
本篇知识点沿用知识点15的项目,为大家介绍spring boot如何连接kafka,本章有些长请耐心看完。没有kafka集群的去我主页找
各类型大数据集群搭建文档
–>
大数据原生集群本地测试环境搭建三
第一步:首先导入pom依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
第二步:修改spring boot配置文件
#kafka集群地址
spring.kafka.bootstrap-servers=192.168.88.186:9092,192.168.88.187:9092,192.168.88.188:9092
#生产者配置#系列化方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#重试次数
spring.kafka.producer.retries=0#采用的ack机制
spring.kafka.producer.acks=1#批量提交的数据大小 16kb
spring.kafka.producer.batch-size=16384#生产者暂存数据的缓冲区大小
spring.kafka.producer.buffer-memory=33554432#消费者配置#是否自动提交偏移量
spring.kafka.consumer.enable-auto-commit=true
#消费消息后间隔多长时间提交偏移量
spring.kafka.consumer.auto-commit-interval=100#默认的消费者组,代码中可以热键修改
spring.kafka.consumer.group-id=test
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
spring.kafka.consumer.auto-offset-reset=latest
#系列化方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
第三步:我们建立一个测试类,来认识如何使用生产者
packagecom.wy.scjg;importcom.wy.scjg.bean.User;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importorg.springframework.kafka.core.KafkaTemplate;importjavax.annotation.Resource;@SpringBootTestpublicclassKfKTest{@ResourceprivateKafkaTemplate kafkaTemplate;@Testvoidpro_test(){User user =newUser();
user.setName("张三");
user.setAge(20);
kafkaTemplate.send("test",user.toString());}}
我们在服务器端开一个消费者,消费test主题的消息,集群地址改你自己的
./bin/kafka-console-consumer.sh --bootstrap-server hdp1:9092,hdp2:9092,hdp3:9092 --topic test
我们运行测试类,看效果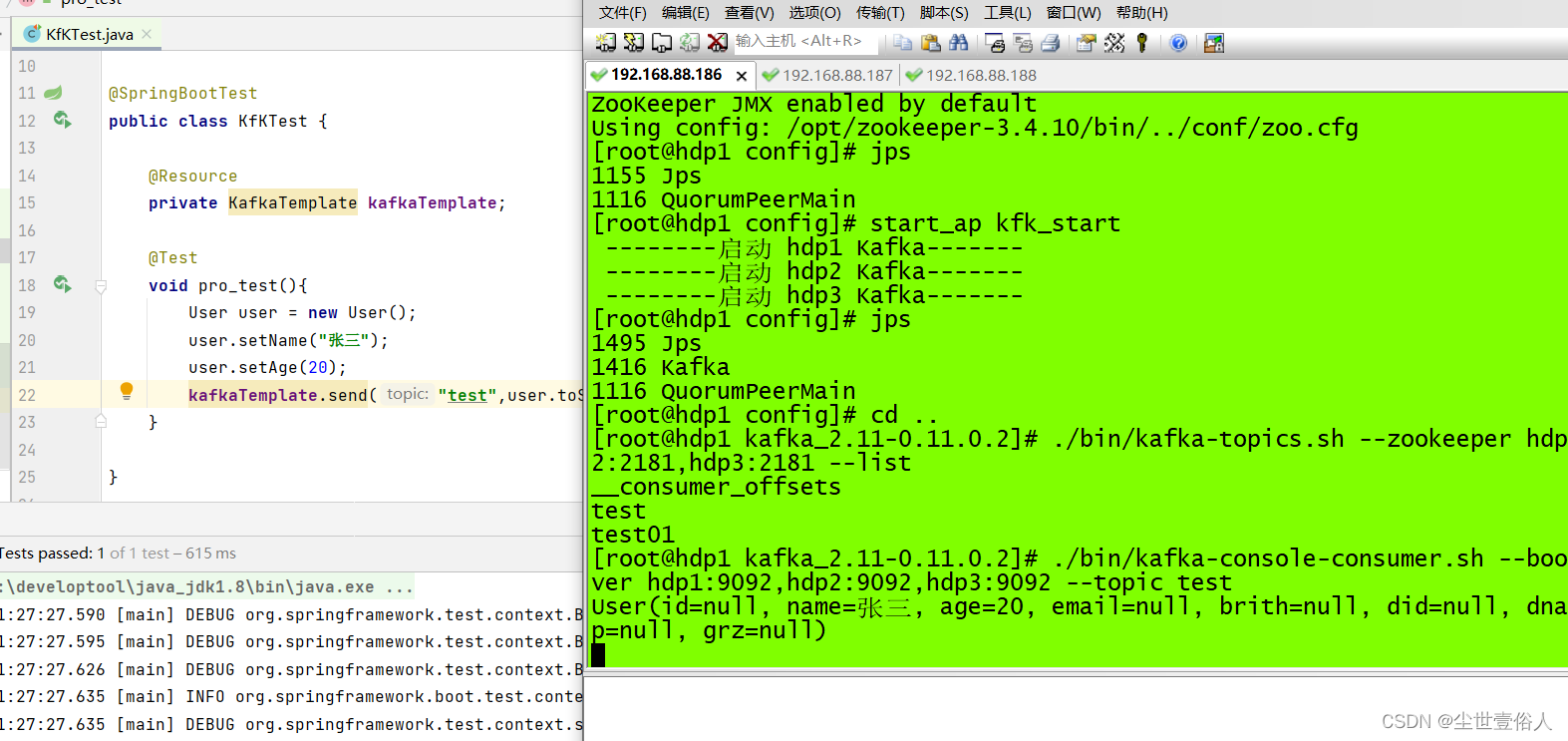
通过效果,我们可以看到数据成功发送
第四步:我们要知道spring boot整合的kafka为我们提供了两种可供选择的生产方式,上一步是其一叫做异步发送,也是默认的发送方式,另一种是同步发送,区别就在于异步发送是生产者消息发送到集群后一边等集群成功收到消息的回馈一边发送下一条,同步发送是发送后不再去马上准备下一条,而是等收到集群反馈的成功消息才准备下一条,下面我们看一下如何使用同步发送,修改测试类的发送方法
@Testvoidpro_test()throwsExecutionException,InterruptedException,TimeoutException{User user =newUser();
user.setName("张三");
user.setAge(20);//同步发送其实就是发送时强制监听结果ListenableFuture<SendResult<String,Object>> sendResult = kafkaTemplate.send("test", user.toString());//开始监听,设置一个时间,超过后放弃此处监听SendResult<String,Object> result = sendResult.get(3,TimeUnit.SECONDS);System.out.println("监听到的结果-------"+result.getProducerRecord().value());}
再次运行,我们可以看到,集群再次收到了消息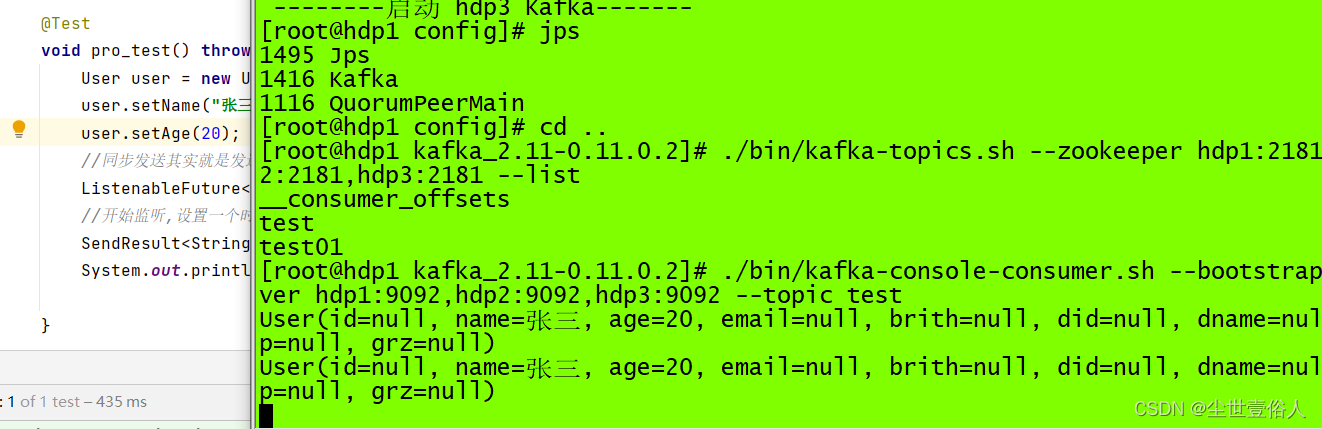
控制台也监听到了结果

第五步:生产者我们会用了,我们现在看看消费者如何使用,消费者必须要框架的支撑,因此我们不在使用测试类,我们让它以一个配置类的形式存在,当然大家如果愿意也可以新建一个独立的包存放,然后使用@Component注解向框架注册
packagecom.wy.scjg.config;importorg.apache.kafka.clients.consumer.KafkaConsumer;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.KafkaListener;@ConfigurationpublicclassConsumerConfig{privatefinalLogger logger =LoggerFactory.getLogger(KafkaConsumer.class);//不指定group,默认取spring boot里配置的@KafkaListener(id ="test1", topics ="test")publicvoidlisten(String mes){
logger.info("我收到的数据是-------------"+mes);}}
我们在服务器开一个生产者
./bin/kafka-console-producer.sh --broker-lisdp1:9092,hdp2:9092,hdp3:9092 --topic test
运行项目,生产者发生消息,看控制台的输出
但是消费者还需要两个东西,这里提供给大家
package com.wy.scjg.config;import org.apache.kafka.clients.admin.NewTopic;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.kafka.support.converter.RecordMessageConverter;import org.springframework.kafka.support.converter.StringJsonMessageConverter;
@Configuration
public class ConsumerConfig {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//不指定group,默认取spring boot里配置的
@KafkaListener(id ="test1", topics ="test")
public void listen(String mes){
logger.info("我收到的数据是-------------"+mes);}
@Bean
public RecordMessageConverter converter(){return new StringJsonMessageConverter();}
@Bean
public NewTopic topic(){
//主题 分区数 副本数
return new NewTopic("test", 1, (short)1);}}
我这里说一下这两个东西有什么用,NewTopic 是消费一个没有的主题时框架会创建,一般工作中如果用到了,切记副本数一定要按需求做更改,一般不可能是1,RecordMessageConverter是很早之前我碰到一个没有这个bean的bug,所以大家如果也遇到了可以怎么写一个
但其实消费者不止这一种写法,你还可以写成下面这个样子
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//不指定group,默认取spring boot配置文件里面的
@KafkaListener(topics ={"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord){
Optional<?> optional = Optional.ofNullable(consumerRecord.value());if(optional.isPresent()){
Object msg = optional.get();
logger.info("message:{}", msg);}}}
第六步:前面我们在发送消息时对同步的发送做了监听,那大家有没有想过,异步发送这么监听?有人会说同步监听不就相当于异步监听了吗,但本质上是不一样的,异步优点就是发送消息不会由于监听结果而造成阻塞,所以这个时候也就需要去注册一个异步监听的配置类
package com.wy.scjg.config;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.support.ProducerListener;import javax.annotation.PostConstruct;import javax.annotation.Resource;
@Configuration
public class ProSendYBLen {
private final static Logger logger = LoggerFactory.getLogger(KafkaListener.class);
@Resource
KafkaTemplate kafkaTemplate;
//配置监听
@PostConstruct
private void listener(){
kafkaTemplate.setProducerListener(new ProducerListener(){
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata){
logger.info("我已经接收到消息-----message={}", producerRecord.value());}
@Override
public void onError(ProducerRecord producerRecord, RecordMetadata recordMetadata, Exception exception){
logger.error("接收失败--------message={}", producerRecord.value());}});}}
想要看到效果,我们就需要有一个生产者的Controller,因为如果你还使用测试类的话生产者发送完消息后测试程序就结束了,和项目没关联的
packagecom.wy.scjg.controller;importcom.wy.scjg.bean.User;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.stereotype.Controller;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.ResponseBody;importjavax.annotation.Resource;importjava.util.concurrent.ExecutionException;importjava.util.concurrent.TimeoutException;@Controller@RequestMapping("/kfk")publicclassKfkController{@ResourceprivateKafkaTemplate kafkaTemplate;@RequestMapping("/send")@ResponseBodypublicStringpro_test()throwsExecutionException,InterruptedException,TimeoutException{User user =newUser();
user.setName("张三");
user.setAge(20);
kafkaTemplate.send("test", user.toString());return"发送完成";}}
注意如果你是跟着知识点走的,那就把拦截器设置一下,不然影响演示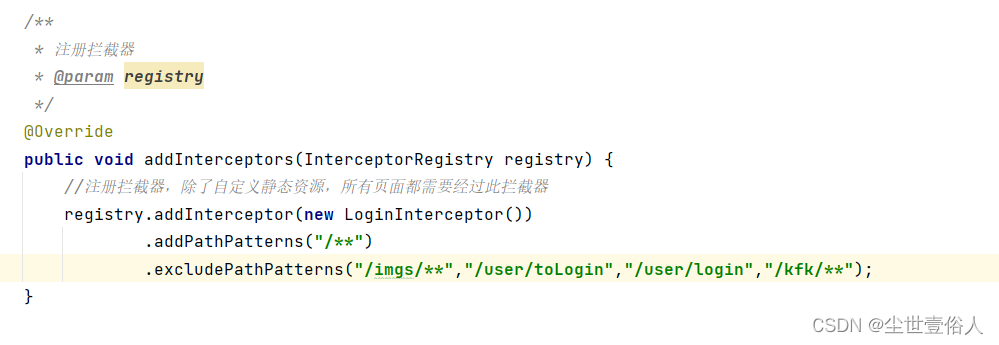
然后运行项目,对发送消息的kafka控制器发出请求,之后你会在控制台中发现如下输出
到此我希望大家不要钻牛角尖,去考虑消费者监听怎么写,消费者进程本身就是个监听器,没有说像生产者一样再去写一个的说法
第七步:这一步是个理论知识,可以跳过
我们知道生产者和消费者是有系列化方式的,一般默认用
org.apache.kafka.common.serialization.StringDeserializer
,同时数据的发送一般都是字符串就足以满足需求,很少用到其他的类型,但是我们要知道系列化方式不止有String,还有Long等等的其他类型,大家可以看下序列化包下的类,如下图
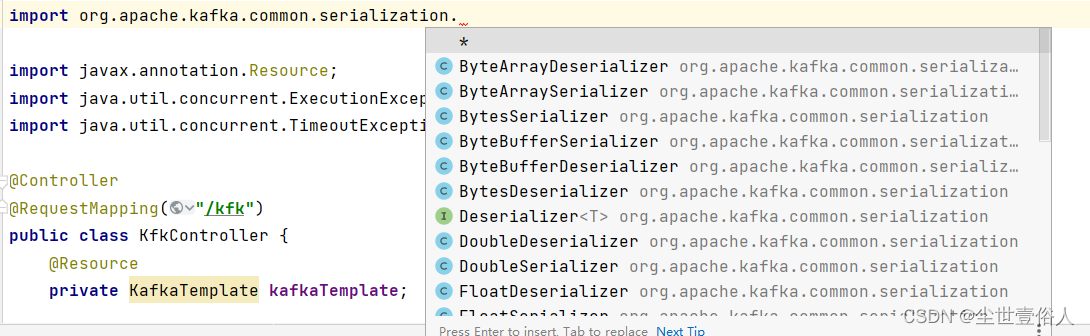
在网络上你会看到自己写系列化类的,比如我想要发出去的数据本身就是JSON格式,那就自定义一个生产者用的系列化类,实现
Serializable
接口,重写
public byte[] serialize(String s, Object o) {}
方法,然后在有一个消费者用的反系列化类,实现
Deserializer
接口,重写
public Object deserialize(String s, byte[] bytes)
方法,最后将这两个类配置在spring boot的kafka配置里
这一套理论上是可行的,但是实际开发中我们不会去做,因为没有必要,一个搞不好出问题还不好解决,同时之所以说是理论上可行,还因为Serializable和Deserializer接口的方法编译不让重写会报错
第八步:在生产和消费的时候,我们可以指定发送到那个分区下,想要指定分区有两种方式
#直接指定0分区
kafkaTemplate.send("test", 0, key, "");#不指定数字分区时,按照key的hash决定分区
kafkaTemplate.send("test", key, "")
消费的时候你也可以指定消费的分区,不过只能直接指定
@KafkaListener(topics ={"test"},topicPattern ="0")
你如果想用给自定义的也可以,那你就需要自定义一个分区的策略类
packagecom.wy.scjg.config;importorg.apache.kafka.clients.producer.Partitioner;importorg.apache.kafka.common.Cluster;importjava.util.Map;publicclassMyPartitionerimplementsPartitioner{@Overridepublicintpartition(String s,Object key,byte[] bytes,Object o1,byte[] bytes1,Cluster cluster){String keyStr = key+"";if(keyStr.startsWith("0")){return0;}else{return1;}}@Overridepublicvoidclose(){}@Overridepublicvoidconfigure(Map<String,?> map){}}
然后自定义一个Kafka的配置类
packagecom.wy.scjg.config;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.common.serialization.StringSerializer;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.beans.factory.annotation.Value;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.core.DefaultKafkaProducerFactory;importorg.springframework.kafka.core.KafkaTemplate;importjavax.annotation.PostConstruct;importjava.util.HashMap;importjava.util.Map;@ConfigurationpublicclassMyPartitionTemplate{privatefinalLogger logger =LoggerFactory.getLogger(this.getClass());@Value("${spring.kafka.bootstrap-servers}")privateString bootstrapServers;KafkaTemplate kafkaTemplate;@PostConstructpublicvoidsetKafkaTemplate(){Map<String,Object> props =newHashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);//注意分区器在这里!!!
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyPartitioner.class);this.kafkaTemplate =newKafkaTemplate<String,String>(newDefaultKafkaProducerFactory<>(props));}publicKafkaTemplategetKafkaTemplate(){return kafkaTemplate;}}
解释一下PostConstruct的作用,它用来标注一个非静态的方法,用来在spring boot注入一个对象后被调用,对该对象做配置
这样你就不能直接用
KafkaTemplate
了,你要注入你自定义的
MyPartitionTemplate
,我们用前面介绍生产者时的测试类修改一下
packagecom.wy.scjg;importcom.wy.scjg.config.MyPartitionTemplate;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importjava.util.concurrent.ExecutionException;importjava.util.concurrent.TimeoutException;@SpringBootTestpublicclassKfKTest{@AutowiredprivateMyPartitionTemplate myPartitionTemplate;@Testvoidpro_test()throwsExecutionException,InterruptedException,TimeoutException{
myPartitionTemplate.getKafkaTemplate().send("test",0,"0","0开头的数据");}}
同时你的消费者配置类也要改一下,我改的时候为了和前面呼应,我将消费者改成了另一种写法,大家注意一下
packagecom.wy.scjg.config;importorg.apache.kafka.clients.admin.NewTopic;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.apache.kafka.clients.consumer.KafkaConsumer;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.kafka.support.converter.RecordMessageConverter;importorg.springframework.kafka.support.converter.StringJsonMessageConverter;importjava.util.Optional;@ConfigurationpublicclassConsumerConfig{privatefinalLogger logger =LoggerFactory.getLogger(KafkaConsumer.class);@KafkaListener(id ="test1", topics ="test",topicPattern ="0")publicvoidonMessage1(ConsumerRecord<?,?> consumerRecord){Optional<?> optional =Optional.ofNullable(consumerRecord.value());if(optional.isPresent()){Object msg = optional.get();
logger.info("partition=0,message:{}", msg);}}@BeanpublicRecordMessageConverterconverter(){returnnewStringJsonMessageConverter();}@BeanpublicNewTopictopic(){//主题 分区数 副本数returnnewNewTopic("test",1,(short)1);}}
此时运行项目,通过测试类向不同分区发送消息,看控制台的输出,你就会发现,你只能接收到0分区的内容
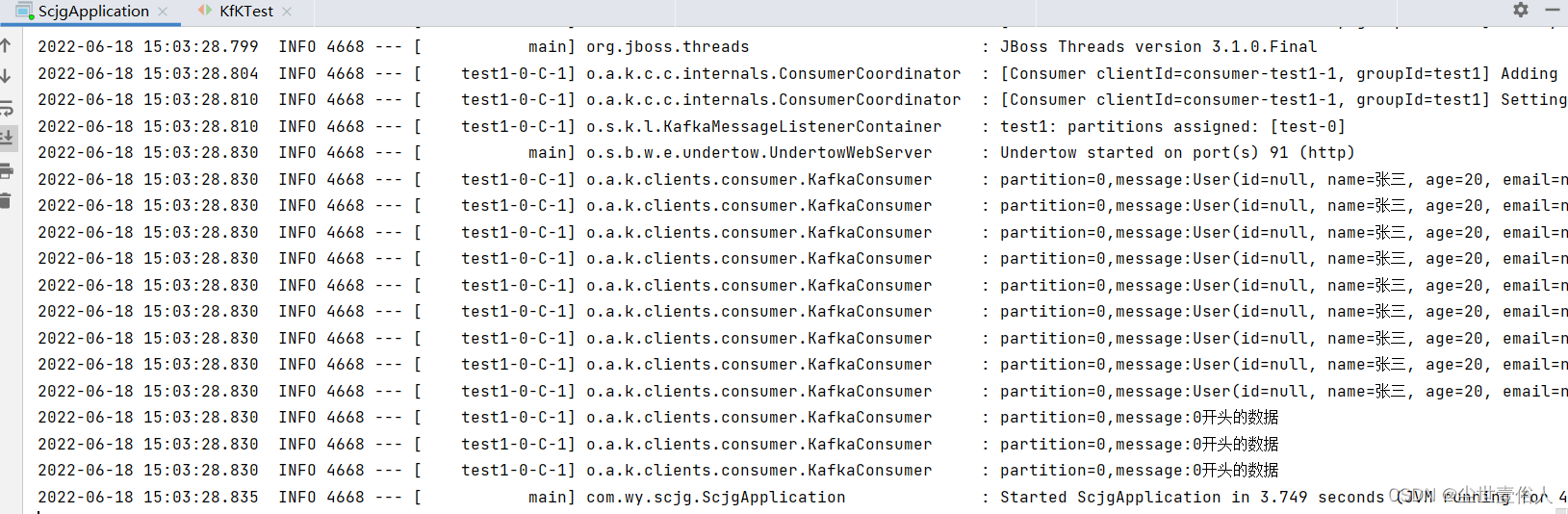
第九步:说完分区,我们再说一下消费者组,你可以为了提高效率,在消费者中写多个方法接收数据,如下面这样
//组1,消费者1
@KafkaListener(topics ={"test"},groupId ="group1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord){
Optional<?> optional = Optional.ofNullable(consumerRecord.value());if(optional.isPresent()){
Object msg = optional.get();
logger.info("group:group1-1 , message:{}", msg);}}
//组1,消费者2
@KafkaListener(topics ={"test"},groupId ="group1")
public void onMessage2(ConsumerRecord<?, ?> consumerRecord){
Optional<?> optional = Optional.ofNullable(consumerRecord.value());if(optional.isPresent()){
Object msg = optional.get();
logger.info("group:group1-2 , message:{}", msg);}}
//组2,只有一个消费者
@KafkaListener(topics ={"test"},groupId ="group2")
public void onMessage3(ConsumerRecord<?, ?> consumerRecord){
Optional<?> optional = Optional.ofNullable(consumerRecord.value());if(optional.isPresent()){
Object msg = optional.get();
logger.info("group:group2 , message:{}", msg);}}
注意如果你的主题分区数大于同组下消费者数,则正常按照消费者策略划分,但如果你的同组消费者数大于主题分区数,那就会出现空闲的消费者进程,这种情况你最好做处理,即使在正式工作开发中,也不要有这种情况,因为说不准空闲的消费者进程就会导致任务阻塞超时,接收不到数据就会认为网络卡顿,一直在那等着,不给你返回结果,处理方式要不对主题加分区,要不就是生成新的主题
第十步:最后我们说一下偏移量,一般情况下,项目开发用的是自动提交偏移量,但是有的时候不排除让你手动提交偏移量,这个时候也就需要自定义配置类了,和自定义发送分区差不多
首先你要有一个配置类,主要作用是修改手动提交的配置
@Configuration
public class MyOffsetConfig {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaListenerContainerFactory<?>manualKafkaListenerContainerFactory(){
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 注意这里!!!设置手动提交
configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));
// ack模式:
// AckMode针对ENABLE_AUTO_COMMIT_CONFIG=false时生效,有以下几种:
//
// RECORD
// 每处理一条commit一次
//
// BATCH(默认)
// 每次poll的时候批量提交一次,频率取决于每次poll的调用频率
//
// TIME
// 每次间隔ackTime的时间去commit(跟auto commit interval有什么区别呢?)
//
// COUNT
// 累积达到ackCount次的ack去commit
//
// COUNT_TIME
// ackTime或ackCount哪个条件先满足,就commit
//
// MANUAL
// listener负责ack,但是背后也是批量上去
//
// MANUAL_IMMEDIATE
// listner负责ack,每调用一次,就立即commit
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);return factory;}}
然后再消费者中你就可以在消费者中选择一种下列代码中核实你的一种写法
@ComponentpublicclassMyOffsetConsumer{privatefinalLogger logger =LoggerFactory.getLogger(this.getClass());@KafkaListener(topics ="test", groupId ="myoffset-group-1", containerFactory ="manualKafkaListenerContainerFactory")publicvoidmanualCommit(@PayloadString message,@Header(KafkaHeaders.RECEIVED_PARTITION_ID)int partition,@Header(KafkaHeaders.RECEIVED_TOPIC)String topic,Consumer consumer,Acknowledgment ack){
logger.info("手动提交偏移量 , partition={}, msg={}", partition, message);// 同步提交
consumer.commitSync();//异步提交//consumer.commitAsync();// ack提交也可以,会按设置的ack策略走(参考MyOffsetConfig.java里的ack模式)// ack.acknowledge();}@KafkaListener(topics ="test", groupId ="myoffset-group-2", containerFactory ="manualKafkaListenerContainerFactory")publicvoidnoCommit(@PayloadString message,@Header(KafkaHeaders.RECEIVED_PARTITION_ID)int partition,@Header(KafkaHeaders.RECEIVED_TOPIC)String topic,Consumer consumer,Acknowledgment ack){
logger.info("忘记提交偏移量, partition={}, msg={}", partition, message);// 不做commit!这里如果你要用一定要提交,这个方法是用来做不提交,会重复消费的测试的}/**
* 现实状况:
* commitSync和commitAsync组合使用
* <p>
* 手工提交异步 consumer.commitAsync();
* 手工同步提交 consumer.commitSync()
* <p>
* commitSync()方法提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,
* commitSync()会一直重试,但是commitAsync()不会。
* <p>
* 一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大问题
* 因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。
* 但如果这是发生在关闭消费者或再均衡前的最后一次提交,就要确保能够提交成功。否则就会造成重复消费
* 因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
*/@KafkaListener(topics ="test", groupId ="myoffset-group-3",containerFactory ="manualKafkaListenerContainerFactory")publicvoidmanualOffset(@PayloadString message,@Header(KafkaHeaders.RECEIVED_PARTITION_ID)int partition,@Header(KafkaHeaders.RECEIVED_TOPIC)String topic,Consumer consumer,Acknowledgment ack){try{
logger.info("同步异步搭配 , partition={}, msg={}", partition, message);//先异步提交
consumer.commitAsync();//继续做别的事}catch(Exception e){System.out.println("commit failed");}finally{try{
consumer.commitSync();}finally{
consumer.close();}}}/**
* 甚至可以手动提交,指定任意位置的偏移量
* 不推荐日常使用!!!
*/@KafkaListener(topics ="test", groupId ="myoffset-group-4",containerFactory ="manualKafkaListenerContainerFactory")publicvoidoffset(ConsumerRecordrecord,Consumer consumer){
logger.info("手动指定任意偏移量, partition={}, msg={}",record.partition(),record);Map<TopicPartition,OffsetAndMetadata> currentOffset =newHashMap<>();
currentOffset.put(newTopicPartition(record.topic(),record.partition()),newOffsetAndMetadata(record.offset()+1));
consumer.commitSync(currentOffset);}}
到此spring boot整合kafka就介绍完了,最后在强调一遍,如果关闭了自动提交偏移量,那一定要手动提交,并且推荐使用manualOffset这种提交方式
我还要给各位开发者提一个醒,千万要分清直接使用kafka和spring boot整合kafka这两种开发手段的区别,他们两个虽然原理相同,但是由于是两个相对独立的东西,所以在配置和使用以及理解上千万不要混为一谈,就比如最开始说的spring boot整合kafka的同步监听,这个只是恰巧spring boot给你提供了这种可操作手段,和kafka本身的ack是互不影响的两个东西
到此本springbootdemo1.0版本完成
到此本篇知识点讲解结束,此外 本次整体讲解的spring boot项目已上传github
版权归原作者 尘世壹俗人 所有, 如有侵权,请联系我们删除。