

📫作者简介:小明java问道之路,专注于研究 Java/ Liunx内核/ C++及汇编/计算机底层原理/源码,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 InfoQ签约作者、CSDN专家博主/后端领域优质创作者/内容合伙人、阿里云专家/签约博主、51CTO专家 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
本文导读
本文基于《MySQL复制与高可用水平扩展架构实战》扩展其复制的原理以及切换一致性问题。还没看基础的读者们请先行了解这篇基础的MySQL复制详解与实战。本文主要对 MySQL 复制原理与主备一致性同步工作原理解析。
一、MySQL 数据库复制原理
本文基于《MySQL复制与高可用水平扩展架构实战》扩展其复制的原理以及切换一致性问题。还没看基础的读者们请先行了解这篇基础的MySQL复制详解与实战。
1、基于语句的复制
MySQL 5.0和更早版本只支持基于语句的复制,也称为逻辑复制,这在数据库领域很少见。
在基于语句的复制模式中,主数据库记录导致数据更改的查询,当备用数据库读取并重放这些事件时,它实际上再次执行在主数据库上执行的SQL。
好处有很多,一是记录和执行这些语句可以保持活动和备用同步;二是二进制日志中的事件更紧凑,因此相对而言,基于语句的模式不会使用太多带宽。更新TB数据的语句在二进制日志中只能占用几十个字节。
不好的地方也有几点,一是主数据库上的数据更新可能取决于除执行语句之外的其他因素(例如时间戳);二是存在着一些无法被正确复制的 SQL(例如 MySQL中的CURRENT_USER()函数用于返回MySQL帐户的用户名和主机名,或者使用基于语句的复制模式时,存储过程和触发器也可能存在问题);
三是更新必须是串行化,这就需要更多的锁。
2、基于行的复制
基于行复制,该方法将实际数据记录在二进制日志中。
基于行复制,可以正确复制每一行,并且可以更有效地复制某些语句,因为不需要重放更新数据库数据的查询操作,所以可以使用基于行的复制模式来更有效地复制数据,并且重放查询可能会很昂贵。
-- 这时基于行的复制就会复制 SELECT 语句
INSERT INTO stable();
SELECT * FROM stable where id ='';
没有一种模式适合所有情况,所有MySQL可以在两种复制模式之间动态切换。
默认情况下,使用基于语句的复制模式,如果无法正确复制语句,会自动切换到基于行的复制模式。
MySQL 还可以将会话级别变量设置为 binlog_format(二进制格式),以控制二进制日志格式。
对于基于行的复制,时间点恢复很困难,但并非不可能。稍后第二节讲到日志服务器将有所帮助。
3、两种复制方式的比较与生产环境使用
在实际生产环境我们一般会使用基于行的复制,因为这种方法可以比较读多写少很多无效的sql,
但是如果数据库版本太低,就只有基于sql的复制方式。
3.1、基于sql的复制优缺点
优点:
1、当主备模式不同时逻辑复制可以在各种条件下工作,基于语句的复制更灵活。
2、基于语句的复制过程基本上是执行SQL语句,以易于理解的方式在跑步过程中发生的变化,当出现问题时,可以很好地定位
缺点:
MySQL一些情况下无法复制基于语句的模式。存储过程、触发器存在一些复制的错误。简单地说:如果有使用触发器或存储过程,不能使用基于语句的复制模式。
3.2、基于行的复制模式的优缺点
优点:
1、基于行的复制模式无法处理的场景几乎没有(包括SQL构造、触发器、存储过程等都可以执行)。
2、可以减少锁的使用,因为它不要求这串行化是可重复的
3、基于行的复制模式只会记录数据更改,因此二进制日志中记录的实际上是主数据库上已更改的数据。
此模式可以更清楚地知道服务器上发生了什么更改,并更好地记录数据更改。基于行的二进制日志还记录更改之前的数据,有利于某些数据恢复。
缺点:
由于执行过的 sql 语句未记录在日志中,因此无法确定执行了哪些SQL语句,只知道数据行中的更改。
二、MySQL 主备一致性原理
1、****主/备切换过程
在的主/备切换过程,图1中,客户端读取和写入都直接访问 DB1,而 DB2 是 DB1 的备用数据库,并且仅同步 DB1 的更新并在本地执行它们,这样, DB2 和 DB1 的数据可以保持相同。虽然 DB2 未被直接访问,但我仍然建议您将 DB2 设置为只读模式
当需要切换时,将切换到图2。此时,客户端将读取和写入节点 DB2,而 DB1 是 DB2 的备用数据库。

2、MySQL 的sql语句同步内部工作原理
在从客户端接收到更新请求后,主库执行内部事务的更新逻辑并写入undo log、bin log、redo log。
备库和主库之间保持长连接,主数据库A内有一个线程 dump_thread,用于服务备库的长连接。
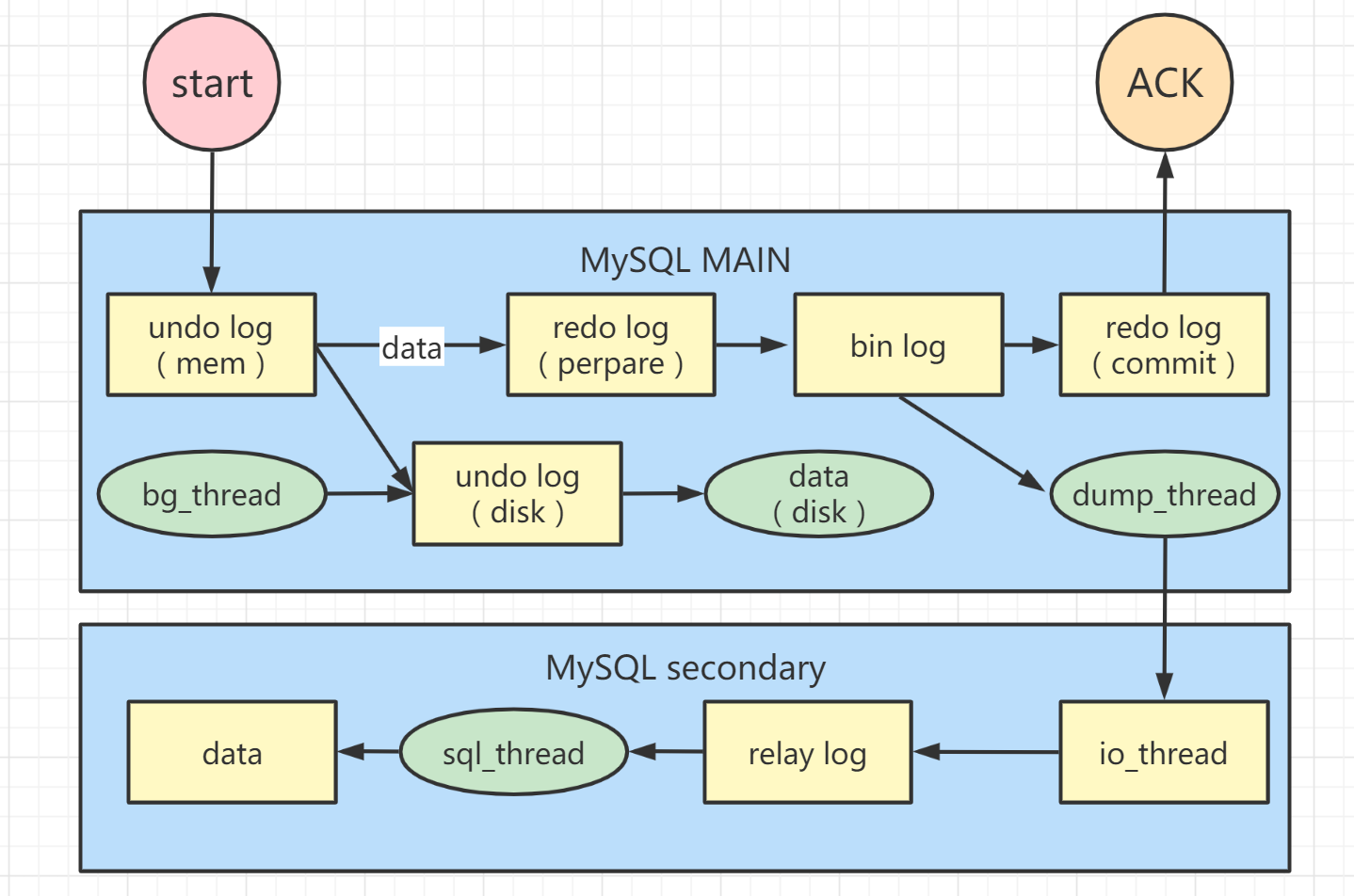
具体流程如下,在备用数据库上,使用 change-master (更改主机)命令设置主数据库 的IP、端口、用户名和密码,以及请求bin log的位置(此位置包括文件名和日志偏移量)。
在备用数据库上执行 start slave (启动从属设备)命令。此时,备用数据库将启动两个线程,即figure_Thread(图形线程)和sql_Thread(sql线程)中显示的 io 其中 io_Thread 负责与主库建立连接。
主库校验完用户名、密码后,开始按照备库传过来的位置,从本地读取 bin log,发给从库。
获取 bin log后,备用数据库将其写入本地文件,该文件称为 relay log (中继日志)。sql_Thread 读取传输日志,解析日志中的命令并执行。
3、MySQL 循环复制问题
双主结构(MM模式)中,客户端在 主库A 上更新了一条语句,然后再把生成的 bin log 发送到主库 B,节点 B 执行完这条更新语句后也会生成 bin log。这时主库 A,不知道这是 B库的同步当成新的执行操作就会发生循环复制问题。
如何解决呢?
首先设置两个数据库的服务器ID不同。如果相同,则不能设置为主/备用关系;
当备用数据库接收到 bin log 并重放它时,它会生成一个新的 bin log,其服务器ID与原始binlog相同;
每个数据库收到自己主数据库发送的日志后,首先判断服务器ID。如果与自己的ID相同,则表示bin log 日志是自己生成的,将直接丢弃。
总结
本文基于《MySQL复制与高可用水平扩展架构实战》扩展其复制的原理以及切换一致性问题。还没看基础的读者们请先行了解这篇基础的MySQL复制详解与实战。本文主要对 MySQL 复制原理与主备一致性同步工作原理解析。
版权归原作者 小明java问道之路 所有, 如有侵权,请联系我们删除。