
首发CSDN:徐同学呀,原创不易,转载请注明源链接。我是徐同学,用心输出高质量文章,希望对你有所帮助。
文章目录
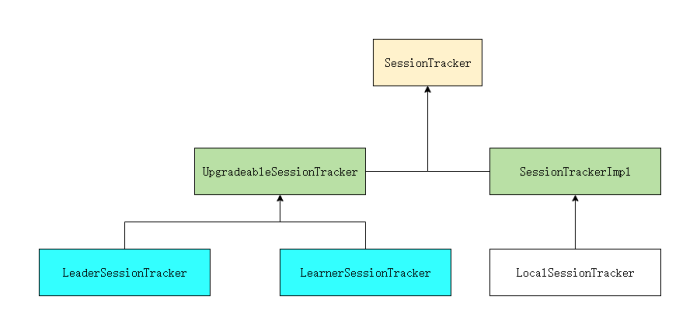
SessionTracker类关系结构

Zookeeper服务器会话管理是由SessionTracker完成的。
SessionTracker
由
ZooKeeperServer
所持有,具体持有情况如下:
LearnerZooKeeperServer持有LearnerSessionTracker。LeaderZooKeeperServer持有LeaderSessionTracker。LearnerSessionTracker和LeaderSessionTracker都可以持有LocalSessionTracker。
LearnerSessionTracker
LearnerSessionTracker
只负责session的创建,并不对session做过期检查、清理等工作。
touchTable
LearnerSessionTracker
用
AtomicReference<Map<Long, Integer>> touchTable
存储
sessionId
和
timeout
的关系,
Map<Long, Integer>
是
ConcurrentHashMap
,key是
sessionId
,value是
timeout
。
touchTable
相关增、删、改、查方法分别为:
LearnerSessionTracker#commitSession,创建session的事务请求在两阶段的commit阶段时调用。LearnerSessionTracker#removeSession,关闭session时调用。LearnerSessionTracker#touchSession,客户端向服务端发送请求的流程中调用,用于重置或者添加session。LearnerSessionTracker#snapshot,获取整个Map并将touchTable置空,因为Learner不管理session,所以在Learner接收到Leader的心跳时,会将持有的所有session(sessionId+timeout)取出来构建成PING响应包发给Leader,通知Leader更新对应session的过期时间。为了保证操作touchTable时线程安全,故而将其设置成AtomicReference修饰的。
public Map<Long, Integer> snapshot() {
return touchTable.getAndSet(new ConcurrentHashMap<Long, Integer>());
}
LeaderSessionTracker
LeaderSessionTracker
中对session的管理是委托给
globalSessionTracker
的。
globalSessionTracker
是
SessionTrackerImpl
的实例对象,其是一个线程。
每一个会话在
SessionTrackerImpl
内部都保留了三份:
sessionsById:HashMap<Long,SessionImpl>类型的数据结构,用于根据sessionID来管理Session实体SessionImpl。sessionsWithTimeout:ConcurrentHashMap<Long,Integer>类型的数据结构,用于根据 sessionID 来管理会话的超时时间。该数据结构和ZooKeeper内存数据库相连通,会被定期持久化到快照文件中去。sessionExpiryQueue:ExpiryQueue<SessionImpl>定制化实现的按过期时间分桶管理会话的数据结构。
创建sessionId

创建session实则是创建sessionId。
// org.apache.zookeeper.server.quorum.LearnerSessionTracker#createSession
public long createSession(int sessionTimeout) {
if (localSessionsEnabled) {
return localSessionTracker.createSession(sessionTimeout);
}
return nextSessionId.getAndIncrement();
}
sessionId会在
LearnerSessionTracker
创建时调用
initializeNextSessionId
设置一个初始值,后面就是在这个初始值的基础上自增来分配sessionID。
// org.apache.zookeeper.server.SessionTrackerImpl#initializeNextSessionId
public static long initializeNextSessionId(long id) {
long nextSid;
nextSid = (Time.currentElapsedTime() << 24) >>> 8;
nextSid = nextSid | (id << 56);
if (nextSid == EphemeralType.CONTAINER_EPHEMERAL_OWNER) {
++nextSid; // this is an unlikely edge case, but check it just in case
}
return nextSid;
}
从源码可以总结出,生成sessionId初始值一共分为5个步骤:
假设当前时间毫秒值为
1644397769145
,机器sid为1。
(1)获取当前时间毫秒值
0000 0000 0000 0000 0000 0001 0111 1110 1101 1101 1011 1110 1011 0001 1011 1001
(2)向左移动24位,右边24个0就是左移出来的。
左移24位的目的是,将高位的1移出,剩下的最高位是0,这样得到的数就是一个正数。
0111 1110 1101 1101 1011 1110 1011 0001 1011 1001 0000 0000 0000 0000 0000 0000
当前时间毫秒值左移24位不一定是个正数,2022-04-07 01:50:41:664 之后的第40位是1,左移24位后,高位就是1,显然是个负数。所以才有了 右移8位是无符号的。
2022-04-07 01:50:41:664
0000 0000 0000 0000 0000 0001 1000 0000 0000 0000 0000 0000 0000 0000 0000 0000
(3)无符号右移8位
>>>
表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0。
0000 0000 0111 1110 1101 1101 1011 1110 1011 0001 1011 1001 0000 0000 0000 0000
(4)机器标识 SID 左移 56位
0000 0001 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
(5)(3)计算的数值和(4)计算的数据做
|
运算
|
: 按位或 ,双目运算 ,1 | 1 = 1,1 | 0 = 1,0 | 1 = 1,0 | 0 = 0
0000 0001 0111 1110 1101 1101 1011 1110 1011 0001 1011 1001 0000 0000 0000 0000
从sessionId创建可以看出,sessionId共64位,高8位是机器标识sid,中间40位是时间毫秒值,低16位是0,可用于后续自增。
1、先来看高8位是机器标识SID,实际生产中集群节点数最大可以是多少个?
源码中对机器标识SID限制不多,只有一个不能等于-1,其他数值经测试SID可以为负数,0,正数:
- SID取值为负数生成sessionId就没有多大意义了,难以区分出高8位是SID;
- SID也一般不设置为0,0和256重复了,左移56位都是0;
- SID取值大于256也没有意义,左移56位都是0,这样sessionId高8位没有识别度,可能会全局不唯一;
- SID在
[1, 127]范围内,计算的sessionId是正数,一个zk集群有127个节点也完全足够; - SID在
[128,255]范围内,第八位是1,左移56位左移56位就是一个负数,所以最后计算的sessionId也是一个负数。
所以一般SID正常取值为
[1, 127]
。
2、再来看中间40位的时间毫秒值,是否存在
(时间毫秒数<<24) >>> 8
计算的值有相等的情况?
通过
(时间毫秒数<<24) >>> 8
方式计算结果范围在
[0, 1099511627776)
(
1L << 40
=
1099511627776
),也就是两个时间戳之间间隔
1099511627776
毫秒,计算结果就会有重复。
1099511627776
毫秒换算成年,差不多是34.8年。所以计算的40位的时间毫秒值,每34.8年重复一次。
3、最后看低16位自增是否够用?
16位用于自增,取值范围为
[0, 65535]
,也就是说1ms最多可以生成65536个sessionId,1秒6553.6万,理论qps就是6553.6万/s。这个qps大部分业务应该是够的。
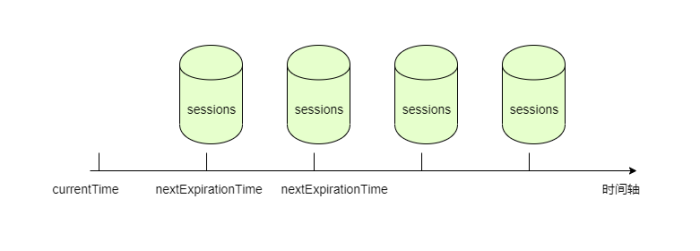
过期时间分桶管理会话
理论
所谓按过期时间分桶管理会话,就是最近一次具有相同过期时间点的会话放在一个桶里,这样方便批量管理。最近一次过期时间点如何计算?
nextExpirationTime = currentTime + sessionTimeout
如果真以这种方式计算最近一次过期时间点的话,桶会分的很散。看看zookssper是如何分桶的?
ZooKeeper的Leader服务器在运行期间会启动一个线程(
globalSessionTracker
)定时地进行会话过期检查,其时间间隔是
expirationInterval
,单位是毫秒,默认是
tickTime
,即默认情况下,每隔 2000 毫秒进行一次会话超时检查。
为了方便对多个会话同时进行超时检查,完整的
nextExpirationTime
的计算方式如下:
time = currentTime + sessionTimeout;
nextExpirationTime = (time / expirationInterval + 1) * expirationInterval;
如上方式计算的nextExpirationTime比正常计算的过期时间多出
(0,2000]
ms, 且总是
expirationInterval
的整数倍。
假设当前时间为1644377661000,sessionTimeout为20000:
time = 1644377661000 + 20000 = 1644377681000
nextExpirationTime = (1644377681000/2000 + 1) * 2000
nextExpirationTime = (822188840 + 1) * 2000
nextExpirationTime = 1644377682000
计算的nextExpirationTime比正常过期时间time多1000ms。
因此会话过期时长实际为
(sessionTimeout,sessionTimeout + expirationInterval]
ms。因此,将要在这个范围内过期的会话会放在一个桶里管理。
用
expirationInterval
的倍数作为时间点来分布会话,因此,超时检查线程只要在这些指定的时间点上进行检查即可。
源码实现
分桶管理实则是一个Map数据结构,key为
nextExpirationTime
,value为
Set
就是装会话实例的桶。
// E 泛型 可对应 SessionImpl
private final ConcurrentHashMap<Long, Set<E>> expiryMap = new ConcurrentHashMap<Long, Set<E>>();
为了方便通过会话检索
nextExpirationTime
,即找到会话所在的桶编号,还维护了一个Map,key为会话实例,value为
nextExpirationTime
。
private final ConcurrentHashMap<E, Long> elemMap = new ConcurrentHashMap<E, Long>();
计算 nextExpirationTime:
private long roundToNextInterval(long time) {
// nextExpirationTime值总是ExpirationInterval的整数倍数
// time / expirationInterval 会向下取整,+1就是向上取整,宁可大也不能比原来小
return (time / expirationInterval + 1) * expirationInterval;
}
调用示例:
Long newExpiryTime = roundToNextInterval(now + timeout)
会话过期检查

LeaderSessionTracker
会启动一个
超时检查线程
循环定时检查会话桶是否过期,过期的则进行清理操作。
// org.apache.zookeeper.server.SessionTrackerImpl#run
public void run() {
try {
while (running) {
// 判断 下一个检查过期时间点是否到了
// waitTime = expirationTime - now
long waitTime = sessionExpiryQueue.getWaitTime();
if (waitTime > 0) {
// 没到就休眠
Thread.sleep(waitTime);
continue;
}
// 依次清理过期 session
for (SessionImpl s : sessionExpiryQueue.poll()) {
ServerMetrics.getMetrics().STALE_SESSIONS_EXPIRED.add(1);
// 将会话状态设置为正在关闭
setSessionClosing(s.sessionId);
// 构建并发起 会话关闭 请求
expirer.expire(s);
}
}
} catch (InterruptedException e) {
handleException(this.getName(), e);
}
LOG.info("SessionTrackerImpl exited loop!");
}
获取距离下次过期时间间隔,waitTime > 0 则 休眠waitTime时间:
// org.apache.zookeeper.server.ExpiryQueue#getWaitTime
public long getWaitTime() {
long now = Time.currentElapsedTime();
long expirationTime = nextExpirationTime.get();
return now < expirationTime ? (expirationTime - now) : 0L;
}
从
ExpiryQueue
中取出过期的会话桶:
// org.apache.zookeeper.server.ExpiryQueue#poll
public Set<E> poll() {
long now = Time.currentElapsedTime();
// 1. 判断 expirationTime 是否过期
long expirationTime = nextExpirationTime.get();
if (now < expirationTime) {
return Collections.emptySet();
}
Set<E> set = null;
long newExpirationTime = expirationTime + expirationInterval;
// 2. cas 更新 nextExpirationTime
if (nextExpirationTime.compareAndSet(expirationTime, newExpirationTime)) {
// 3. 清理 过期桶
set = expiryMap.remove(expirationTime);
}
if (set == null) {
return Collections.emptySet();
}
return set;
}
会话清理
检测到会话过期,需要对该会话做清理工作。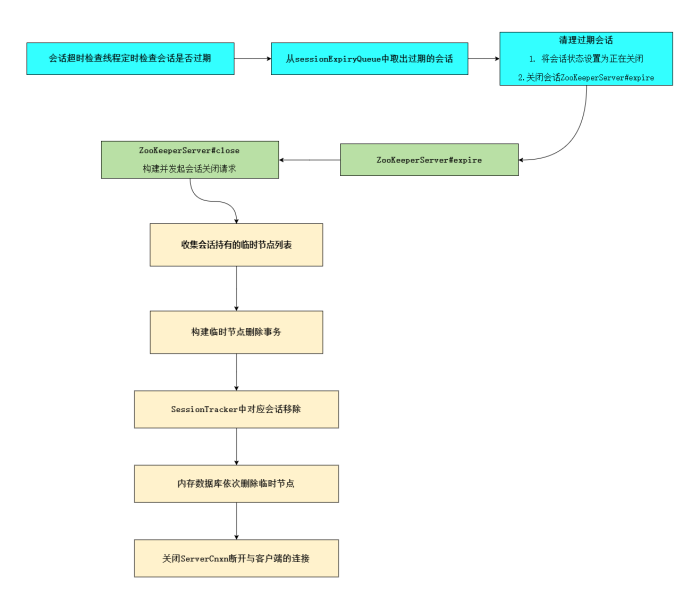
1、标记会话状态为“正在关闭”:
由于整个会话清理过程需要一段的时间,因此为了保证在此期间不再处理来自该客户端的新请求,SessionTracker会首先将该会话的isClosing属性标记为true。这样,即使在会话清理期间接收到该客户端的新请求,也无法继续处理了。
2、发起发起“会话关闭”请求:
为了使对该会话的关闭操作在整个服务端集群中都生效,ZooKeeper 使用了提交“会话关闭”请求的方式,并立即交付给PrepRequestProcessor处理器进行处理。
过期的会话桶中的会话依次构建并发起“会话关闭”请求:
ZooKeeperServer
实现了接口
SessionExpirer
。
// org.apache.zookeeper.server.ZooKeeperServer#expire
public void expire(Session session) {
long sessionId = session.getSessionId();
LOG.info(
"Expiring session 0x{}, timeout of {}ms exceeded",
Long.toHexString(sessionId),
session.getTimeout());
close(sessionId);
}
// org.apache.zookeeper.server.ZooKeeperServer#close
private void close(long sessionId) {
Request si = new Request(null, sessionId, 0, OpCode.closeSession, null, null);
submitRequest(si);
}
3、收集会话相关的临时节点列表
在ZooKeeper中,一旦某个会话失效后,那么和该会话相关的临时(EPHEMERAL)节点都需要被清理掉。因此,在清理临时节点之前,首先需要将服务器上所有和该会话相关的临时节点都整理出来。
在 ZooKeeper 的内存数据库中,为每个会话都单独保存了一份由该会话维护的所有临时节点集合
ephemerals
,key为
sessionID
,value为临时节点path集合。
Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>();
因此在会话清理阶段,只需要根据当前即将关闭的会话的
sessionID
从内存数据库中获取到这份临时节点列表
ephemerals
即可。
发起的“会话关闭”请求,流转到
PrepRequestProcessor
,由
PrepRequestProcessor
做临时节点收集工作。
在处理会话关闭请求时,可能正好有节点删除和节点创建的请求在进行:
- 节点删除请求,删除的目标节点正好是上述临时节点中的一个,需要将其从上述获取的临时节点列表中排除,以免重复删除。
- 临时节点创建请求,创建的目标节点正好是上述临时节点中的一个,需要将其加入到上述获取的临时节点列表中。后续进行删除操作。
完成会话相关的临时节点收集后,ZooKeeper会逐个将这些临时节点转换成“节点删除”请求,并放入事务变更队列
outstandingChanges
中去。
同时将收集起来的
ephemerals
构建
CloseSessionTxn
设置给
Request
。
如下是
PrepRequestProcessor
中处理会话关闭请求的部分代码:
// org.apache.zookeeper.server.PrepRequestProcessor#pRequest2Txn
case OpCode.closeSession:
synchronized (zks.outstandingChanges) {
// 需要将 Ephemerals 临时节点移动到 zks.outstandingChanges 中
// 这个过程需要对 zks.outstandingChanges加同步锁,否则将会出现:
// 正在进行中的删除节点的事务,会重复执行删除操作。
// need to move getEphemerals into zks.outstandingChanges
// synchronized block, otherwise there will be a race
// condition with the on flying deleteNode txn, and we'll
// delete the node again here, which is not correct
Set<String> es = zks.getZKDatabase().getEphemerals(request.sessionId);
for (ChangeRecord c : zks.outstandingChanges) {
if (c.stat == null) {
// Doing a delete
// stat = null,说明该节点正在进行删除操作,
// 需要在 ephemerals 中将其排除
es.remove(c.path);
} else if (c.stat.getEphemeralOwner() == request.sessionId) {
// outstandingChanges中有该会话的临时节点,可能正在进行创建节点操作
// 需要将其加入到 ephemerals中
es.add(c.path);
}
}
// 构建 节点删除 事务,并将其加入到 zks.outstandingChanges中
for (String path2Delete : es) {
if (digestEnabled) {
parentPath = getParentPathAndValidate(path2Delete);
parentRecord = getRecordForPath(parentPath);
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
parentRecord.stat.setPzxid(request.getHdr().getZxid());
parentRecord.precalculatedDigest = precalculateDigest(
DigestOpCode.UPDATE, parentPath, parentRecord.data, parentRecord.stat);
addChangeRecord(parentRecord);
}
nodeRecord = new ChangeRecord(
request.getHdr().getZxid(), path2Delete, null, 0, null);
nodeRecord.precalculatedDigest = precalculateDigest(
DigestOpCode.REMOVE, path2Delete);
addChangeRecord(nodeRecord);
}
if (ZooKeeperServer.isCloseSessionTxnEnabled()) {
// 将 ephemerals 构建 CloseSessionTxn 放进 request
request.setTxn(new CloseSessionTxn(new ArrayList<String>(es)));
}
zks.sessionTracker.setSessionClosing(request.sessionId);
}
break;
4、移除会话:
会话关闭请求流转到
FinalRequestProcessor
,将其应用到内存数据库。首先将会话从 SessionTracker 中清除。
5、删除临时节点:
内存数据库DataTree,从请求中取出
CloseSessionTxn
,解析出
ephemerals
,依次执行删除节点操作。
6、关闭 ServerCnxn:
最后,断开与客户端的连接。向网络底层发送
ServerCnxnFactory.closeConn
(
ByteBuffer.allocate(0)
),
NIOServerCnxn
在处理写事件(
NIOServerCnxn#handleWrite
)时会触发
CloseRequestException
异常,并捕获该异常,进行连接断开和清理工作。
会话激活
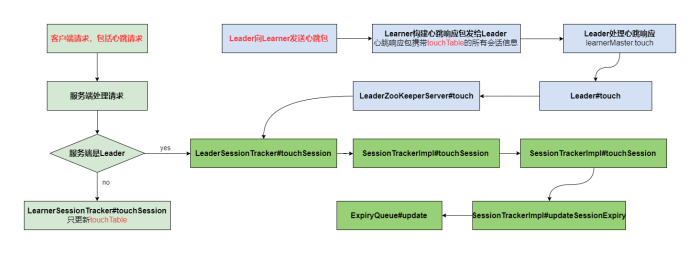
为了保持客户端会话的有效性,在ZooKeeper的运行过程中,客户端会在会话超时时间过期范围内向服务端发送 PING 请求来保持会话的有效性,也就是心跳检测。
如果客户端发现在 sessionTimeout/3 时间内尚未和服务器进行过任何通信,即没有向服务端发送任何请求,那么就会主动发起一个PING请求,服务端收到该请求后,重新激活对应的客户端会话,这个重新激活的过程称为
touchSession
。实际上,只要客户端有请求发送到服务端,就会触发一次会话激活。
通过阅读会话管理SessionTracker的源码,发现Learner(Follower+Observer)是不管理会话的,Leader才有管理会话的职责。而当客户端连接的服务端是Learner时,向Learner发送心跳或者请求触发的会话激活,还需要配合 Learner 和 Leader之间的心跳过程。
服务端接收客户端的请求,在流转链式
RequestProcessor
处理时,会先触发会话激活
touchSession
,对于Learner的
LearnerSessionTracker
来说,
touchSession
只是简单的更新下
touchTable
。
当Learner接收到来自Leader的心跳,构建心跳响应时,将
touchTable
中的会话信息(
sessionId+sessionTimeout
)全部取出来发送给Leader,让Leader去触发会话激活。
// org.apache.zookeeper.server.SessionTrackerImpl#touchSession
public synchronized boolean touchSession(long sessionId, int timeout) {
SessionImpl s = sessionsById.get(sessionId);
// 检查会话是否存在
if (s == null) {
logTraceTouchInvalidSession(sessionId, timeout);
return false;
}
// 检查会话是否正在关闭
if (s.isClosing()) {
logTraceTouchClosingSession(sessionId, timeout);
return false;
}
// 更新会话
updateSessionExpiry(s, timeout);
return true;
}
会话激活的过程,就是会话从旧桶迁移到新桶的过程:
// org.apache.zookeeper.server.ExpiryQueue#update
public Long update(E elem, int timeout) {
// 1.获取会话实例上一次过期时间点
Long prevExpiryTime = elemMap.get(elem);
long now = Time.currentElapsedTime();
// 2.计算的 newExpiryTime 比 now + timeout 要大
Long newExpiryTime = roundToNextInterval(now + timeout);
// 3. prevExpiryTime 和 newExpiryTime 进行比较,相等就不做处理
if (newExpiryTime.equals(prevExpiryTime)) {
// No change, so nothing to update
return null;
}
// 4.将 会话实例放进新桶里
// First add the elem to the new expiry time bucket in expiryMap.
Set<E> set = expiryMap.get(newExpiryTime);
if (set == null) {
// Construct a ConcurrentHashSet using a ConcurrentHashMap
set = Collections.newSetFromMap(new ConcurrentHashMap<E, Boolean>());
// Put the new set in the map, but only if another thread
// hasn't beaten us to it
Set<E> existingSet = expiryMap.putIfAbsent(newExpiryTime, set);
if (existingSet != null) {
set = existingSet;
}
}
set.add(elem);
// 5. 将旧桶中的对应会话记录删除
// Map the elem to the new expiry time. If a different previous
// mapping was present, clean up the previous expiry bucket.
prevExpiryTime = elemMap.put(elem, newExpiryTime);
if (prevExpiryTime != null && !newExpiryTime.equals(prevExpiryTime)) {
Set<E> prevSet = expiryMap.get(prevExpiryTime);
if (prevSet != null) {
prevSet.remove(elem);
}
}
return newExpiryTime;
}
LearnerSessionTracker
可以开启本地会话管理
LocalSessionTracker
,
LocalSessionTracker
继承则
SessionTrackerImpl
,故而会话管理的原理是一样的,默认是不开启的。
如若文章有错误理解,欢迎批评指正,同时非常期待你的评论、点赞和收藏。
如果想了解更多优质文章,和我更密切的学习交流,请关注如下同名公众号【徐同学呀】,期待你的加入。
版权归原作者 徐同学呀 所有, 如有侵权,请联系我们删除。