
系列文章目录
- 1- RDD的基本介绍(了解)
- 2- 如何构建RDD(熟悉)
- 3- RDD的相关算子(案例详解) (掌握)
- 4- spark RDD算子相关面试题(重点)
文章目录
前言
本文主要详解Spark RDD及工作中常用RDD算子;
一、RDD的基本介绍(了解)
1、什么是RDD
RDD:英文全称Resilient Distributed Dataset,叫做弹性分布式数据集,代表一个不可变、可分区、里面的元素可并行计算的分布式的抽象的数据集合。
- Resilient弹性:RDD的数据可以存储在内存或者磁盘当中,RDD的数据可以分区
- Distributed分布式:RDD的数据可以分布式存储,可以进行并行计算
- Dataset数据集:一个用于存放数据的集合
2、RDD的五大特性
1、(必须的)RDD是由一系列分区组成的
2、(必须的)对RDD做计算,相当于对RDD的每个分区做计算
3、(必须的)RDD之间存在着依赖关系(宽依赖和窄依赖)
4、(可选的)对于KV类型的RDD,默认操作的是k,当然我们可以进行自定义分区方案
5、(可选的)移动数据不如移动计算,让计算程序离数据越近越好
3、RDD的五大特点
1、分区:RDD逻辑上是分区的,仅仅是定义分区的规则,并不是直接对数据进行分区操作,因为RDD本身不存储数据。
2、只读:RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
3、依赖:RDD之间存在着依赖关系(宽依赖和窄依赖)
4、cache缓存:如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,后续每次直接从缓存获取即可
5、checkpoint检查点:与缓存类似的,都是可以将中间某一个RDD的结果保存起来,只不过checkpoint支持真正持久化保存
二、如何构建RDD(熟悉)
构建RDD对象的方式主要有两种:
1、通过 parallelize(data): 通过自定义列表的方式初始化RDD对象。(一般用于测试)
2、通过 textFile(data): 通过读取外部文件的方式来初始化RDD对象,实际工作中经常使用。

1、并行化本地集合方式
- 黑窗口中实现:

- 开发工具实现:
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
conf = SparkConf().setAppName('pyspark_demo').setMaster('local[3]')
sc = SparkContext(conf=conf)
# 2.数据输入
# 3.数据处理(切分,转换,分组聚合)
d = [1, 2, 3, 4]
rdd = sc.parallelize(d,numSlices=1)
# 4.数据输出
print(rdd.collect())
# 6.分区演示
# 获取分区数
print(rdd.getNumPartitions())
# 获取各个分区数据
print(rdd.glom().collect())
# 5.关闭资源
sc.stop()
相关的API:
# parallelize(参数1,参数2)
使用本地数据构建RDD。参数1:本地数据列表;参数2:可选的,表示有多少个分区
# getNumPartitions
查看RDD的分区数量
# glom
查看每个分区的数据内容
修改分区数,效果:
1- 默认和setMaster('local[num]')中的num数量有关。如果是*,就是和机器的CPU核数相同。另外可以指定具体的数字,数字是多少,那么分区数就是多少
2- parallelize()中第二个参数numSlices可以手动指定RDD的分区数。如果同时设置了local和numSlices,numSlices的优先级高一些
2、读取外部数据源方式
- TextFile API的方式实现:
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
conf = SparkConf().setAppName('pyspark_demo').setMaster('local[3]')
sc = SparkContext(conf=conf)
# 2.数据输入
# 3.数据处理(切分,转换,分组聚合)
# 注意: 如果要提交到yarn,文件建议使用hdfs路径
rdd = sc.textFile('hdfs://node1:8020/source/c1.txt',minPartitions=1)
# 4.数据输出
print(rdd.collect())
# 6.分区演示
# 获取分区数
print(rdd.getNumPartitions())
# 获取各个分区数据
print(rdd.glom().collect())
# 5.关闭资源
sc.stop()
修改分区数,效果:
到底有多少个分区,一切以getNumPartitions结果为准
分区数据量,当调大local[num]中num的值时候,不生效;调小的时候生效
同时也受minPartitions影响
3、处理小文件的操作
wholeTextFiles: wholeTextFiles既能直接读取文件,也能读取一个目录下的所有小文件
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
conf = SparkConf().setAppName('pyspark_demo').setMaster('local[10]')
sc = SparkContext(conf=conf)
# 2.数据输入
# 3.数据处理(切分,转换,分组聚合)
# 注意: 如果要提交到yarn,文件建议使用hdfs路径
# 注意: wholeTextFiles既能直接读取文件,也能读取一个目录下的所有小文件
rdd = sc.wholeTextFiles('hdfs://node1:8020/source/c1.txt')
# 4.数据输出
print(rdd.collect())
# 6.分区演示
# 获取分区数
print(rdd.getNumPartitions())
# 获取各个分区数据
print(rdd.glom().collect())
# 5.关闭资源
sc.stop()
修改分区数,效果:
wholeTextFiles: 读取小文件。
1-支持本地文件系统和HDFS文件系统。参数minPartitions指定最小的分区数。
2-通过该方式读取文件,会尽可能使用少的分区数,可能会将多个小文件的数据放到同一个分区中进行处理。
3-一个文件要完整的存放在一个元组中,也就是不能将一个文件分成多个进行读取。文件是不可分割的。
4-RDD分区数量既受到minPartitions参数的影响,同时受到小文件个数的影响
4、RDD分区数量如何确定
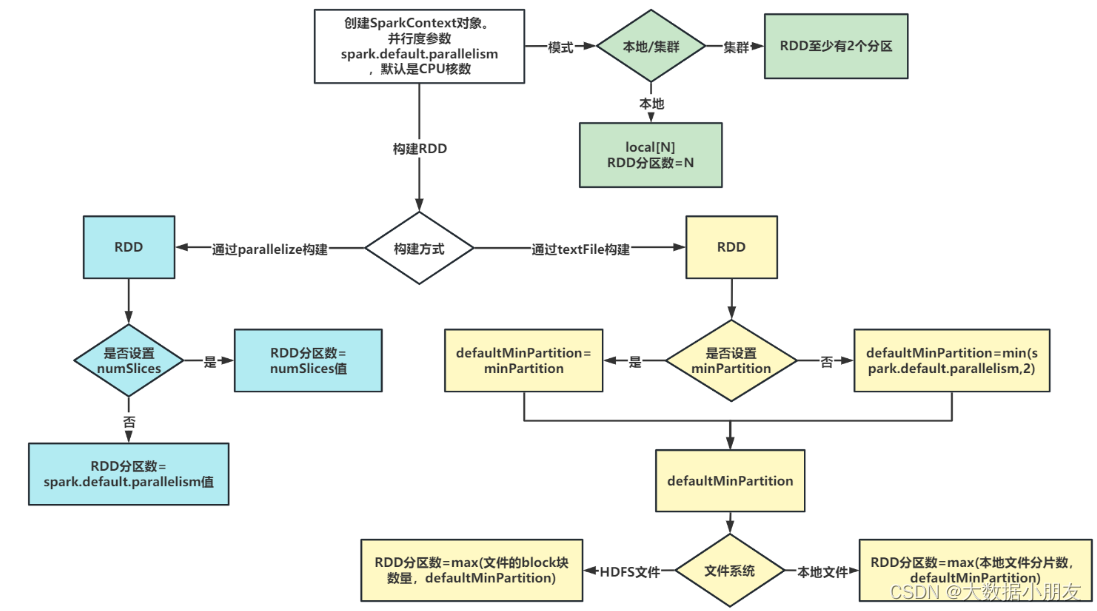
1- RDD的分区数量,一般设置为机器CPU核数的2-3倍。为了充分利用服务器的硬件资源
2- RDD的分区数据量受到多个因素的影响,例如:机器CPU的核数、调用的算子、算子中参数的设置、集群的类型等。RDD具体有多少个分区,直接通过getNumPartitions查看
3- 当初始化SparkContext对象的时候,其实就确定了一个参数spark.default.parallelism,默认为CPU的核数。如果是本地集群,就取决于local[num]中设置的数字大小;如果是集群,默认至少有2个分区
4- 通过parallelize来构建RDD,如果没有指定分区数,默认就取spark.default.parallelism参数值;如果指定了分区数,也就是numSlices参数,那么numSlices的优先级会更高一些,最终RDD的分区数取该参数的值。
5- 通过textFile来构建RDD
5.1- 首先确认defaultMinPartition参数的值。该参数的值,如果没有指定textFile的minPartition参数,那么就根据公式min(spark.default.parallelism,2);如果有指定textFile的minPartition参数,那么就取设置的值
5.2- 再根据读取文件所在的文件系统的不同,来决定最终RDD的分区数:
5.2.1- 本地文件系统: RDD分区数 = max(本地文件分片数,defaultMinPartition)
5.2.2- HDFS文件系统: RDD分区数 = max(文件block块的数量,defaultMinPartition)
- 常规处理小文件的办法(补充):
1- 大数据框架提供的现有的工具或者命令
1.1- 合并hdfs中多个小文件到linux本地: hadoop fs -getmerge 小文件路径 linux输出路径/文件名.后缀名
举例: [root@node1 ~]# hadoop fs -getmerge /data/*.txt /merged_file.txt
1.2- 归档hdfs中多个小文件到hdfs: hadoop archive -archiveName 归档名.har -p 小文件路径 hdfs输出路径
举例: [root@node1 ~]# hadoop archive -archiveName merged_file.har -p /data/ /
2- 可以通过编写自定义的代码,将小文件读取进来,在代码中输出的时候,输出形成大的文件
三、RDD的相关算子(掌握)
RDD算子: 指的是RDD对象中提供了非常多的具有特殊功能的函数, 我们将这些函数称为算子(函数/方法/API)
相关的算子的官方文档: https://spark.apache.org/docs/3.1.2/api/python/reference/pyspark.html#rdd-apis
1、RDD算子的分类
整个RDD算子, 共分为两大类:
## Transformation(转换算子):
返回值: 是一个新的RDD
特点: 转换算子只是定义数据的处理规则,并不会立即执行,是lazy(惰性)的。需要由Action算子触发
Action(动作算子):
返回值: 要么没有返回值None,或者返回非RDD类型的数据
特点: 动作算子都是立即执行。执行的时候,会将它上游的其他算子一同触发执行
- 相关的转换算子,如图所示:

- 相关的动作算子,如图所示:

2、RDD的转换算子
Transformation(转换算子):
返回值: 是一个新的RDD
特点: 转换算子只是定义数据的处理规则,并不会立即执行,是lazy(惰性)的。需要由Action算子触发
2.1 单值类型算子

map算子:
- 格式:rdd.map(fn)
- 说明: 主要根据传入的函数,对数据进行一对一的转换操作,传入一行,返回一行
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 数字加一后返回
代码: init_rdd.map(lambda num:num+1).collect()
结果: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
flatMap算子:
- 格式:rdd.flatMap(fn)
- 说明:在map算子的基础上,加入一个压扁的操作, 主要适用于一行中包含多个内容的操作,实现一转多的操作
输入: init_rdd = sc.parallelize(['张三 李四 王五','赵六 周日'])
需求: 将姓名拆分,把每个姓名都放到同一个数据集中
代码: init_rdd.flatMap(lambda line:line.split()).collect()
结果: ['张三', '李四', '王五', '赵六', '周日']
说明: split()默认会按照空白字符对内容进行切分处理。例如:空格、制表符、回车。还是推荐大家明确指定你所需要分割的符号。
groupBy 算子:
- 格式: groupBy(fn)
- 说明: 根据用户传入的自定义函数,对数据进行分组操作
- 注意: mapValues(list)可以以列表形式展示数据
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 将数据分成奇数和偶数
代码: init_rdd.groupBy(lambda num:"偶数" if num%2==0 else "奇数").mapValues(list).collect()
结果: [('偶数', [0, 2, 4, 6, 8]), ('奇数', [1, 3, 5, 7, 9])]
总结: mapValues(list)将数据类型转成List列表
filter算子:
- 格式:filter(fn)
- 说明:根据用户传入的自定义函数对数据进行过滤操作。自定义函数的返回值类型是bool类型。True表示满足过滤条件,会将数据保留下来;False会将数据丢弃掉
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 过滤掉数值<=3的数据
代码: init_rdd.filter(lambda num:num>3).collect()
结果: [4, 5, 6, 7, 8, 9]
2.2 双值类型算子
union(并集) 和intersection(交集)
- 格式: rdd1.union(rdd2) rdd1.intersection(rdd2)
- 注意: 并集的结果可以使用distinct()函数去重
输入: rdd1 = sc.parallelize([3,3,2,6,8,0])
rdd2 = sc.parallelize([3,2,1,5,7])
并集: rdd1.union(rdd2).collect()
结果: [3, 3, 2, 6, 8, 0, 3, 2, 1, 5, 7]
说明: union取并集不会对重复出现的数据去重
对并集的结果进行去重: rdd1.union(rdd2).distinct().collect()
结果: [8, 0, 1, 5, 2, 6, 3, 7]
说明: distinct()是转换算子,用来对RDD中的元素进行去重处理
交集: rdd1.intersection(rdd2).collect()
结果: [2, 3]
说明: 交集会对结果数据进行去重处理
2.3 KV类型算子
groupByKey():
- 格式: rdd.groupByKey()
- 说明: 对键值对类型的RDD中的元素按照键key进行分组操作。只会进行分组
输入: rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01','赵六'),('c03','田七'),('c03','周八'),('c02','李九')])
需求: 对学生按照班级分组展示
代码: rdd.groupByKey().mapValues(list).collect()
结果: [('c01', ['张三', '赵六']), ('c02', ['李四', '王五', '李九']), ('c03', ['田七', '周八'])]
reduceByKey():
- 格式: rdd.reduceByKey(fn)
- 说明: 根据key进行分组,将一个组内的value数据放置到一个列表中,对这个列表基于fn进行聚合计算操作
输入: rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01','赵六'),('c03','田七'),('c03','周八'),('c02','李九')])
需求: 统计每个班级学生人数
代码: rdd.map(lambda tup:(tup[0],1)).reduceByKey(lambda agg,curr:agg+curr).collect()
结果: [('c01', 2), ('c02', 3), ('c03', 2)]
sortByKey()算子:
- 格式:rdd.sortByKey(ascending=True|False)
- 说明: 根据key进行排序操作,默认按照key进行升序排序,如果需要降序,设置 ascending 参数的值为False
输入: rdd = sc.parallelize([(10,2),(15,3),(8,4),(7,4),(2,4),(12,4)])
需求: 根据key进行排序操作,演示升序
代码: rdd.sortByKey().collect()
结果: [(2, 4), (7, 4), (8, 4), (10, 2), (12, 4), (15, 3)]
需求: 根据key进行排序操作,演示降序
代码: rdd.sortByKey(ascending=False).collect()
结果: [(15, 3), (12, 4), (10, 2), (8, 4), (7, 4), (2, 4)]
输入: rdd = sc.parallelize([('a01',2),('A01',3),('a011',2),('a03',2),('a021',2),('a04',2)])
需求: 根据key进行排序操作,演示升序
代码: rdd.sortByKey().collect()
结果: [('A01', 3), ('a01', 2), ('a011', 2), ('a021', 2), ('a03', 2), ('a04', 2)]
总结: 对字符串类型的key进行排序的时候,按照ASCII码表进行排序。大写字母排在小写字母的前面;如果前缀一样,短的排在前面,长的排在后面。
拓展工具: https://tool.ip138.com/
该工具很实用
3、RDD的动作算子
返回值: 要么没有返回值None,或者返回非RDD类型的数据
特点: 动作算子都是立即执行。执行的时候,会将它上游的其他算子一同触发执行
collect() 基础算子:
- 格式: rdd.collect()
- 作用: 收集各个分区的数据,将数据汇总到一个大的列表返回
3.1 KV类型算子
countByKey():
- 格式: rdd.countByKey()
- 说明: 根据key进行分组,统计每个key出现的次数
输入: rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01',' 赵六'),('c03','田七'),('c03','周八'),('c02','李九')])
需求: 统计每个班级学生人数
代码: rdd.countByKey()
结果: defaultdict(<class 'int'>, {'c01': 2, 'c02': 3, 'c03': 2})
countByValue():
- 格式: rdd.countByValue()
- 说明: 统计列表中每每个元素出现次数
输入: rdd = sc.parallelize([1,3,1,2,3])
需求: 统计上述列表中每个元素次数
代码: rdd.countByValue()
结果: defaultdict(<class 'int'>, {1: 2, 3: 2, 2: 1})
3.2 单值类型算子
count() 算子:
- 格式: rdd.count()
- 说明:统计RDD中一共有多少个元素
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 获取一共有多少个元素
代码: rdd.count()
结果: 10
first() 算子:
- 格式: rdd.first()
- 说明: 取RDD中的第一个元素。不会对RDD中的数据排序
输入: rdd = sc.parallelize([3,1,2,4,5,6,7,8,9,10])
需求: 获取第一个元素
代码: rdd.first()
结果: 3
top()算子:
- 格式: top(N,[fn])
- 说明: 对数据集进行倒序排序操作,如果kv(键值对)类型,针对key进行排序,获取前N个元素
- fn: 可以自定义排序,按照谁来排序
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 获取top3元素
代码: rdd.top(3)
结果: [10, 9, 8]
输入: rdd = sc.parallelize([('c01',5),('c02',8),('c04',1),('c03',4)])
需求: 按照班级人数降序排序,取前2个
代码: rdd.top(2,key=lambda tup:tup[1])
结果: [('c02', 8), ('c01', 5)]
需求: 按照班级人数升序排序,取前2个
代码: rdd.top(2,key=lambda tup:-tup[1])
结果: [('c04', 1), ('c03', 4)]
take() 算子:
- 格式: rdd.take(N)
- 说明: 取RDD中的前N元素。不会对RDD中的数据排序
输入: rdd = sc.parallelize([3,1,2,4,5,6,7,8,9,10])
需求: 获取前3个元素
代码: rdd.take(3)
结果: [3, 1, 2]
说明: 返回结果是List列表。必须要传递参数N,而且不能是负数。
takeSample()算子:
- 格式: rdd.takeSample(withReplacement, num,[seed])
- 说明: 返回一个随机抽样的数组
- withReplacement表示指定是否需要补充到指定长度, 以及抽样num个元素,最后也能可选地预先指定一个随机数生成器种子seed
输入: rdd = sc.parallelize(range(0, 2))
需求: 随机抽样4个元素的数据集,补充长度,每次都随机生成不同的结果
代码: rdd.takeSample(True,4)
结果: [0, 1, 0, 1]
需求: 随机抽样4个元素的数据集,不补充长度
代码: rdd.takeSample(False,4)
结果: [1, 0]
需求: 随机抽样4个元素的数据集,补充长度,指定种子1,无论运行多少次都是一样结果
代码: rdd.takeSample(True,4,1)
结果: [1, 1, 1, 0]
foreach() 算子:
- 格式: foreach(fn)
- 作用: 遍历RDD中的元素,对元素根据传入的函数进行自定义的处理
- 遍历: 把元素从容器中一个个取出的过程

输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 对数据进行遍历打印
代码: rdd.foreach(lambda num:print(num))
结果: 每个元素都被打印到控制台
说明:
1- foreach()算子对自定义函数不要求有返回值,另外该算子也没有返回值
2- 因为底层是多线程运行的,因此输出结果分区间可能是乱序
3- 该算子,一般用来对结果数据保存到数据库或者文件中
reduce() 算子:
- 格式: reduce(fn)
- 作用: 根据用户传入的自定义函数,对数据进行聚合操作。
- 和reduceByKey的区别是该算子是Action动作算子;而reduceByKey是Transformation转换算子。
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 统计所有元素之和是多少
代码: rdd.reduce(lambda agg,curr:agg+curr)
结果: 55
4、RDD的重要算子(重点补充)
工作用的比较多,而且比较复杂的一些算子。并不是算子的分类
4.1 基本算子

4.2 分区算子
分区算子:针对整个分区数据进行处理的算子。
mapPartitions和foreachPartition
说明:map和foreach算子都有对应的分区算子,即mapPartitions和foreachPartition
分区算子适用于有反复消耗资源的操作,例如:文件的打开和关闭、数据库的连接和关闭等,能够减少操作的次数。
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
- 代码详解:
演示: map和mapPartitions
需求: 对数字加一
================================map==================================
自定义函数:
def my_add(num):
print(f"传递进来的数据{num}")
return num+1
rdd.map(my_add).collect()
结果:
传递进来的数据4
传递进来的数据5
传递进来的数据6
传递进来的数据1
传递进来的数据2
传递进来的数据3
传递进来的数据7
传递进来的数据8
传递进来的数据9
传递进来的数据10
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
请问: my_add被调用了几次?
回答: 10
思考: 假设咱们要把每条数据都保存到数据库中,效率会高吗?
弊端: 会导致消耗资源的操作反复多次的执行,非常消耗资源
def my_add(num):
# 打开数据库连接
# 将数据保存到数据库
# 关闭数据库连接
print(f"传递进来的数据{num}")
return num+1
=============================mapPartitions===========================
自定义函数:
def my_add(list):
# 打开数据库连接
# 将数据保存到数据库
# 关闭数据库连接
print("输入的参数",list)
new_list = []
for i in list:
new_list.append(i + 1)
return new_list
rdd.mapPartitions(my_add).collect()
结果:
输入的参数 <itertools.chain object at 0x7ff21ae9d940>
输入的参数 <itertools.chain object at 0x7ff21ae9d940>
输入的参数 <itertools.chain object at 0x7ff21ae94e50>
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
演示: foreach和foreachPartition
需求: 遍历打印
==============================foreach================================
自定义函数:
def my_print(num):
print(f"传递进来的数据{num}")
print(num)
rdd.foreach(my_print)
结果:
传递进来的数据1
1
传递进来的数据2
2
传递进来的数据3
3
传递进来的数据4
4
传递进来的数据5
5
传递进来的数据6
6
传递进来的数据7
7
传递进来的数据8
8
传递进来的数据9
9
传递进来的数据10
10
==========================foreachPartition===========================
# 自定义函数:
def my_print(list):
print(f"传递进来的数据{list}")
for i in list:
print(i)
rdd.foreachPartition(my_print)
结果:
传递进来的数据<itertools.chain object at 0x7ff21ae9d2b0>
1
2
3
传递进来的数据<itertools.chain object at 0x7ff21ae9d2b0>
4
5
6
传递进来的数据<itertools.chain object at 0x7ff21ae94a60>
7
8
9
10
- 该小节总结:
1- map和foreach算子都有对应的分区算子,分别是mapPartitions和foreachPartition
2- 分区算子适用于有反复消耗资源的操作,例如:文件的打开和关闭、数据库的连接和关闭等,能够减少操作的次数。
3- 如果没有反复消耗资源的操作,调用两类算子,效果一样
4.3 重分区算子
重分区算子:对RDD的分区重新进行分区操作的算子,也就是改变RDD分区数的算子。
repartition算子:
- 格式:repartition(num)
- 作用:改变RDD分区数。既能够增大RDD分区数,也能够减小RDD分区数。
- 一定会导致发生Shuffle过程。因为通过查看源码,底层就是调用了coalesce,把shuffle固定设置为True
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
需求: 增大为5个分区,查看分区效果
增大分区: rdd.repartition(5).glom().collect()
结果: [[], [1, 2, 3], [7, 8, 9, 10], [4, 5, 6], []]
需求: 减小为2个分区,查看分区效果
减少分区: rdd.repartition(2).glom().collect()
结果: [[1, 2, 3, 7, 8, 9, 10], [4, 5, 6]]
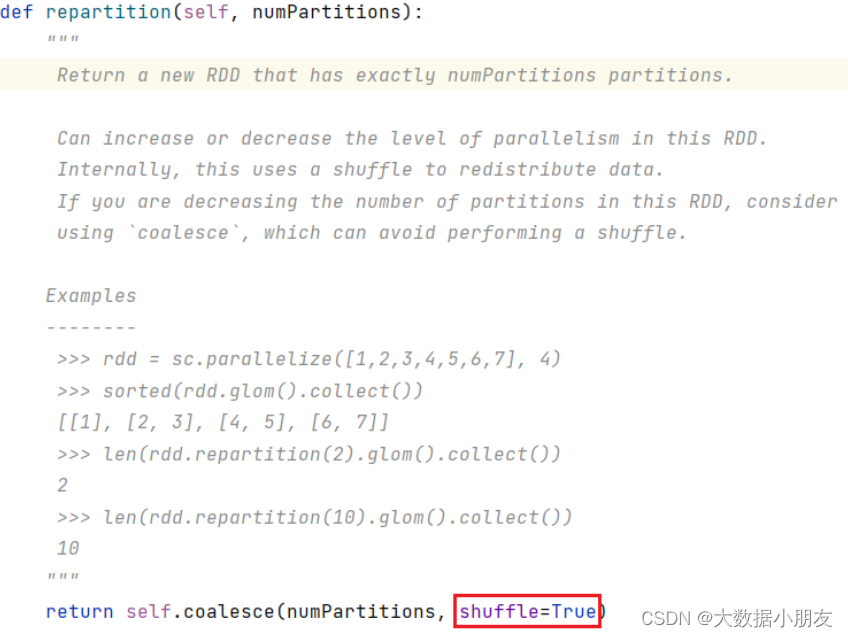
coalesce算子:
- 格式:coalesce(num,shuffle=True|False)
- 作用:改变RDD分区数
- 注意: 默认只能减小RDD分区数,不能增大! 且减小过程中默认不会发生Shuffle过程!
- 注意: 如果想增大分区,就需要将参数shuffle设置为True,那就一定会导致Shuffle过程。
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
需求: 减小为2个分区,查看分区效果
减少分区: rdd.coalesce(2).glom().collect()
结果: [[1, 2, 3], [4, 5, 6, 7, 8, 9, 10]]
需求: 增大为5个分区,查看分区效果
增大分区: rdd.coalesce(5).glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
需求: 将shuffle设置为True,再增大分区
代码: rdd.coalesce(5,shuffle=True).glom().collect()
结果: [[], [1, 2, 3], [7, 8, 9, 10], [4, 5, 6], []]
需求: 将shuffle设置为True,再减小分区
代码: rdd.coalesce(2,shuffle=True).glom().collect()
结果: [[1, 2, 3, 7, 8, 9, 10], [4, 5, 6]]

- repartition 和 coalesce总结:
1- 这两个算子都是用来改变RDD的分区数
2- repartition 既能够增大RDD分区数,也能够减小RDD分区数。但是都会导致发生Shuffle过程。
3- coalesce默认只能减小RDD分区数,不能增大,且减小过程中默认不会发生Shuffle过程。
但是如果想增大分区,需要将参数shuffle设置为True,但是会导致Shuffle过程。
4- repartition 底层实际上是调用了coalesce算子,并且将shuffle参数设置为了True
partitionBy算子:
- 格式:partitionBy(num,[fn])
- 作用:该算子主要是用来改变key-value键值对数据类型RDD的分区数的。num表示要设置的分区数;fn参数是可选,用来让用户自定义分区规则。
注意:
默认情况下,根据key进行Hash取模分区。
如果对默认分区规则不满意,可以传递参数fn来自定义分区规则。
但是自定义分区规则函数需要满足两个条件,
条件一:分区编号的数据类型需要是int类型;
条件二:传递给自定义分区函数的参数是key
输入: rdd = sc.parallelize([(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)],5)
查看分区情况: rdd.glom().collect()
结果: [[(1, 1), (2, 2)], [(3, 3), (4, 4)], [(5, 5), (6, 6)], [(7, 7), (8, 8)], [(9, 9), (10, 10)]]
需求: 增大分区,尝试分为20个分区,观察效果
代码: rdd.partitionBy(20).glom().collect()
结果: [[], [(1, 1)], [(2, 2)], [(3, 3)], [(4, 4)], [(5, 5)], [(6, 6)], [(7, 7)], [(8, 8)], [(9, 9)], [(10, 10)], [], [], [], [], [], [], [], [], []]
需求: 减少分区,尝试分为2个分区,观察效果
代码: rdd.partitionBy(2).glom().collect()
结果: [[(2, 2), (4, 4), (6, 6), (8, 8), (10, 10)], [(1, 1), (3, 3), (5, 5), (7, 7), (9, 9)]]
需求: 将 key>5 放置在一个分区,剩余放置到另一个分区
代码: rdd.partitionBy(2,partitionFunc=lambda key:0 if key>5 else 1).glom().collect()
结果: [[(6, 6), (7, 7), (8, 8), (9, 9), (10, 10)], [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]]
注意: 分区编号的数据类型需要是int类型
4.4 聚合算子
聚合算子: 对数据集中的数据进行聚合操作的算子
4.4.1 单值类型的聚合算子
- reduce(fn1):根据传入函数对数据进行聚合处理
- fold(defaultAgg,fn1):根据传入函数对数据进行聚合处理,同时支持给agg设置初始值
- aggregate(defaultAgg, fn1, fn2):根据传入函数对数据进行聚合处理。defaultAgg设置agg的初始值,fn1对各个分区内的数据进行聚合计算,fn2 负责将各个分区的聚合结果进行汇总聚合
注意:
reduce、fold、aggregate算子都能实现聚合操作。reduce的底层是fold,fold底层是aggregate。
在工作中,如果能够通过reduce实现的,就优先选择reduce;否则选择fold,实在不行就选择aggregate
输入:rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
需求: 求和计算, 求所有数据之和
================================reduce================================
代码:
def my_sum(agg,curr):
return agg+curr
rdd.reduce(my_sum)
结果: 55
================================fold================================
代码:
def my_sum(agg,curr):
return agg+curr
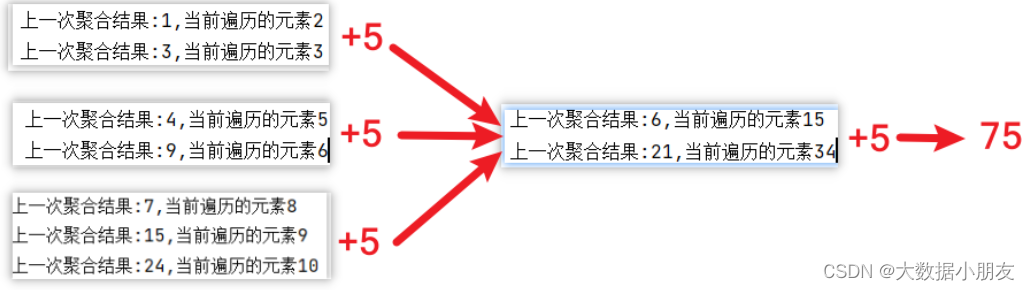
rdd.fold(5,my_sum)
结果: 75
================================aggregate================================
代码:
def my_sum_1(agg,curr):
return agg+curr
def my_sum_2(agg,curr):
return agg+curr
rdd.aggregate(5,my_sum_1,my_sum_2)
结果: 75
- reduce底层:

- fold和aggregate:
4.4.2 KV类型的聚合算子
- reduceByKey(fn1)
- foldByKey(defaultAgg, fn1)
- aggregateByKey(defaultAgg, fn1, fn2);
以上三个与单值是一样的,只是在单值的基础上加了分组的操作而已,针对每个分组内的数据进行聚合而已。另外有一个:groupByKey() 仅分组,不聚合统计
问题:**groupByKey() + 聚合操作** 和 **reduceByKey()** 都可以完成分组聚合统计,谁的效率更高一些?
答: reduceByKey(),因为底层会进行局部的聚合操作,会减小后续处理的数据量
- reduceByKey:
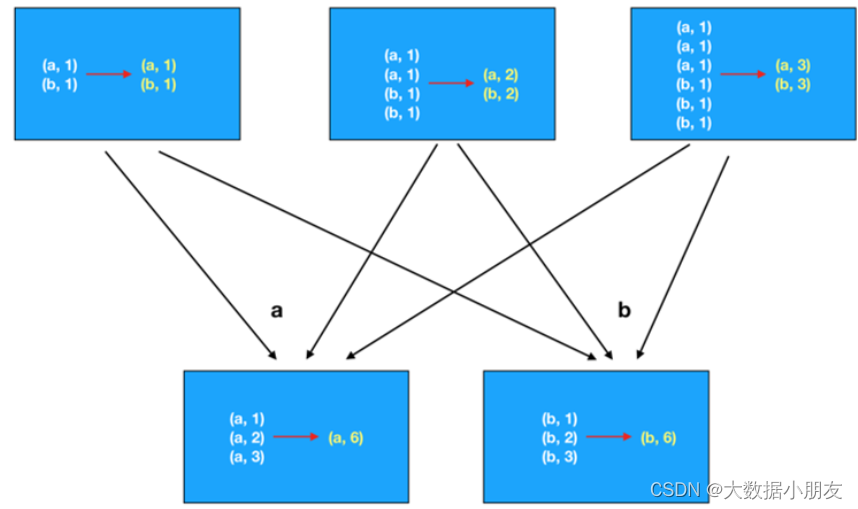
- groupByKey:

4.5 关联算子
关联算子: 主要是针对kv类型的数据,根据key进行关联操作的算子
相关的算子:
- join:实现两个RDD的join关联操作
- leftOuterJoin:实现两个RDD的左关联操作
- rightOuterJoin:实现两个RDD的右关联操作
- fullOuterJoin:实现两个RDD的满外(全外)关联操作
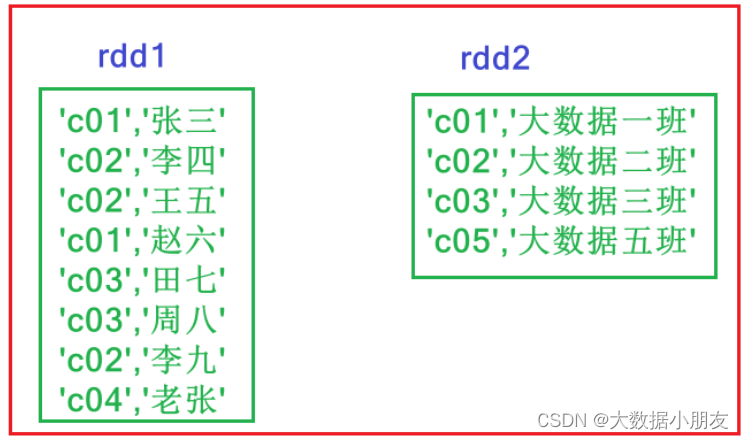
输入:
rdd1 = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01','赵六'),('c03','田七'),('c03','周八'),('c02','李九'),('c04','老张')])
rdd2 = sc.parallelize([('c01','大数据一班'),('c02','大数据二班'),('c03','大数据三班'),('c05','大数据五班')])
================================join================================
代码: rdd1.join(rdd2).collect()
结果:
[
('c01', ('张三', '大数据一班')),
('c01', ('赵六', '大数据一班')),
('c02', ('李四', '大数据二班')),
('c02', ('王五', '大数据二班')),
('c02', ('李九', '大数据二班')),
('c03', ('田七', '大数据三班')),
('c03', ('周八', '大数据三班'))
]
================================leftOuterJoin================================
代码: rdd1.leftOuterJoin(rdd2).collect()
结果:
[
('c04', ('老张', None)),
('c01', ('张三', '大数据一班')),
('c01', ('赵六', '大数据一班')),
('c02', ('李四', '大数据二班')),
('c02', ('王五', '大数据二班')),
('c02', ('李九', '大数据二班')),
('c03', ('田七', '大数据三班')),
('c03', ('周八', '大数据三班'))
]
================================rightOuterJoin================================
代码: rdd1.rightOuterJoin(rdd2).collect()
结果:
[
('c05', (None, '大数据五班')),
('c01', ('张三', '大数据一班')),
('c01', ('赵六', '大数据一班')),
('c02', ('李四', '大数据二班')),
('c02', ('王五', '大数据二班')),
('c02', ('李九', '大数据二班')),
('c03', ('田七', '大数据三班')),
('c03', ('周八', '大数据三班'))
]
================================fullOuterJoin================================
代码: rdd1.fullOuterJoin(rdd2).collect()
结果:
[
('c04', ('老张', None)),
('c05', (None, '大数据五班')),
('c01', ('张三', '大数据一班')),
('c01', ('赵六', '大数据一班')),
('c02', ('李四', '大数据二班')),
('c02', ('王五', '大数据二班')),
('c02', ('李九', '大数据二班')),
('c03', ('田七', '大数据三班')),
('c03', ('周八', '大数据三班'))
]
四、spark算子相关面试题(重点)
1.如何理解RDD,以及RDD的分类
RDD:英文全称Resilient Distributed Dataset,叫做弹性分布式数据集,代表一个不可变、可分区、里面的元素可并行计算的分布式的抽象的数据集合。尽管RDD本身并不直接分类为不同的类型,但我们可以根据它们的创建方式和用途来间接地讨论它们的“分类”或“种类”。以下是根据创建方式和用途对RDD的一些间接“分类”:
- 转换型RDD: 通过在一个现有的RDD上应用转换操作(如map(), filter(), flatMap(), reduceByKey(), join(), 等)创建的RDD。转换操作是惰性的,这意味着它们不会立即计算数据,而是会创建一个新的RDD,这个新的RDD包含了如何计算所需数据的描述。
- 动作型RDD: 通过在一个RDD上应用动作操作(如collect(), count(), reduce(), saveAsTextFile(), 等)来触发实际计算的RDD。动作操作会触发Spark作业的执行,该作业会计算从原始数据到最终结果的整个RDD依赖链。
- 宽依赖型RDD: 当一个RDD的分区中的数据依赖于父RDD的多个分区时,该RDD具有宽依赖(例如,reduceByKey()或groupByKey()操作)。宽依赖的RDD在计算时通常需要进行shuffle操作。
- 窄依赖型RDD: 当一个RDD的分区中的数据仅依赖于父RDD的一个分区时,该RDD具有窄依赖(例如,map(), filter(), flatMap()操作)。窄依赖的RDD在计算时通常更加高效,因为它们不需要进行shuffle操作。
- 持久化RDD: 通过调用RDD的persist()或cache()方法创建的RDD。持久化(或缓存)的RDD会将其内容保存在集群的内存中,以便在后续的操作中重复使用,从而提高计算效率。
- 检查点RDD: 通过调用RDD的checkpoint()方法创建的RDD。检查点是一种将RDD的内容写入到持久化存储(如HDFS)中的机制,以便在作业失败时可以从该检查点恢复,而不是从头开始重新计算整个RDD依赖链。
- 分区型RDD: 根据数据的特定分区策略(如哈希分区、范围分区等)创建的RDD。分区策略决定了数据在集群中的分布方式,这对于优化性能和确保数据的局部性非常重要。
- 补充: 这些“分类”是基于RDD的创建方式和用途的,而不是RDD本身的直接属性。在Spark的上下文中,我们通常不直接按类型来区分RDD,而是根据它们的转换和动作操作以及它们之间的依赖关系来理解和优化Spark作业。
2.简单介绍下RDD的五大特性
1、(必须的)RDD是由一系列分区组成的
2、(必须的)对RDD做计算,相当于对RDD的每个分区做计算
3、(必须的)RDD之间存在着依赖关系(宽依赖和窄依赖)
4、(可选的)对于KV类型的RDD,默认操作的是k,当然我们可以进行自定义分区方案
5、(可选的)移动数据不如移动计算,让计算程序离数据越近越好
3.简单介绍下RDD的五大特点
1、分区:RDD逻辑上是分区的,仅仅是定义分区的规则,并不是直接对数据进行分区操作,因为RDD本身不存储数据。
2、只读:RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
3、依赖:RDD之间存在着依赖关系(宽依赖和窄依赖)
4、cache缓存:如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,后续每次直接从缓存获取即可
5、checkpoint检查点:与缓存类似的,都是可以将中间某一个RDD的结果保存起来,只不过checkpoint支持真正持久化保存
4.开发中如何小文件处理的方案
本章 :第二节第3部分
常规处理小文件的办法:
1- 大数据框架提供的现有的工具或者命令
1.1- 合并hdfs中多个小文件到linux本地: hadoop fs -getmerge 小文件路径 linux输出路径/文件名.后缀名
举例: [root@node1 ~]# hadoop fs -getmerge /data/*.txt /merged_file.txt
1.2- 归档hdfs中多个小文件到hdfs: hadoop archive -archiveName 归档名.har -p 小文件路径 hdfs输出路径
举例: [root@node1 ~]# hadoop archive -archiveName merged_file.har -p /data/ /
2- 可以通过编写自定义的代码,将小文件读取进来,在代码中输出的时候,输出形成大的文件
5.RDD分区数量如何确定
本章 :第二节第4部分
1- RDD的分区数量,一般设置为机器CPU核数的2-3倍。为了充分利用服务器的硬件资源
2- RDD的分区数据量受到多个因素的影响,例如:机器CPU的核数、调用的算子、算子中参数的设置、集群的类型等。RDD具体有多少个分区,直接通过getNumPartitions查看
3- 当初始化SparkContext对象的时候,其实就确定了一个参数spark.default.parallelism,默认为CPU的核数。如果是本地集群,就取决于local[num]中设置的数字大小;如果是集群,默认至少有2个分区
4- 通过parallelize来构建RDD,如果没有指定分区数,默认就取spark.default.parallelism参数值;如果指定了分区数,也就是numSlices参数,那么numSlices的优先级会更高一些,最终RDD的分区数取该参数的值。
5- 通过textFile来构建RDD
5.1- 首先确认defaultMinPartition参数的值。该参数的值,如果没有指定textFile的minPartition参数,那么就根据公式min(spark.default.parallelism,2);如果有指定textFile的minPartition参数,那么就取设置的值
5.2- 再根据读取文件所在的文件系统的不同,来决定最终RDD的分区数:
5.2.1- 本地文件系统: RDD分区数 = max(本地文件分片数,defaultMinPartition)
5.2.2- HDFS文件系统: RDD分区数 = max(文件block块的数量,defaultMinPartition)
6.请说出10个常用的RDD算子以及对应的功能
本章:第三节第4部分(重点补充),可根据自己需求,选择性记忆
1:分区算子:mapPartitions和foreachPartition
*说明:map和foreach算子都有对应的分区算子,即mapPartitions和foreachPartition
分区算子适用于有反复消耗资源的操作,例如:文件的打开和关闭、数据库的连接和关闭等,能够减少操作的次数。
*如果没有反复消耗资源的操作,调用两类算子,效果一样
2:重分区算子:对RDD的分区重新进行分区操作的算子,也就是改变RDD分区数的算子
repartition算子:
* 作用:改变RDD分区数。既能够增大RDD分区数,也能够减小RDD分区数。
* 一定会导致发生Shuffle过程。因为通过查看源码,底层就是调用了coalesce,把shuffle固定设置为True
3:聚合算子: 对数据集中的数据进行聚合操作的算子
- reduce(fn1):根据传入函数对数据进行聚合处理
- fold(defaultAgg,fn1):根据传入函数对数据进行聚合处理,同时支持给agg设置初始值
- aggregate(defaultAgg, fn1, fn2):根据传入函数对数据进行聚合处理。defaultAgg设置agg的初始值,fn1对各个分区内的数据进行聚合计算,fn2 负责将各个分区的聚合结果进行汇总聚合

版权归原作者 大数据小朋友 所有, 如有侵权,请联系我们删除。