
首先回顾之前的知识点
消费者消费消息,每消费offset+1,然后提交offset给到我们kafka中topic中的cousumer_offsets,该消费者宕机后,另外的消费者就会读取consumer_offsets读取我们的offset消费后面的消息
我们kafka消费者是自动拉取消息的,mq是队列push给消费者
自动提交:消息poll下来后(还没有消费)直接提交offset,速度很快,可能出现消费失败
手动提交:在消息消费时/消费后再提交offset
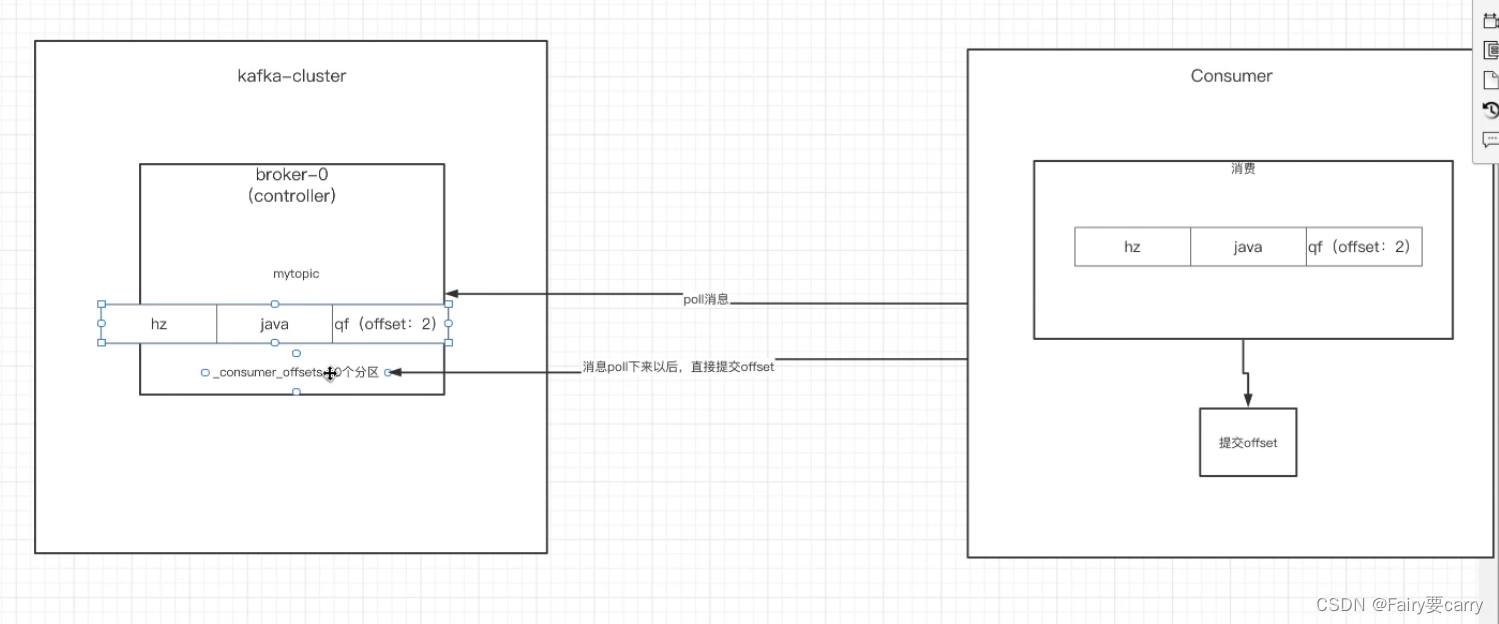
自动提交offset
缺点:可能会丢消息,比如消费者poll了topic中partition的消息后,然后提交offset,可能消费者没有消费成功
提交的内容offset——>消费组+topic+offset

自动提交的配置

/**
* 1.1设置是否自动提交offset并设置offset的间隔时间
*/
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");

一poll就提交offset了
手动提交
分为手动同步提交+手动异步提交
手动同步提交:在消息消费完后调用同步提交的方法,当集群返回ack前一直阻塞,返回ack后表示成功

consumer.commitAsync();
手动异步提交:不需要等集群返回ack,直接执行后序的逻辑即可,我们可以设置一个回调方法
消费者poll消息的细节
定义:消费者会根据设置的消费时间来决定消费多少消息
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500)//拉取0.5s消息
默认消费者一次性poll500条信息(长轮询时间为1s),如果时间内poll了500条就结束for循环
//长轮询拉取时间,1s:消费者拉取1s时间不管拉了多少条消息(除非时间内拉取完了zk维护的topic分区中所有消息)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
完整代码:
while(true){
//长轮询拉取时间,1s:消费者拉取1s时间不管拉了多少条消息(除非时间内拉取完了zk维护的topic分区中所有消息)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到的消息:partition= %d,offset= %d,key= %s,value=%s %n",record.partition(),
record.offset(),record.key(),record.value());
}
/**
* 4.1手动提交:所有消息消费完再提交offset给broker中_consumer_offsets
*/
if(records.count()>0){
//同步:阻塞,提交成功,等待broker的返回ack
consumer.commitAsync();
//异步:提交完后不需要等待broker返回ack,直接往下走
}
}
如果两次poll的间隔>30s,集群会认为该消费者消费能力弱将其踢出,触发rebalance机制,消息交给消费组中的其他消费者
properties.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);

按照新方法进行消费消息
1.指定时间进行消息的消费
1.根据时间将topic中partition分区信息全部放入map中——>2.然后指定时间,封装topic和分区与时间到map中——>3.最后再将map添加到更高级的map,key为分区,如果有两个分区就是2个map——>4.最后遍历,然后提取出value并得到offset打印

2.指定分区开始从头消费+指定分区的偏移量开始消费
//指定分区消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME,0)));
/**
* 4.回溯消费消息(指定某分区从头开始消费)
*/
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME,0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME,0)));
/**
* 4.1指定offset开始消费
*/
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME,0)));
consumer.seek(new TopicPartition(TOPIC_NAME,0),10);
新消费组的消费offset规则
新消费组在启动后,默认是从当前分区最后一条消息的offset+1开始消费,可以通过配置进行重新消费
/**
* 2.13设置下次换了消费组还是按照offset记录继续消费
*/
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"earliest");
版权归原作者 Fairy要carry 所有, 如有侵权,请联系我们删除。