
一、语法
Case具有两种格式。简单Case函数和Case搜索函数。
简单Case函数格式:
CASE 列名
WHEN 条件值1 THEN 选项1
WHEN 条件值2 THEN 选项2
……
ELSE 默认值
END
Case搜索函数:
CASE
WHEN 条件1 THEN 选项1
WHEN 条件2 THEN 选项2
……
ELSE 默认值
END
二、case when应用场景
case when与子查询性能比较及优化。
为了方便说明,我们先创建表,并造点数据。
CREATETABLE`table_a`(`id`INTNOTNULLAUTO_INCREMENT,`country`VARCHAR(50)NOTNULL,`sex`CHAR(2)notnull,`population`intNOTNULL,PRIMARYKEY(`id`));insertinto table_a values(null,"中国","男",10);insertinto table_a values(null,"中国","女",5);insertinto table_a values(null,"美国","男",2);insertinto table_a values(null,"美国","女",4);insertinto table_a values(null,"加拿大","男",4);insertinto table_a values(null,"加拿大","女",4);insertinto table_a values(null,"英国","男",6);insertinto table_a values(null,"英国","女",6);insertinto table_a values(null,"法国","男",2);insertinto table_a values(null,"法国","女",2);insertinto table_a values(null,"日本","男",7);insertinto table_a values(null,"日本","女",7);insertinto table_a values(null,"德国","男",2);insertinto table_a values(null,"墨西哥","男",7);insertinto table_a values(null,"印度","男",1);
2.1 案例一
统计亚洲和北美洲的人口数量,要求结果如下: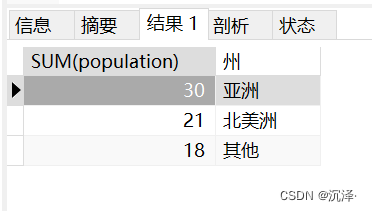
若第一时间没有想到case when,我们可能会写出下面的sql:
SELECTsum(population)from Table_A where country in('中国','印度','日本')UNIONSELECTsum(population)from Table_A where country in('美国','加拿大','墨西哥')UNIONSELECTsum(population)from Table_A where country notin('中国','印度','日本','美国','加拿大','墨西哥');
运行结果: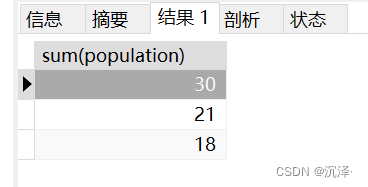
这个sql的性能效率比较低,对同一个数据表查询了三次,也无法获得州的那一列。
使用case when进行改造,如下:
SELECTSUM(population)FROM Table_A
GROUPBYCASE country
WHEN'中国'THEN'亚洲'WHEN'印度'THEN'亚洲'WHEN'日本'THEN'亚洲'WHEN'美国'THEN'北美洲'WHEN'加拿大'THEN'北美洲'WHEN'墨西哥'THEN'北美洲'ELSE'其他'END;
运行结果: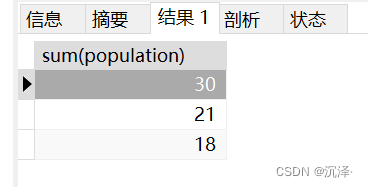
使用了case when的sql语句明显效率高一些,因为它仅查找了一次表而已,若想获得州的那一列,只需改写如下:
SELECTSUM(population),(CASE country WHEN'中国'THEN'亚洲'WHEN'印度'THEN'亚洲'WHEN'日本'THEN'亚洲'WHEN'美国'THEN'北美洲'WHEN'加拿大'THEN'北美洲'WHEN'墨西哥'THEN'北美洲'ELSE'其他'END)as 州
FROM Table_A
GROUPBYCASE country
WHEN'中国'THEN'亚洲'WHEN'印度'THEN'亚洲'WHEN'日本'THEN'亚洲'WHEN'美国'THEN'北美洲'WHEN'加拿大'THEN'北美洲'WHEN'墨西哥'THEN'北美洲'ELSE'其他'END;
运行结果: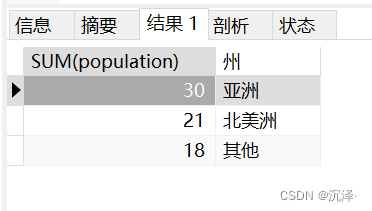
2.2 案例二
统计每个国家的男生人数和女生人数,要求结果如下: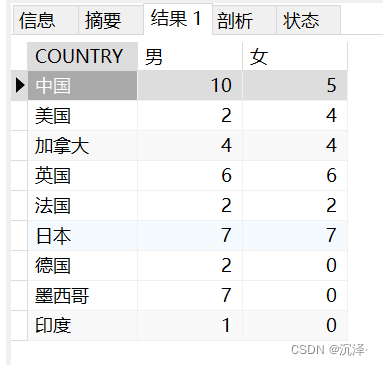
同样的,不使用case when的写法如下:
SELECT
a.country,(SELECTSUM( a1.population )FROM
table_a a1
WHERE
a1.country = a.country
AND a1.sex ='男') 男,(SELECTSUM( a1.population )FROM
table_a a1
WHERE
a1.country = a.country
AND a1.sex ='女') 女
FROM
table_a a
GROUPBY
a.country;
执行结果: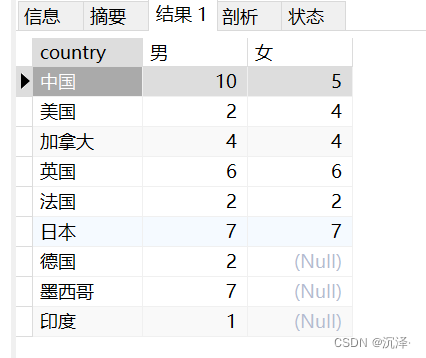
使用case when进行优化:
SELECT COUNTRY,SUM(CASE SEX WHEN'男'THEN population ELSE0END)AS'男',SUM(CASE SEX WHEN'女'THEN population ELSE0END)AS'女'FROM table_a GROUPBY COUNTRY;
执行结果: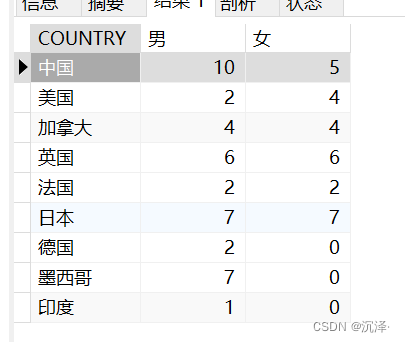
两者对比,显然的case when的效率既简洁,效率也高。
2.3 案例三
上述两个案例也许不够贴近日常的工作内容,下面举个现实工作遇到的案例。
建表sql如下:
-- 货架表CREATETABLE`shelves`(`shelves_id`INTNOTNULLAUTO_INCREMENT,-- 货架id`shelves_num`VARCHAR(50)NOTNULLUNIQUE,-- 货架号`shelves_area`VARCHAR(50)NOTNULL,--货架区域PRIMARYKEY(`shelves_id`));-- 物品表CREATETABLE`goods`(`goods_id`INTNOTNULLAUTO_INCREMENT,-- 物品id`goods_name`VARCHAR(50)NOTNULLUNIQUE,-- 物品名称`goods_type`VARCHAR(20)NOTNULL,-- 物品类型`goods_quantity`intNOTNULL,-- 物品数量`goods_createTime`DATETIMENULLDEFAULTNULL,-- 创建时间`goods_expiryTime`DATETIMENULLDEFAULTNULL,-- 过期时间`goods_shelvesId`INTNULLDEFAULTNULL,-- 货架idPRIMARYKEY(`goods_id`));
需求说明:统计每个货架上的物品数量,要求统计结果如下
使用子查询的写法:
SELECT
shelves_area shelvesArea,
shelves_num shelvesNum,COUNT(DISTINCT goods_type ) goodsTypeSum,COUNT( goods_id ) goodsSum,(SELECTCOUNT(*)FROM
goods
WHERE
goods_expiryTime <NOW()AND goods_shelvesId = shelves_id ) isNotExpiry,(SELECTCOUNT(*)FROM
goods
WHERE
goods_expiryTime >NOW()AND goods_shelvesId = shelves_id) isExpiry
FROM
shelves
LEFTJOIN goods ON shelves_id = goods_shelvesId
GROUPBY shelves_id;
使用case when的写法:
SELECT
shelves_area shelvesArea,
shelves_num shelvesNum,COUNT(DISTINCT goods_type ) goodsTypeSum,COUNT( goods_id ) goodsSum,SUM(CASEWHEN(shelves_id = goods_shelvesId AND goods_expiryTime <NOW())THEN1ELSE0END) isNotExpiry,SUM(CASEWHEN(shelves_id = goods_shelvesId AND goods_expiryTime >NOW())THEN1ELSE0END) isExpiry
FROM
shelves
LEFTJOIN goods ON shelves_id = goods_shelvesId
GROUPBY shelves_id;
两个不同写法的运行结果是一样的,但是性能效率上case when 显然比子查询的高一些。
运行结果如下(本人未造相关测试数据):
三、扩展
3.1 根据条件有选择的UPDATE
例,有如下更新条件
1.工资5000以上的职员,工资减少10%
2.工资在2000到4600之间的职员,工资增加15%
很容易考虑的是选择执行两次UPDATE语句,如下所示
--条件1
UPDATE Personnel SET salary = salary * 0.9 WHERE salary >= 5000;
--条件2
UPDATE Personnel SET salary = salary * 1.15
WHERE salary >= 2000 AND salary < 4600;
但是事情没有想象得那么简单,假设有个人工资5000块。首先,按照条件1,工资减少10%,变成工资4500。接下来运行第二个SQL时候,因为这个人的工资是4500在2000到4600的范围之内,需增加15%,最后这个人的工资结果是5175,不但没有减少,反而增加了。如果要是反过来执行,那么工资4600的人相反会变成减少工资。暂且不管这个规章是多么荒诞,如果想要一个SQL 语句实现这个功能的话,我们需要用到Case函数。代码如下:
UPDATE Personnel SET salary =
CASE WHEN salary >= 5000 THEN salary * 0.9
WHEN salary >= 2000 AND salary < 4600 THEN salary * 1.15
ELSE salary
END;
这里要注意一点,最后一行的ELSE salary是必需的,要是没有这行,不符合这两个条件的人的工资将会被写成NUll,那可就大事不妙了。在Case函数中Else部分的默认值是NULL,这点是需要注意的地方。
这种方法还可以在很多地方使用,比如说变更主键这种累活。
一般情况下,要想把两条数据的Primary key,a和b交换,需要经过临时存储,拷贝,读回数据的三个过程,要是使用Case函数的话,一切都变得简单多了。
p_key col_1 col_2
a 1 张三
b 2 李四
c 3 王五
假设有如上数据,需要把主键a和b相互交换。用Case函数来实现的话,代码如下
UPDATE SomeTable SET p_key =
CASE WHEN p_key = 'a' THEN 'b'
WHEN p_key = 'b' THEN 'a'
ELSE p_key
END
WHERE p_key IN('a', 'b');
四、参考来源
版权归原作者 沉泽· 所有, 如有侵权,请联系我们删除。