
一共分三步:
第一:下载对应的Google浏览器,对应的Google驱动
第二:配置环境变量
第三:基本操作指令及提升方向
那么从第一步开始
1.选择下载对应的Google浏览机版本
https://www.slimjet.com/chrome/google-chrome-old-version.php
我选的是103.0.5060.53版本

下载完放入文件夹--养成好习惯
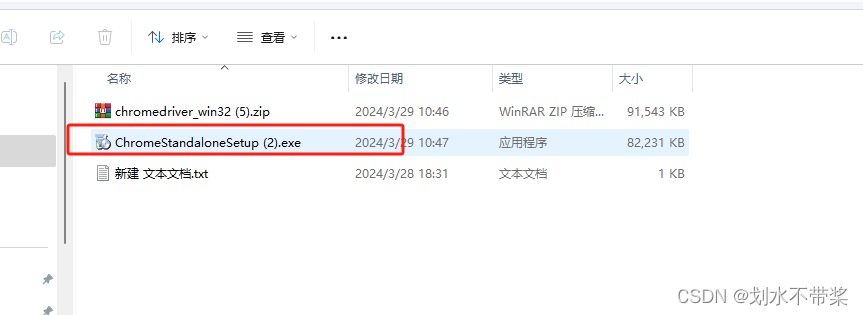
下载对应的Google驱动
ChromeDriver - WebDriver for Chrome - Downloads
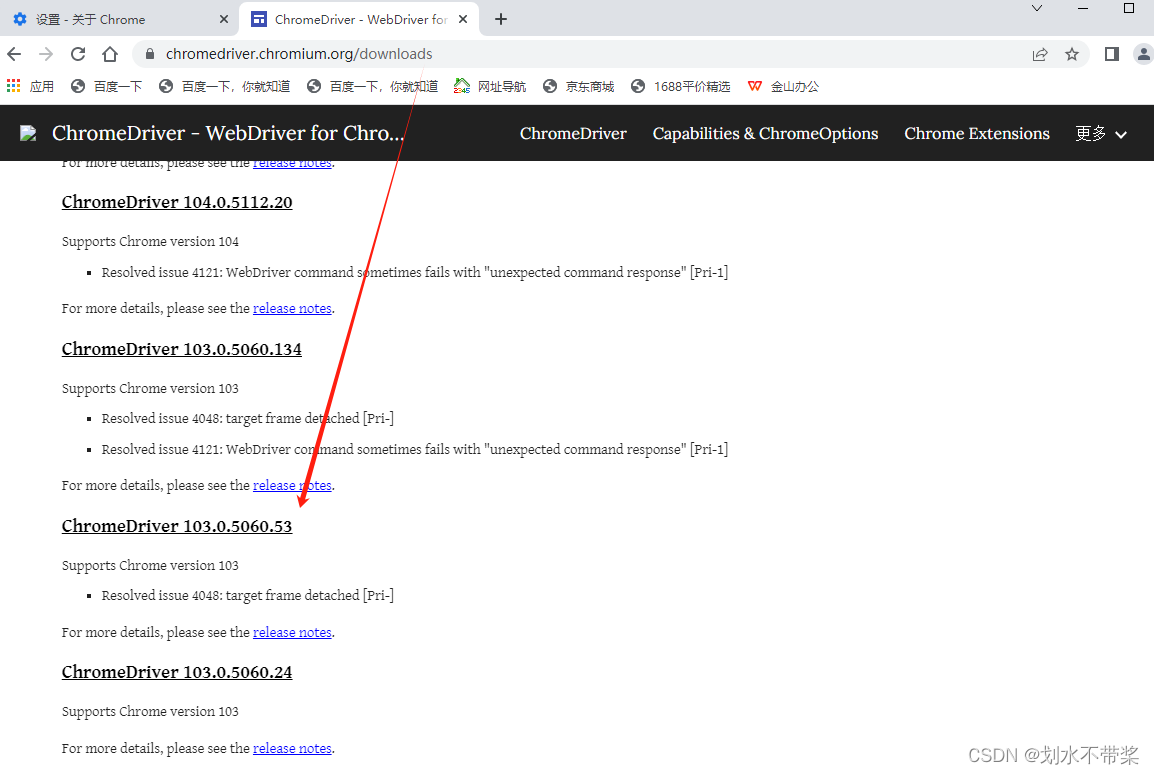
下载完成放入文件夹就完成了第一阶段
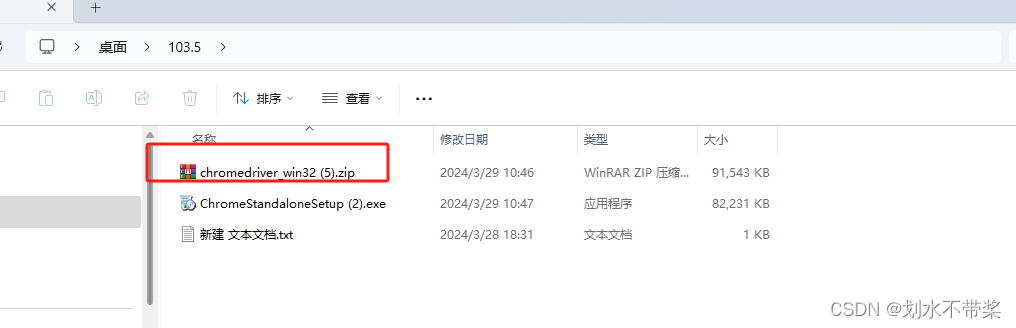
重点:做笔记
安装好Google浏览器然后解压Google驱动:
把解压后的Google驱动和Google.exe放在同目录下:
我的是 C:\Program Files (x86)\Google\Chrome\Application (点击桌面Google头标查看文件所在位置)
如图:
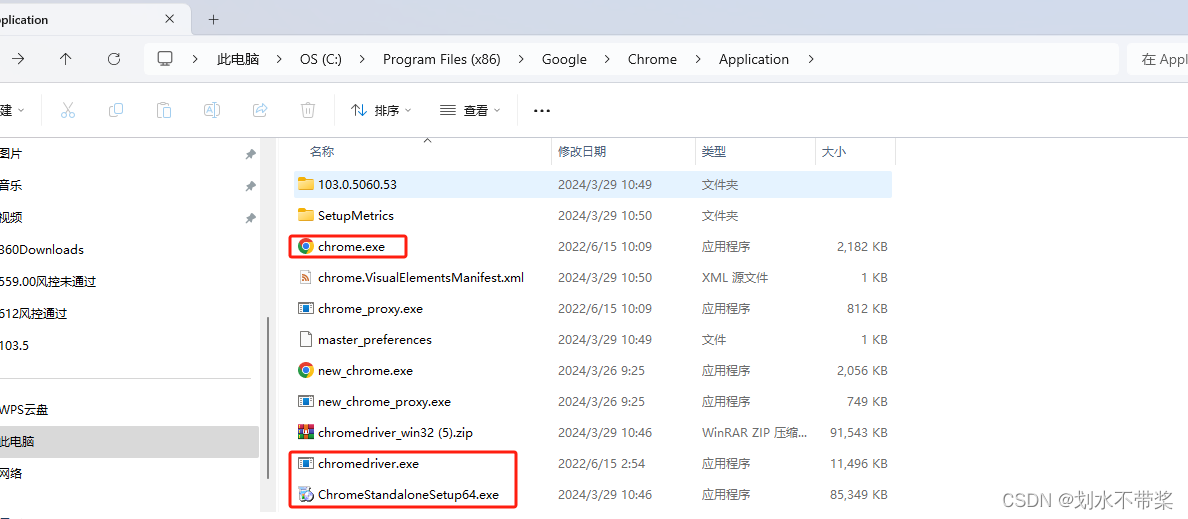
2.开始配置环境变量
第一步:把下载好的Google安装,配置在Aaitest的路径里面

第二步:设置--环境变量--path里面配置上对应google 驱动的环境变量就完成了
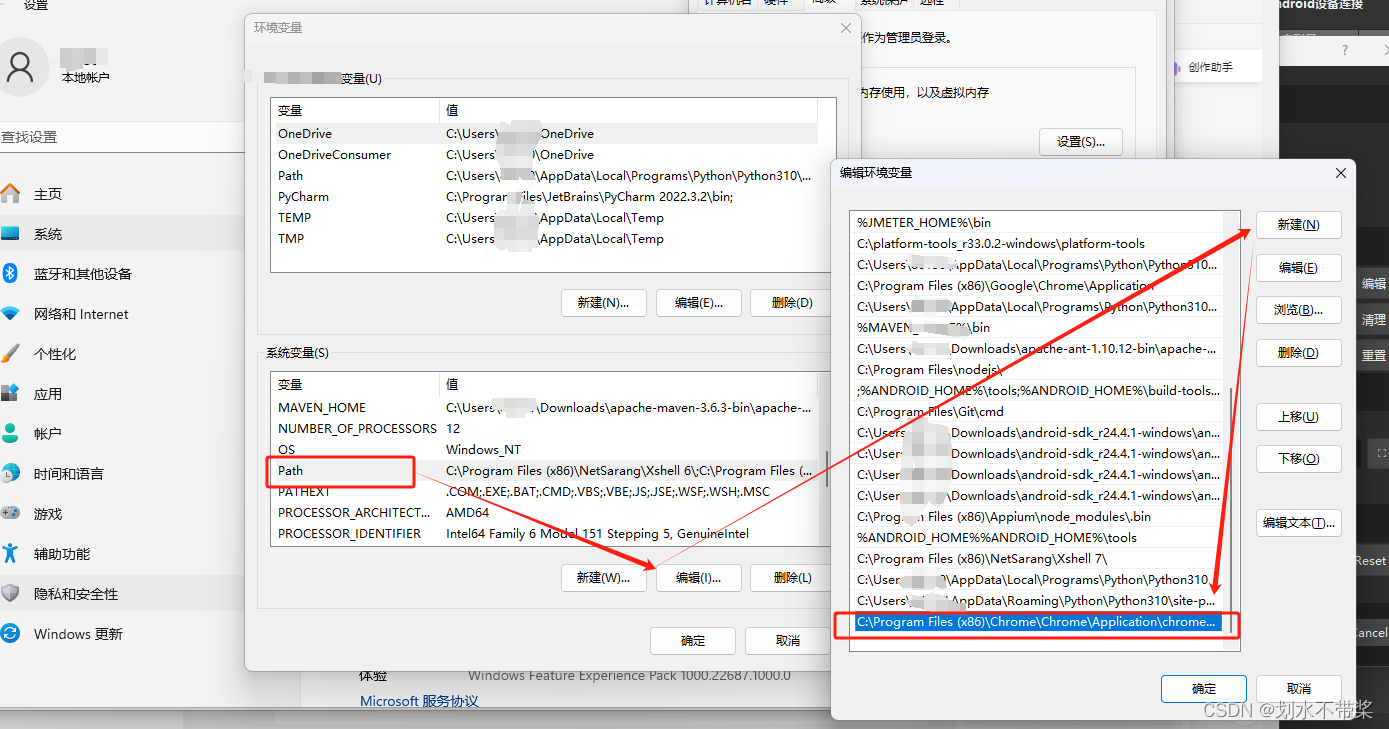
第三步:
基本实践
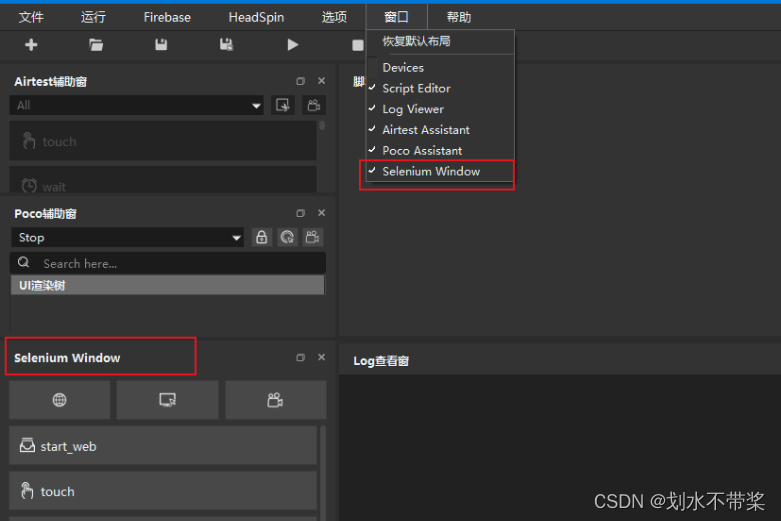
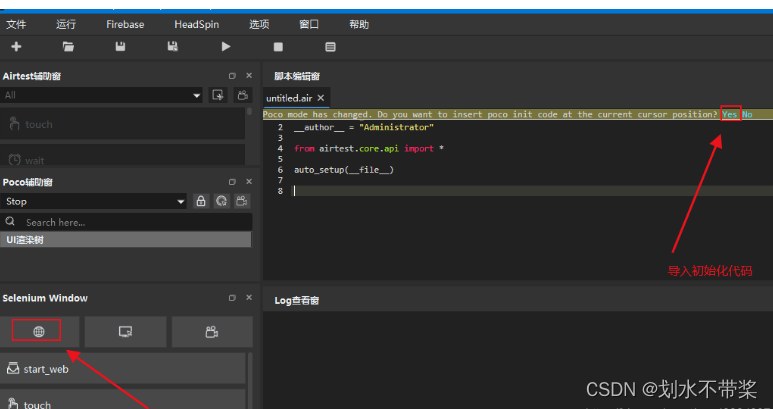

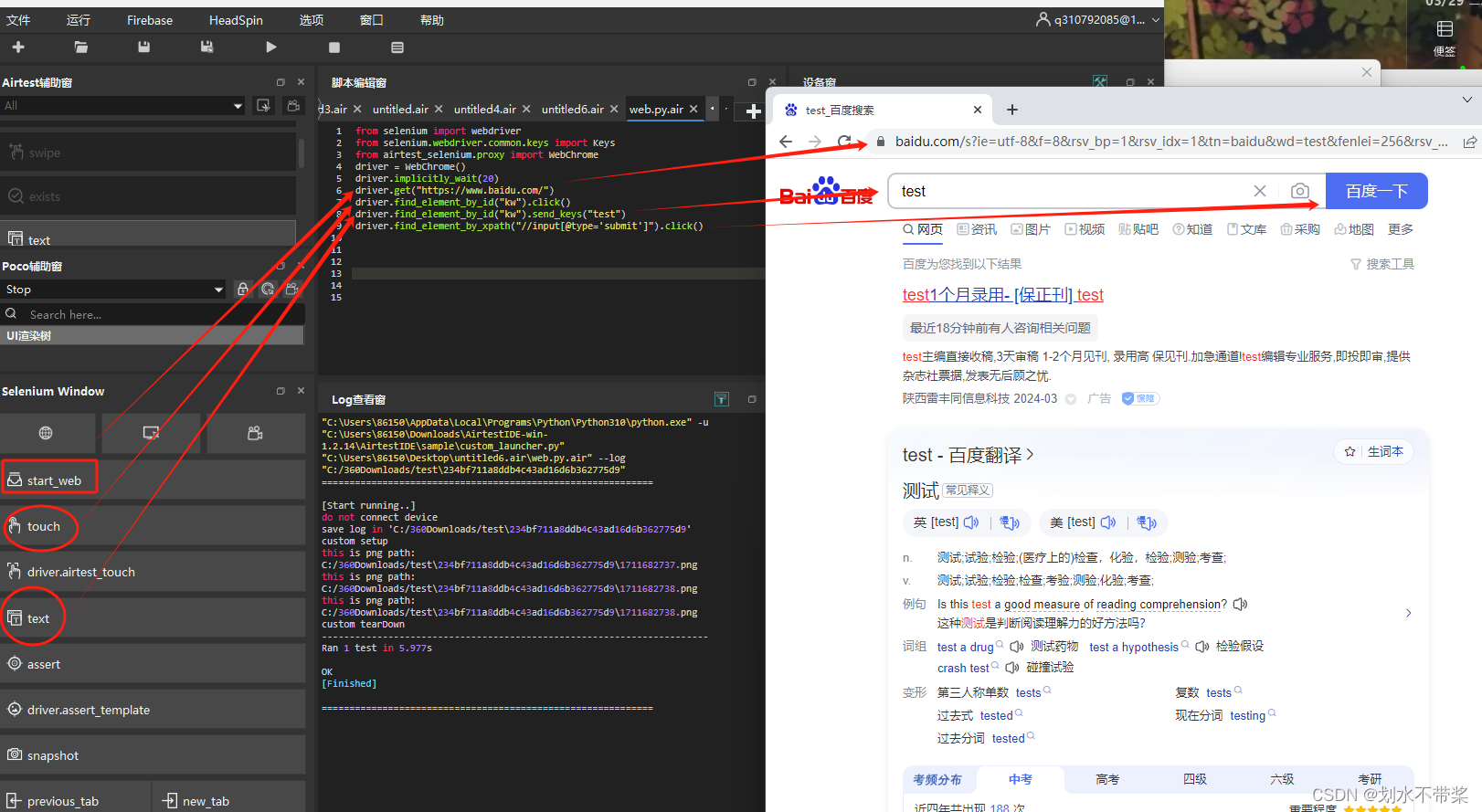
实例代码如下
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from airtest_selenium.proxy import WebChrome
driver = WebChrome()
driver.implicitly_wait(20)
driver.get("https://www.baidu.com/")
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").send_keys("test")
driver.find_element_by_xpath("//input[@type='submit']").click()
点击运行就有对应的结果日志

进阶路线链接
Airtest-Selenium实操小课③:下载可爱猫猫图片-CSDN博客
源码如下:
# -*- encoding=utf8 -*-
from airtest.core.api import *
# 引入selenium的webdriver模块
from airtest_selenium.proxy import WebChrome
import requests
from selenium.webdriver.common.by import By
def download_image(url, save_path): #下载图片
response = requests.get(url, stream=True)
if response.status_code == 200: #网页可以正常访问
with open(save_path, 'wb') as file:
for chunk in response.iter_content(1024):
file.write(chunk)
print("图片下载完成!")
else:
print("下载失败。")
def start_selenium():
# 创建一个实例,代码运行到这里,会打开一个chrome浏览器
driver = WebChrome()
driver.implicitly_wait(20)
driver.get("https://www.baidu.com/")
# 输入搜索关键词并提交搜索
search_box = driver.find_element_by_name('wd')
search_box.send_keys('可爱猫猫图片')
search_box.submit()
# 定位搜索结果中的图片元素
image_elements = driver.find_elements(By.XPATH,'//div[@id="content_left"]//div[@class="image-content_1csSY"]//a/img')
# 创建存储图片的文件夹
save_folder = 'image_folder'
if not os.path.exists(save_folder):
os.makedirs(save_folder)
index = 0
# 循环保存图片
for i in image_elements:
image_url = i.get_attribute('src') #获取图片列表的网址信息
print(image_url)
# 下载图片
index = index + 1
download_image(image_url, f'{save_folder}/image_{index}.jpg')
if __name__ == "__main__":
start_selenium()
爬虫结果如下

本文转载自: https://blog.csdn.net/weixin_43886221/article/details/137138484
版权归原作者 划水不带桨 所有, 如有侵权,请联系我们删除。
版权归原作者 划水不带桨 所有, 如有侵权,请联系我们删除。