
如果我必须用一句话来描述 Elasticsearch,我会这样说:
当搜索遇到大规模分析时(近乎实时)
Elasticsearch 是目前最受欢迎的 10 大开源技术之一。 公平地说,它包含许多本身并不独特的关键功能,但是,结合使用它可以成为最好的搜索引擎/分析平台。
更准确地说,Elasticsearch 之所以如此受欢迎,是因为结合了以下特性:
- 使用相关性评分进行搜索
- 全文搜索
- 分析(聚合)
- 无模式(shemaless 对数据模式没有限制)、NoSQL、面向文档
- 丰富的数据类型选择
- 水平可扩展
- 容错的
当我们使用 Elasticsearch时,我们很快意识到官方文档看起来更像是从应该称为文档的内容中 “挤压” 出来的,尽管官方的文档在很多方面都是很不错的。 我们有时不得不到处搜索和使用 stackowerflowing。
在本文中,我将主要介绍查询/搜索 Elasticsearch 集群。 有许多不同的方法可以实现或多或少相同的结果,因此,我将尝试解释每种方法的优缺点。
更重要的是,我将向你介绍两个重要的概念 —— 查询(query)和过滤(filter)上下文 —— 文档中没有很好地解释它们。 我会给你一套规则,告诉你什么时候最好使用哪种方法。如果我希望您在阅读完本文后记住一件事,那就是:
你真的需要在查询时对文档进行评分吗?
Query 上下文与 filter 上下文
当我们谈论 Elasticsearch 时,总会有一个相关性分数。 相关性分数是一个严格的正浮点数,表示每个文档满足搜索条件的程度。 该分数是相对于分配的最高分数而言的,因此,分数越高,文档与搜索标准的相关性越好。
但是,过滤器(filter)和查询(query)是两个不同的概念,你在编写查询之前应该能够理解它们。一般来说,过滤器上下文是一个是/否选项,其中每个文档都与查询匹配或不匹配。 一个很好的例子是 SQL WHERE 后跟一些条件。 SQL 查询总是返回与条件严格匹配的行。 SQL 查询无法返回不明确的结果。
过滤器会自动缓存,不会影响相关性得分。
另一方面,Elastisearch 查询(query)上下文向你显示每个文档与你的要求的匹配程度。 为此,查询使用分析器来查找最佳匹配。经验法则是:
将过滤器用于:
- 是/否搜索
- 搜索精确值(数字、范围和关键字)
将查询用于:
- 模棱两可的结果(一些文档比其他文档更受关注)
- 全文搜索
除非你需要相关性分数或全文搜索,否则请始终尝试使用过滤器。 过滤器 “更便宜”。
此外,Elasticsearch 会自动缓存过滤器的结果。
在第 1 部分和第 2 部分中,我将讨论查询(可以转换为过滤器)。 请不要如下的将结构化与全文与查询与过滤器混淆 —— 这是两个不同的东西。
1)结构化查询
结构化查询也称为术语级(term-level)查询,是一组检查是否应选择文档的查询方法。 因此,在许多情况下并不真正需要相关性分数 —— 文档要么匹配要么不匹配(尤其是数字)。
术语级查询仍然是查询,因此它们将返回分数。
术语查询(term query)
返回字段值与条件完全匹配的文档。 术语查询在某种程度上是 SQL select * from table_name where column_name =...
术语查询直接进入倒排索引,这使得它很快。 在处理文本数据时,最好只对 keyword 字段使用术语(term)。
GET /_search
{
"query": {
"term": {
"<field_name>": {
"value": "<your_value>"
}
}
}
}
默认情况下,术语查询在查询上下文中运行,因此,它将计算分数。 即使返回的所有文档的分数都相同,也会涉及额外的计算能力。
带过滤器的术语查询(term query)
如果我们想加速术语查询并将其缓存起来,那么它应该包含在一个 constant_score 过滤器中。还记得经验法则吗? 如果你不关心相关性分数,请使用此方法。
GET /_search
{
"query": {
"constant_score" : {
"filter" : {
"term" : {"<field_name>" : "<your_value>"}
}
}
}
}
现在,查询不计算任何相关性得分,因此速度更快。 此外,它会自动缓存。
快速建议 —— 在 text 字段中使用 match 而不是 term。
请记住,术语查询直接指向倒排索引。 Term query 获取你提供的值并按原样搜索它,这就是为什么它非常适合查询未经任何转换而存储的 keyword 字段。
Terms query
正如你可能已经猜到的那样,术语查询允许你返回与至少一个确切术语匹配的文档。术语查询在某种程度上是 select * from table_name where column_name is in...
重要的是要了解 Elasticsearch 中的查询字段可能是一个列表,例如 { "name" : ["Odin", "Woden", "Wodan"] }。 如果你执行包含以下名称之一的术语查询,那么这条记录将被匹配 —— 它不必匹配字段中的所有值,而只需匹配一个。
GET /_search
{
"query" : {
"terms" : {
"name" : ["Frigg", "Odin", "Baldr"]
}
}
}
Terms set query
与术语查询相同,但这次你可以指定查询字段中应包含多少个确切术语。
你指定必须匹配的数量 —— 一个、两个、三个或全部。 但是,这个数字是另一个数字字段。 因此,每个文档都应包含此编号(特定于此特定文档)。关于这个个搜索,详细描述请参阅文章 “开始使用 Elasticsearch (2)” 中的描述。
Range query
返回查询字段值在定义范围内的文档。等效于 SQL select * from table_name where column_name is between...
范围查询有自己的语法:
- gt 大于
- gte 大于或等于
- lt 小于
- lte 小于或等于
字段值应 ≥ 4 且 ≤ 17 的示例:
GET _search
{
"query": {
"range" : {
"<field_name>" : {
"gte" : 4,
"lte" : 17
}
}
}
}
范围查询也适用于日期。
正则表达式、通配符和前缀查询
Regexp 查询返回字段与你的正则表达式匹配的文档。如果你从未使用过正则表达式,那么我强烈建议你至少了解一下它是什么以及何时可以应用它
Elasticsearch 的正则表达式是 Lucene 的正则表达式。 它具有标准的保留字符和运算符。 如果你已经使用过 Python 的 re 包,那么在这里使用它应该不是问题。 唯一不同的是 Lucene 的引擎不支持 ^ 和 $ 等 anchor 操作符。你可以在官方文档中找到正则表达式的完整列表。
除了正则表达式查询之外,Elsticsearch 还有通配符和前缀查询。 从逻辑上讲,这两个只是正则表达式的特例。不幸的是,我找不到关于这 3 个查询的性能的任何信息。
Exists query
由于 Elasticsearch 是无模式的(或没有严格的模式限制),当不同的文档具有不同的字段时,这是一种相当普遍的情况。 因此,了解文档是否具有任何特定字段有很多用处。
Exists query 返回包含字段索引值的文档
GET /_search
{
"query": {
"exists": {
"field": "<your_field_name>"
}
}
}
2)全文查询
全文查询适用于非结构化文本数据。 全文查询利用分词器。 因此,我将简要介绍一下 Elasticsearch 的分析器,以便我们更好地分析全文查询。Elasticsearch 的分词器管道每次将文本类型数据插入 Elasticsearch 索引时,都会对其进行分析,然后存储在倒排索引中。 根据你配置分词器的方式将影响你的搜索功能,因为分词器也适用于全文搜索。
管道分词器由三个阶段组成:
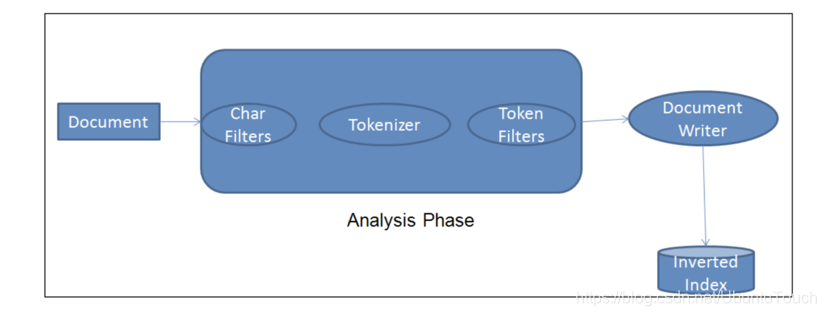
总是有一个分词器和零个或多个字符和分词过滤器。
1)Character filter 按原样接收文本数据,然后它可能会在数据被 tokenizer 之前对数据进行预处理。 Character filter 用于:
- 替换匹配给定正则表达式的字符
- 替换匹配给定字符串的字符
- 净化 HTML 文本
- Tokenizer 将 character filter(如果有)后收到的文本数据分解为 token。 例如,whitespace tokenizer 只是通过空格来打断文本(它不是标准的)。 因此,Wednesday is called after Woden。 将拆分为 [Wednesday, is, called, after, Woden.]。 有许多内置分词器可用于创建自定义分析器。
Standard analyzer 在删除标点符号后按空格分隔文本。 对于绝大多数语言来说,它是最中性的选择。除了 tokenization之外,tokenizer 还执行以下操作:
- 跟踪 token 顺序,
- 注意每个单词的开始和结束
- 定义 token 的类型
3)Token filter 对 token 应用一些转换。 你可以选择将许多不同的 token 过滤器添加到您的分析器中。 一些最受欢迎的是:
- lowercase 小写
- stemmer 词干分析器(存在于多种语言中!)
- 删除重复项
- 转换为 ASCII 等价物
- 模式的解决方法
- token 数量限制
- token 的停止列表(从停止列表中删除令牌)
如果你对 analyzer 不是很熟的话,请阅读我之前的文章 “Elasticsearch: analyzer”。
现在,当我们知道分析器由什么组成时,我们可能会考虑如何处理我们的数据。 然后,我们可以通过选择合适的组件来组成一个最适合我们案例的分析器。 可以在每个字段的基础上指定分词器。
我们现在有足够的理论,让我们看看默认分词器是如何工作的。
Standard analyzer 是默认的。 它有 0 个字符过滤器、标准标记器、小写和停止标记过滤器。 你可以根据需要编写自定义分析器,但也有一些内置分词器。
一些最高效的开箱即用分析器是语言分词器,它们利用每种语言的细节来进行更高级的转换。 因此,如果你事先知道数据的语言,我建议你从 standard analyzer 切换到其中一种数据语言。
全文查询将使用与索引数据时使用的分析器相同的分词器。 更准确地说,你的查询文本将与搜索字段中的文本数据进行相同的转换,因此两者处于同一级别。
Match query
Match query 是查询文本字段的标准查询。我们可以将 match query 称为 term query 的等效项,但用于 text 类型字段(而在处理文本数据时,术语应仅用于 keyword 类型字段)。
GET /_search
{
"query" : {
"match" : {
"<text_field>" {
"query" : "<your_value>"
}
}
}
}
传递到 query 参数(必填)的字符串,默认情况下,将由与应用于搜索字段的分析器相同的分词器进行处理。 除非你使用分析器参数自己指定分词器。
当你指定要搜索的短语时,系统会对它进行分析,结果始终是一组 token。 默认情况下,Elasticsearch 将在所有这些标记之间使用 OR 运算符。 这意味着至少应该有一个匹配 —— 不过更多的匹配会得到更高的分数。 你可以在运算符参数中将其切换为 AND。 在这种情况下,必须在文档中找到所有 token 才能返回。
如果你想在 OR 和 AND 之间有一些东西,你可以指定 minimum_should_match 参数,它指定应该匹配的子句数。 它可以指定为数字和百分比。
fuzziness 参数(可选)允许您省略拼写错误。 Levenshtein 距离用于计算。
如果你将匹配查询应用于 keyword 字段,那么它将执行与术语查询相同的操作。 更有趣的是,如果将存储在倒排索引中的 token 的确切值传递给 term query,那么它将返回与 match query 完全相同的结果,但速度更快,因为它会直接进入倒排索引。
Multi-match query
Multi-match query 与 match 的作用相同,唯一的区别是它应用于多个字段。
GET /_search
{
"query": {
"multi_match" : {
"query": "<your_value>",
"fields": [ "<text_field1>", "<text_field2>" ]
}
}
}
- 可以使用 wildcard 指定字段名称
- 默认情况下每个字段都具有相同的权重
- 每个字段对分数的贡献都可以提高
- 如果 fields 参数中没有指定字段,则将搜索所有符合条件的字段
有不同类型的 multi_match。 我不打算在这篇文章中描述它们,但我会解释最流行的:
best_fields 类型(默认)更喜欢在一个字段中找到来自搜索值的 token 的结果,而不是搜索标记在不同字段之间拆分的结果。
phrase 类型的行为与 best_fields 类似,但搜索与 match_phrase 相似的整个短语。
我强烈建议你阅读官方文档以检查每个字段的分数是如何准确计算的。
Boolean query
Boolean query 将其他查询组合在一起。 它是最重要的复合查询。Boolean query 允许你将查询上下文中的搜索与过滤上下文搜索结合起来。
Boolean query 有四种可以组合在一起的出现(类型):
- must 或 “必须满足条款”
- should 或 “如果满足子句,则对相关性分数加分”
- filter 或 “必须满足条款但不计算相关性分数”
- must_not 或 “与 must 相反,对相关性分数没有贡献”
must 和 should → 查询上下文
filter 和 must_not → 过滤上下文
对于熟悉 SQL 的人来说,must 是 AND 而 should 是 OR 运算符。 因此,必须满足 must 子句中的每个查询
Boosting query
Boosting query与大多数查询的提升参数相似,但并不相同。 Boosting query 返回匹配 positive 子句的文档并降低匹配 negative 子句的文档的分数。
Constant score query
正如我们之前在 term query 示例中看到的,constant_score 查询将任何查询转换为相关性得分等于 boost 参数(默认为 1)的过滤器上下文。
总结
总而言之,Elasticsearch 现在适合许多用途,有时很难理解什么是最好的工具。我希望你记住的主要事情是,你并不总是需要使用最高级的功能来解决简单的问题。
如果你不需要相关性分数来检索你的数据,请尝试切换到过滤器上下文。
此外,了解 Elasticsearch 的底层工作原理也很重要,因此我建议你充分了解分词器的功能。Elasticsearch 中有更多的查询类型。 我试图描述最常用的。 我希望你喜欢它。
更多阅读:开始使用 Elasticsearch (2)
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。