
基于混淆的加强网络安全的方法
原文链接:https://ieeexplore.ieee.org/abstract/document/9330553
一、摘要:
背景:web垃圾网页是一种不公平的做法,它采取不道德的措施改变了搜索引擎的排名方法,以提高搜索引擎的搜索结果。
本文贡献:本文提出了用于网络垃圾邮件检测的框架Cognitive spammer framework(CSF),从而对搜索引擎结果页面进行校正。
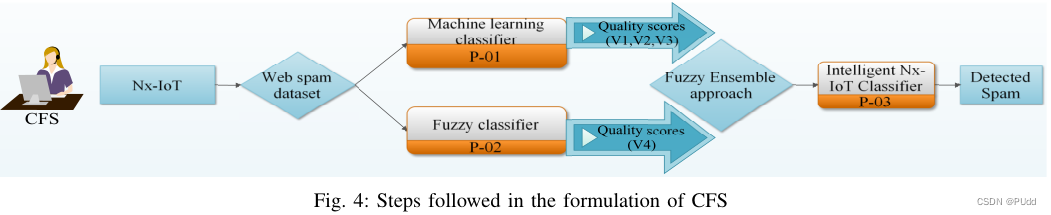
CSF通过三个机器学习分类器和基于模糊规则的分类器来检测web垃圾网页,其中每个分类器为网页采用QAIR进行质量评分。然后,这些质量分数被综合起来生成一个分数,这个分数可以预测网页的垃圾信息。CSF集成了这几个模型,建立起了一个智能模型,旨在提高ML模型的精度。(感觉也可以用作购物网站筛选评论、屏蔽广告刷单一类的操作)
二、相关工作
1 相关检测工作:
现有的技术,主要集中在恶意网页被搜索引擎索引后的检测。
(1)排名算法:
谷歌遵循排名算法,PageRank计算网页的排名得分。但是,垃圾邮件发送者仍然试图操纵搜索结果。例如,作者[13]以这种方式更新了PageRank算法,以便在恶意网页出现在搜索结果之前检测到它们。
(2)用户行为分析:
用户行为分析是检测垃圾网页的一个很好的参数。一个网页的相关性是通过用户花费的时间和点击次数来预测的。所提出的web垃圾邮件检测方案考虑了停留时间和点击次数两个因素。
(3)网页质量:
分析网页质量可以帮助计算其重要性。计算网页质量评分,建立的模型称为内容信任模型。
(4)机器学习:
它是在不同领域发挥不同作用的范式。它是进行实验和验证垃圾邮件检测算法的核心。它预测了用来形成垃圾网页的网页特征的合并。利用大量合并的网页特征训练ML模型,以标准数据集成功检测垃圾网页。
2 相关集成工作:
(1)非加权投票:
每个分类器不仅产生分类决策,而且产生类概率估计。由所有分类器产生的估计量组合在式2中。在这个方程中,hl是分类器,结果是在数据点x处对k的真实预测。
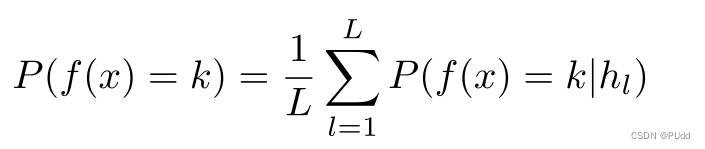
(2)最小二乘:
这种方法用于回归问题。该方法以最大权重为目标,提高了集成模型的精度。应用的原理是,由hl估计的方差与hl的权重成反比。
(3)似然组合:
该方法适用于分类问题。该方法根据独立的分类器权重计算每个分类器的精度。该方法采用先验分布P(hl)与估计似然P(S|hl)相乘的方法。
(4)门控网络:
它是一种组合分类器的方法,接受输入x并产生输出wl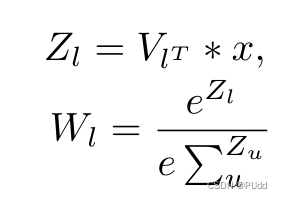
(5)堆叠:
它是通过遗漏一个交叉验证实现的。对于每个分类器和每个训练集,都会产生一个组合假设。在下一个迭代中,除了最后一个迭代之外,使用相同的过程。
三、具体做法:
(1)数据集、预处理、特征提取、洗数据
使用米兰大学的网络算法实验室发起的公开数据集(WEBSPAMUK2007)。数据集中,用包含2/3标签的SET1训练。进行预处理,采用PCA进行特征提取;然后使用一种过采样方法SOTU洗数据。
特征提取展示前七个:
特征选择:采用特征排序方法,即随机森林,计算特征的重要性。为特征排序计算的分数是“基尼指数”。不同的特征构成了树的不同节点。基尼值是为每个叶子计算的,无论是父叶子还是子叶子。然后,利用这些基尼值计算平均下降基尼值。选择的最优特性为:hostid, La-
bel, eq hp mp, indegree hp, indegree mp, outdegree hp, outdegree mp, pagerank hp, pagerank mp, trustrank hp,trustrank mp, truncatedpagerank 1 hp , truncatedpagerank 1 mp.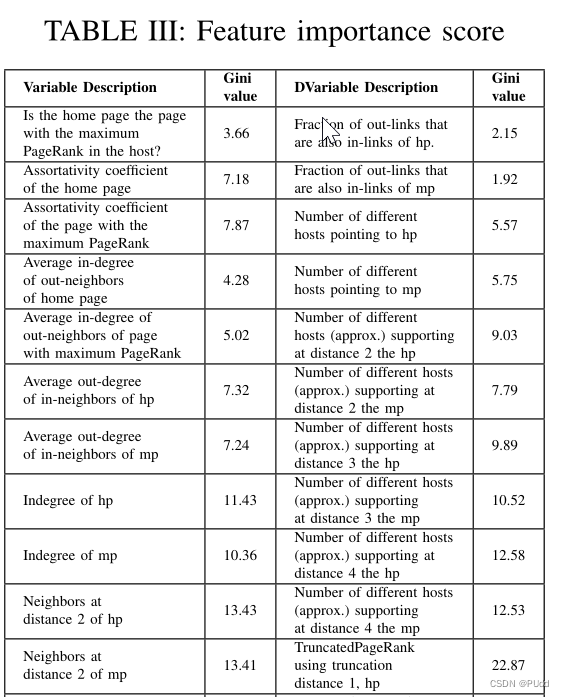
(2)模型
设计了三个机器学习分类器(Bagged Mars(缺点:新知识并不能很好地归纳), Bayesian广义线性模型,boosting线性模型)和一个基于模糊规则的分类器(FRBC)(由IF-THEN规则组成)。
分类规则:
1)收集每个分类器的输出,即网页的质量评分向量Vi。
2)将0到1范围内的每个向量归一化。
3)分数越接近0,垃圾网页的概率越高。分数越接近1,说明网页质量越好。0.5为分界线。
4)使用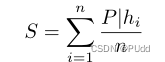 生成所有选票的组合。n为分类器个数,hi为每个分类器产生的假设。
生成所有选票的组合。n为分类器个数,hi为每个分类器产生的假设。
三个机器学习算法ROC曲线分别如下图所示: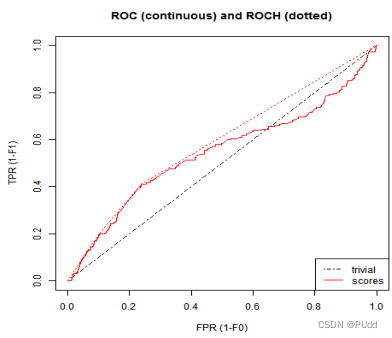
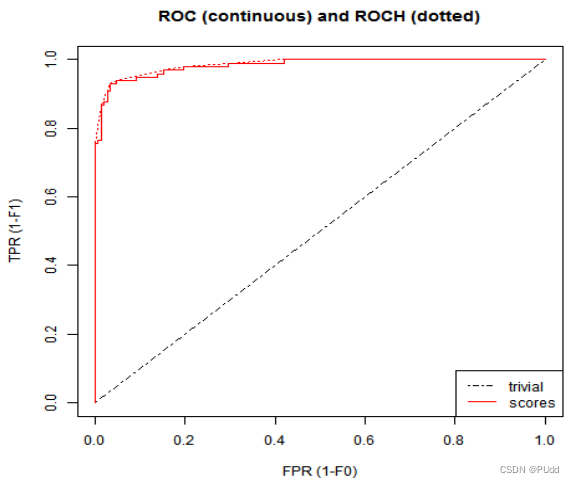
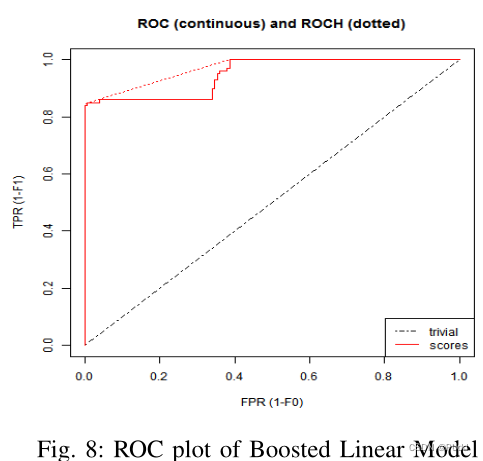
(3)模糊投票计算得分
采用模糊投票法对计算得分,所提出的模糊投票集成方法提高了模型的性能。
(4)测试
在标准数据集WEBSPAM-UK 2007上另外1/3的SET2用于测试。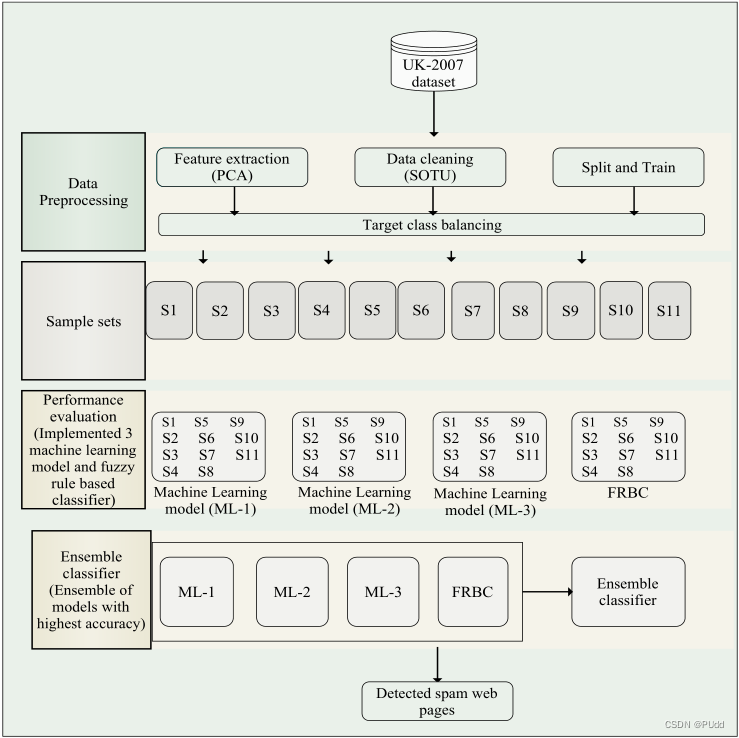
(5)评估得分
结果如下:
达到了97.3%的Accuracy。
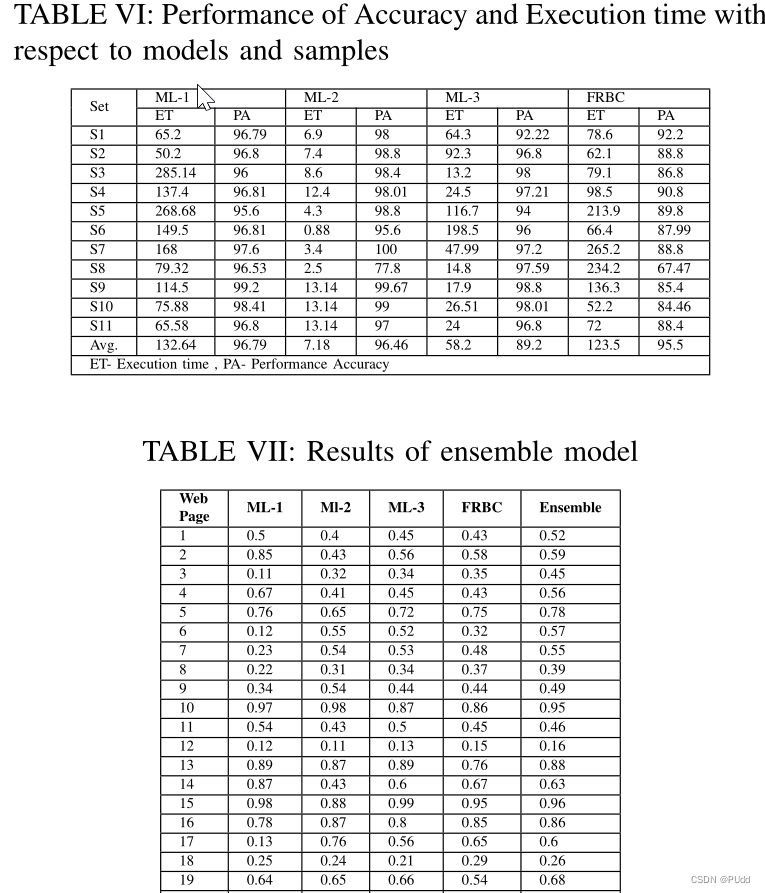
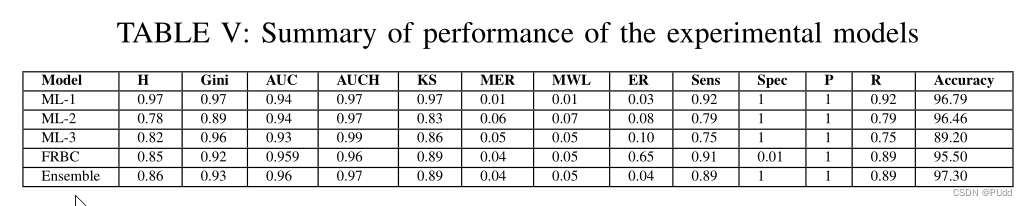
作者也比较了不同大小的训练集和测试集对于实验结果的影响,发现在训练集和测试集8:2的情况下效果比较好。
版权归原作者 PUdd 所有, 如有侵权,请联系我们删除。