
环境准备及提交流程
底层通信协议
- Akka通信协议,收发邮箱是一体的
- Netty通信协议,收发邮箱是分开的
任务调度
任务的最小单位是线程。失败重试,会记录失败的次数,如果超过最大重试次数,宣告Application失败。失败的同时会记录它上一次所在的ExecutorID和Host, 最多重试4次。
Shuffle
功能:打散重分区
特点:无论MR和Spark,Shuffle都需要落盘。其中的区别是MR每次都落盘,Spark是尽可能少落盘。
落盘的话就需要考虑不同分区之间的数据如何存放的问题。假设每个Executor有两个Task,总共有三个分区。以下是四种shuffle落盘的策略:
- 每个Task里面的数据打散成3个文件,一个Executor生成6个文件
- Executor里面的两个Task的数据打散到3个文件中,一个分区一个文件,共3个文件。
sortShuffle: Executor里面打散的数据落盘到一个文件中,三个分区的数据通过索引来区分。这个就是SortShuffle,目前MR就是sortShuffle。bypassShuffle:对不同分区的数据进行打散重分区时不对数据进行排序,只适合非聚合类的shuffle算子,比如reduceByKey。
Spark内存管理
堆内和堆外内存
- 堆内:通过JVM申请的内存,通过了JVM的转化,更加安全,并且有垃圾回收机制。
- 堆外:也称页缓存,自己向操作系统申请。没有经过JVM转换,不安全,没有垃圾回收机制。堆外的内存空间是通过C语言控制的,有出现内存泄漏的危险。 - 优点: - 减少了垃圾回收的工作- 加快了复制的速度,省略了序列化的操作。- 缺点: - 堆外内存难以控制,如果内存泄漏,很难排查- 不适合存储复杂对象。
- spark中,堆外内存默认是关闭的。
- 配置方法 - executor-memory 和 driver-memory- 启用堆外内存spark.memory.offHeap.eabled,并由spark.memory.offHeap.size设置堆外空间大小。
内存的分配
- 静态内存管理,简称写死 - 分为三个部分: - 存储空间60%- 执行空间20%- 其他空间20%
- 统一内存管理,简称动态分配 - 分为三个部分 - 其他空间40%- 存储空间+计算空间=60%- 存储和计算空间反向使用,允许空间借用。
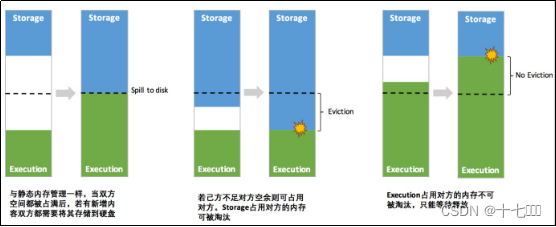
RDD的持久化机制
存储内存淘汰规则:
- 旧RDD所属RDD不能处于被读状态,避免引发一致性问题
- 新旧Block不能属于同一个RDD,避免循环淘汰
- 按照最近最少LRU进行淘汰
本文转载自: https://blog.csdn.net/qq_44273739/article/details/133945678
版权归原作者 十七✧ᐦ̤ 所有, 如有侵权,请联系我们删除。
版权归原作者 十七✧ᐦ̤ 所有, 如有侵权,请联系我们删除。