
一,Spark SQL概述
1,Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
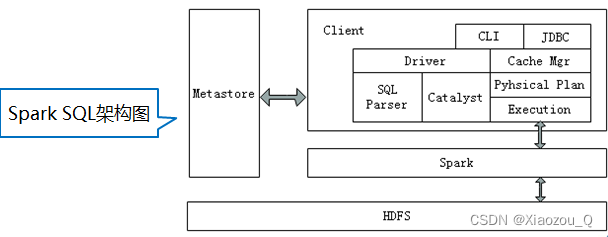
2,Spark SQL架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
二,DataFrame概述
1,DataFrame简介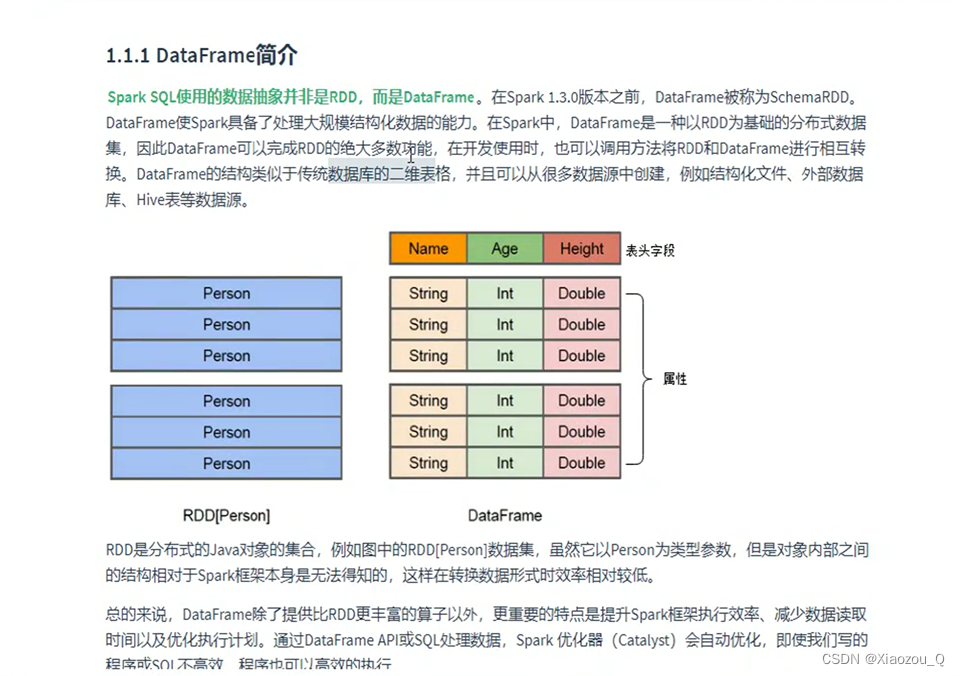
2,DataFrame的创建
已存在的RDD调用toDF()方法转换得到DataFrame
通过Spark读取数据源直接创建DataFrame
(1)数据准备
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:
(2)通过文件直接创建****DataFrame



(3)RDD直接转换为DataFrame 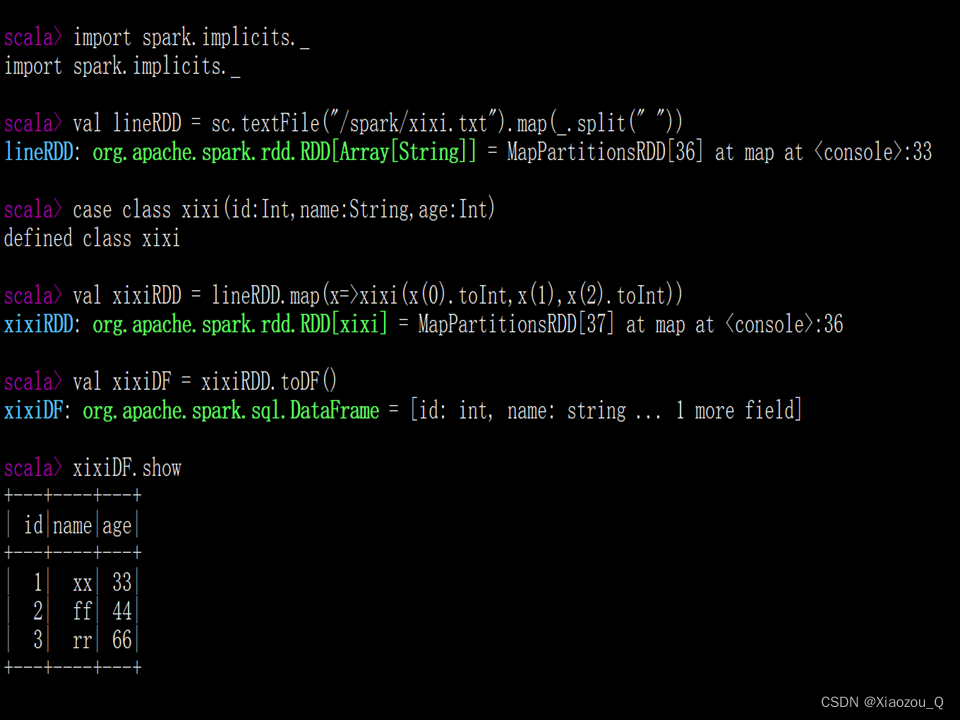
3,DataFrame的常用操作
(1)DSL风格操作
DataFrame提供了一个领域特定语言(DSL)以方便操作结构化数据,下面将针对DSL操作风格,讲解DataFrame
常用操作示例,
1.show():查看DataFrame中的具体内容信息
2.pritSchema0:查看0staFrame的Schema信息
3.select():查看DataFmame中造取部分列的数据,
下面演示查看xixiDF对象的name字段数据,具体代码如下所示
三,Dataset概述
1,RDD、DataFrame及Dataset的区别
RDD数据的表现形式,即序号(1),此时RDD数据没有数据类型和元数据信息。
DataFrame数据的表现形式,即序号(2),此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值
Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制
(1)通过SparkSession中的createDataset来创建****Dataset
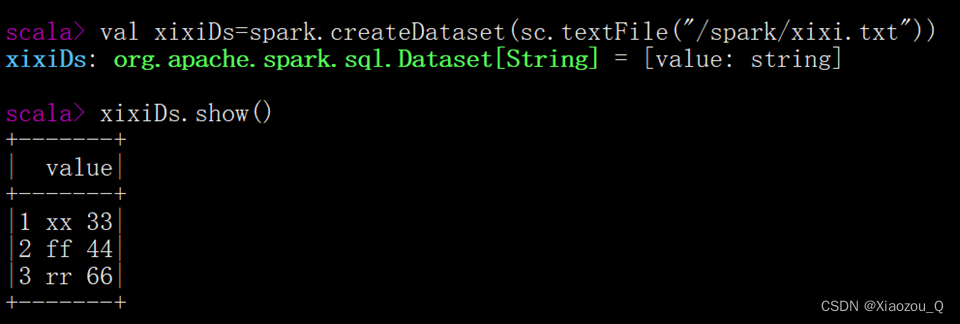
(2)DataFrame通过“as[ElementType]”方法转换得到Dataset
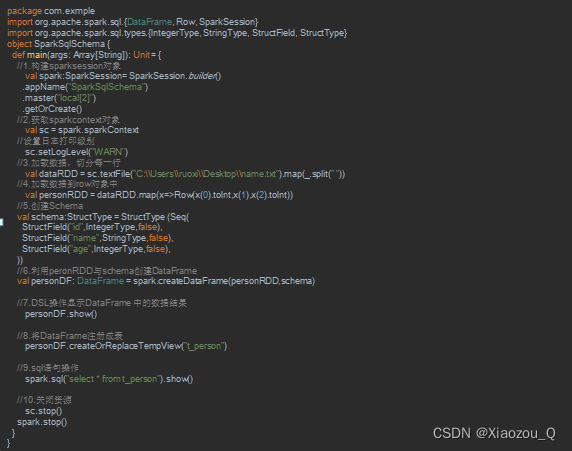
四, RDD转换DataFrame
版权归原作者 Xiaozou_Q 所有, 如有侵权,请联系我们删除。