_number()over(partitionby user_id orderby order_amount desc) rn
from order_info;
版权归原作者 轩裳已逝铭崖 所有, 如有侵权,请联系我们删除。