
人人都能看懂的Spring原理,绝对不会懵逼
为什么要使用Spring?
其实回答这个问题,可以反过来思考,能不能不使用Spring,不使用Spring会怎么样?
如果只是写些小Demo代码,或者开发一个小工具,那真的没必要使用Spring。
但如果是公司级的项目或系统,里面的代码量是非常庞大的,工程里面会有很多的类,很多的模块,系统的运行会创建很多对象,而对象与对象之间又有错综复杂的依赖关系。在没有Spring的管理下,这些对象的创建,依赖关系的维护,都需要通过硬编码进行管理,那么久而久之代码就会变得非常的难以维护,类与类之间,模块与模块之间的耦合度会非常的高,一个小改动,就有可能影响很多地方。
其实不使用Spring也不是不可以,很多开源框架也没有依赖Spring进行开发,但是它们也在进行版本的迭代和扩展,那是因为它们使用了各种设计模式优化了它们代码的设计,使其变得更好维护和扩展,或者可以说是不得不使用设计模式去优化,因为不这么做的话,它们的项目也会慢慢的变得无法再继续维护和扩展。
而我们基本上都是做业务开发的,都是以实现功能为主,功能可用基本上就不会再想着去优化,所以如果不使用Spring,那么10个项目可能就是10座祖传屎山。
其实问题主要就是以下两点:
- 所有需要用到的对象,都需要手动创建,这些都是硬编码
- 对象与对象间的依赖关系,需要人为管理,对象的属性需要手动赋值,一个对象里面依赖到另外10个对象,那连带的要创建这10个对象
使用Spring,就是为了降低类与类之间,模块与模块之间的耦合度,使得代码更易于维护。
Spring的核心功能,就是管理对象的生命周期,特别是对象的创建,以及对象依赖关系的管理,也就是所谓的IOC(控制反转)和DI(依赖注入)。而其他的功能(例如AOP、事务)都相当于是扩展功能。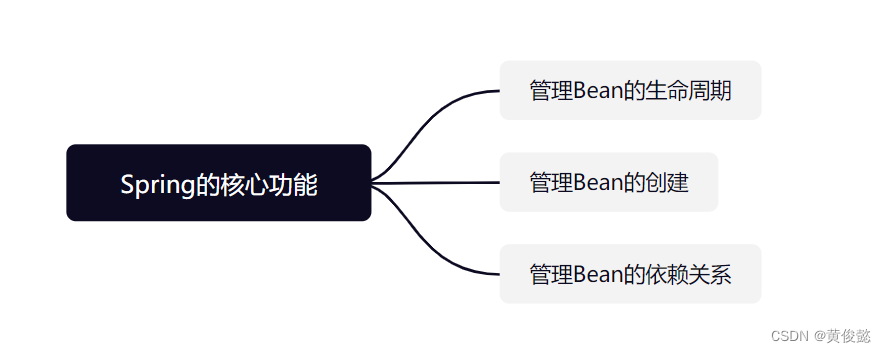
Spring的核心组件
先看看Spring有哪些比较核心的组件,没有列全,只列了一些主要的,混个眼熟。

其中DefaultListableBeanFactory是Bean工厂的最终实现类,最终使用到的Bean工厂就是它,而它同时又实现了BeanDefinitionRegistry(bean定义注册表),所以它也是一个bean定义注册表。
Spring是如何实现IOC和DI的?
定义了BeanDefinition
首先,Spring把我们交给他管理的对象,称为Bean,然后又定义了BeanDefinition(Bean定义)去描述这些Bean
那为什么要弄一个BeanDefinition呢?
BeanDefinition相当于是对Class类元数据信息的一种扩展。
因为Spring不是简单的帮我们创建一个对象就完事,他需要知道如何创建这个对象,如何给它的属性赋值,注入哪些值,有哪些生命周期回调函数等等,单凭一个Class对象,不足以描述一个Bean的所有属性。
因此,Spring把Bean的作用域,是否懒加载,属性依赖信息,自动装配模型等描述信息,封装到了BeanDefinition中。
有了BeanDefinition之后,Spring就可以根据BeanDefinition去实例化和初始化Bean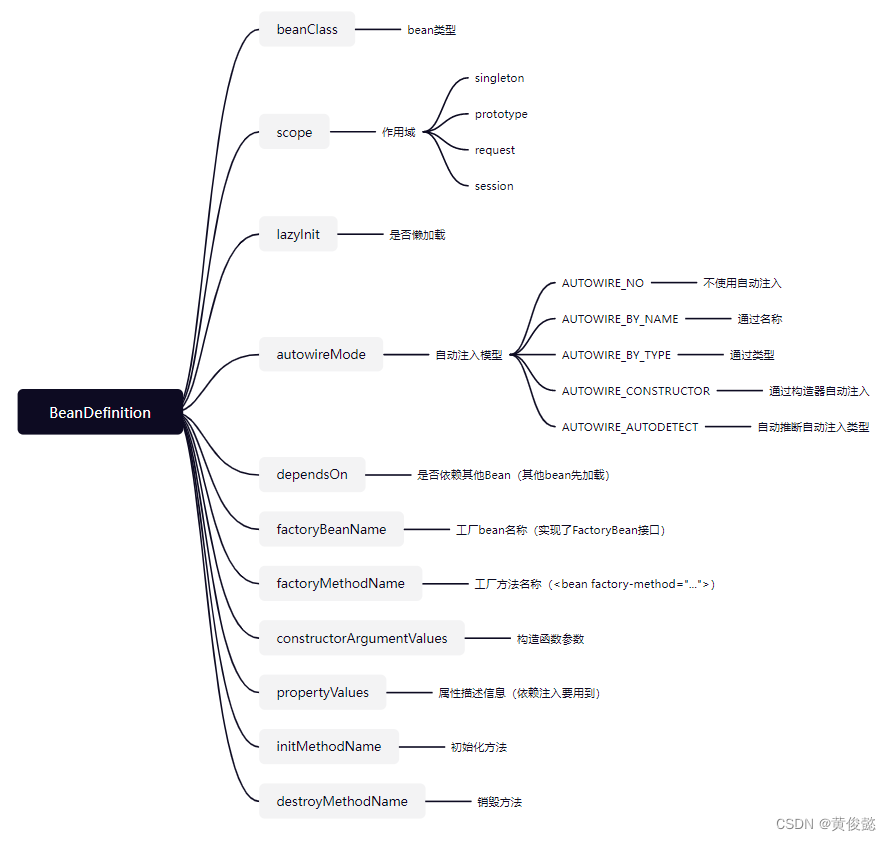
扫描加载BeanDefinition
先有BeanDefinition,再有bean。
接下来Spring就要扫描我们的配置文件或注解,加载BeanDefinition,注册到Spring容器里面,正确来说应该是放到一个Map中,这个Map的名字叫beanDefinitionMap,key就是beanName,value就是BeanDefinition。
而这个工作是通过BeanDefinitionReader完成的。
如果是XML的配置方式,则通过XmlBeanDefinitionReader完成BeanDefinition的加载和注册,
如果是注解的配置方式,则通过AnnotatedBeanDefinitionReader完成BeanDefinition的加载和注册。
BeanDefinition最后会被注册到DefaultListableBeanFactory(也就是我们常说的的Bean工厂)的beanDefinitionMap中,DefaultListableBeanFactory实现了BeanDefinitionRegistry接口,所以拥有了BeanDefinition注册表的功能。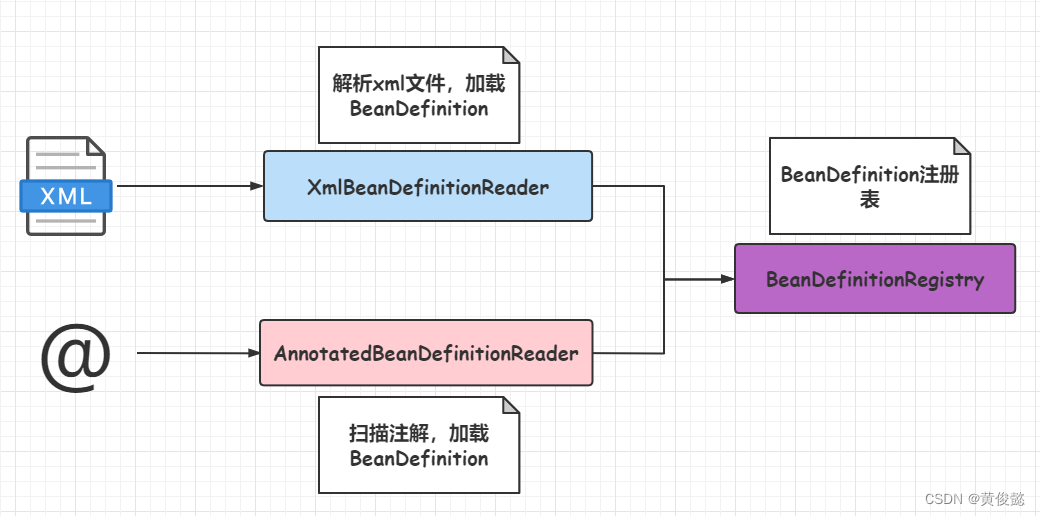
根据BeanDefinition进行Bean的实例化和初始化
有了BeanDefinition,就可以根据BeanDefinition进行Bean的实例化和初始化了。
实例化
首先是根据BeanDefinition进行Bean的实例化,实例化是通过反射完成的,会通过反射获取Constructor构造器对象,然后调用newInstance方法进行实例化。
但是一个类中可能有多个构造函数,具体要用哪个呢?
这就要看BeanDefinition中关于构造器参数的描述信息constructorArgumentValues,获取最匹配的构造器。这个步骤叫做推断构造。
如果没有指定构造器参数,则使用的是默认的构造器。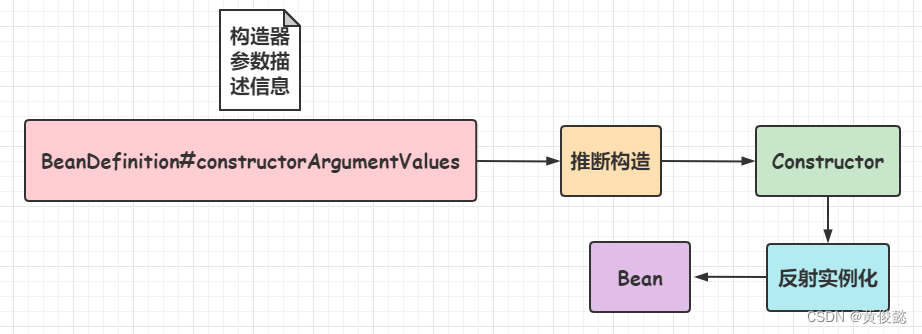
属性赋值
Bean实例化之后,就要对Bean进行属性赋值,也就是依赖注入。
Spring会根据BeanDefinition中记录的autowireMode自动注入模型,使用对应的策略进行依赖注入。
不同的自动注入模型,对应使用不同的策略为该Bean的属性找到匹配的值或对象:
- byName:BeanFactory#getBean(属性名)
- byType:根据类型从Spring容器中获取beanName,再通过BeanFactory#getBean(beanName)获取bean,这里如果获取到多个相同类型的bean,还要推断出一个最匹配的
- constructor:构造器注入,不在这里处理,在实例化的时候已经处理了
- no:不使用自动注入,使用我们手动指定的值(也就是配置文件指定要注入的属性值),手动指定的值保存在BeanDefinition的propertyValues中
为该Bean的属性找到匹配的值后,并不是马上进行属性赋值,而是收集到一个PropertyValues中,后面再根据PropertyValues为该Bean的所有属性进行赋值。PropertyValues相当于是一个对bean的不同属性要赋哪些值的描述对象。
BeanDefinition中的propertyValues也是一个PropertyValues对象,保存的是我们手动指定的属性值,这里会合并为一个PropertyValues对象。
属性赋值当然也是通过反射进行,通过setXXX方法的方法对象Method的 Method#invoke(…) 方法进行属性赋值。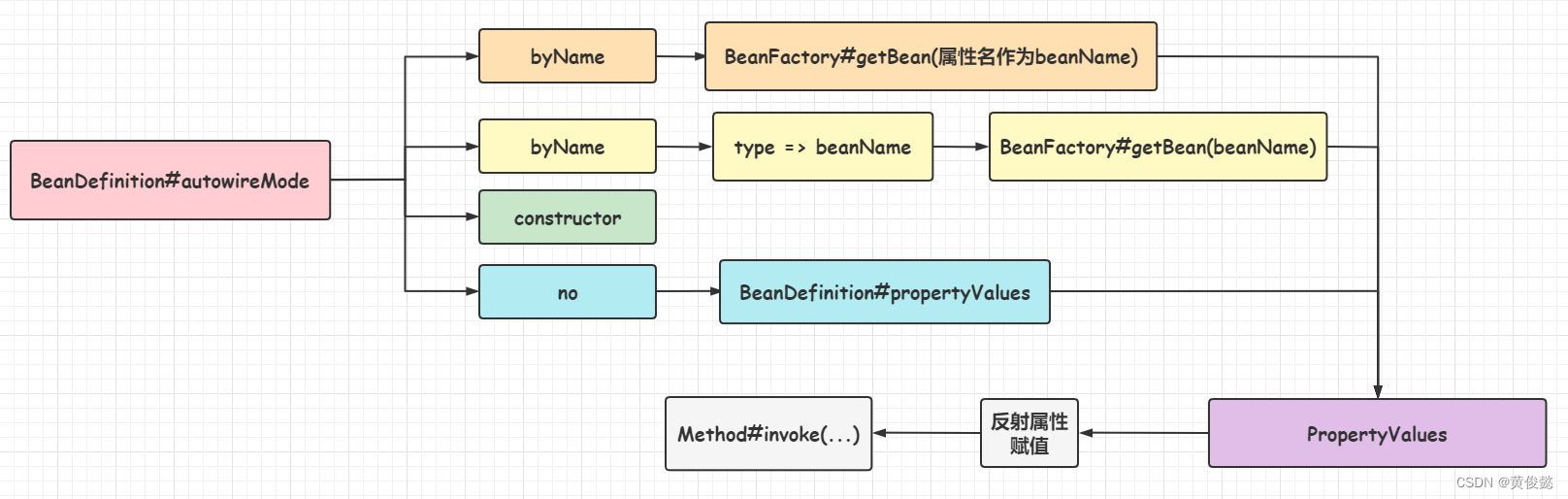
保存到单例缓冲池
初始化完成后的Bean,就会放入到单例缓存池中。
这个单例缓存池的名字叫singletonObjects,也是一个Map,key是beanName,value是对应的Bean,当我们需要某个Bean时,就从该缓存池中返回。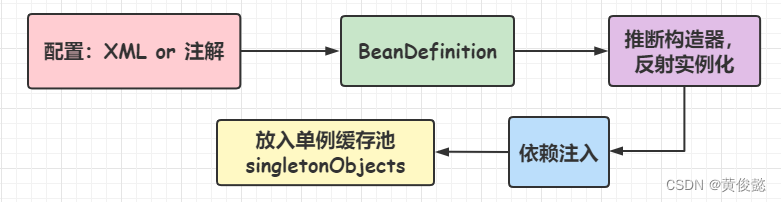
一个Bean从创建到销毁都会经历哪些步骤?
上面这个流程是比较粗糙的,一个Bean在Spring中是有一个完整的生命周期的,也就是在实例化、初始化、初始化完成、再到销毁,有哪些步骤,要干哪些事情。
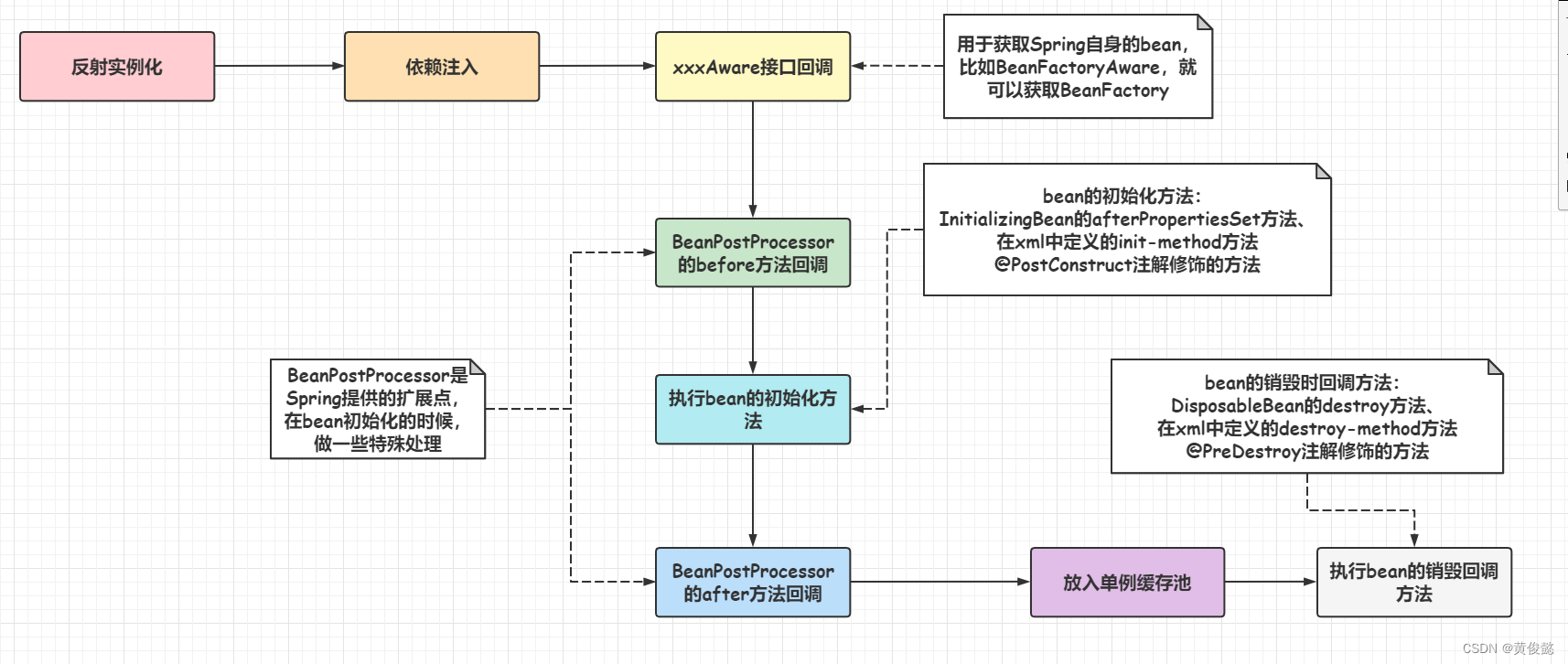
以上就是bean的生命周期的详细过程。
xxxAware接口是用于获取Spring自身的bean的,比如实现了BeanFactoryAware接口,Spring会回调setBeanFactory方法,我们就可以获取到BeanFactory,通过实现BeanNameAware接口获取beanName也是同理。
BeanPostProcessor是Spring提供的扩展点,该接口有两个方法postProcessBeforeInitialization和postProcessAfterInitialization(也就是before方法和after方法),会在bean初始化的时候被回调。用于在执行beab的初始化方法的前后,对该bean进行一些特殊处理,比如可以动态代理返回一个代理对象,替换掉原来的bean。
我们可以定义自己的BeanPostProcessor实现,然后注册到Spring容器中。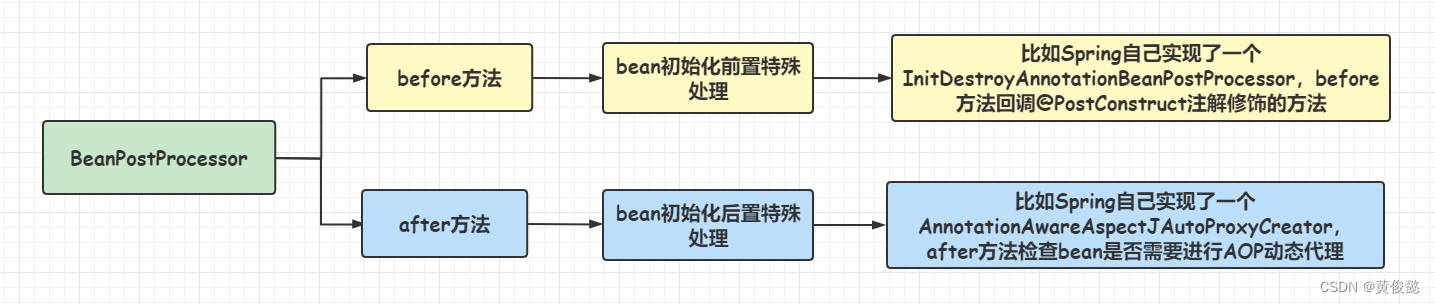
而bean的初始化方法和销毁回调方法,我们应该比较熟悉。我们可以通过接口的方式、xml、注解,配置初始化方法和销毁回调方法。
生命周期阶段接口xml注解初始化InitializingBean#afterPropertiesSetinit-method@PostConstruct销毁DisposableBean#destroydestroy-method@PreDestroy
Spring怎么完成依赖注入?
以下是Spring对依赖注入的具体处理逻辑。
byName
byName的依赖注入比较简单,就是以属性名作为beanName,调用**BeanFactory#getBean(属性名)**,从Spring容器中获取对应的bean,然后通过反射进行注入。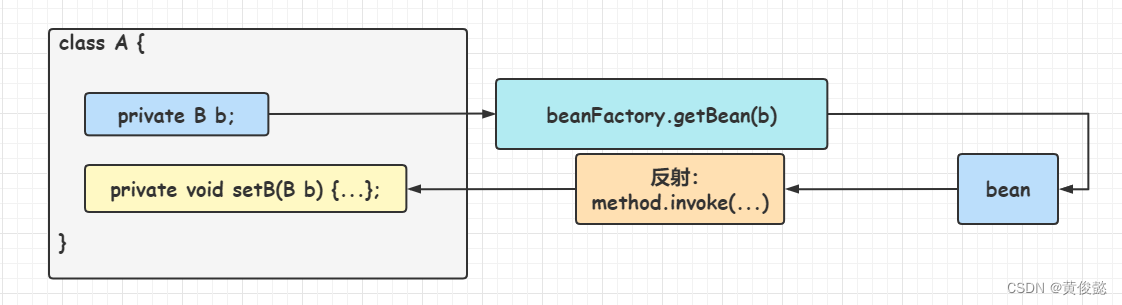
byType
byType稍微复杂一点。
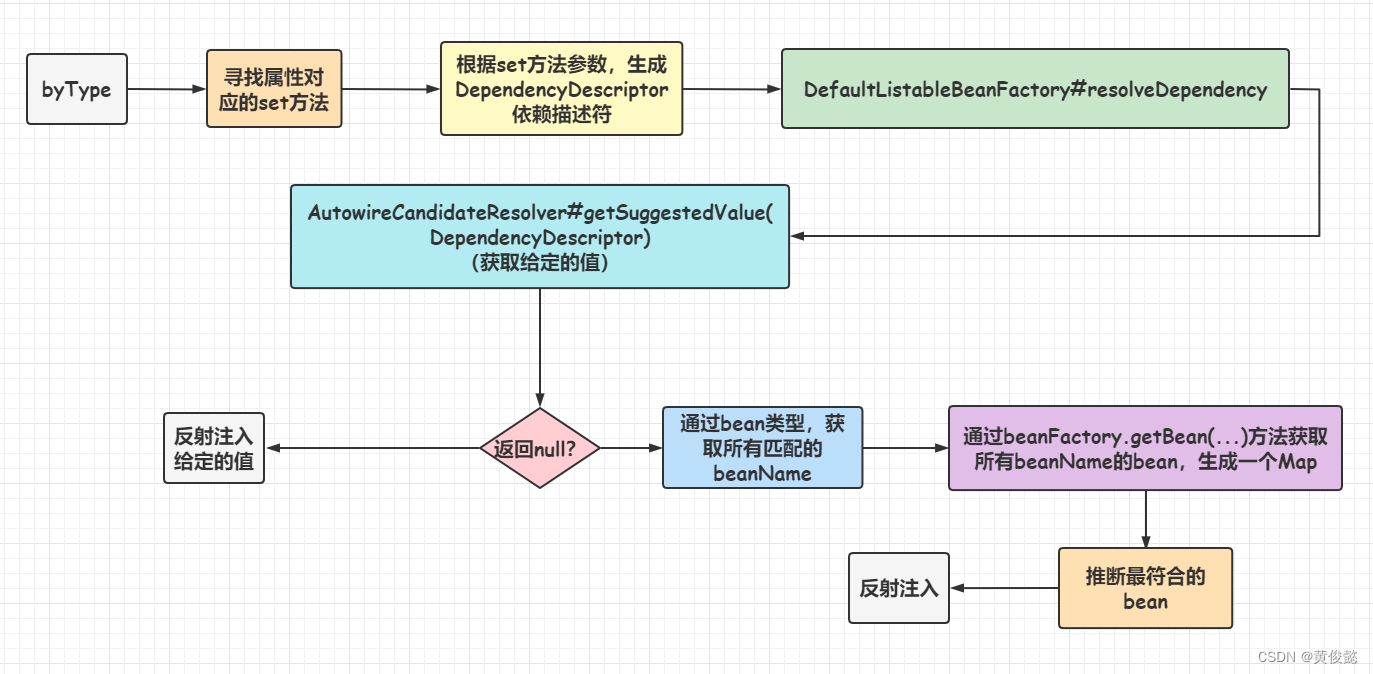
byType使用到了DefaultListableBeanFactory的resolveDependency方法,这个方法顾名思义就是解决依赖关系。
byType的处理,首先会根据属性名获取对应的setXXX方法,然后根据set方法的参数,生成一个DependencyDescriptor依赖描述符,DependencyDescriptor是对set方法的描述。这个描述符对象,包含了set方法所在类的Class,set方法名称,参数类型,set方法对应的属性名等。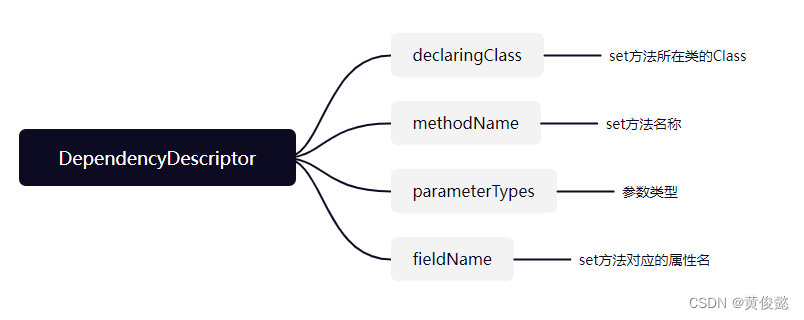
然后,DefaultListableBeanFactory#resolveDependency有两步处理:
- 回调AutowireCandidateResolver的getSuggestedValue方法,根据DependencyDescriptor依赖描述符获取对应的值。
- 如果AutowireCandidateResolver的getSuggestedValue方法没有返回有效的值。则通过bean的类型获取所有符合该类型的beanName,然后获取生成一个Map,key是beanName,value是beanName对应的bean,然后推断哪个bean更符合,则使用哪个bean注入。
这里出现了一个比较陌生的东西-AutowireCandidateResolver(自动装配候选解析器),其实它就是Spring定义的一个接口,里面有个getSuggestedValue方法。我们可以通过自定义一个AutowireCandidateResolver然后实现getSuggestedValue方法,实现自定义的依赖注入,例如为某些特定类型的属性,注入我们自己给定的值或者对象。比如Spring自己就实现了一个QualifierAnnotationAutowireCandidateResolver类型的AutowireCandidateResolver,getSuggestedValue方法处理@value注解修饰的属性的依赖注入,返回@Value注解上给定的值或者@Value指定的配置项对应的值。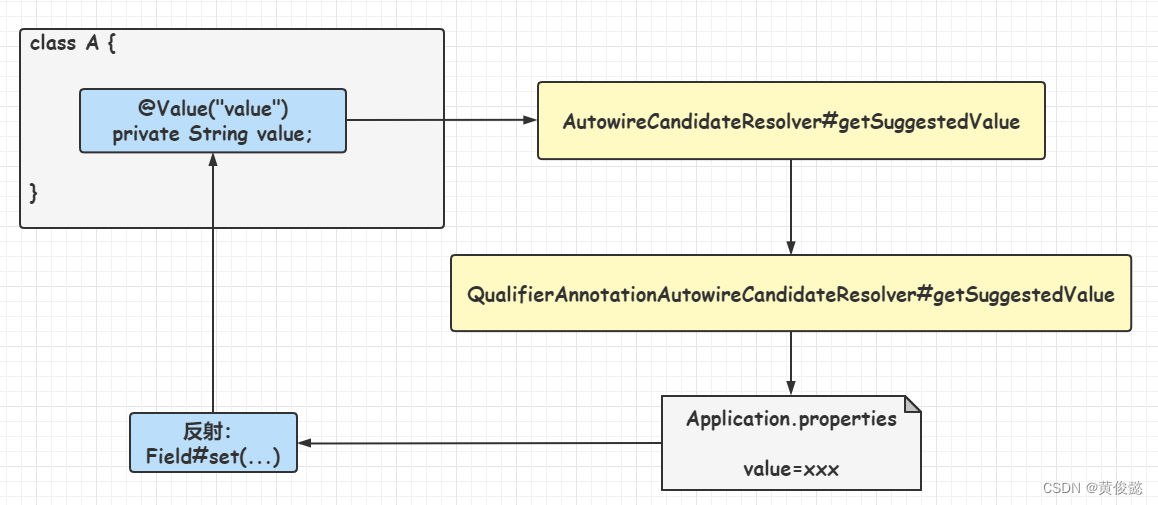
如果AutowireCandidateResolver的getSuggestedValue方法返回了null,那么就要走接下来的步骤:通过bean类型获取所有类型匹配的beanName,进而获取所有类型匹配的bean,然后推断一个最合适的。
那如何推断最符合的bean呢?
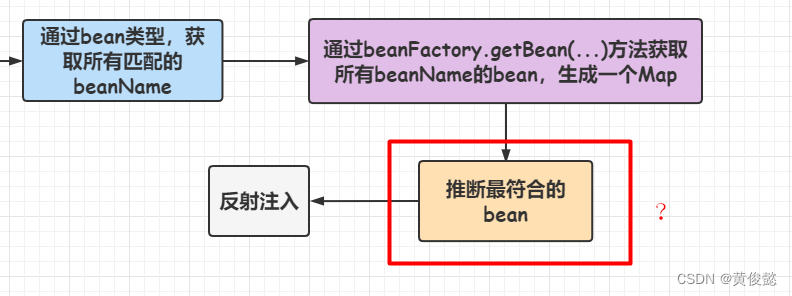
其实就是四步:
- 如果被 @Primary 注解修饰的,优先使用,但是发现有多个被@Primary修饰的,则报错
- 如果没有@Primary注解修饰的,则看有没有被 @Priority ,如果有,则使用,发现多个被@Priority注解修饰的,则报错
- 如果也没有,则寻找beanName和属性名匹配的bean
- 如何还没有,如果该属性是必须要注入的,则报错,否则返回null
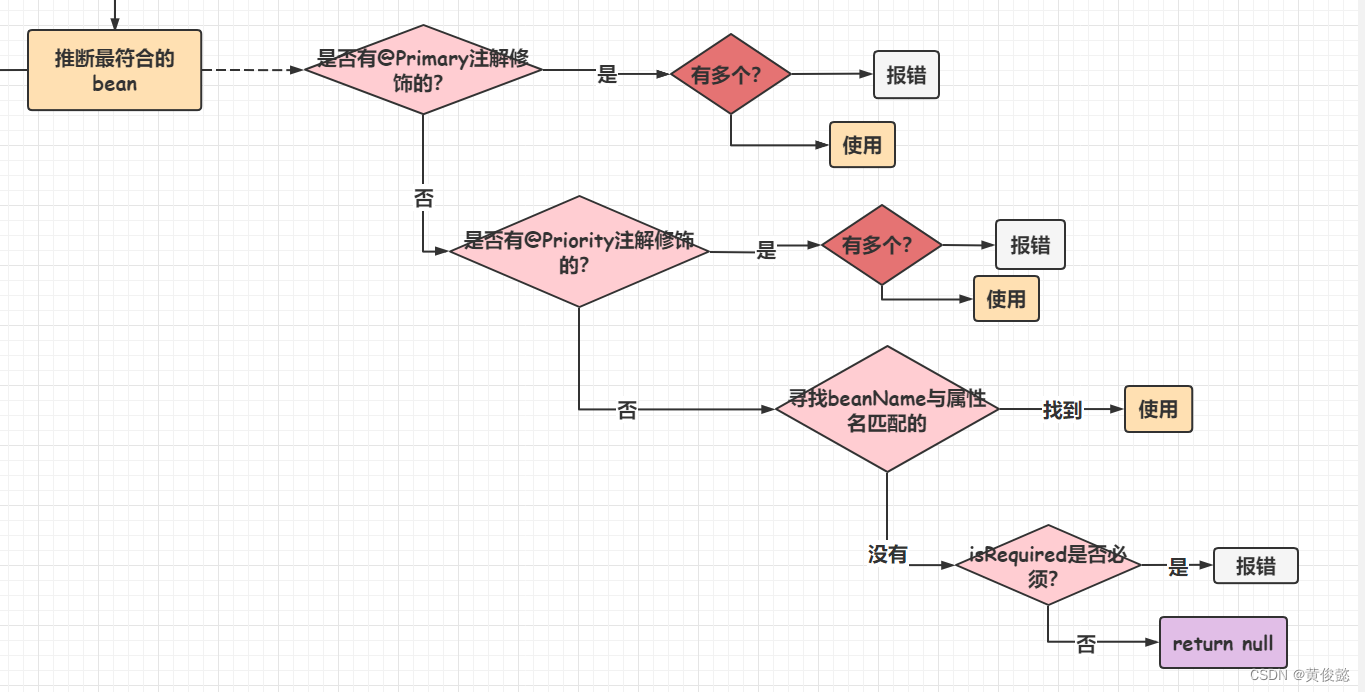
@Autowired
@Autowired注解修饰的属性的处理,比较特别。
Spring自定义了一个BeanPostProcessor实现类AutowiredAnnotationBeanPostProcessor,再进行依赖注入时会进行回调,扫描被被@Autowired注解修饰的属性,然后最终会调用DefaultListableBeanFactory的resolveDependency方法,所以最后的处理逻辑是跟byType一致的。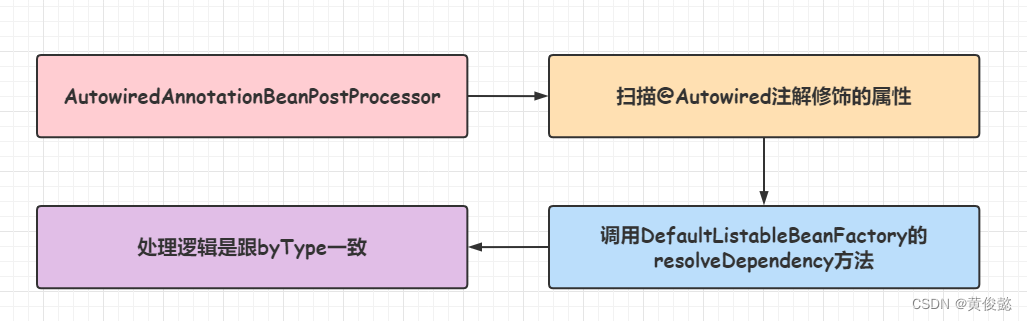
@Autowired如果在字段上,则通过Field#set(…)进行反射注入
@Autowired如果在方法上,则通过set方法的Method对象的Method.invoke(…)方法进行反射注入
循环依赖怎么解决?
什么是循环依赖?
就是你中有我,我中有你~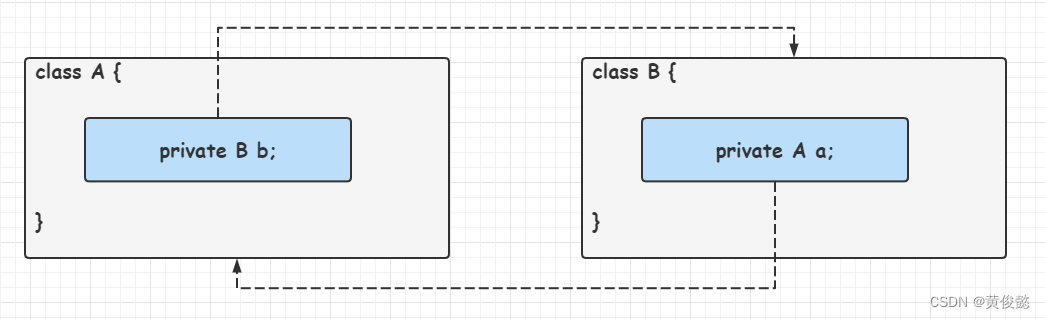
这种情况如果不做特殊处理,就会造成死循环,也就是初始化A时,发现依赖了B,就去初始化B,而初始化B时,发现依赖了A,又去初始化A…
那Spring如何解决循环依赖呢?答案就是三级环境。
三级缓存解决循环依赖
第一级缓存就是单例缓存池singletonObjects,这个是在bean初始化完成后才放入进去的,而依赖注入是在bean初始化的时候进行的,显然不能解决循环依赖。
所以应该多加一个二级缓存,在bean实例化后,初始化前,提前放入到二级缓存中,这叫提前暴露。然后当进行依赖注入时,发现属性所依赖的bean又依赖到自己,那就直接从缓存中拿。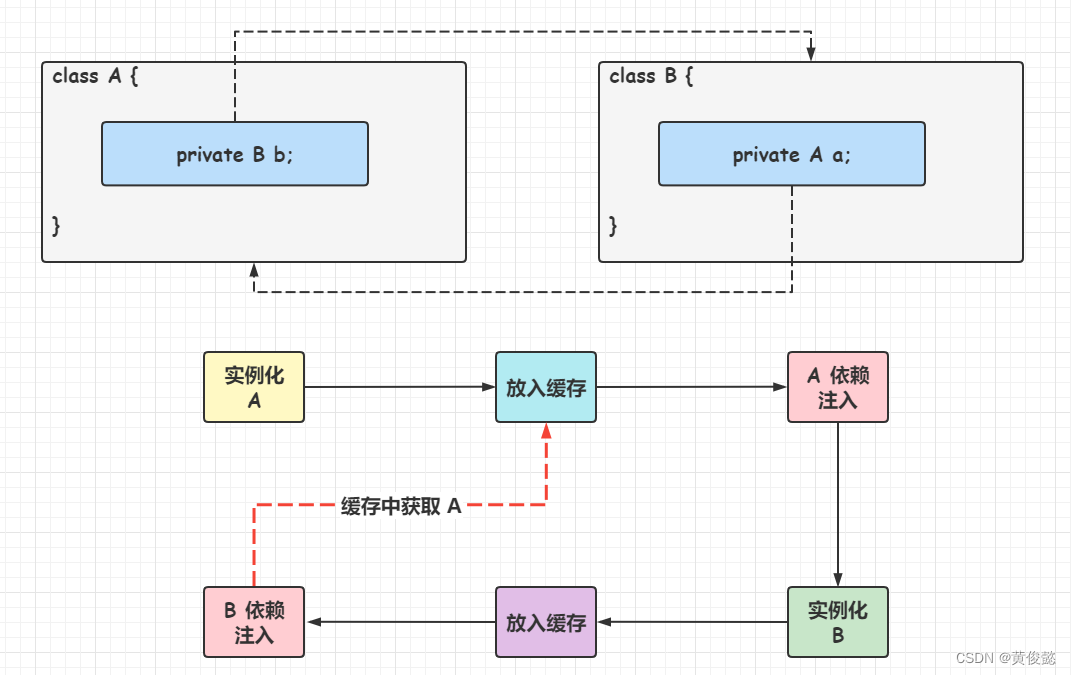
那看来搞两级缓存就可以了,为什么要搞三级呢?
那是因为Spring还要处理AOP处理,假如一个bean后面要进行AOP处理,返回一个代理对象,那这里提前暴露的又是原对象,就会出现注入的类型和最后放入到单例缓存池的类型不一致。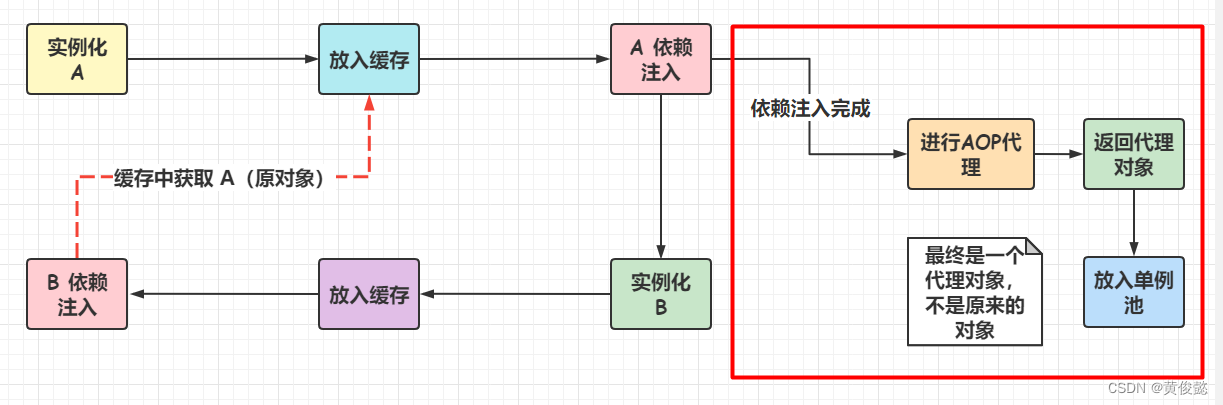
所以再多搞一级缓存,也就是第三级缓存。
第三级缓存存放什么呢?存放的是把bean包装一层后的ObjectFactory对象,ObjectFactory#getObject()返回里面的bean。为什么要包装一层呢?因为不知道这个bean需不需要进行AOP,如果不需要,则返回原来的bean,如果需要,那么就要提前进行AOP处理,返回代理对象,这样依赖的bean和最后放入单例池的都是同一个对象(代理对象)。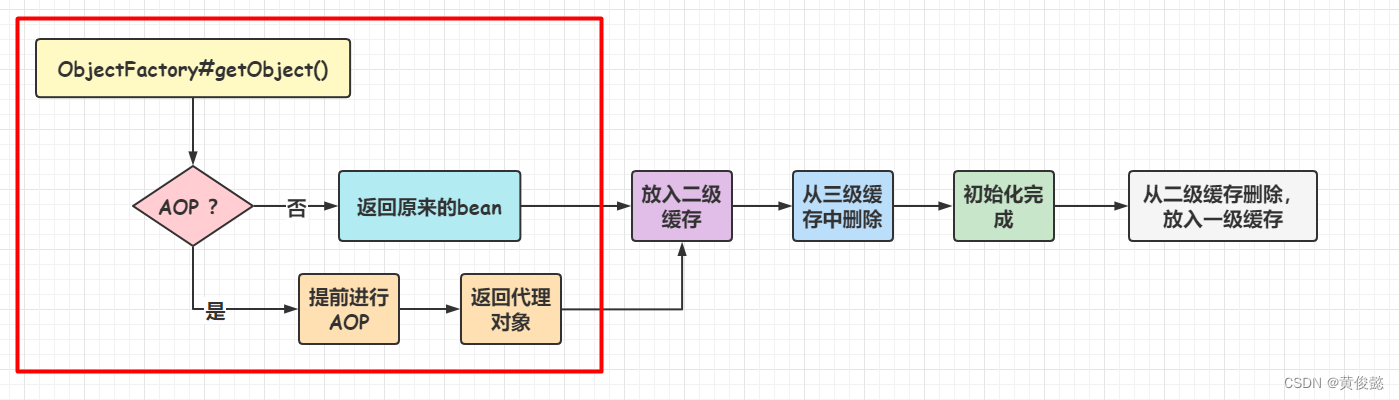
然后依赖注入时获取依赖的bean就变成这样的流程: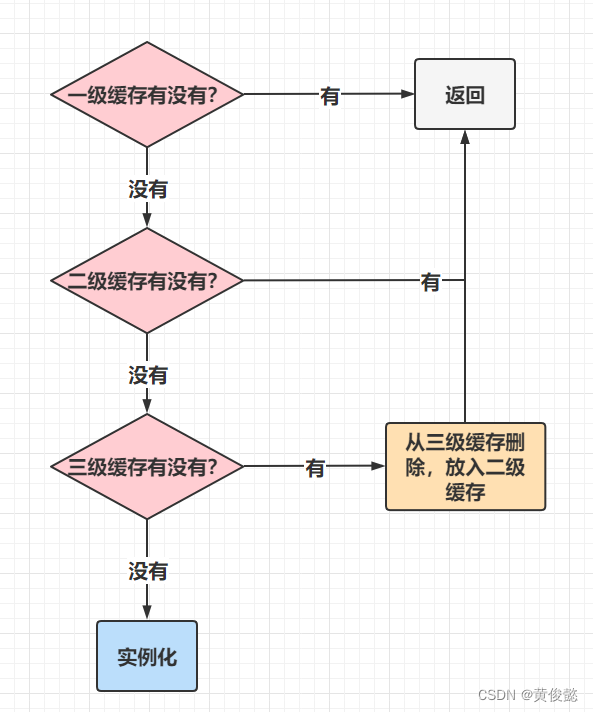
三级缓存中返回的对象,放入二级缓存,然后从二级缓存删除。
实例化完成后,从二级缓存删除,放入一级缓存。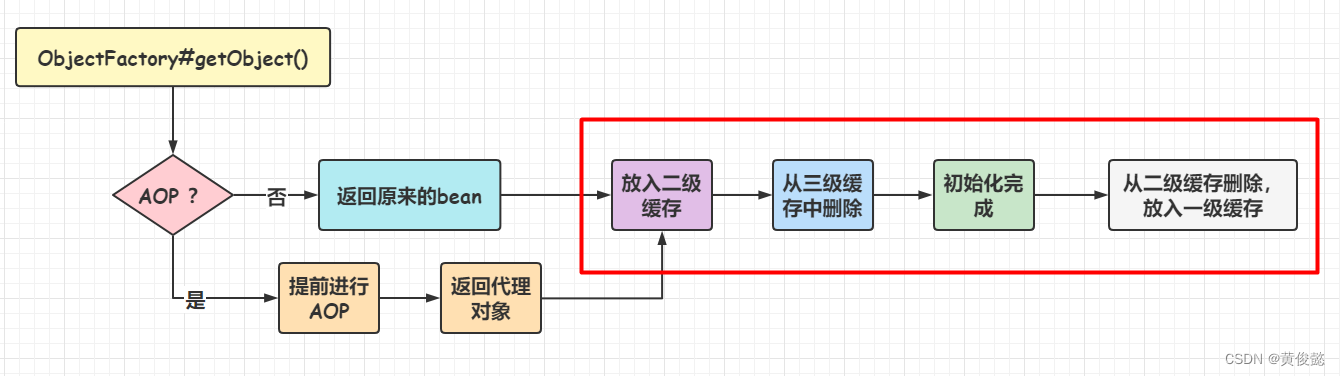
到这里,Spring最核心的原理基本上就差不多了,如果这些都能弄懂的话,可以说是对Spring有一个比较深入的理解。
当然Spring还有一些扩展的东西,比如AOP,事务,还有其他的扩展点。
Spring怎么实现AOP的?
AOP是什么?为什么会有AOP?
AOP的意思就是面向切面编程,所谓切面,可以简单理解为横跨了多个方法,就像一个切面一样,在各方法前(或者后)都要执行的代码。
比如处理请求前打印日志,进行权限校验等,这些代码在每个请求方法前都要执行,但是不可能每个方法都重复写一遍,所以通过AOP,就可以把这些每个地方都要执行的代码,提取到切面中去。
AOP的核心组件
先看一下AOP的核心组件: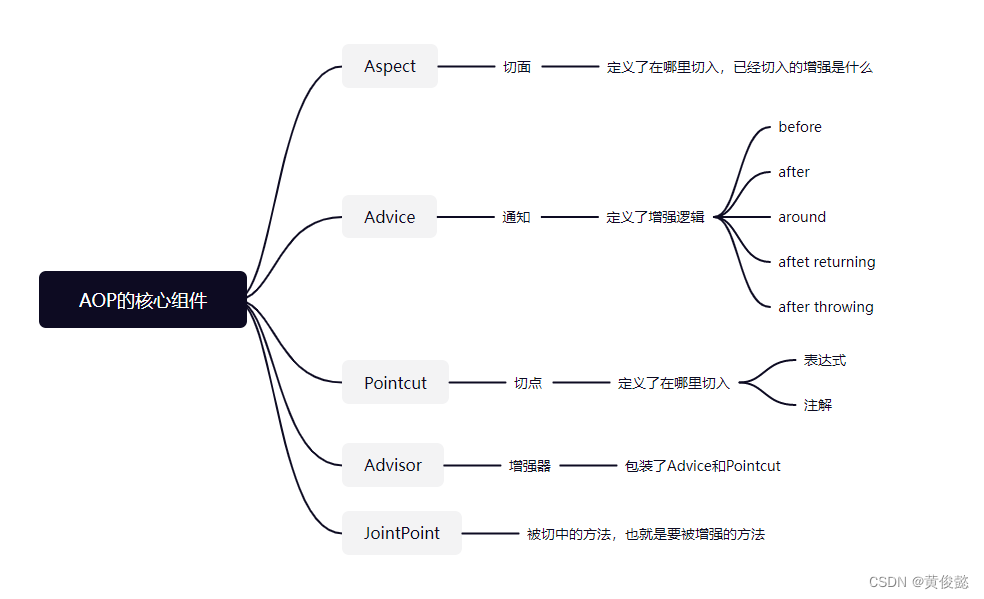
有了解过AOP的应该对这些都很熟悉。
AOP处理
AOP处理要做的事情,就是在被Pointcut命中的方法前后(具体是前是后,要看Advice类型),织入Advice定义的增强逻辑,织入的方式就是创建一个代理对象,在执行方法前(或者后),执行增强逻辑。
经过代理增强之后,目标方法就会被包裹起来,根据不同的Advice(通知)类型,在它的前前后后,会有不同的增强逻辑: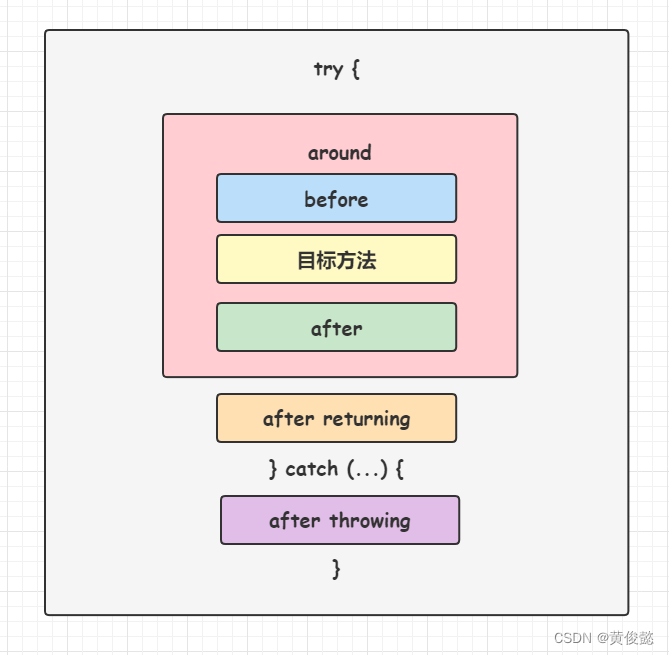
Spring中的AOP实现
Spring首先实现了一个BeanPostProcessor(bean后置处理器),AnnotationAwareAspectJAutoProxyCreator,它的祖先类AbstractAutoProxyCreator在after方法定义了AOP的入口,在after方法中检查是否要对bean进行AOP处理,如果需要,则进行AOP处理。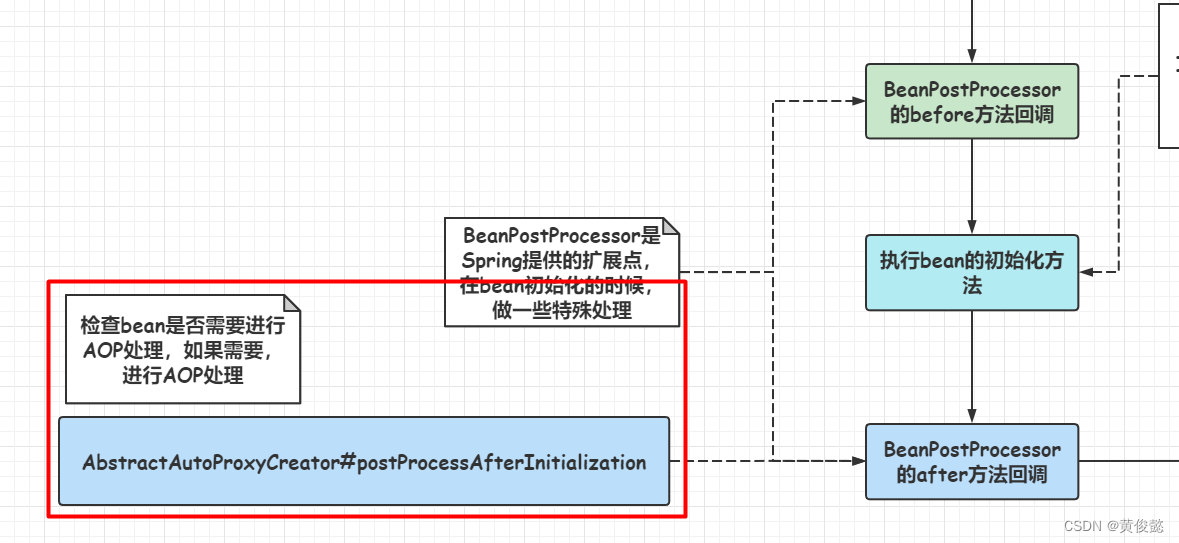
检查一个bean是否需要进行AOP处理,其实就是拿到所有我们定义的Pointcut,看bean里面的方法有没有被Pointcut切中的,有的话,就要进行AOP处理。
Pointcut是通过MethodMatcher方法匹配器的matches方法,与方法进行匹配,匹配结果返回true或者false。
如果需要进行AOP处理,则要进行动态代理,生成代理对象。
代理方式有JDK动态代理和CGLib两种,如果bean实现了接口,则使用JDK动态代理,否则使用CGLib。
生成的代理对象里,会保存一个Advisor[] 增强器数组,在方法调用时会触发Advisor里的Advice增强逻辑的调用。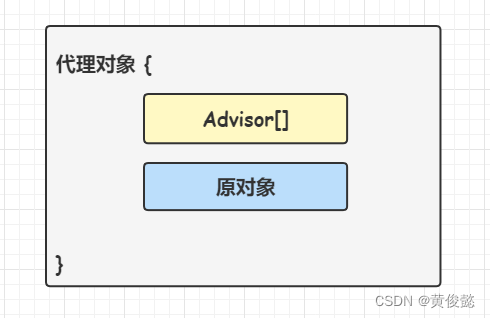
在进行方法调用时,就会从Advisor中筛选出需要执行的Advisor(一个类中有多个方法,可能被不同的Pointcut切中,就要进行不同的增强逻辑),这个筛选也是通过Pointcut(一个Advisor会有一个Pointcut与之对应) 进行匹配。从筛选出的各个Advisor中取出Advice,与目标方法一起,封装为一个执行器链。然后就是责任链模式的链式调用。
Spring怎么实现事务的?
Spring是通过AOP实现事务的,也就是通过AOP处理,把被@Transactional注解修饰的目标方法包裹在try-catch块里面,在进入try-catch之前,先开启事务,然后在try块中执行目标方法,如果目标方法报错,则在catch块中回滚事务,如果没有报错,则在try-catch块之后提交事务。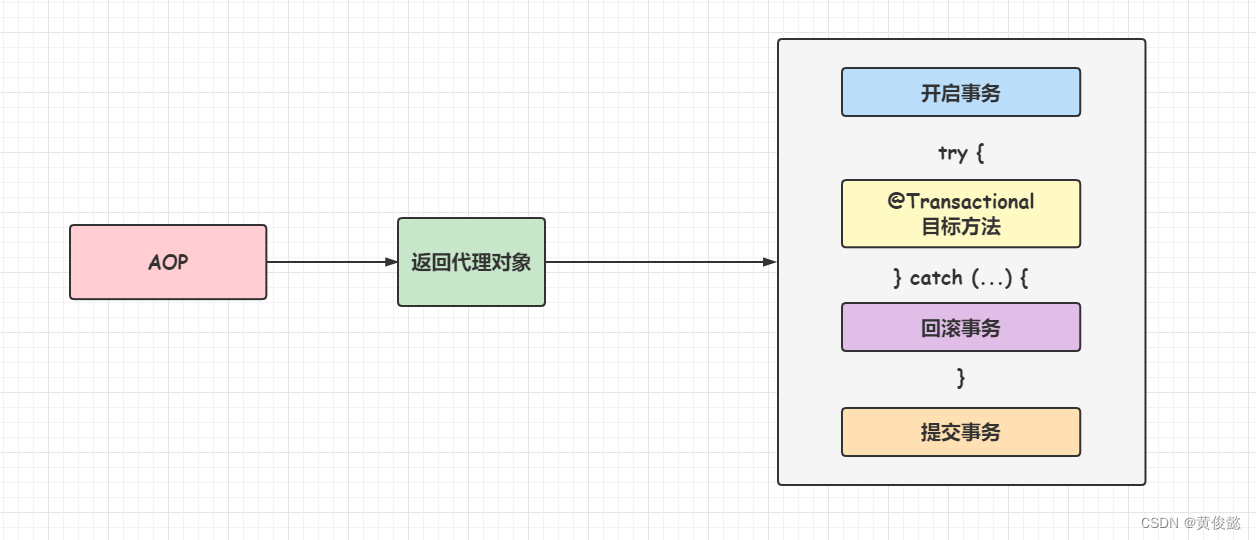
Spring提供了哪些扩展点?
这里就简单罗列一下Spring的扩展点、扩展点的用途、以及例子,具体细节就不展开说明了。
版权归原作者 黄俊懿 所有, 如有侵权,请联系我们删除。